







 超级会员免费看
超级会员免费看
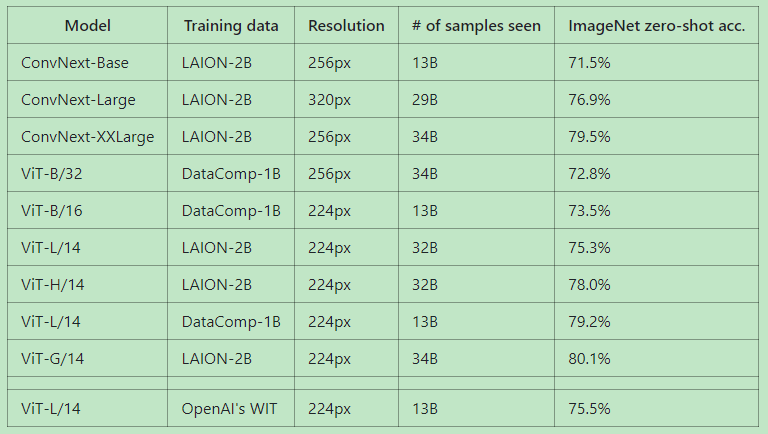
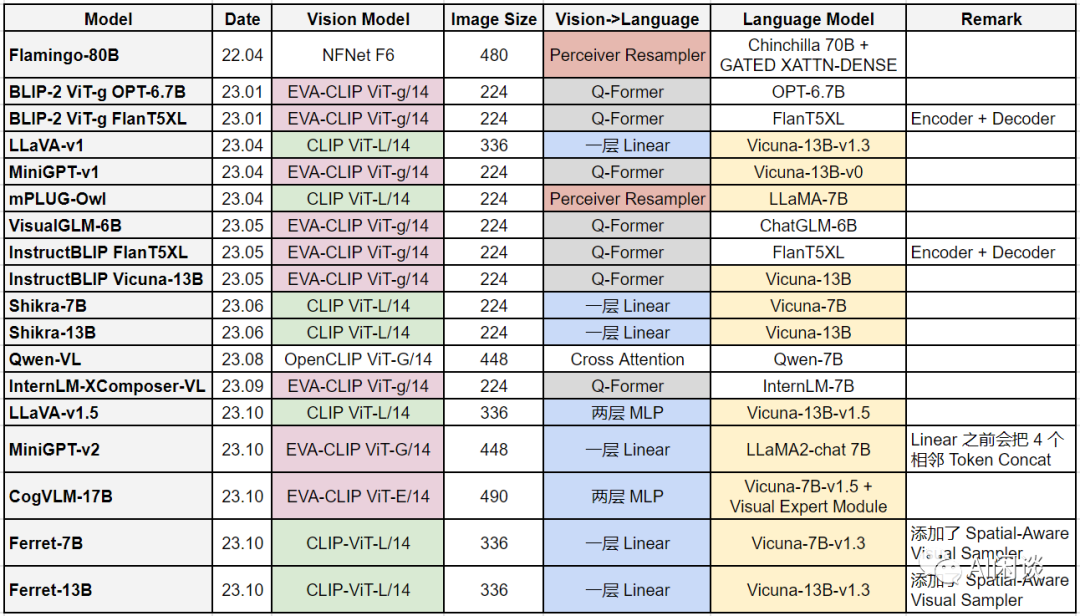
 本文探讨了在多模态视觉编码中,使用如CLIP的ViT(Vision Transformer)而非传统分类backbone能显著提升效果。列举了不同模型如EVA2-CLIP-E、QWEN-VL、LLAVA等,它们支持的分辨率从224到896像素不等,展示分辨率变化对模型性能的影响。
本文探讨了在多模态视觉编码中,使用如CLIP的ViT(Vision Transformer)而非传统分类backbone能显著提升效果。列举了不同模型如EVA2-CLIP-E、QWEN-VL、LLAVA等,它们支持的分辨率从224到896像素不等,展示分辨率变化对模型性能的影响。
在多模态的视觉编码主干中,若采用分类的backbone效果很差,经过语义对齐的backbone,比如clip的vit,效果则好很多。
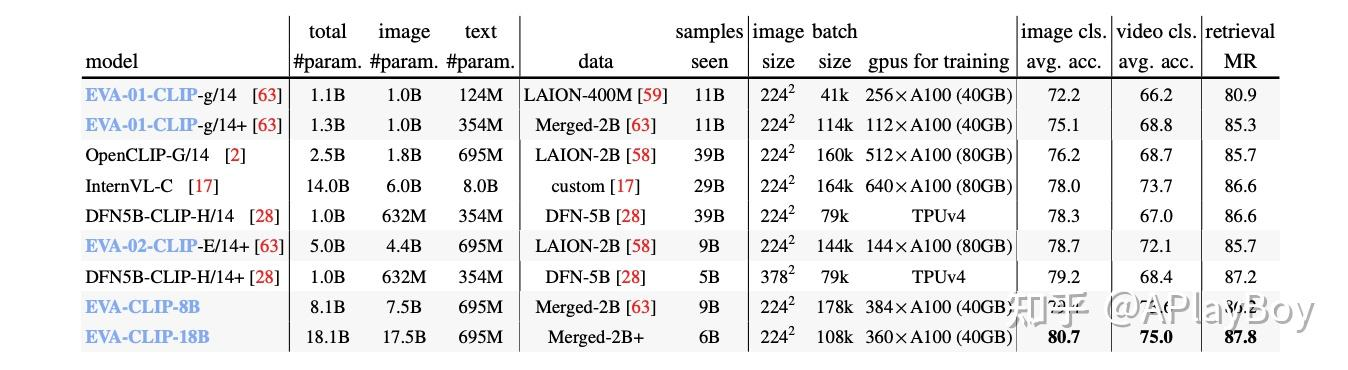
1.Cogvlm中的EVA2-CLIP-E,VIT中最后一层被移除,4.4B,支持分辨率为334/490.
2.QWEN-VL中openclip的ViT-bigG,1.9B,支持分辨率448x448。
在多模态的视觉编码主干中,若采用分类的backbone效果很差,经过语义对齐的backbone,比如clip的vit,效果则好很多。
1.Cogvlm中的EVA2-CLIP-E,VIT中最后一层被移除,4.4B,支持分辨率为334/490.
2.QWEN-VL中openclip的ViT-bigG,1.9B,支持分辨率448x448。
 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























