







- 背景
听歌识曲是我们生活中常见的功能了,那么这里面的原理又是什么呢?
正如一句话说的:你眼中看似落叶纷飞变化无常的世界,实际只是躺在上帝怀中一份早已谱好的乐章,傅里叶同学告诉我们,任何周期函数,都可以看作是不同振幅,不同相位正弦波的叠加
这也是听歌识曲里面用到的一个重要概念:频谱,更进一步说是短时傅里叶变换,通过变换采集音频特征作为匹配对象,将待识别的音频按同样方式采集特征,双方进行匹配,匹配结果不仅包含了音频种类,还有对应的时间偏移,下面就来简单介绍一下具体的过程吧!
- 音乐识别过程
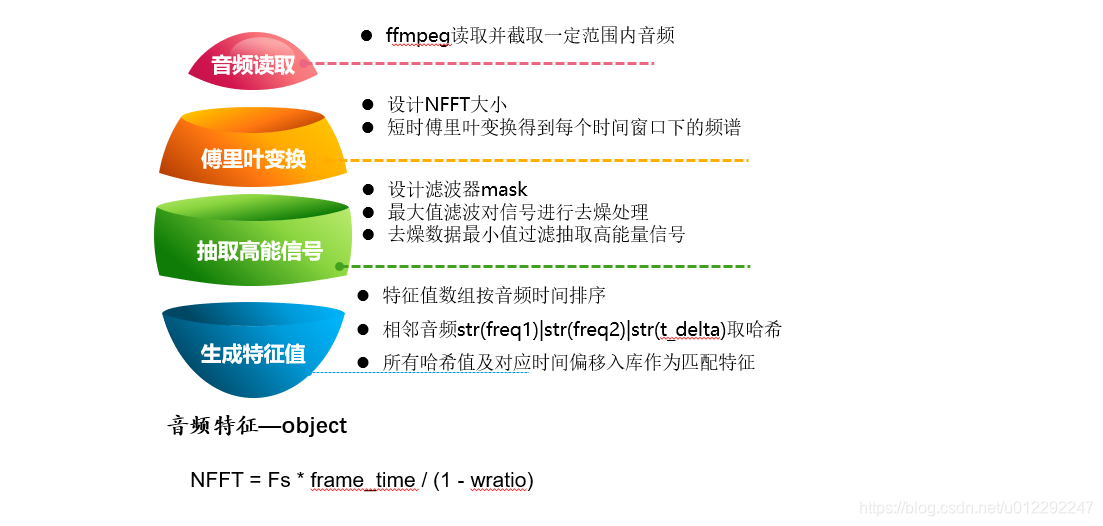
1、音频信息读取
def read(filename, limit=None):
"""
Reads any file supported by pydub (ffmpeg) and returns the data contained
within. If file reading fails due to input being a 24-bit wav file,
wavio is used as a backup.
Can be optionally limited to a certain amount of seconds from the start
of the file by specifying the `limit` parameter. This is the amount of
seconds from the start of the file.
returns: (channels, samplerate)
"""
# pydub does not support 24-bit wav files, use wavio when this occurs
try:
audiofile = AudioSegment.from_file(filename)
if limit:
res_len = min(len(audiofile), limit * 1000)
audiofile = audiofile[:res_len]
data = np.fromstring(audiofile._data, np.int16)
channels = []
for chn in xrange(audiofile.channels):
channels.append(data[chn::audiofile.channels])
fs = audiofile.frame_rate
except audioop.error:
fs, _, audiofile = wavio.readwav(filename)
if limit:
res_len = min(len(audiofile), limit * 1000)
audiofile = audiofile[:res_len]
audiofile = audiofile.T
audiofile = audiofile.astype(np.int16)
channels = []
for chn in audiofile:
channels.append(chn)
return channels, audiofile.frame_rate, unique_hash(filename)读取方式有两种,优先使用ffmpeg库来读取,即上面的AudioSegment,读取后可以截取指定范围内的音频数据,比如上面的limit参数就是限定前几秒音频。最终拿到的结果就是前几秒音频所有通道的数据,也能获得音频的采样频率,采样位数等相关信息。
2、将获得的音频信息进行短时傅里叶变换
短时傅里叶简介:
短时傅里叶的主要思想是将一段音频分割成多帧,分帧理论基础是音频的短时平稳性,然后每一帧音频进行傅里叶变换得到频谱。但是分帧的一个问题就是频谱泄漏,为了解决这个问题,还需要一个窗函数使分帧后的信号变得连续,每一帧就会表现出周期函数的特征。短时傅里叶变换用来分析分段平稳信号或者近似平稳信号犹可,但是对于非平稳信号,当信号变化剧烈时,要求窗函数有较高的时间分辨率;而波形变化比较平缓的时刻,主要是低频信号,则要求窗函数有较高的频率分辨率。
这里再补充一下分帧加窗作用:
傅里叶变换是针对无限长波形做处理的,所以会将每一段截取的音频帧无限复制形成无限长波形,如果截取的音频帧刚好是整个周期,那复制后完美还原原本波形,如果只是四分之一波形呢,复制后的波形就和原本的差异比较大了,这样变换得到的频谱图也是不准的,所以需要用周期函数即窗函数进行一次调整,这样截取的音频帧就具备周期性,复制后也不会影响。
同样加窗后窗函数两边的波形会被削弱,为了弥补这个缺点,就可以通过帧重叠来弥补,即帧偏移为1/2或者1/3帧
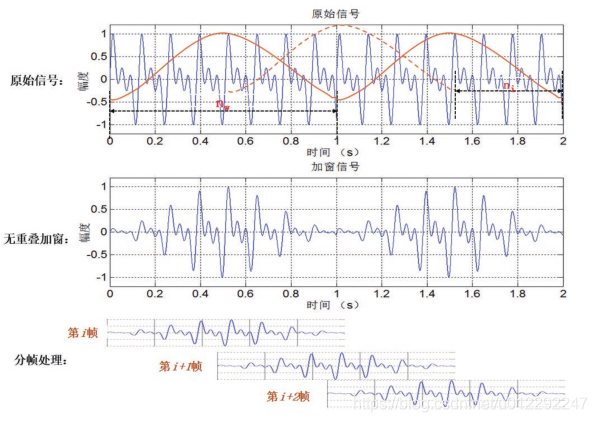
短时傅里叶实现:
# FFT the signal and extract frequency components
# NFFT是频谱横坐标分割数,即频率密度,NFFT越大代表频率精度越高,时间精度越低,因为匹配音乐是匹配高频部分,所以要保证频谱分辨率一致
# 分帧时长取30毫秒,NFFT = Fs * frame_time / (1 - wratio), len = (NFFT * wsize) * (1 - wratio) , wsize = len / (Fs * frame_time)
# wsize = int(Fs * 0.06),取最接近的2的整次幂
arr2D = mlab.specgram(
channel_samples,
NFFT=wsize,
Fs=Fs,
window=mlab.window_hanning,
noverlap=int(wsize * wratio))[0]
# apply log transform since specgram() returns linear array
arr2D = 10 * np.log10(arr2D)
arr2D[arr2D == -np.inf] = 0 # replace infs with zeros上面是python提供的短时傅里叶实现,NFFT代表的是频率分辨率,因为频率分辨率决定了时间分辨率,所以根据音频短时平稳特性,如果我们选取的时间段是30ms,那么NFFT就可以选择512(NFFT最好是2的整次幂,比较符合快速傅里叶变换算法,算法最高效),另外为什么傅里叶变换后取log,是因为人对声音强弱的感觉并不是与声强成正比,而是与其对数成正比的。
备注:DNN做声学模型时,一般用fbank,不用mfcc,因为fbank信息更多
3、抽取短时高能信号
音频中的高能信号为需要保留的信息,其他都为噪声信号,所以要匹配音乐的话我们只要抽取出音乐的高能信号存储到数据库作为匹配对象就可以了,下面是例子:
def get_2D_peaks(arr2D, plot=False, amp_min=DEFAULT_AMP_MIN):
# http://docs.scipy.org/doc/scipy/reference/generated/scipy.ndimage.iterate_structure.html#scipy.ndimage.iterate_structure
neighborhood = np.ones((PEAK_NEIGHBORHOOD_SIZE, PEAK_NEIGHBORHOOD_SIZE))
local_max = maximum_filter(arr2D, footprint=neighborhood)
# 二次滤波作用是减少指纹
neighborhood = np.ones((2, 2))
local_max = maximum_filter(local_max, footprint=neighborhood) == arr2D
background = (arr2D == 0)
eroded_background = binary_erosion(background, structure=neighborhood,
border_value=1)
# Boolean mask of arr2D with True at peaks (Fixed deprecated boolean operator by changing '-' to '^')
detected_peaks = local_max + eroded_background
# extract peaks
amps = arr2D[detected_peaks]
# j代表时间轴,i代表频谱横轴
j, i = np.where(detected_peaks)
# filter peaks
amps = amps.flatten()
peaks = zip(i, j, amps)
# max_value = {}
# for coloum in i:
# if coloum not in max_value:
# temp = np.amax(arr2D[:, coloum])
# max_value[coloum] = temp * (2 - amp_min_ratio) if temp < 0 else temp * amp_min_ratio
peaks_filtered = filter(lambda x: x[2] > amp_min, peaks) # freq, time, amp
# get indices for frequency and time
frequency_idx = []
time_idx = []
for x in peaks_filtered:
frequency_idx.append(x[1])
time_idx.append(x[0])
# if plot:
# # scatter of the peaks
# fig, ax = plt.subplots()
#
# ax.imshow(arr2D)
# ax.scatter(time_idx, frequency_idx, c='k')
# ax.set_xlabel('Time')
# ax.set_ylabel('Frequency')
# ax.set_title("Spectrogram")
# plt.gca().invert_yaxis()
# plt.show()
return zip(frequency_idx, time_idx)抽取的主要思想是最大值滤波器,将短时傅里叶变换得到的数据转成每个时间段对应频谱的数组,然后设置滤波器的mask,因为窗函数选择的是hanning窗,所以mask形状选择和它类似的棱形形状,经过最大值滤波器过滤后得到的就是去燥后的信号以及对应的时间偏移,再经过声强最小值过滤一下就完成了。
4、将抽取的短时高能信号取哈希值入库
def generate_hashes(peaks, fan_value=DEFAULT_FAN_VALUE):
"""
Hash list structure:
sha1_hash[0:20] time_offset
[(e05b341a9b77a51fd26, 32), ... ]
"""
peaks = list(peaks)
if PEAK_SORT:
peaks.sort(key=itemgetter(1))
for i in range(len(peaks)):
# 不从0开始的原因是不同歌曲也会有很多相同频率,频率对更能体现歌曲特征
for j in range(1, fan_value):
if (i + j) < len(peaks):
freq1 = peaks[i][IDX_FREQ_I]
freq2 = peaks[i + j][IDX_FREQ_I]
t1 = peaks[i][IDX_TIME_J]
t2 = peaks[i + j][IDX_TIME_J]
t_delta = t2 - t1
if t_delta >= MIN_HASH_TIME_DELTA and t_delta <= MAX_HASH_TIME_DELTA:
content = "%s|%s|%s" % (str(freq1), str(freq2), str(t_delta))
h = hashlib.sha1(content.encode("utf-8"))
yield (h.hexdigest()[0:FINGERPRINT_REDUCTION], t1)为了匹配的准确率,高能信号取哈希值时可以设置一个fan_value来加强每个高能信号之间的连续性,即哈希值除了当前高能信号频率,还包括它之后的若干个高能信号频率以及时间差信息,频率对很重要,不过经过测试fan_value取3就能达到还不错的效果,并且每秒指纹80个。
5、特征匹配
基于上面四个步骤,我们得到了音乐的主要特征,接下来将要识别的音乐同样按照上面四个步骤取特征,然后从数据库查找所有相同hash值的数据,将匹配到的特征时间做个差值就是当前音频在原始音乐的偏移了,这也是听歌识曲里面不仅可以匹配到音乐还能定位到当前播放时间位置的原理了。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









