







1. Linux文件
一个正常可以运行的bin文件,直接进行反汇编以后实际有用的数据行数目*4就是文件ll出来的直接大小数目。一个可执行文件正常包含代码段、只读数据段、读写数据段、未初始化数据段、文件注释五个部分。
代码段(code 或text),代码段由各个函数产生,函数的每一个语句都最终编译成二进制代码。
只读数据段(rodata),被const修饰的初始值非0的全局变量。
读写数据段(data), .data段包含初始值非0的全局变量(不管静态还是非静态static)
未初始化数据段(bss),包含初始值为0或未初始的全局变量(不管有没有const修饰也不管是不是静态还是非静态)
文件注释(comment),主要是文件变量和文件相关的说明,这部分不计入实际bin文件大小的。
另外,局部变量则保存在栈中,它的生存周期仅在所在局部(即所定义的{}内)
#include <stdio.h>
#include <string.h>
#define N 10
int a_global;
int a1_global=0;
int a2_global=5;
static int b_global;
static int b1_global=0;
static int b2_global=6;
const int c_global;
const static int c1_global;
const static int c2_global=7;
int main()
{
const char c_local;
const char c1_local='A';
return 0;
}
asm.elf: file format elf32-littlearm
Disassembly of section .text:
00000000 <main>:
0: e1a0c00d mov ip, sp
4: e92dd800 stmdb sp!, {fp, ip, lr, pc}
8: e24cb004 sub fp, ip, #4 ; 0x4
c: e24dd004 sub sp, sp, #4 ; 0x4
10: e3a03041 mov r3, #65 ; 0x41
14: e54b300e strb r3, [fp, #-14]
18: e3a03000 mov r3, #0 ; 0x0
1c: e1a00003 mov r0, r3
20: e89da808 ldmia sp, {r3, fp, sp, pc}
Disassembly of section .data:
00000800 <__data_start>:
800: 00000005 andeq r0, r0, r5
00000804 <b2_global>:
804: 00000006 andeq r0, r0, r6
Disassembly of section .rodata:
00000024 <c2_global>:
24: 00000007 andeq r0, r0, r7
Disassembly of section .bss:
00000808 <a1_global>:
808: 00000000 andeq r0, r0, r0
0000080c <b1_global>:
80c: 00000000 andeq r0, r0, r0
00000810 <b_global>:
810: 00000000 andeq r0, r0, r0
00000814 <c1_global>:
814: 00000000 andeq r0, r0, r0
00000818 <c_global>:
818: 00000000 andeq r0, r0, r0
0000081c <a_global>:
81c: 00000000 andeq r0, r0, r0
Disassembly of section .comment:
00000000 <.comment>:
0: 43434700 cmpmi r3, #0 ; 0x0
4: 4728203a undefined
8: 2029554e eorcs r5, r9, lr, asr #10
c: 2e342e33 mrccs 14, 1, r2, cr4, cr3, {1}
10: Address 0x10 is out of bounds.2. 程序运行
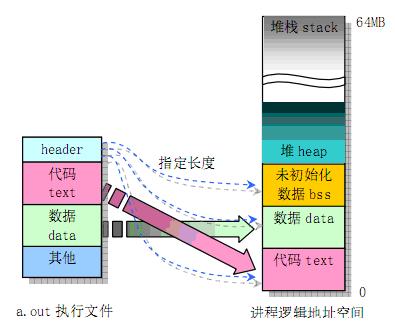
堆(heap) :堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc/free等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张)/释放的内存从堆中被剔除(堆被缩减)
栈(stack) :栈又称堆栈, 存放程序的 局部变量 (但不包括static声明的变量, static 意味着 在数据段中 存放变量)。除此以外,在函数被调用时,栈用来传递参数和返回值。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。储动态内存分配,需要程序员手工分配,手工释放
如果程序是裸机驱动开发,程序是通过下载工具加载到单板的flash上面,不像系统编程本身编写链接出来的文件就是在系统管理的flash空间中。在嵌入式中,文件组成格式和加载格式是一致,只是偏移地址不一样。程序运行中逻辑程序最大的一个问题是代码的重定位,设计复杂的代码重定位流程。但是实际系统文件运行时,由系统加载文件到SDRAM中,一般也不需要复杂的代码重定位处理流程。
3. RT-Thread实例说明
RT-Thread 程序内存分布
一般 MCU 包含的存储空间有:片内 Flash 与片内 RAM,RAM 相当于内存,Flash 相当于硬盘。编译器会将一个程序分类为好几个部分,分别存储在 MCU 不同的存储区。
Keil 工程在编译完之后,会有相应的程序所占用的空间提示信息,如下所示:
linking...
Program Size: Code=48008 RO-data=5660 RW-data=604 ZI-data=2124
After Build - User command \#1: fromelf --bin.\\build\\rtthread-stm32.axf--output rtthread.bin
".\\build\\rtthread-stm32.axf" - 0 Error(s), 0 Warning(s).
Build Time Elapsed: 00:00:07复制错误复制成功上面提到的 Program Size 包含以下几个部分:
1)Code:代码段,存放程序的代码部分;
2)RO-data:只读数据段,存放程序中定义的常量;
3)RW-data:读写数据段,存放初始化为非 0 值的全局变量;
4)ZI-data(bss数据段):0 数据段,存放未初始化的全局变量及初始化为 0 的变量;
编译完工程会生成一个.map 的文件,该文件说明了各个函数占用的尺寸和地址,在文件的最后几行也说明了上面几个字段的关系:
Total RO Size (Code + RO Data) 53668 ( 52.41kB)
Total RW Size (RW Data + ZI Data) 2728 ( 2.66kB)
Total ROM Size (Code + RO Data + RW Data) 53780 ( 52.52kB)复制错误复制成功1)RO Size 包含了 Code 及 RO-data,表示程序占用 Flash 空间的大小;
2)RW Size 包含了 RW-data 及 ZI-data,表示运行时占用的 RAM 的大小;
3)ROM Size 包含了 Code、RO-data 以及 RW-data,表示烧写程序所占用的 Flash 空间的大小;
程序运行之前,需要有文件实体被烧录到 STM32 的 Flash 中,一般是 bin 或者 hex 文件,该被烧录文件称为可执行映像文件。如下图左边部分所示,是可执行映像文件烧录到 STM32 后的内存分布,它包含 RO 段和 RW 段两个部分:其中 RO 段中保存了 Code、RO-data 的数据,RW 段保存了 RW-data 的数据,由于 ZI-data 都是 0,所以未包含在映像文件中。
STM32 在上电启动之后默认从 Flash 启动,启动之后会将 RW 段中的 RW-data(初始化的全局变量)搬运到 RAM 中,但不会搬运 RO 段,即 CPU 的执行代码从 Flash 中读取,另外根据编译器给出的 ZI 地址和大小分配出 ZI 段,并将这块 RAM 区域清零。
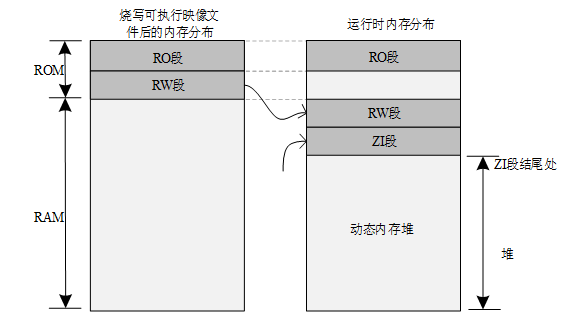
其中动态内存堆为未使用的 RAM 空间,应用程序申请和释放的内存块都来自该空间。当然RT-Thread内部有几种不同类型的算法来完成堆数据空间的管理,细节查看rt-thread-------内存管理(内存堆)-CSDN博客
如下面的例子:
rt_uint8_t* msg_ptr;
msg_ptr = (rt_uint8_t*) rt_malloc (128);
rt_memset(msg_ptr, 0, 128);复制错误复制成功代码中的 msg_ptr 指针指向的 128 字节内存空间位于动态内存堆空间中。
而一些全局变量则是存放于 RW 段和 ZI 段中,RW 段存放的是具有初始值的全局变量(而常量形式的全局变量则放置在 RO 段中,是只读属性的),ZI 段存放的系统未初始化的全局变量,如下面的例子:
#include <rtthread.h>
const static rt_uint32_t sensor_enable = 0x000000FE;
rt_uint32_t sensor_value;
rt_bool_t sensor_inited = RT_FALSE;
void sensor_init()
{
/* ... */
}复制错误复制成功sensor_value 存放在 ZI 段中,系统启动后会自动初始化成零(由用户程序或编译器提供的一些库函数初始化成零)。sensor_inited 变量则存放在 RW 段中,而 sensor_enable 存放在 RO 段中。
4. 堆栈空间差异
文章目录
0.前言
1.程序内存分区中的堆与栈
1.1 栈简介
1.2 堆简介
1.3 堆与栈区别
2.数据结构中的堆与栈
2.1 栈简介
2.2 堆简介
2.2.1 堆的性质
2.2.2 堆的基本操作
2.2.3 堆操作实现
2.2.4 堆的具体应用——堆排序
参考文献
杂注
0.前言
堆(Heap)与栈(Stack)是开发人员必须面对的两个概念,在理解这两个概念时,需要放到具体的场景下,因为不同场景下,堆与栈代表不同的含义。一般情况下,有两层含义:
(1)程序内存布局场景下,堆与栈表示两种内存管理方式;
(2)数据结构场景下,堆与栈表示两种常用的数据结构。
1.程序内存分区中的堆与栈
1.1 栈简介
栈由操作系统自动分配释放 ,用于存放函数的参数值、局部变量等,其操作方式类似于数据结构中的栈。参考如下代码:
int main() {
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
}
1
2
3
4
5
其中函数中定义的局部变量按照先后定义的顺序依次压入栈中,也就是说相邻变量的地址之间不会存在其它变量。栈的内存地址生长方向与堆相反,由高到底,所以后定义的变量地址低于先定义的变量,比如上面代码中变量 s 的地址小于变量 b 的地址,p2 地址小于 s 的地址。栈中存储的数据的生命周期随着函数的执行完成而结束。
1.2 堆简介
堆由开发人员分配和释放, 若开发人员不释放,程序结束时由 OS 回收,分配方式类似于链表。参考如下代码:
int main() {
// C 中用 malloc() 函数申请
char* p1 = (char *)malloc(10);
cout<<(int*)p1<<endl; //输出:00000000003BA0C0
// 用 free() 函数释放
free(p1);
// C++ 中用 new 运算符申请
char* p2 = new char[10];
cout << (int*)p2 << endl; //输出:00000000003BA0C0
// 用 delete 运算符释放
delete[] p2;
}
其中 p1 所指的 10 字节的内存空间与 p2 所指的 10 字节内存空间都是存在于堆。堆的内存地址生长方向与栈相反,由低到高,但需要注意的是,后申请的内存空间并不一定在先申请的内存空间的后面,即 p2 指向的地址并不一定大于 p1 所指向的内存地址,原因是先申请的内存空间一旦被释放,后申请的内存空间则会利用先前被释放的内存,从而导致先后分配的内存空间在地址上不存在先后关系。堆中存储的数据若未释放,则其生命周期等同于程序的生命周期。
关于堆上内存空间的分配过程,首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确地释放本内存空间。由于找到的堆节点的大小不一定正好等于申请的大小,系统会自动地将多余的那部分重新放入空闲链表。
1.3 堆与栈区别
堆与栈实际上是操作系统对进程占用的内存空间的两种管理方式,主要有如下几种区别:
(1)管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;
(2)空间大小不同。每个进程拥有的栈大小要远远小于堆大小。理论上,进程可申请的堆大小为虚拟内存大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
(3)生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(4)分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有 2 种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca()函数分配,但是栈的动态分配和堆是不同的,它的动态分配是由操作系统进行释放,无需我们手工实现。
(5)分配效率不同。栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。
(6)存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。当主函数调用另外一个函数的时候,要对当前函数执行断点进行保存,需要使用栈来实现,首先入栈的是主函数下一条语句的地址,即扩展指针寄存器的内容(EIP),然后是当前栈帧的底部地址,即扩展基址指针寄存器内容(EBP),再然后是被调函数的实参等,一般情况下是按照从右向左的顺序入栈,之后是被调函数的局部变量,注意静态变量是存放在数据段或者BSS段,是不入栈的。出栈的顺序正好相反,最终栈顶指向主函数下一条语句的地址,主程序又从该地址开始执行。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
从以上可以看到,堆和栈相比,由于大量malloc()/free()或new/delete的使用,容易造成大量的内存碎片,并且可能引发用户态和核心态的切换,效率较低。栈相比于堆,在程序中应用较为广泛,最常见的是函数的调用过程由栈来实现,函数返回地址、EBP、实参和局部变量都采用栈的方式存放。虽然栈有众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,主要还是用堆。
无论是堆还是栈,在内存使用时都要防止非法越界,越界导致的非法内存访问可能会摧毁程序的堆、栈数据,轻则导致程序运行处于不确定状态,获取不到预期结果,重则导致程序异常崩溃,这些都是我们编程时与内存打交道时应该注意的问题。
2.数据结构中的堆与栈
数据结构中,堆与栈是两个常见的数据结构,理解二者的定义、用法与区别,能够利用堆与栈解决很多实际问题。
2.1 栈简介
栈是一种运算受限的线性表,其限制是指只仅允许在表的一端进行插入和删除操作,这一端被称为栈顶(Top),相对地,把另一端称为栈底(Bottom)。把新元素放到栈顶元素的上面,使之成为新的栈顶元素称作进栈、入栈或压栈(Push);把栈顶元素删除,使其相邻的元素成为新的栈顶元素称作出栈或退栈(Pop)。这种受限的运算使栈拥有“先进后出”的特性(First In Last Out),简称 FILO。
栈分顺序栈和链式栈两种。栈是一种线性结构,所以可以使用数组或链表(单向链表、双向链表或循环链表)作为底层数据结构。使用数组实现的栈叫做顺序栈,使用链表实现的栈叫做链式栈,二者的区别是顺序栈中的元素地址连续,链式栈中的元素地址不连续。
栈的结构如下图所示:
栈的基本操作包括初始化、判断栈是否为空、入栈、出栈以及获取栈顶元素等。下面以顺序栈为例,使用 C++ 给出一个简单的实现。
#include<stdio.h>
#include<malloc.h>
#define DataType int
#define MAXSIZE 1024
struct SeqStack {
DataType data[MAXSIZE];
int top;
};
//栈初始化,成功返回栈对象指针,失败返回空指针NULL
SeqStack* initSeqStack() {
SeqStack* s=(SeqStack*)malloc(sizeof(SeqStack));
if(!s) {
printf("空间不足\n");
return NULL;
} else {
s->top = -1;
return s;
}
}
//判断栈是否为空
bool isEmptySeqStack(SeqStack* s) {
if (s->top == -1)
return true;
else
return false;
}
//入栈,返回-1失败,0成功
int pushSeqStack(SeqStack* s, DataType x) {
if(s->top == MAXSIZE-1)
{
return -1;//栈满不能入栈
} else {
s->top++;
s->data[s->top] = x;
return 0;
}
}
//出栈,返回-1失败,0成功
int popSeqStack(SeqStack* s, DataType* x) {
if(isEmptySeqStack(s)) {
return -1;//栈空不能出栈
} else {
*x = s->data[s->top];
s->top--;
return 0;
}
}
//取栈顶元素,返回-1失败,0成功
int topSeqStack(SeqStack* s,DataType* x) {
if (isEmptySeqStack(s))
return -1; //栈空
else {
*x=s->data[s->top];
return 0;
}
}
//打印栈中元素
int printSeqStack(SeqStack* s) {
int i;
printf("当前栈中的元素:\n");
for (i = s->top; i >= 0; i--)
printf("%4d",s->data[i]);
printf("\n");
return 0;
}
//test
int main() {
SeqStack* seqStack=initSeqStack();
if(seqStack) {
//将4、5、7分别入栈
pushSeqStack(seqStack,4);
pushSeqStack(seqStack,5);
pushSeqStack(seqStack,7);
//打印栈内所有元素
printSeqStack(seqStack);
//获取栈顶元素
DataType x=0;
int ret=topSeqStack(seqStack,&x);
if(0==ret) {
printf("top element is %d\n",x);
}
//将栈顶元素出栈
ret=popSeqStack(seqStack,&x);
if(0==ret) {
printf("pop top element is %d\n",x);
}
}
return 0;
}
运行上面的程序,输出结果:
当前栈中的元素:
7 5 4
top element is 7
pop top element is 7
1
2
3
4
2.2 堆简介
2.2.1 堆的性质
堆是一种常用的树形结构,是一种特殊的完全二叉树,当且仅当满足所有节点的值总是不大于或不小于其父节点的值的完全二叉树被称之为堆。堆的这一特性称之为堆序性。因此,在一个堆中,根节点是最大(或最小)节点。如果根节点最小,称之为小顶堆(或小根堆),如果根节点最大,称之为大顶堆(或大根堆)。堆的左右孩子没有大小的顺序。下面是一个小顶堆示例:
堆的存储一般都用数组来存储堆,i节点的父节点下标就为( i – 1 ) / 2 (i – 1) / 2(i–1)/2。它的左右子节点下标分别为 2 ∗ i + 1 2 * i + 12∗i+1 和 2 ∗ i + 2 2 * i + 22∗i+2。如第0个节点左右子节点下标分别为1和2。
2.2.2 堆的基本操作
(1)建立
以最小堆为例,如果以数组存储元素时,一个数组具有对应的树表示形式,但树并不满足堆的条件,需要重新排列元素,可以建立“堆化”的树。
(2)插入
将一个新元素插入到表尾,即数组末尾时,如果新构成的二叉树不满足堆的性质,需要重新排列元素,下图演示了插入15时,堆的调整。
(3)删除。
堆排序中,删除一个元素总是发生在堆顶,因为堆顶的元素是最小的(小顶堆中)。表中最后一个元素用来填补空缺位置,结果树被更新以满足堆条件。
2.2.3 堆操作实现
(1)插入代码实现
每次插入都是将新数据放在数组最后。可以发现从这个新数据的父节点到根节点必然为一个有序的数列,现在的任务是将这个新数据插入到这个有序数据中,这就类似于直接插入排序中将一个数据并入到有序区间中,这是节点“上浮”调整。不难写出插入一个新数据时堆的调整代码:
// 新加入i节点,其父节点为(i-1)/2
// 参数:a:数组,i:新插入元素在数组中的下标
void minHeapFixUp(int a[], int i) {
int j, temp;
temp = a[i];
j = (i-1)/2; //父节点
while (j >= 0 && i != 0) {
if (a[j] <= temp)//如果父节点不大于新插入的元素,停止寻找
break;
a[i]=a[j]; //把较大的子节点往下移动,替换它的子节点
i = j;
j = (i-1)/2;
}
a[i] = temp;
}
因此,插入数据到最小堆时:
// 在最小堆中加入新的数据data
// a:数组,index:插入的下标,
void minHeapAddNumber(int a[], int index, int data) {
a[index] = data;
minHeapFixUp(a, index);
}
(2)删除代码实现
按照堆删除的说明,堆中每次都只能删除第0个数据。为了便于重建堆,实际的操作是将数组最后一个数据与根节点交换,然后再从根节点开始进行一次从上向下的调整。
调整时先在左右儿子节点中找最小的,如果父节点不大于这个最小的子节点说明不需要调整了,反之将最小的子节点换到父节点的位置。此时父节点实际上并不需要换到最小子节点的位置,因为这不是父节点的最终位置。但逻辑上父节点替换了最小的子节点,然后再考虑父节点对后面的节点的影响。堆元素的删除导致的堆调整,其整个过程就是将根节点进行“下沉”处理。下面给出代码:
// a为数组,len为节点总数;从index节点开始调整,index从0开始计算index其子节点为 2*index+1, 2*index+2;len/2-1为最后一个非叶子节点
void minHeapFixDown(int a[],int len,int index) {
if(index>(len/2-1))//index为叶子节点不用调整
return;
int tmp=a[index];
lastIndex=index;
while(index<=len/2-1) //当下沉到叶子节点时,就不用调整了
{
// 如果左子节点小于待调整节点
if(a[2*index+1]<tmp) {
lastIndex = 2*index+1;
}
//如果存在右子节点且小于左子节点和待调整节点
if(2*index+2<len && a[2*index+2]<a[2*index+1]&& a[2*index+2]<tmp) {
lastIndex=2*index+2;
}
//如果左右子节点有一个小于待调整节点,选择最小子节点进行上浮
if(lastIndex!=index) {
a[index]=a[lastIndex];
index=lastIndex;
} else break; //否则待调整节点不用下沉调整
}
a[lastIndex]=tmp; //将待调整节点放到最后的位置
}
根据堆删除的下沉思想,可以有不同版本的代码实现,以上是和孙凛同学一起讨论出的一个版本,在这里感谢他的参与,读者可另行给出。个人体会,这里建议大家根据对堆调整过程的理解,写出自己的代码,切勿看示例代码去理解算法,而是理解算法思想写出代码,否则很快就会忘记。
(3)建堆
有了堆的插入和删除后,再考虑下如何对一个数据进行堆化操作。要一个一个的从数组中取出数据来建立堆吧,不用!先看一个数组,如下图:
很明显,对叶子节点来说,可以认为它已经是一个合法的堆了即20,60, 65, 4, 49都分别是一个合法的堆。只要从A[4]=50开始向下调整就可以了。然后再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分别作一次向下调整操作就可以了。下图展示了这些步骤:
写出堆化数组的代码:
// 建立最小堆
// a:数组,n:数组长度
void makeMinHeap(int a[], int n) {
for (int i = n/2-1; i >= 0; i--)
minHeapFixDown(a, i, n);
}
2.2.4 堆的具体应用——堆排序
堆排序(Heapsort)是堆的一个经典应用,有了上面对堆的了解,不难实现堆排序。由于堆也是用数组来存储的,故对数组进行堆化后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n - 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。
因此,完成堆排序并没有用到前面说明的插入操作,只用到了建堆和节点向下调整的操作,堆排序的操作如下:
// array:待排序数组,len:数组长度
void heapSort(int array[],int len) {
// 建堆
makeMinHeap(array,len);
// 最后一个叶子节点和根节点交换,并进行堆调整,交换次数为len-1次
for(int i=len-1;i>0;--i) {
//最后一个叶子节点交换
array[i]=array[i]+array[0];
array[0]=array[i]-array[0];
array[i]=array[i]-array[0];
// 堆调整
minHeapFixDown(array, 0, len-i-1);
}
}
(1)稳定性。堆排序是不稳定排序。
(2)堆排序性能分析。由于每次重新恢复堆的时间复杂度为O(logN),共N-1次堆调整操作,再加上前面建立堆时N/2次向下调整,每次调整时间复杂度也为O(logN)。两次操作时间复杂度相加还是O(NlogN),故堆排序的时间复杂度为O(NlogN)。
最坏情况:如果待排序数组是有序的,仍然需要O(NlogN)复杂度的比较操作,只是少了移动的操作;
最好情况:如果待排序数组是逆序的,不仅需要O(NlogN)复杂度的比较操作,而且需要O(NlogN)复杂度的交换操作,总的时间复杂度还是O(NlogN)。
因此,堆排序和快速排序在效率上是差不多的,但是堆排序一般优于快速排序的重要一点是数据的初始分布情况对堆排序的效率没有大的影响。
————————————————
版权声明:本文为CSDN博主「恋喵大鲤鱼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/K346K346/article/details/80849966/
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/u012294613/article/details/126319401















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









