







 本文介绍了HierarchicalDeepStereoMatching在处理高分辨率图像的立体匹配方法,通过encoder-decoder结构结合SPP提升感受野,实现高质量特征提取。采用金字塔式代价聚合和多分辨率损失函数进行训练,并利用数据增强处理标定误差、光照变化和遮挡区域。实验结果显示,该方法能产生出色的三维点云效果,代码开源并可复现。
本文介绍了HierarchicalDeepStereoMatching在处理高分辨率图像的立体匹配方法,通过encoder-decoder结构结合SPP提升感受野,实现高质量特征提取。采用金字塔式代价聚合和多分辨率损失函数进行训练,并利用数据增强处理标定误差、光照变化和遮挡区域。实验结果显示,该方法能产生出色的三维点云效果,代码开源并可复现。
论文
Hierarchical Deep Stereo Matching on High-resolution Images
摘要
本篇文章本人在看的时候,感觉特别像StereoNet和StereoDRNet。high-res-stereo强调了其在处理高分辨率影像的能力,并且也得到了非常漂亮的效果;另外,就是这篇文章也公开了代码,目前从issue的情况来看,论文的结果是可复现的!
方法
以下展示了high-res-stereo的网络结构,其实还是特征提取和代价回归两部分。
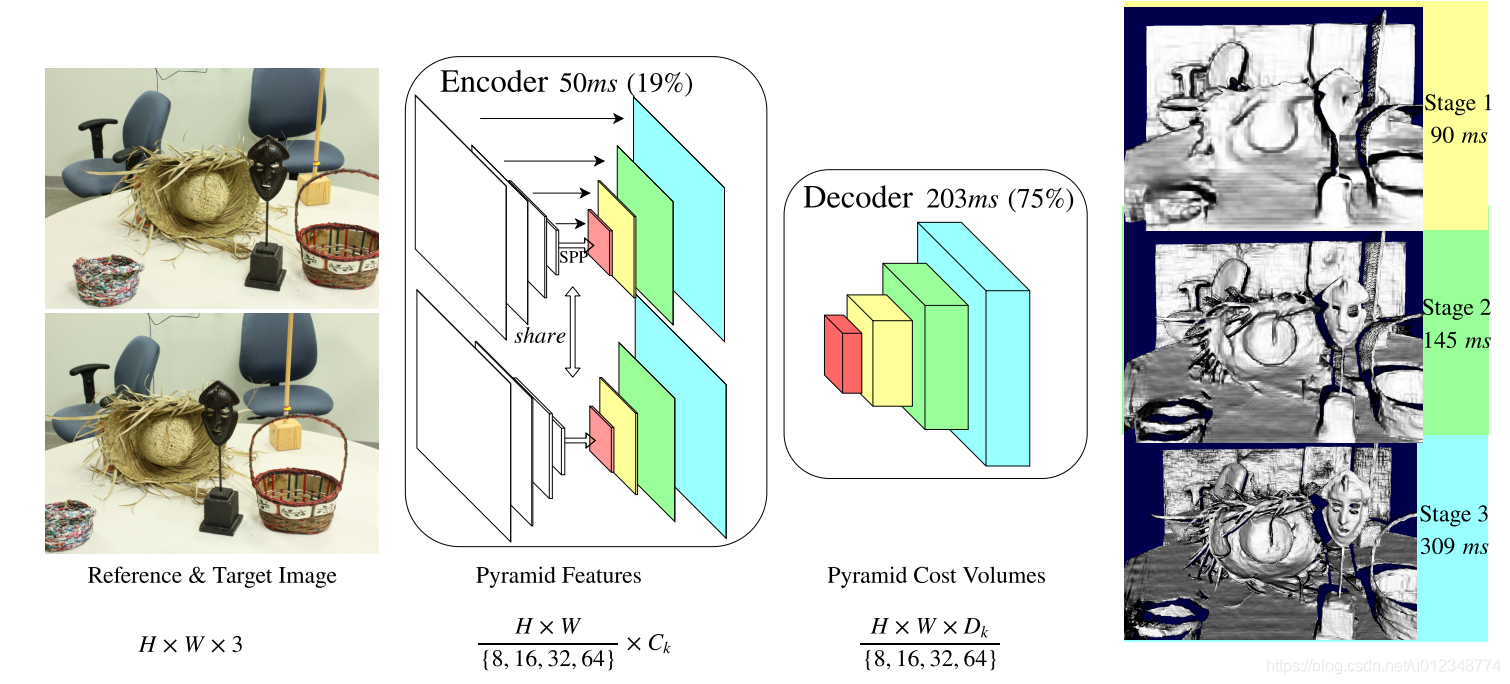
1. 特征提取
high-res-stereo的特征提取与其他文章还是有一点不同的,其应用了一个encoder-decoder结构,并在最中间用了一个SPP来提高感受野。目前看到的大部分论文,都是只有一个encoder,并没有decoder;本篇文章的意思是,加一个decoder可以保证高分辨特征的质量。
2. 代价聚合
金字塔式的代价聚合已经不是什么新鲜事了,high-res-stereo也是这么操作的。先用低分辨率的特征构建低分辨率的cost volumn,然后简单的三维卷积一下上采样(三线性插值)得到较高分辨率的cost volumn,其网络结构如下。总之,就是为了扩大感受野,不择手段!
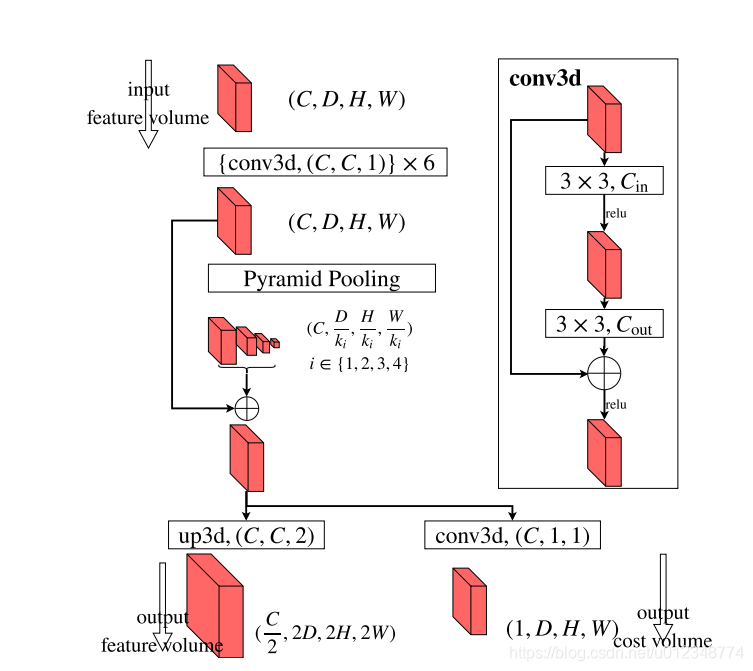
训练
1. loss
由于视差是从低分辨率到高分辨率逐步生成,所以loss肯定也是多分辨率的。
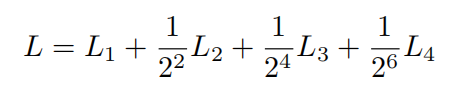
2.数据增强
本篇文章的数据增强,还是非常有意思的,总的来说有以下三个:
- 考虑标定误差,人为增加误差
- 考虑光照变化
- 考虑遮挡区域,随机遮挡一些区域
结果
这篇文章的结果是非常让我震惊的。对于我这种测量出身的人来说,视差图其实没啥用,三维点云效果好不好最重要。后续一定要跑代码的!


















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









