







实际应用中,我们的训练数据中只有少数的图像有分类标签,大部分是没有分类标签的,所以我们要利用其它已有的信息来进行分类,本文就是针对解决这样的问题而提出的方法。
文章中提出的方法主要有两个步骤:
1、采用已经有标签(确定分类)的图像训练分类器,利用已有的图像内容和关键字。采用多核训练,结合两种核,第一种核是基于图像内容,第二个核是基于关键字。这个MKL分类器是用来预测训练数据中没有标签但是有关键字的图像的标签。
2、采用已有标签的图像以及分类器在没有标签图像上的输出来训练第二个分类器,这个分类器将以视觉特征作为输入。
svm分类函数形式如下:
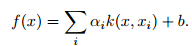
sign(f(x))可得到图像的分类。我们将b设置为0,















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









