







https://github.com/NVlabs/EmerNeRF
该方法是Nvidia提出的,其亮点是不需要额外的2D、3Dbox先验,可以自动解耦动静field。
核心思想:
1. 动、静filed都用hash grid编码,动态filed比静态多了时间t,静态的hash编码输入是(x,y,z),动态是(x,y,z,t)。
2. 使用flow融合多帧的特征,预测当前时刻的点的前向和后向的flow,最后的动态Feature是0.25pre+0.5+0.25next
3. 用3个head分别预测正常物体、天空和阴影。
3.1 SCENE REPRESENTATIONS
1 Scene decomposition
为了实现高效的场景解耦,把4D场景分解为静态场和动态场,两者都分别由可学习的hash grid(instant NGP) Hs和hd表示。(注,下标s和d分别表示static和dynamic,下文所有表示都是此含义)
这种解耦为与时间无关的特征 hs = Hs(x) 和时变特征 hd = Hd(x, t) 提供了一种灵活紧凑的 4D 场景表示,其中 x = (x, y, z) 是查询点的 3D 位置,t 表示其时间步长。这些特征通过轻量级 MLP进一步转换为动态和静态的feature(gs和gd),和用于预测每个点的密度 (σs 和 σd)。

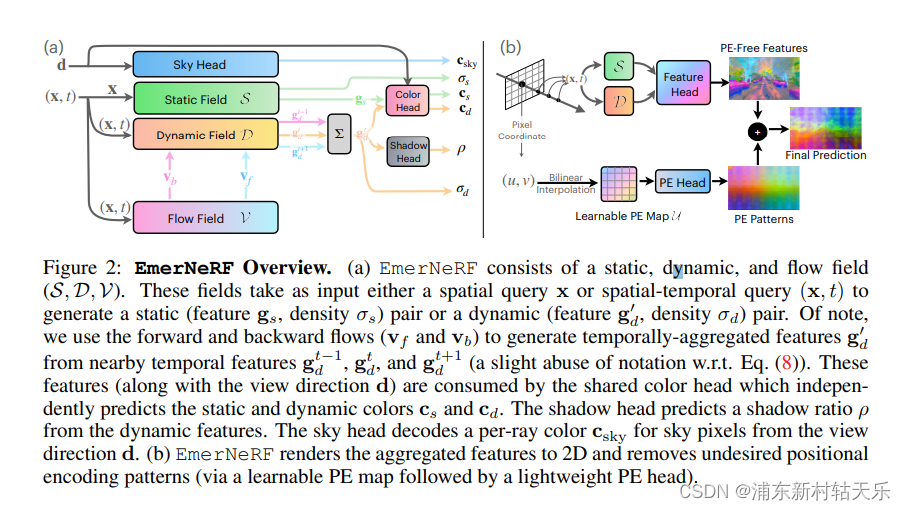
所以这一步得到每个3D点的feature和密度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









