









在北京时间9月13日凌晨,OpenAI正式发布了一系列全新的AI大模型【o1-preview 和 o1-mini】,专门针对复杂问题的解决。这一发布标志着一次重要的突破,新模型能够实现复杂的推理能力,通用模型在解决科学、代码和数学等领域中的难题方面,表现出了比之前模型更强的能力。
4o和o1系列模型价格和上下文长度
| 对比项 | OpenAI o1-preview | OpenAI o1-mini | GPT-4o | GPT-4o mini |
| 价格(百万 tokens) | 输入:15.00 | 输入:3.00 | 输入:5.00 | 输入:0.150 |
| 上下文长度 | 128,000 tokens | 128,000 tokens | 128,000 tokens | 128,000 tokens |
o1-preview与o1-mini特性
o1-preview
作为该系列的主打模型,o1-preview 被设计用于解决复杂推理任务,能够处理科学、编码和数学领域中更复杂的问题。根据 OpenAI 的研究,o1-preview 在竞争性编程问题(Codeforces)上达到了89%的排名,在美国数学奥林匹克预选赛(AIME)中位列全美前500名学生之列,并在物理学、生物学和化学问题的基准测试(GPQA)中超越了人类博士级别的准确率。这使得 o1-preview 成为一个适合需要深入推理的应用场景的强大工具。
o1-mini
o1-mini 是该系列的一个更加经济、高效的版本,尤其擅长 STEM(科学、技术、工程、数学)领域,特别是数学和编程。尽管性能不及 o1-preview,但在一些评价基准(如 AIME 和 Codeforces)上,o1-mini 的表现几乎与 o1-preview 相当。因此,对于那些需要推理但不需要广泛世界知识的应用场景,o1-mini 提供了一种更快速、成本更低的解决方案。
o1 模型创造了多项历史记录
首先,o1 模型正是之前 OpenAI 从山姆・奥特曼到科学家们一直高调宣传的“草莓大模型”。它具备真正的通用推理能力,在一系列高难基准测试中表现出色,相较于 GPT-4o 有显著提升,使大模型的上限从“难以达到”直接跃升至优秀水平,未经专门训练即可在数学奥赛中夺得金牌,甚至在博士级别的科学问答中超越人类专家。
OpenAI o1 工作原理
在技术博客《Learning to Reason with LLMs》中,OpenAI 详细介绍了 o1 系列语言模型的技术细节。
OpenAI o1 是一种通过强化学习训练来执行复杂推理任务的新型语言模型。其特点是,o1 在回答问题之前会进行思考——在响应用户之前会生成一条长长的内部思维链。
这意味着该模型在作出反应前,需要像人类一样花费更多时间来思考问题。通过训练,它们学会了如何改善自己的思维过程,尝试不同的策略,并识别和纠正错误。
在 OpenAI 的测试中,该系列后续更新的模型在物理、化学和生物学这些具有挑战性的基准任务上表现得与博士生相似。同时,OpenAI 还发现它在数学和编码方面表现出色。
在国际数学奥林匹克(IMO)资格考试中,GPT-4o 仅正确解答了 13% 的问题,而 o1 模型则正确解答了 83% 的问题。
模型的编码能力也在比赛中得到了验证,在 Codeforces 比赛中排名达到了89%。
OpenAI 表示,作为早期模型,o1 还不具备 ChatGPT 的许多实用功能,例如浏览网页获取信息以及上传文件和图片。
然而,对于复杂的推理任务而言,这是一个重大的进步,代表了人工智能能力的新高度。因此,OpenAI 将计数器重置为 1,并将这个系列的模型命名为 OpenAI o1。
关键在于,OpenAI 的大规模强化学习算法教会模型如何在高度有效的数据训练过程中利用其「思维链」进行高效思考。简单来说,这类似于强化学习中的 Scaling Law。
这两部分在我的【AI 大模型全栈通识课】中有详细介绍
分别为:
-
第一单元的《🌈 1-5人工智能的本质》
-
第二单元的《🎯 2-2-4 COT 思维链》】
课程介绍:https://www.yuque.com/lhyyh/agi/introduce
OpenAI 发现,随着强化学习的增多(训练期间的计算量增加)和思考时间的延长(测试期间的计算时间增加),o1 模型的性能不断提升。此外,扩展这种方法的限制与大模型预训练的限制截然不同,OpenAI 仍在深入研究这个领域。
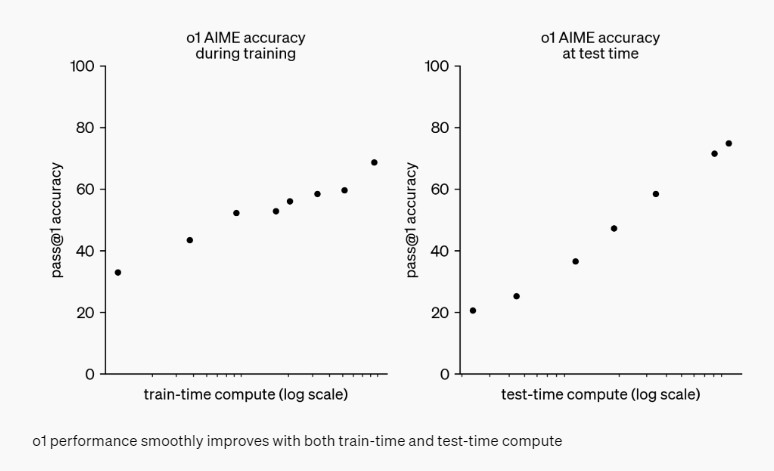
评估
为了展示 o1 相较于 GPT-4o 的推理性能提升,OpenAI 对 o1 模型进行了多项人类考试和机器学习基准测试。实验结果显示,o1 在绝大多数推理任务上的表现显著优于 GPT-4o。
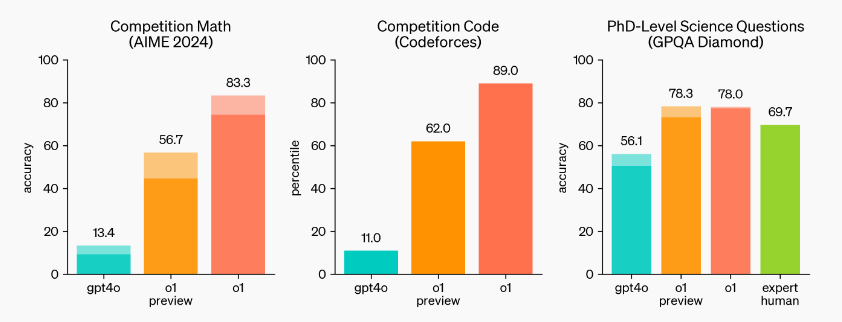
o1 在具有挑战性的推理基准上比 GPT-4o 有了很大的改进。
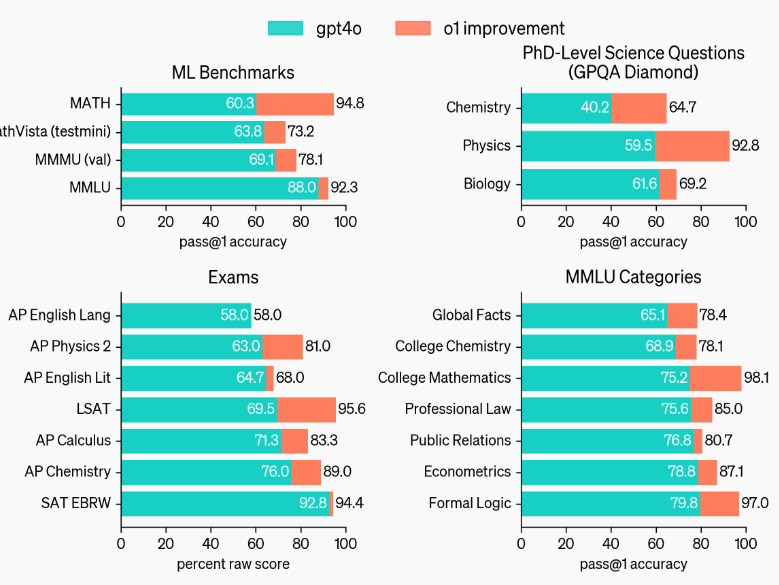
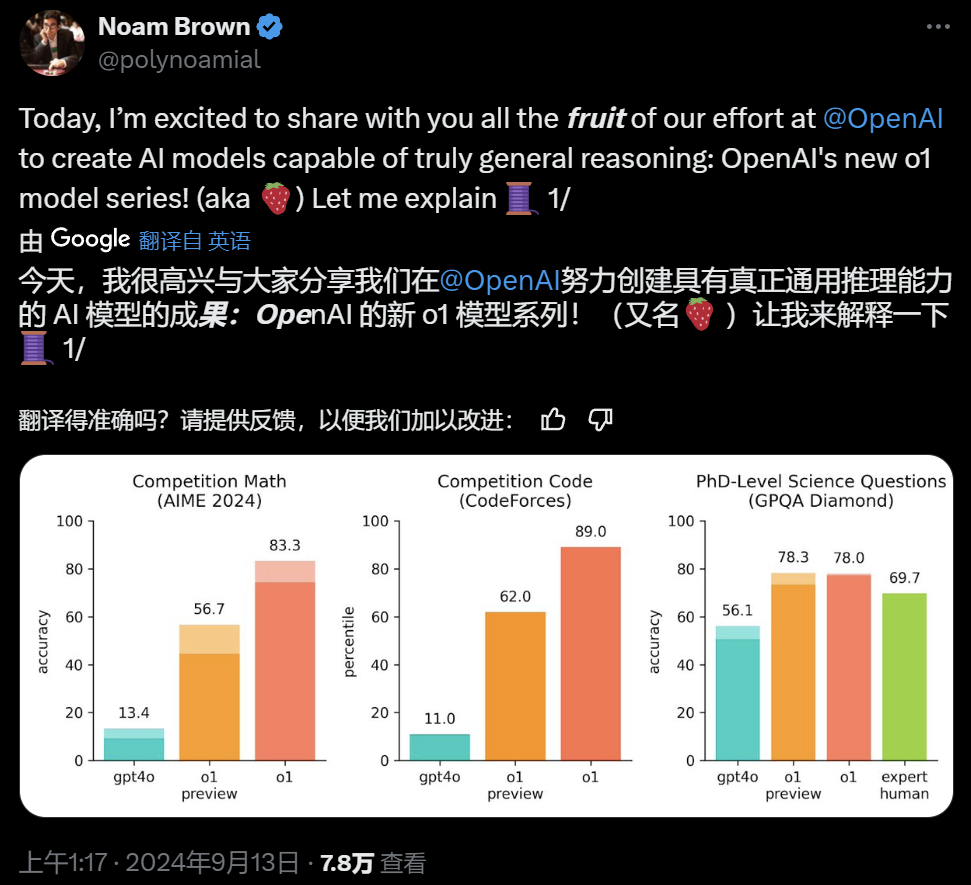
在许多要求高度推理能力的基准测试中,o1 的表现堪比人类专家。最近的前沿模型在 MATH 和 GSM8K 测试中表现出色,以至于这些测试在区分模型方面已不再具备挑战。因此,OpenAI 在 AIME 考试中评估了 o1 的数学成绩,这是一项旨在测试美国最聪明高中数学学生的考试。
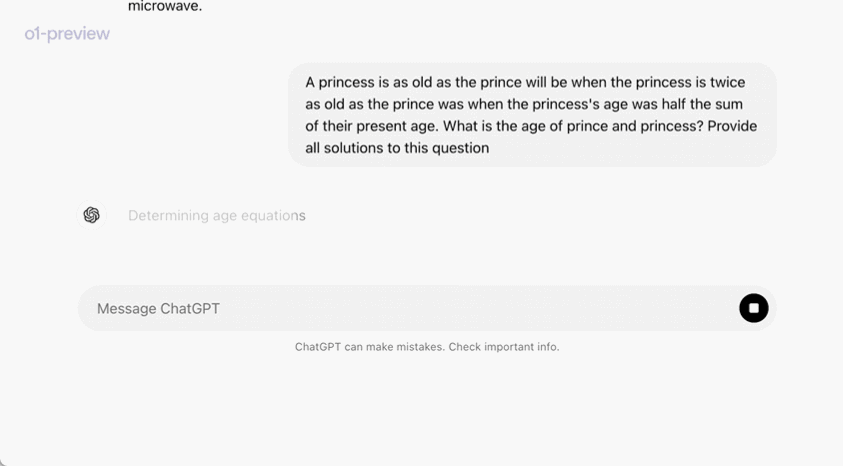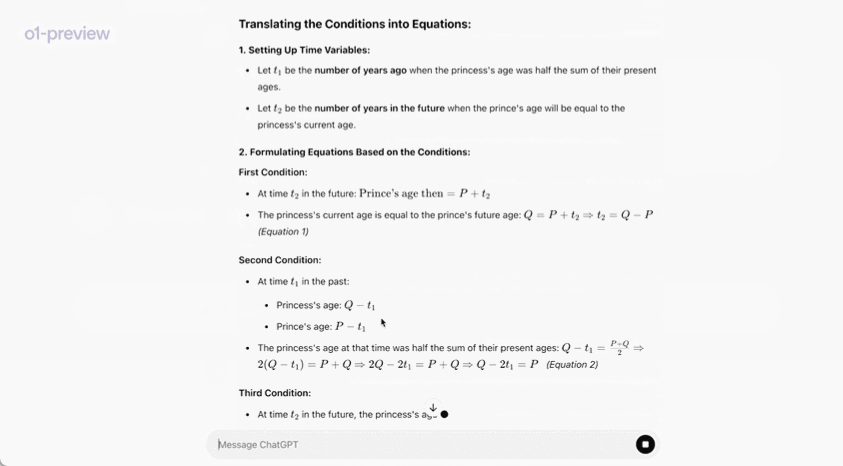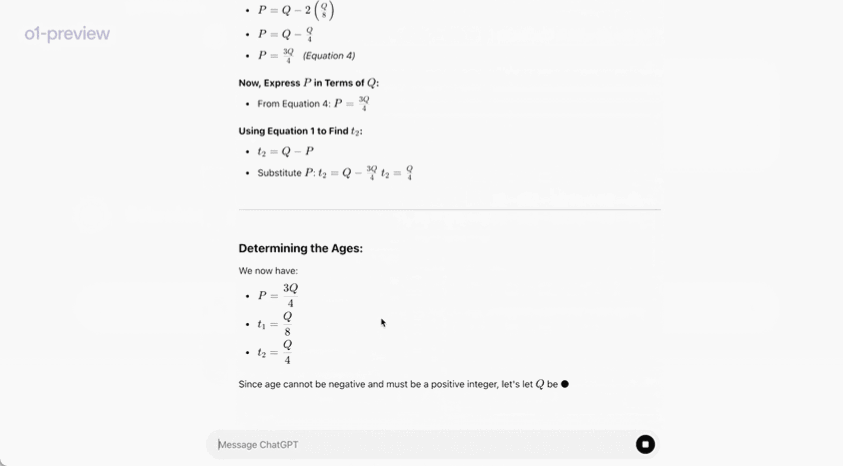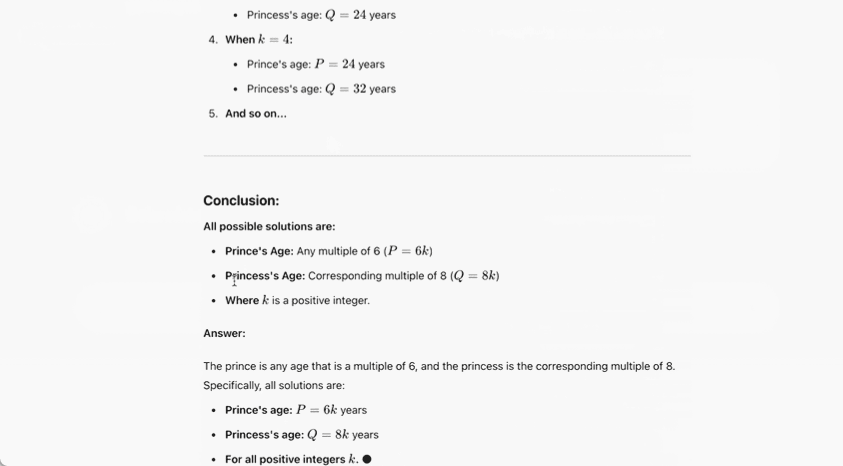
在一个官方演示中,o1-preview 解答了一个非常困难的推理问题:当公主的年龄是王子的两倍时,公主的年龄与王子一样大,而公主的年龄是他们现在年龄总和的一半。王子和公主的年龄是多少?提供这个问题的所有解。
在 2024 年的 AIME 考试中,GPT-4o 平均仅解决了 12% (1.8/15) 的题目,而 o1 在每道题只有一个样本的情况下,正确率平均为 74% (11.1/15)。在 64 个样本之间达成一致的情况下,这一比例提升至 83% (12.5/15),当使用学习的评分函数对 1000 个样本重新排序时,正确率进一步提高到 93% (13.9/15)。这一成绩足以跻身全美前 500 名,并超过了美国数学奥林匹克竞赛的分数线。
此外,OpenAI 还在 GPQA Diamond 基准上评估了 o1,这是一项用于测试化学、物理和生物学专业知识的高难度智力基准。为了与人类进行对比,OpenAI 邀请了拥有博士学位的专家来回答 GPQA Diamond 基准问题。
实验结果显示:o1 的表现超越了人类专家,成为第一个在该基准测试中取得如此成绩的模型。
这些结果并不意味着 o1 在所有领域都超过了博士级别的专家——只是它在某些博士应该解决的问题上表现得更为出色。在其他多个机器学习基准测试中,o1 也实现了新的 SOTA(最先进技术)。
在启用视觉感知能力后,o1 在 MMMU 基准上的得分为 78.2%,成为第一个与人类专家水平相当的模型。同时,o1 在 57 个 MMLU 子类别中的 54 个中表现优于 GPT-4o。
思维链(CoT)
类似于人类在回答复杂问题前进行深思熟虑,o1 在解决问题时运用了思维链的概念。通过强化学习,o1 逐渐磨练其思维链并优化使用策略。o1 学会了如何识别和纠正错误,并能将复杂的步骤拆解为更简单的部分。此外,当当前的方法不起作用时,o1 还能尝试不同的解决方案。这一过程显著提升了模型的推理能力。
编程能力
在对 o1 进行初始化并进一步训练其编程技能后,OpenAI 创建了一个非常强大的编程模型(o1-ioi)。该模型在 2024 年国际信息学奥林匹克竞赛(IOI)中获得了 213 分,排名在前 49% 左右。其参赛条件与人类参赛者一致:在 10 小时内解决 6 道复杂的算法题,每题只能提交 50 次答案。
针对每个问题,专门训练的 o1 模型会生成许多候选答案,然后根据测试时的选择策略提交 50 个答案。选择标准包括在 IOI 公共测试案例、模型生成的测试案例以及一个学习得到的评分函数上的表现。
研究发现,这种策略非常有效。如果随机提交答案,平均得分仅为 156 分。这说明在竞赛条件下,使用这种策略至少可以增加 60 分。
OpenAI 还发现,如果放宽提交次数限制,模型性能可以显著提升。允许每题提交 1 万次答案,即使不使用选择策略,模型也能得 362.14 分——达到了金牌水平。
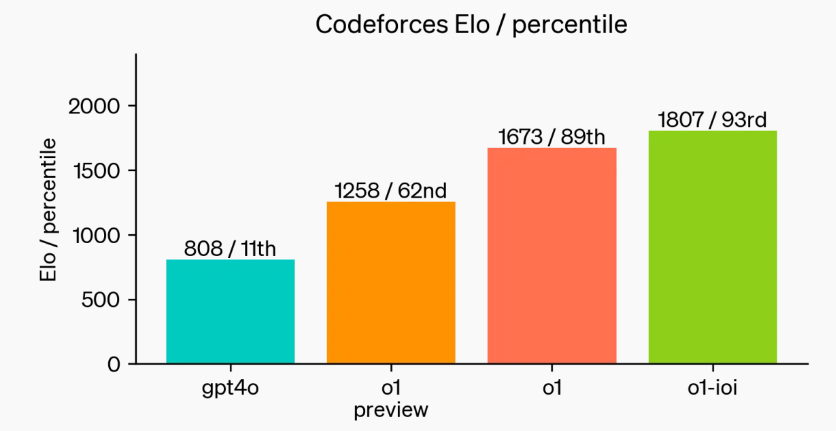
最后,OpenAI 模拟了 Codeforces 举办的编程竞赛,以展示该模型的编码能力。评估标准与竞赛规则非常接近,允许提交 10 次代码。GPT-4o 的 Elo 评分为 808,处于前 11% 水平。而 o1-ioi 模型的 Elo 评分为 1807,超过了 93% 的对手,远超 GPT-4o 和 o1。
应用场景
OpenAI o1 系列模型(包括 o1-preview 和 o1-mini)尤其适用于需要深入思考和复杂推理的任务。以下是一些适合使用 o1 模型的场景:
-
策略构思(Strategy Ideation) :o1-preview 模型可以在早期策略制定中充当有价值的构思伙伴,帮助创建测试场景、优先级框架以及后续步骤。
-
教育(Education) :在课程开发和学生辅导中,o1-preview 模型能够提供详细的教学指导,如解释微分方程,并生成示例和练习题。
-
编码练习和评论(Coding Exercises and Reviews) :o1-mini 模型在编写和调试复杂代码方面表现出色,能够理解问题的复杂性并提供逐步分解和伪代码。
-
高级数学和物理问题(Advanced Mathematics and Physics Problems) :o1-preview 模型能提供复杂的数学证明和详细的逻辑思路解释,非常适合学习高等数学和物理的学生。
-
复杂写作任务(Complex Writing Tasks) :o1-preview 模型能处理多层次的写作任务,维护问题的结构,并提供背景、结论和详细的优缺点列表。
功能限制
o1 系列模型缺乏多模态处理能力:o1-preview 和 o1-mini 模型无法处理图像、音频或视频的输入和输出。因此,如果需要处理多模态输入,建议使用 GPT-4o。
其他工具和功能限制:o1-preview 和 o1-mini 模型不具备内存功能、定制说明、数据分析、文件上传、网页浏览、发现和使用 GPTs、视觉和语音等高级功能。这些功能需要通过 GPT-4o 来实现。
参考内容:
https://mp.weixin.qq.com/s/sGcx90Q_uI8se-DKosj9dw
https://openai.com/index/introducing-openai-o1-preview/
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
https://openai.com/index/learning-to-reason-with-llms/
https://x.com/sama/status/1834283100639297910
另外,我的【AI 大模型全栈通识课】即将收官,感兴趣的小伙伴可以前来了解。
课程为系列课程,由浅入深,分五个单元共78+节(持续更新)课。
学完你将成为懂业务,懂开发,懂AI;会使用,会微调,会绘画的三懂三会人才
成为中国第一批AI大模型全栈工程师。
无论你是程序员、职场白领、政府文员、老师、甚至是宝妈、无业人员,学习 AI ,都将为你带来质的改变。
🧑💻 想转行,想跳槽,想升职,想涨薪的快快看过来👇
课程介绍:https://www.yuque.com/lhyyh/agi/introduce
往期推荐:
1. 我的国家级工信部认证 AIGC 证书(导师级)到手啦~
2. OpenAI推出神秘“草莓”项目,很快发布“GPT-5”猎户座!
3. AI重磅!OpenAI推出SearchGPT,向谷歌发起挑战,进军搜索引擎!
















 4015
4015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











