










传送门:Keras 中文文档
一、准备工作
1、概述
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
Keras 支持多个后端引擎,即可以基于不同的深度学习后端开发。重要的是,任何仅利用内置层构建的 Keras 模型,都可以在所有这些后端中移植:你可以用一种后端训练模型,再将它载入另一种后端中(例如为了发布的需要)。支持的后端有:
- 谷歌的 TensorFlow 后端
- 微软的 CNTK 后端
- Theano 后端
- 亚马逊也正在为 Keras 开发 MXNet 后端。
2、安装
pip install keras
3、GPU设置
(1)单GPU运行
根据后端的不同:
- TensorFlow 或 CNTK 后端:只要检测到任何可用的 GPU,那么代码将自动在 GPU 上运行。
- Theano 后端:
- 方法1:使用 Theano flags。
gpu可能需要根据你的设备标识符(例如gpu0,gpu1等)进行更改。THEANO_FLAGS=device=gpu,floatX=float32 python test.py - 方法 2:创建
.theanorc,详见 Theano Configuration - 方法 3:在代码的开头手动设置
theano.config.device,theano.config.floatX:import theano theano.config.device = 'gpu' theano.config.floatX = 'float32'
- 方法1:使用 Theano flags。
(2)多GPU运行
建议使用 Tensorflow 后端实现,方法:数据并行 和 设备并行。
- 数据并行(大多数情况):在每个设备上复制一次目标模型,并使用每个模型副本处理不同部分的输入数据。
- 使用内置函数
keras.utils.multi_gpu_model:可以生成任何模型的数据并行版本,在多达 8 个 GPU 上实现准线性加速。 - 文档:multi_gpu_model
- 示例:
from keras.utils import multi_gpu_model # 将 `model` 复制到 8 个 GPU 上。假定机器有 8 个可用的 GPU。 parallel_model = multi_gpu_model(model, gpus=8) parallel_model.compile(loss='categorical_crossentropy', optimizer='rmsprop') # 这个 `fit` 调用将分布在 8 个 GPU 上。 # 由于 batch size 为 256,每个 GPU 将处理 32 个样本。 parallel_model.fit(x, y, epochs=20, batch_size=256)
- 使用内置函数
- 设备并行:在不同设备上运行同一模型的不同部分。
- 适用于具有并行体系结构的模型,eg:两个分支的模型;
- 使用 TensorFlow 的
device_scopes来实现; - 示例:
# 模型中共享的 LSTM 用于并行编码两个不同的序列
input_a = keras.Input(shape=(140, 256))
input_b = keras.Input(shape=(140, 256))
shared_lstm = keras.layers.LSTM(64)
# 在一个 GPU 上处理第一个序列
with tf.device_scope('/gpu:0'):
encoded_a = shared_lstm(tweet_a)
# 在另一个 GPU上 处理下一个序列
with tf.device_scope('/gpu:1'):
encoded_b = shared_lstm(tweet_b)
# 在 CPU 上连接结果
with tf.device_scope('/cpu:0'):
merged_vector = keras.layers.concatenate([encoded_a, encoded_b],
axis=-1)
二、顺序模型 简单示例
1、整体流程
(1)顺序模型的构建——Sequential()
方法:
- 通过网络层的列表构建
- 使用
.add()方法将各层添加到模型中
## 顺序模型构建
# 1. 通过网络层的列表构建
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
# 2.使用 .add() 方法将各层添加到模型中
model = Sequential()
model.add(Dense(units=32, activation='relu', input_dim=784))
model.add(Dense(units=10, activation='softmax'))
指定输入数据的尺寸:顺序模型中的第一层(且只有第一层,因为下面的层可以自动地推断尺寸)需要接收关于其输入尺寸的信息。
input_shape参数:一个表示尺寸的元组 (一个由整数或 None 组成的元组,其中 None 表示可能为任何正整数)。在 input_shape 中不包含数据的 batch 大小。- 具体的层可能会支持特定的参数:
Dense层通过参数input_dim指定输入尺寸、某些 3D 时序层支持input_dim和input_length参数。
- 具体的层可能会支持特定的参数:
batch_size参数:设置 batch 的大小,eg:同时传递batch_size=32和input_shape=(6, 8),则每一批输入的尺寸就为(32,6,8)- 示例,两者等价:
model = Sequential() model.add(Dense(32, input_shape=(784, ))) model = Sequential() model.add(Dense(32, input_dim=784)))
(2)模型编译——compile
配置模型学习的过程,通过 compile 方法实现,其参数如下:
optimizer参数:优化器 。可以是现有优化器的字符串标识符,如rmsprop或adagrad,也可以是 Optimizer 类的实例。loss参数:损失函数,模型试图最小化的目标函数。可以是现有损失函数的字符串标识符,如categorical_crossentropy或mse,也可以是一个 目标函数 。metrics参数:评估标准。分类问题,至少设置metrics = ['accuracy']。评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数。
## 多分类器问题
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
## 二分类问题
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
## 均方误差回归问题
model.compile(optimizer='rmsprop',
loss='mse')
## 自定义评估标准函数
import keras.backend as K
def maen_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
(3)模型训练——fit
训练数据均为Numpy矩阵。
示例1:
## 数据生成
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
## 模型构建:二分类模型
model = Sequential()
model.add(Dense(32, activation='relu', input_dim = 100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
## 模型训练
model.fit(data, labels, epochs=10, batch_size=32)
示例2:
## 数据生成
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
## 模型构建:多分类模型
model = Sequential()
model.add(Dense(32, activation='relu', input_dim = 100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
## 将标签转换为分类的 one-hot 编码
import keras
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
## 训练模型
model.fit(data, one_hot_labels, epochs=10, batch_size=32)
(4)模型保存
a、保存/加载整个模型(结构 + 权重 + 优化器状态)
- 使用
model.save(filepath)将 Keras 模型保存到单个 HDF5 文件中,该文件包括:- 模型的结构,允许重新创建模型;
- 模型的权重;
- 训练配置项(损失函数,优化器);
- 优化器状态,允许准确地从你上次结束的地方继续训练。
- 使用
keras.models.load_model(filepath)重新实例化模型。此外,还负责使用保存的训练配置项来编译模型(除非模型从未编译过)。 - 注意:不建议使用 pickle 或 cPickle 来保存 Keras 模型。
- 示例:
from keras.models import load_model
model.save('my_model.h5') # 创建 HDF5 文件 'my_model.h5'
del model # 删除现有模型
# 返回一个编译好的模型
# 与之前那个相同
model = load_model('my_model.h5')
b、只保存/加载模型的结构*:无其权重或训练配置项
- 生成 JSON/YAML 文件,可读、可手动编辑;
- 示例:
##### 保存模型
# 保存为 JSON
json_string = model.to_json()
# 保存为 YAML
yaml_string = model.to_yaml()
##### 重建模型
# 从 JSON 重建模型:
from keras.models import model_from_json
model = model_from_json(json_string)
# 从 YAML 重建模型:
from keras.models import model_from_yaml
model = model_from_yaml(yaml_string)
c、只保存/加载模型的权重:保存成 HDF5 格式
- 保存参数、加载参数(同结构、有共同层)
## 保存参数
model.save_weights('my_model_weights.h5')
## 加载参数:将保存的权重加载到具有相同结构的模型中
model.load_weights('my_model_weights.h5')
## 加载参数:加载到不同的结构(有一些共同层)的模型,可按层的名字进行加载
model.load_weights('my_model_weights.h5', by_name=True)
- 示例:
"""
假设原始模型如下所示:
model = Sequential()
model.add(Dense(2, input_dim=3, name='dense_1'))
model.add(Dense(3, name='dense_2'))
...
model.save_weights(fname)
"""
# 新模型
model = Sequential()
model.add(Dense(2, input_dim=3, name='dense_1')) # 将被加载
model.add(Dense(10, name='new_dense')) # 将不被加载
# 从第一个模型加载权重;只会影响第一层,dense_1
model.load_weights(fname, by_name=True)
d、处理已保存模型中的自定义层(或其他自定义对象)
若要加载的模型包含自定义层或其他自定义类或函数,则可以通过 custom_objects 参数将它们传递给加载机制。
from keras.models import load_model
# 假设模型包含一个 AttentionLayer 类的实例
model = load_model('my_model.h5', custom_objects={'AttentionLayer': AttentionLayer})
或 使用 自定义对象作用域
from keras.utils import CustomObjectScope
with CustomObjectScope({'AttentionLayer': AttentionLayer}):
model = load_model('my_model.h5')
自定义对象的处理与 load_model, model_from_json, model_from_yaml 的工作方式相同
from keras.models import model_from_json
model = model_from_json(json_string, custom_objects={'AttentionLayer': AttentionLayer})
(5)获取中间层的输出
方法一:创建一个新的 Model 来输出你所感兴趣的层
from keras.models import Model
model = ... # 创建原始模型
layer_name = 'my_layer'
intermediate_layer_model = Model(inputs=model.input,
outputs=model.get_layer(layer_name).output)
intermediate_output = intermediate_layer_model.predict(data)
方法二:构建一个 函数,该函数将在给定输入的情况下返回某个层的输出
- 构建 Keras 函数,也可构建 Theano 或 TensorFlow 函数
from keras import backend as K # 以 Sequential 模型为例 get_3rd_layer_output = K.function([model.layers[0].input], [model.layers[3].output]) layer_output = get_3rd_layer_output([x])[0] - 注意:若模型在训练和测试阶段有不同的行为(例如,使用
Dropout,BatchNormalization等),则需要将学习阶段标志传递给你的函数:get_3rd_layer_output = K.function([model.layers[0].input, K.learning_phase()], [model.layers[3].output]) # 测试模式 = 0 时的输出 layer_output = get_3rd_layer_output([x, 0])[0] # 测试模式 = 1 时的输出 layer_output = get_3rd_layer_output([x, 1])[0]
2、示例
(1)样例1:基于多层感知器 (MLP) 的 softmax 多分类
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
## 数据生成
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
## 模型构建
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
(2)示例2:类似 VGG 的卷积神经网络
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# 生成虚拟数据
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
## 模型构建
model = Sequential()
# 输入: 3 通道 100x100 像素图像 -> (100, 100, 3) 张量。
# 使用 32 个大小为 3x3 的卷积滤波器。
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd,
loss='categorical_crossentropy')
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)
(3)示例3:基于 LSTM 的序列分类
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
timesteps = 7 #句子长度
num_classes = 9 #类别数
max_features = 8 #词汇量
batch = 5
# 创建虚假的训练数据
x_train = np.random.randint(max_features,size=(batch, timesteps)) #存的是各个字在embedding中的index
y_train = np.random.randint(num_classes, size=(batch, 1))
model = Sequential()
model.add(Embedding(max_features, output_dim=20, input_length=timesteps))
model.add(LSTM(20))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
(4)示例4:用于序列分类的栈式LSTM
结构:三个LSTM堆叠。 开始的两层LSTM返回其全部输出序列,而第三层LSTM只返回其输出序列的最后一步结果,从而其时域维度降低(即将输入序列转换为单个向量)
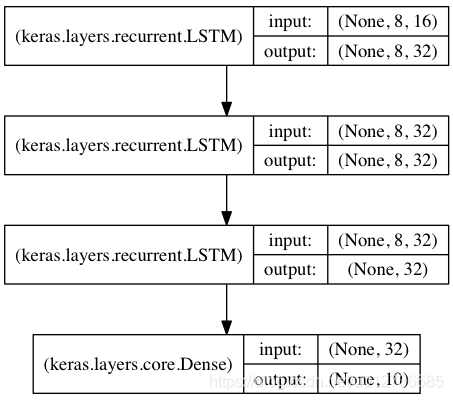
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# 生成虚拟训练数据
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# 生成虚拟验证数据
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
######### 模型构建
## input data shape: (batch_size, timesteps, data_dim)
model = Sequential()
# 返回维度为 32 的向量序列
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True))
model.add(LSTM(32))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=64, epochs=5, validation_data=(x_val, y_val))
(5)示例5:“stateful” 渲染的的栈式 LSTM 模型
有状态 (stateful) 的循环神经网络模型中:在一个 batch 的样本处理完成后,其内部状态(记忆)会被记录并作为下一个 batch 的样本的初始状态。这允许处理更长的序列,同时保持计算复杂度的可控性。
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# 生成虚拟训练数据
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# 生成虚拟验证数据
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
# 期望输入数据尺寸: (batch_size, timesteps, data_dim)
# 请注意,我们必须提供完整的 batch_input_shape,因为网络是有状态的。
# 第 k 批数据的第 i 个样本是第 k-1 批数据的第 i 个样本的后续。
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))
三、Keras 函数式 API
Keras 函数式 API :定义复杂模型(如多输出模型、有向无环图,或具有共享层的模型)的方法。
1、示例
- 网络层的实例是可调用的,它以张量为参数,并且返回一个张量;
- 输入和输出均为张量,它们都可以用来定义一个模型(Model);
- 这样的模型同 Keras 的 Sequential 模型一样,都可以被训练;
from keras.layers import Input, Dense
from keras.models import Model
## 数据生成
import numpy as np
data = np.random.random((1000, 784))
labels = np.random.randint(10, size=(1000, 10))
## 这部分返回一个张量
inputs = Input(shape=(784, ))
## 层的实例是可调用的,它以张量为参数,并且返回一个张量
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
pred = Dense(10, activation='softmax')(x)
# 这部分创建了一个包含输入层和三个全连接层的模型
model = Model(inputs=inputs, outputs=pred)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels, epochs=10)
所有的模型都可调用,就像网络层一样
- 便于重用训练好的模型:可以将任何模型看作是一个层,然后通过传递一个张量来调用它。
- 注意:在调用模型时,您不仅重用模型的结构,还重用了它的权重。
- 示例:图像分类 =》视频分类
from keras.layers import TimeDistributed
## 模型定义
x = Input(shape=(784,))
# 这是可行的,并且返回上面定义的 10-way softmax。
y = model(x)
# 输入数据定义:输入张量是 20 个时间步的序列,每一个时间为一个 784 维的向量
input_sequences = Input(shape=(20, 784))
# 这部分将我们之前定义的模型应用于输入序列中的每个时间步。
# 之前定义的模型的输出是一个 10-way softmax,
# 因而下面的层的输出将是维度为 10 的 20 个向量的序列。
processed_sequeneces = TimeDistributed(model)(input_sequences)
2、多输入多输出模型
函数式 API 使 处理大量交织的数据流 变得容易。
示例:预测 Twitter 上的一条新闻标题有多少转发和点赞数。
- 模型的主要输入:新闻标题本身,即一系列词语,其他的辅助输入:例如新闻标题的发布的时间等。
- 该模型也将通过两个损失函数进行监督学习。较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法。
模型结构如下:
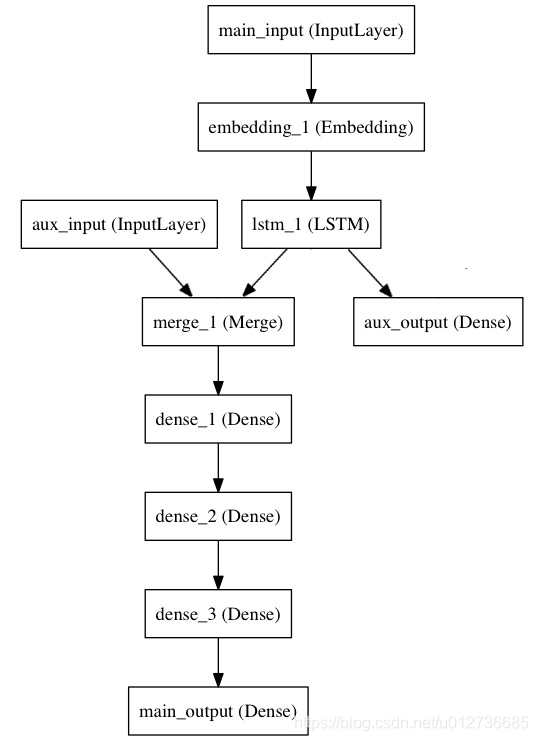
实现
- 主要输入:新闻标题,即一个整数序列(每个整数编码一个词)。 这些整数在 1 到 10,000 之间(10,000 个词的词汇表),且序列长度为 100 个词。
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
###### 模型构建
# 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 注意我们可以通过传递一个 "name" 参数来命名任何层。
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列,每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量,
# 它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
# 辅助损失: 使得即使在模型主损失很高的情况下,LSTM 层和 Embedding 层都能被平稳地训练。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
# 将辅助输入数据与 LSTM 层的输出连接起来,输入到模型中
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input])
# 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
# 然后定义一个具有两个输入和两个输出的模型
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
##### 编译与训练
# 方式1:编译模型,并给辅助损失分配一个 0.2 的权重。
# 如果要为不同的输出指定不同的 loss_weights 或 loss,可以使用列表或字典。
# 在这里,我们给 loss 参数传递单个损失函数,这个损失将用于所有的输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
model.fit([headline_data, addition_data], [labels, labels],
epochs=50, batch_size=32)
# 方式2:通过 name 参数编译和训练模型
model.compile(optimizer='rmsprop',
loss={'main_output':'binary_crossentropy', 'aux_output':'binary_crossentropy'},
loss_weights={'main_output':1., 'aux_output':0.2})
model.fit({'main_input': headline_data, 'aux_input':additional_data},
{'main_output': labels, 'aux_output':labels},
epochs=50, batch_size=32)
3、共享网络层
(1)共享网络层
目标:建立一个模型来分辨两条推文是否来自同一个人(例如,通过推文的相似性来对用户进行比较)。
方法:建立一个模型,将两条推文编码成两个向量,连接向量,然后添加逻辑回归层;这将输出两条推文来自同一作者的概率。模型将接收一对对正负表示的推特数据。
分析:该问题是对称的,编码第一条推文的机制应该被完全重用来编码第二条推文(权重及其他全部)。这里我们使用一个共享的 LSTM 层来编码推文。
数据预处理:首先 将一条推特转换为一个尺寸为 (280, 256) 的矩阵,即每条推特 280 字符,每个字符为 256 维的 one-hot 编码向量 (取 256 个常用字符)。
import keras
from keras.layers import Input, LSTM, Dense
from keras.models import Model
##### 模型构建
tweet_a = Input(shape=(280, 256))
tweet_b = Input(shape=(280, 256))
## 共享网络层:该层只实例化一次,然后传入想要的输入即可
# 这一层可以输入一个矩阵,并返回一个 64 维的向量
shared_lstm = LSTM(64)
# 当我们重用相同的图层实例多次,图层的权重也会被重用 (它其实就是同一层)
encoded_a = shared_lstm(tweet_a)
encoded_b = shared_lstm(tweet_b)
# 连接两个向量
merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
pred = Dense(1, activation='sigmoid')(merged_vector)
# 定义一个连接推特输入和预测的可训练的模型
model = Model(inputs=[tweet_a, tweet_b], outputs=pred)
##### 编译与训练
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit([data_a, data_b], labels, epochs=10)
(2)读取共享层的输出或输出尺寸
每当在某个输入上调用一个层时,都将创建一个新的张量(层的输出),并且为该层添加一个「节点」,将输入张量连接到输出张量。当多次调用同一个图层时,该图层将拥有多个节点索引 (0, 1, 2…)。
layer.output:获得层实例的输出张量;layer.output_shape:获取其输出形状;layer.input_shape:获取其输入形状;
## 该层有单个输入
a = Input(shape=(280, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
assert lstm.output == encoded_a
注意1:如果该层有多个输入,则不能用 layer.output 获取输出的张量
a = Input(shape=(280, 256))
b = Input(shape=(280, 256))
lstm = LSTM(32)
encoded_a = lstm(a) # 输入1
encoded_b = lstm(b) # 输入2
assert lstm.get_output_at(0) == encoded_a
assert lstm.get_output_at(1) == encoded_b
注意2:同上示例
a = Input(shape=(32, 32, 3))
b = Input(shape=(64, 64, 3))
conv = Conv2D(16, (3, 3), padding='same')
conved_a = conv(a)
# 到目前为止只有一个输入,以下可行:
assert conv.input_shape == (None, 32, 32, 3)
conved_b = conv(b)
# 现在 `.input_shape` 属性不可行,但是这样可以:
assert conv.get_input_shape_at(0) == (None, 32, 32, 3)
assert conv.get_input_shape_at(1) == (None, 64, 64, 3)
4、其他示例
(1)Inception
##### Inception
from keras.layers import Conv2D, MaxPooling2D, Input
input_img = Input(shape=(256, 256, 3))
tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_3)
output = keras.layers.concatenate([tower_1, tower_2, tower_3])
(2)Conv上的残差连接
##### Conv上的残差连接
from keras.layers import Conv2D, Input
x = Input(shape=(256, 256, 3))
y = Conv2D(3, (3, 3), padding='same')(x)
z = keras.layers.add([x, y])
(3)共享视觉模型
共享视觉模型:在两个输入上重复使用同一个图像处理模块,以判断两个 MNIST 数字是否为相同的数字。
from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flatten
from keras.models import Model
# 首先,定义视觉模型
digit_input = Input(shape=(27, 27, 1))
x = Conv2D(64, (3, 3))(digit_input)
x = Conv2D(64, (3, 3))(x)
x = MaxPooling2D((2, 2))(x)
output = Flatten(x)
vision_model = Model(digit_input, output)
# 然后,定义区分数字的模型
digit_a = Input(shape=(27, 27, 1))
digit_b = Input(shape=(27, 27, 1))
# 视觉模型将被共享,包括权重和其他所有,并构建新网络
out_a = vision_model(digit_a)
out_b = vision_model(digit_b)
concatenated = keras.layers.concatenate([out_a, out_b])
output = Dense(1, activation='sigmoid')(concatenated)
classification_model = Model([digit_a, digit_b], output)
(4)视觉问答模型
目标:当问关于图片的自然语言问题时,选择正确的单词作答。
方法:它通过将问题和图像编码成向量,然后连接两者,在上面训练一个逻辑回归,来从词汇表中挑选一个可能的单词作答。
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.layers import Input, LSTM, Embedding, Dense
from keras.models import Model, Sequential
## 定义视觉模型,该模型将图像编码为向量
vision_model = Sequential()
vision_model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
vision_model.add(Conv2D(64, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(128, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(Conv2D(256, (3, 3), activation='relu'))
vision_model.add(MaxPooling2D((2, 2)))
vision_model.add(Flatten())
## 用视觉模型来得到一个输出张量:
image_input = Input(shape=(224, 224, 3))
encoded_image = vision_model(image_input)
## 定义语言模型,将问题编码成一个向量。每个问题最长 100 个词,词的索引从 1 到 9999.
question_input = Input(shape=(100, ), dtype='int32')
embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
encoded_question = LSTM(256)(embedded_question)
# 连接问题向量和图像向量
merged = keras.layers.concatenate([encoded_question, encoded_image])
# 然后在上面训练一个 1000 词的逻辑回归模型
output = Dense(1000, activation='softmax')(merged)
# 最终模型
vqa_model = Model(inputs=[image_input, question_input], outputs=output)
(5)视频问答模型
目标:图像问答模型 ==》 视频问答模型。在适当的训练下,你可以给它展示一小段视频(例如 100 帧的人体动作),然后问它一个关于这段视频的问题(例如,「这个人在做什么运动?」 -> 「足球」)。
from keras.layers import TimeDistributed
video_input = Input(shape=(100, 224, 224, 3))
### 基于之前定义的视觉模型(权重被重用)构建的视频编码
# 输出为向量的序列
encoded_frame_sequence = TimeDistributed(vision_model)(video_input)
# 输出为一个向量
encoded_video = LSTM(256)(encoded_frame_sequence)
# 这是问题编码器的模型级表示,重复使用与之前相同的权重:
question_encoder = Model(inputs=question_input, outputs=encoded_question)
#用它来编码这个问题:
video_question_input = Input(shape=(100, ), dtype='int32')
encoded_video_question = question_encoder(video_question_input)
#视频问答模式:
merged = keras.layers.concatenate([encoded_video, encoded_video_question])
out = Dense(1000, activation='softmax')(merged)
video_qa_model = Model(inputs=[video_input, video_question_input], outputs=output)














 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









