










传送门:https://www.missshi.cn/api/view/blog/5a06a441e519f50d0400035e
本文我们详细讲解如何利用xgboost方法来解决泰坦尼克沉船事故人员存活预测的问题。
实现语言以Python为例来进行讲解。
评价标准
我们的目标是预测泰坦尼克号中哪些乘客可以幸存下来。
评价维度就是预测的准确率。
需要上传的文件格式如下:
一个csv文件,包含418行数据和1行Title。
每行都是有两列,其中,第一列为乘客的ID,第二列为是否能够幸存(幸存为1,否则为0)。
例如:
PassengerId,Survived
892,0
893,1
894,0
Etc.
数据集
https://pan.baidu.com/s/1pxgXW4s075j7zLWQpeoc4w
数据集中输入的特征包含如下字段:
- survived:是否幸存(1为幸存,0为死亡)
- pclass:船票档次,分为1,2,3三类。
- Name:乘客姓名
- Age:乘客的年龄
- SibSp:船上兄弟姐妹的数目
- Parch:船上父母子女的数目
- Ticket:船票号码
- Fare:船票价格
- Cabin:客舱号码
- Embarked:登船港口
第三方库引入
首先,我们来看下用xgboost解决这个问题需要引入哪些第三方库吧:
# Load in our libraries
import pandas as pd
import numpy as np
import re
import sklearn
import xgboost as xgb
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')
# Going to use these 5 base models for the stacking
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ExtraTreesClassifier
from sklearn.svm import SVC
from sklearn.cross_validation import KFold;
其中,numpy和pandas是在进行数据计算和分析中最常用的第三方库。
re是正则表达式库。
sklearn是专门用于机器学习的第三方库。
matplotlib,seaborn和plotly是Python用于绘图的第三方库。
xgboost是Python基于xgboost算法开发的第三方库。
特征的分析和提取
在传统机器学习算法中,我们首先需要分析数据的内在结构,找出数据的结构特征信息。
# Load in the train and test datasets
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
# Store our passenger ID for easy access
PassengerId = test['PassengerId']
train.head(3)
我们利用pandas库的方法直接读入excel方法后,读取训练集的前三行数据如下:

full_data = [train, test]
# 特征处理:额外添加一些需要从已有数据中计算得到的其他特征
# 1.添加姓名长度
train['Name_length'] = train['Name'].apply(len)
test['Name_length'] = test['Name'].apply(len)
# 2.是否有Cabin(客舱号码),判断 null
train['Has_Cabin'] = train['Cabin'].apply(lambda x:0 if type(x) == float else 1)
test['Has_Cabin'] = test['Cabin'].apply(lambda x:0 if type(x) == float else 1)
# 3.计算全部家人数目
for dataset in full_data:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
# 4.是否是一个人
for dataset in full_data:
dataset['IsAlone'] = 0
# loc[position,填写的列]
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
# 5.对Embarked(登船港口)列的空值进行处理
for dataset in full_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
# 6.用训练集数据的Fare(船票价格)的中值来填充所有Fare为空的数据
for dataset in full_data:
dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median())
train['CategoricalFare'] = pd.qcut(train['Fare'], 4) # 分为四类
# 7.创建一个新的特征CategoricalAge
for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
dataset['Age'] = dataset['Age'].astype(int)
train['CategoricalAge'] = pd.cut(train['Age'], 5)
# 8.定义函数,用于查询姓名中的Title(称谓)
def get_title(name):
title_search = re.search('([A-Za-z]+)\.', name)
# 若存在则提取它并返回
if title_search:
return title_search.group(1)
return ""
# 9.创建一个新的变量 Title
for dataset in full_data:
dataset['Title'] = dataset['Name'].apply(get_title)
# 10.将一些不常见的Title转换为一些对应的常见Title类型
for dataset in full_data:
dataset['Title'] = dataset['Title'].replace(['Lady','Countess','Capt','Col','Don','Dr','Major','Rev','Sir','Jonkheer','Dona'],'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms','Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
# 11.字符型映射到整数
for dataset in full_data:
# 将性别映射到0,1
dataset['Sex'] = dataset['Sex'].map({'female':0, 'male':1}).astype(int)
# 将Tile映射到 0-5
title_mapping = {"Mr":1, "Miss":2, "Mrs":3, "Master":4, "Rare":5}
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
# 将Embarked映射到0-2
dataset['Embarked'] = dataset['Embarked'].map({'S':0, 'C':1, 'Q':2}).astype(int)
# 将Fare分为四类0-3
# 并在符合条件的数据行添加Fare标签
dataset.loc[dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
# 将年龄分为5类:0-4
dataset.loc[dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[dataset['Age'] > 64, 'Age'] = 4
接下来,我们需要清除一些我们无法直接利用的一些特征:
# 12. 去除无法直接利用的特征
drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp']
train = train.drop(drop_elements, axis=1)
train = train.drop(['CategoricalAge', 'CategoricalFare'], axis=1)
test = test.drop(drop_elements, axis=1)
到目前为止,我们已经对特征进行了加工、处理和过滤。
接下来,我们需要简单的通过当前的数据进行一些可视化来帮助我们进一步进行分析。
print(train.head(3))

接下来,让我们看一下目前这些特征之间的相关性吧:
colormap = plt.cm.viridis
plt.figure(figsize=(14,12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(train.astype(float).corr(),linewidths=0.1,vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)
相关系数图如下:

Pearson相关系数(Pearson CorrelationCoefficient)是用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。
当Pearson相关系数越接近1时,表示两个特征之间的相关性越强;而当两个特征之间的相关性越接近于0时,表示两个特征之间的相关性越低。
其他参数计算
下面,我们需要计算一些在后续训练过程中需要使用的参数:
ntrain = train.shape[0]
ntest = test.shape[0]
SEED = 0 # for reproducibility
NFOLDS = 5 # set folds for out-of-fold prediction
kf = KFold(ntrain, n_folds= NFOLDS, random_state=SEED)
分类器封装
接下来,我们对Sklearn分类器进行一下封装,便于我们后续直接调用:
class SklearnHelper(object):
def __init__(self, clf, seed=0, params=None):
params['random_state'] = seed
self.clf = clf(**params)
def train(self, x_train, y_train):
self.clf.fit(x_train, y_train)
def predict(self, x):
return self.clf.predict(x)
def fit(self,x,y):
return self.clf.fit(x,y)
def feature_importances(self,x,y):
print(self.clf.fit(x,y).feature_importances_)
同样,我们也对XGBoost分类器进行相关的封装:
def get_oof(clf, x_train, y_train, x_test):
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
oof_test_skf = np.empty((NFOLDS, ntest))
for i, (train_index, test_index) in enumerate(kf):
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_te = x_train[test_index]
clf.train(x_tr, y_tr)
oof_train[test_index] = clf.predict(x_te)
oof_test_skf[i, :] = clf.predict(x_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
下面,我们使用5种模型对其进行分类:
模型构建
首先是对模型的参数进行设置:
## 模型参数设置
# 1. Random Forest
rf_params = {
'n_jobs':-1,
'n_estimators':500,
'warm_start':True,
# 'max_features':0.2,
'max_depth':6,
'min_samples_leaf':2,
'max_features':'sqrt',
'verbose':0
}
# 2. Extra Trees
et_params = {
'n_jobs':-1,
'n_estimators':500,
# 'max_features':0.5,
'max_depth':8,
'min_samples_leaf':2,
'verbose':0
}
# 3. Adaboost
ada_params = {
'n_estimators': 500,
'learning_rate':0.75
}
# 4. Gradint Boosting
gb_params = {
'n_estimators':500,
'max_features':0.2,
'max_depth':5,
'min_samples_leaf':2,
'verbose':0
}
# 5. SVM
svc_params = {
'kernel' : 'linear',
'C':0.025
}
下面,根据设置的参数来创建模型对象:
# 模型构建
rf = SklearnHelper(clf=RandomForestClassifier, seed=SEED, params=rf_params)
et = SklearnHelper(clf=ExtraTreesClassifier, seed=SEED, params=et_params)
ada = SklearnHelper(clf=AdaBoostClassifier, seed=SEED, params=ada_params)
gb = SklearnHelper(clf=GradientBoostingClassifier, seed=SEED, params=gb_params)
svc = SklearnHelper(clf=SVC, seed=SEED, params=svc_params)
接下来,将我们的数据转换为模型需要的numpy数组的格式:
# 模型构建
y_train = train['Survived'].ravel()
train = train.drop(['Survived'], axis=1)
x_train = train.values # Creates an array of the train data
x_test = test.values # Creats an array of the test data
接下来,我们用5个模型分别用于XGBoost训练模型中进行训练预测:
et_oof_train, et_oof_test = get_oof(et, x_train, y_train, x_test) # Extra Trees
rf_oof_train, rf_oof_test = get_oof(rf,x_train, y_train, x_test) # Random Forest
ada_oof_train, ada_oof_test = get_oof(ada, x_train, y_train, x_test) # AdaBoost
gb_oof_train, gb_oof_test = get_oof(gb,x_train, y_train, x_test) # Gradient Boost
svc_oof_train, svc_oof_test = get_oof(svc,x_train, y_train, x_test) # Support Vector Classifier
print("Training is complete")
我们将每个模型中的特征提取出来:
rf_feature = rf.feature_importances(x_train,y_train)
et_feature = et.feature_importances(x_train, y_train)
ada_feature = ada.feature_importances(x_train, y_train)
gb_feature = gb.feature_importances(x_train,y_train)
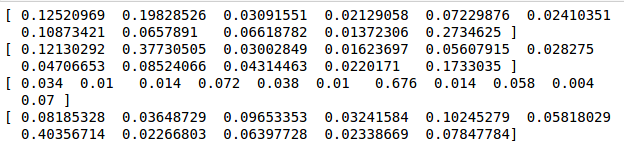
整理得到的特征值如下:
cols = train.columns.values
# Create a dataframe with features
feature_dataframe = pd.DataFrame({
'features': cols,
'Random Forest feature importances': rf_features,
'Extra Trees feature importances': et_features,
'AdaBoost feature importances': ada_features,
'Gradient Boost feature importances': gb_features
})
用图像的方式可以更加明显的表现出来:
trace = go.Scatter(
y = feature_dataframe['Random Forest feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['Random Forest feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'Random Forest Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')
# Scatter plot
trace = go.Scatter(
y = feature_dataframe['Extra Trees feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['Extra Trees feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'Extra Trees Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')
# Scatter plot
trace = go.Scatter(
y = feature_dataframe['AdaBoost feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['AdaBoost feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'AdaBoost Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')
# Scatter plot
trace = go.Scatter(
y = feature_dataframe['Gradient Boost feature importances'].values,
x = feature_dataframe['features'].values,
mode='markers',
marker=dict(
sizemode = 'diameter',
sizeref = 1,
size = 25,
# size= feature_dataframe['AdaBoost feature importances'].values,
#color = np.random.randn(500), #set color equal to a variable
color = feature_dataframe['Gradient Boost feature importances'].values,
colorscale='Portland',
showscale=True
),
text = feature_dataframe['features'].values
)
data = [trace]
layout= go.Layout(
autosize= True,
title= 'Gradient Boosting Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig,filename='scatter2010')




下面,我们在数据中在新增一列,用于添加这个特征值的平均值:
feature_dataframe['mean'] = feature_dataframe.mean(axis= 1) # axis = 1 computes the mean row-wise
# 看一下目前的数据格式吧:
feature_dataframe.head(3)

来用柱状图看下每个特征的重要程度吧:
y = feature_dataframe['mean'].values
x = feature_dataframe['features'].values
data = [go.Bar(
x= x,
y= y,
width = 0.5,
marker=dict(
color = feature_dataframe['mean'].values,
colorscale='Portland',
showscale=True,
reversescale = False
),
opacity=0.6
)]
layout= go.Layout(
autosize= True,
title= 'Barplots of Mean Feature Importance',
hovermode= 'closest',
# xaxis= dict(
# title= 'Pop',
# ticklen= 5,
# zeroline= False,
# gridwidth= 2,
# ),
yaxis=dict(
title= 'Feature Importance',
ticklen= 5,
gridwidth= 2
),
showlegend= False
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='bar-direct-labels')

预测一下看看吧:
base_predictions_train = pd.DataFrame( {'RandomForest': rf_oof_train.ravel(),
'ExtraTrees': et_oof_train.ravel(),
'AdaBoost': ada_oof_train.ravel(),
'GradientBoost': gb_oof_train.ravel()
})
base_predictions_train.head()
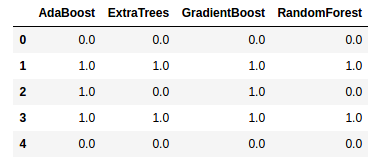
最后,我们再看下这四个特征的相关性图吧:
data = [
go.Heatmap(
z= base_predictions_train.astype(float).corr().values ,
x=base_predictions_train.columns.values,
y= base_predictions_train.columns.values,
colorscale='Viridis',
showscale=True,
reversescale = True
)
]
py.iplot(data, filename='labelled-heatmap')

最后,我们来对测试集的数据进行预测一下吧,并生成最终需要上传的csv文件:
x_train = np.concatenate(( et_oof_train, rf_oof_train, ada_oof_train, gb_oof_train, svc_oof_train), axis=1)
x_test = np.concatenate(( et_oof_test, rf_oof_test, ada_oof_test, gb_oof_test, svc_oof_test), axis=1)
gbm = xgb.XGBClassifier(
#learning_rate = 0.02,
n_estimators= 2000,
max_depth= 4,
min_child_weight= 2,
#gamma=1,
gamma=0.9,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread= -1,
scale_pos_weight=1).fit(x_train, y_train)
predictions = gbm.predict(x_test)
# Generate Submission File
StackingSubmission = pd.DataFrame({ 'PassengerId': PassengerId,
'Survived': predictions })
StackingSubmission.to_csv("StackingSubmission.csv", index=False)
运行完成后,我们可以看到我们成功的得到了StackingSubmission.csv文件。
这个文件的格式就是Kaggle竞赛要求的结果文件啦!
怎么样?对Kaggle比赛是不是有了一点点的了解了?赶紧参与其中吧!















 1909
1909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









