






1、UniMODE: Unified Monocular 3D Object Detection
中文标题:UniMODE: 统一的单目三维物体检测

简介:实现统一的单目3D物体检测对于机器人导航等应用至关重要,涵盖了室内和室外场景。然而,训练模型需要涉及各种场景的数据,这会带来挑战,因为这些场景具有显著不同的特征,如多样的几何属性和异构的领域分布。为了应对这些挑战,我们基于鸟瞰图(BEV)检测范例开发了一个检测器,其中显式的特征投影有助于解决在使用多个场景数据训练检测器时出现的几何学习歧义问题。我们将传统的BEV检测架构分为两个阶段,并提出了一种不均匀的BEV网格设计,以应对由上述挑战导致的收敛不稳定性。此外,我们提出了一种稀疏的BEV特征投影策略来降低计算成本,并引入了一种统一的领域对齐方法来处理异构领域。通过结合这些技术,我们开发了一个名为UniMODE的统一检测器,在具有挑战性的Omni3D数据集上取得了显著进展,比之前最先进技术提高了4.9%AP_3D,成功将BEV检测器扩展到统一的3D物体检测领域。
2、TAMM: TriAdapter Multi-Modal Learning for 3D Shape Understanding
中文标题:TAMM: TriAdapter 多模态学习用于 3D 形状理解
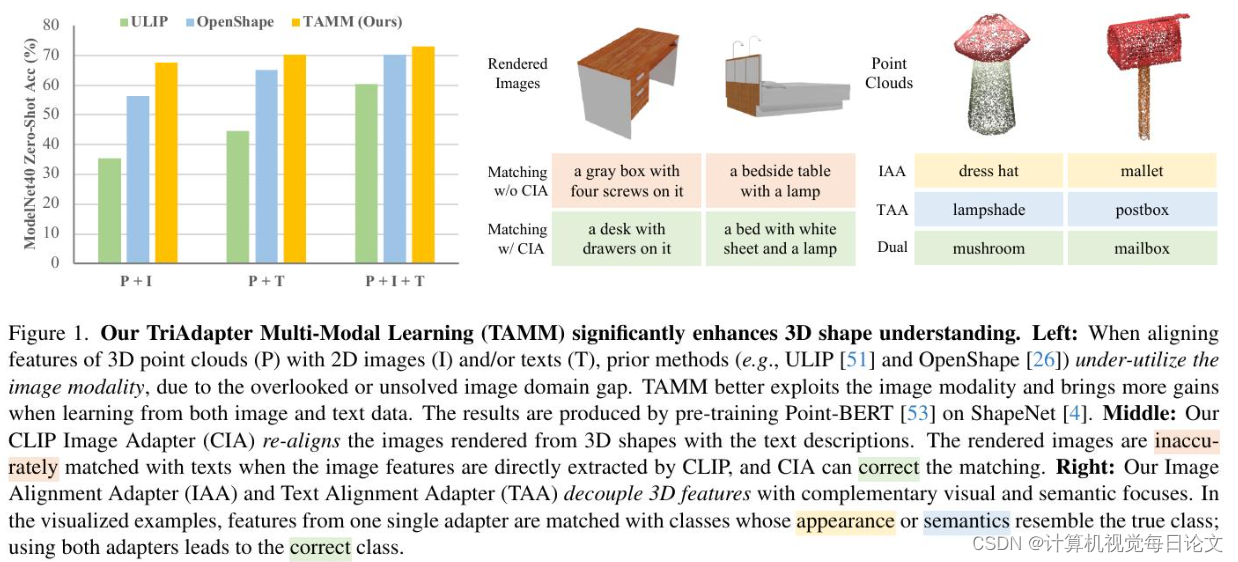
简介:当前三维形状数据集的规模限制了对三维形状的理解,因此多模态学习方法被用来将从数据丰富的二维图像和语言模态中学到的知识转移到三维形状领域。尽管图像和语言表示已经通过交叉模态模型(如CLIP)进行了对齐,但现有的多模态三维表示学习方法中发现图像模态的贡献不如语言模态大,这部分原因在于二维图像中的域偏移和每种模态关注点的不同。为了更有效地利用预训练中的两种模态,提出了TriAdapter多模态学习(TAMM)——一种基于三个协同适配器的新型两阶段学习方法。首先,通过适应CLIP的视觉表示,我们的CLIP图像适配器缓解了三维渲染图像和自然图像之间的域差异,适用于合成的图像-文本对。随后,我们的双适配器将三维形状表示空间分解为两个互补的子空间:一个侧重于视觉属性,另一个侧重于语义理解,从而确保更全面和有效的多模态预训练。广泛的实验证明,TAMM始终增强了各种三维编码器架构、预训练数据集和下游任务的三维表示。值得一提的是,我们将Objaverse-LVIS的零样本分类准确率从46.8提高到50.7,并将ModelNet40的5路10-shot线性探测分类准确率从96.1提高到99.0。详细信息请参考项目主页:\url{https://alanzhangcs.github.io/tamm-page}。
3、IBD: Alleviating Hallucinations in Large Vision-Language Models via Image-Biased Decoding
中文标题:IBD: 通过图像偏向解码减轻大型视觉语言模型中的幻觉
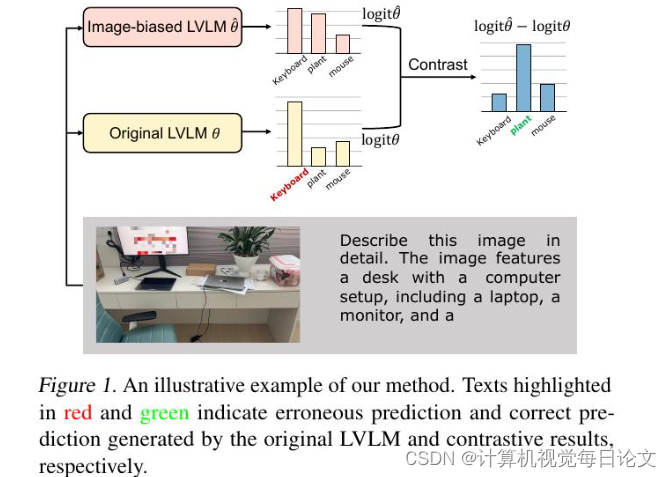
简介:尽管大型视觉语言模型(LVLMs)已经取得了快速发展并被广泛应用,但它们面临着生成幻觉的严重挑战。研究表明,过度依赖语言先验知识是导致这些幻觉的主要原因。为了解决这一问题,我们提出了一种新颖的图像偏置解码(IBD)技术。我们的方法通过对比传统LVLM和图像偏置LVLM的预测,来得出下一个标记的概率分布,从而突显与图像内容高度相关的正确信息,同时减少因文本依赖过多而引起的幻觉误差。我们进行了全面的统计分析来验证我们方法的可靠性,并设计了一种自适应调整策略,以在不同条件下实现稳健和灵活的处理。实验结果基于多个评估指标证实了我们的方法,它能显著减少LVLMs中的幻觉,增强生成响应的真实性,而且无需额外训练数据,仅对模型参数做出最小增加。














 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









