







目前,以CNN、RNN和 Transformer 模型为代表的深度学习算法已经超越了传统机器学习算法,成为了时间序列预测领域一个新的研究趋向。 这其中,基于Transformer架构的模型在时间序列预测中取得了丰硕的成果。
Transformer模型因其强大的序列建模能力,很适合时间序列这种也是序列类型的数据结构。但与文本序列相比,时间序列具有很多独特的特征,比如自相关性、周期性以及长周期性预测,这些特性给Transformer在时间序列预测场景中的应用带来了新的挑战。
为了克服这些挑战,满足预测任务的高效率和高精度需求,研究者对原始的Transformer结构进行了改造,比如无需修改任何模块,即在复杂时序预测任务中取得全面领先的iTransformer。
iTransformer
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
方法: 本文提出了一种新的时间序列预测模型iTransformer,通过将每个时间序列作为变量令牌进行建模,利用自注意力机制捕捉多变量之间的相关性,并利用前馈网络编码序列表示。
创新点:
-
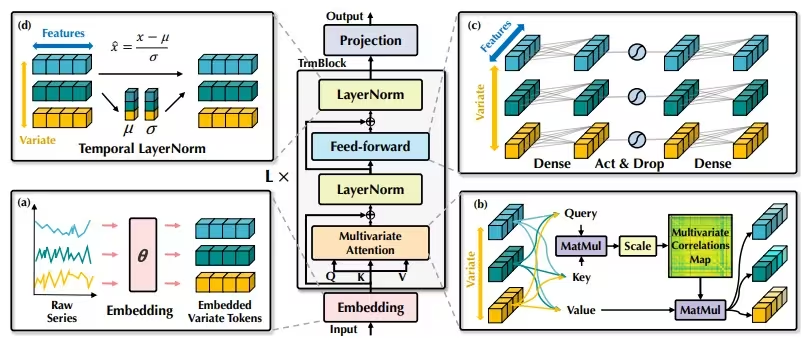
iTransformer采用了Transformer的编码器架构,包括嵌入、投影和Transformer块。这种架构的创新在于将时间序列的每个变量独立地嵌入为变量标记,通过自注意力机制捕捉多变量之间的相关性,并通过共享的前馈网络对每个TrmBlock中的序列进行独立处理。
-
iTransformer通过将时间序列的每个变量独立地嵌入为变量标记,解决了传统Transformer架构中将多个变量嵌入为一个时间标记的问题。这种反转的操作使得嵌入的标记能够更好地捕捉时间序列的全局特征,并且能够更好地利用多变量之间的相关性。
关于iTransformer更为详细的介绍可以参考博客:Transformer王者归来!无需修改任何模块,时序预测全面领先
Pathformer
Pathformer: Multi-Scale Transformers With Adaptive Pathways For Time Series Forecasting
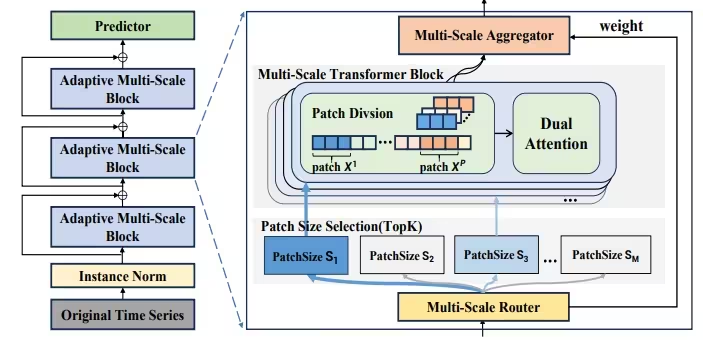
方法: 论文提出了一种自适应多尺度建模方法,即基于多尺度Transformer的自适应路径模型。该模型包含两个主要组件:多尺度路由器和多尺度聚合器。多尺度路由器根据输入数据选择特定大小的分块划分,并通过激活Transformer中的特定部分来控制多尺度特征的提取。路由器与多尺度聚合器配合使用,通过加权聚合将这些特征组合起来,得到Transformer块的输出。
创新点:
-
自适应多尺度建模的AMS Block设计,其中包括多尺度Transformer块和自适应路径。该设计通过多尺度Transformer块和自适应路径实现自适应多尺度建模,能够捕捉不同尺度特征的变化,提高预测准确性。
-
引入噪声项来增加路径权重生成过程的随机性,避免一直选择少数几个尺度,从而忽视其他潜在有用的尺度。这种引入噪声的方法可以使多尺度Transformer块更全面地建模不同时间分辨率和时间距离,提高多尺度建模的效果。
scaleformer
SCALEFORMER: ITERATIVE MULTI-SCALE REFINING TRANSFORMERS FOR TIME SERIES FORECASTING
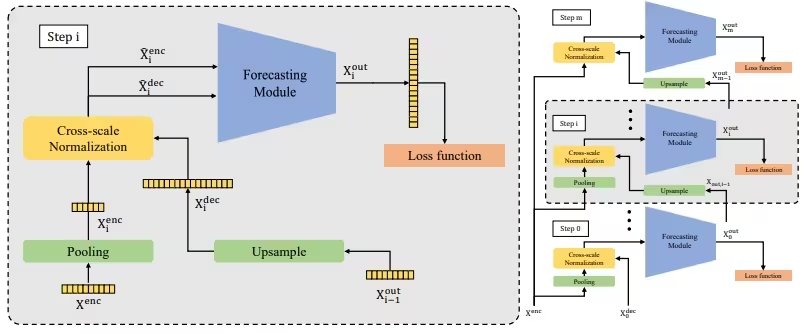
方法: 论文提出了一个通用的多尺度框架,可以应用于最先进的基于Transformer的时间序列预测模型(如FEDformer、Autoformer等)。通过在多个尺度上共享权重,引入架构调整和特殊设计的归一化方案,作者在基准Transformer架构上实现显著的性能改进,对于不同的数据集和Transformer架构,改进范围从5.5%到38.5%不等,并且额外的计算开销很小。
创新点:
-
作者提出了一个多尺度框架,可以应用于最先进的基于transformer的时间序列预测模型(如FEDformer、Autoformer等),通过在多个尺度上迭代地改进预测的时间序列,引入架构适应性和特殊设计的归一化方案,能够在数据集和transformer架构上实现显著的性能改进。
-
作者展示了Scaleformer在概率预测和非transformer模型方面的适用性,并提出了未来工作的方向。
InParformer
InParformer: Evolutionary Decomposition Transformers with Interactive Parallel Attention for Long-Term Time Series Forecasting
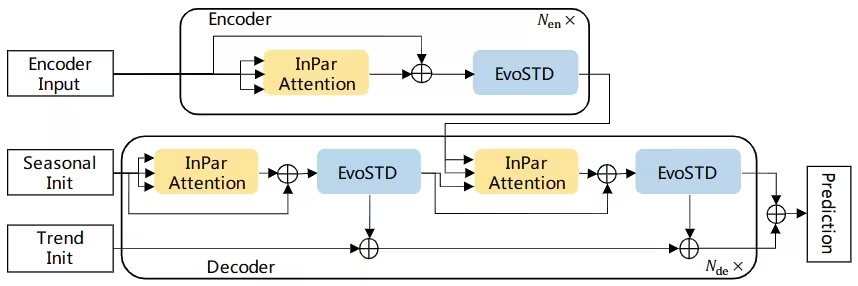
方法: 本文提出了一种名为InParformer的基于Transformer的长期时间序列预测模型。传统的时间序列预测方法主要集中在统计方法上,如ARIMA和指数平滑,对于建模非线性时间动态有困难。为了解决这个问题,引入了经典的机器学习模型,如支持向量回归(SVR)和梯度增强树。
创新点:
-
InPar Attention机制:提出了一种交互并行注意力机制,用于在频率和时间域中全面学习长程依赖关系。
-
EvoSTD模块:引入了进化季节趋势分解模块,用于增强复杂时间模式的提取能力。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









