







本文的主要内容均来源于LLaMA-Factory官方文档:https://llamafactory.readthedocs.io/zh-cn/latest/index.html
文章目录
一、LLaMA-Factory项目介绍
1.1 项目介绍

LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。 通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
-
LLaMA-Factory项目地址:https://github.com/hiyouga/LLaMA-Factory
-
LLaMA-Factory官方文档:https://llamafactory.readthedocs.io/zh-cn/latest/index.html
🤗 强烈推荐LLaMA-Factory官方文档,写得十分详细易懂!手动点赞 o( ̄▽ ̄)o 🤗
1.2 框架特性
框架特性包括:
-
模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
-
训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
-
运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
-
优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
-
加速算子:FlashAttention-2 和 Unsloth。
-
推理引擎:Transformers 和 vLLM。
-
实验面板:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
二、LLaMA-Factory 安装
参考官方安装说明文档:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/installation.html
各个工具和依赖包的版本如下:

2.1 CUDA及Pytorch安装
CUDA 是由 NVIDIA 创建的一个并行计算平台和编程模型,它让开发者可以使用 NVIDIA 的 GPU 进行高性能的并行计算。官方推荐的CUDA是12.2版本。
CUDA的安装过程不再赘述,可以参考本人之前的博客:Ubuntu 22.04安装cuda及Pytorch教程
安装完CUDA后,使用如下命令查看CUDA版本:
nvcc -V
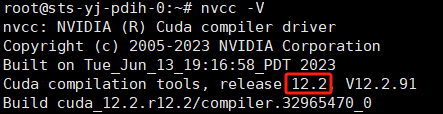
Pytorch安装适应于服务器cuda版本的即可,我这边安装的是:
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121
2.2 LLaMA-Factory 安装
(1)克隆项目代码
首先,使用 Git 克隆 LLaMA-Factory 项目到本地:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
(2)创建虚拟环境
建议在虚拟环境中安装项目依赖,以避免与其他项目冲突:
conda create -n llamafactory python=3.10
source activate llamafactory
(3)安装依赖包
运行如下命令:
pip install -e ".[torch,metrics]"
该命令会执行当前目录下的 setup.py 文件,setup.py 文件中定义了该项目所需的依赖。
注:如果出现环境冲突,请尝试使用 pip install --no-deps -e . 解决。
(4)LLaMA-Factory 校验
完成安装后,可以通过使用如下命令来快速校验安装是否成功:
llamafactory-cli version
如果您能成功看到类似下面的界面,就说明安装成功了。

三、数据处理
dataset_info.json 包含了所有经过预处理的 本地数据集 以及 在线数据集。数据样例如下:
"alpaca_en_demo": {
"file_name": "alpaca_en_demo.json"
},
"alpaca_zh_demo": {
"file_name": "alpaca_zh_demo.json"
},
"glaive_toolcall_en_demo": {
"file_name": "glaive_toolcall_en_demo.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"tools": "tools"
}
},
如果您希望使用自定义数据集,请 务必 在 dataset_info.json 文件中添加对数据集及其内容的定义。
目前我们支持 Alpaca 格式和 ShareGPT 格式的数据集。
3.1 Alpaca格式数据集
针对不同任务,Alpaca格式数据集格式要求如下:
- 指令监督微调
- 预训练
- 偏好训练
- KTO
- 多模态
3.1.1 指令监督微调数据集
指令监督微调样例数据集: https://github.com/hiyouga/LLaMA-Factory/blob/main/data/alpaca_zh_demo.json/
指令监督微调(Instruct Tuning) 通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
指令监督微调数据集 格式要求 如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
各个字段的含义如下:
instruction列对应的内容为人类指令input列对应的内容为人类输入output列对应的内容为模型回答- 如果指定,
system列对应的内容将被作为系统提示词。 history列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
(1)单轮对话样例
下面是一个alpaca 格式的 单轮对话 的简单例子:
"alpaca_zh_demo.json"
{
"instruction": "计算这些物品的总费用。 ",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},
在进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput。而 output 列对应的内容为模型回答。
在上面的例子中,人类的最终输入是:
计算这些物品的总费用。
输入:汽车 - $3000,衣服 - $100,书 - $20。
模型的回答是:
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。
(2)多轮对话样例
下面提供一个 alpaca 格式 多轮对话 的例子,对于单轮对话只需省略 history 列即可。
[
{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
[
"今天会下雨吗?",
"今天不会下雨,是个好天气。"
],
[
"今天适合出去玩吗?",
"非常适合,空气质量很好。"
]
]
}
]
(3)数据集描述
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
3.1.2 预训练数据集
预训练样例数据集:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/c4_demo.json/
大语言模型通过学习未被标记的文本进行预训练,从而学习语言的表征。通常,预训练数据集从互联网上获得,因为互联网上提供了大量的不同领域的文本信息,有助于提升模型的泛化能力。 预训练数据集文本描述格式如下:
[
{"text": "document"},
{"text": "document"}
]
在预训练时,只有 text 列中的 内容 (即document)会用于模型学习。
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "text"
}
}
3.1.3 偏好数据集
偏好数据集用于奖励模型训练、DPO 训练和 ORPO 训练。对于系统指令和人类输入,偏好数据集给出了一个更优的回答和一个更差的回答。
一些研究 表明通过让模型学习“什么更好”可以使得模型更加迎合人类的需求。 甚至可以使得参数相对较少的模型的表现优于参数更多的模型。
偏好数据集需要在 chosen 列中提供更优的回答,并在 rejected 列中提供更差的回答,在一轮问答中其格式如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"chosen": "优质回答(必填)",
"rejected": "劣质回答(必填)"
}
]
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"ranking": true,
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}
3.1.4 KTO 数据集
KTO数据集与偏好数据集类似,但不同于给出一个更优的回答和一个更差的回答,KTO数据集对每一轮问答只给出一个 true/false 的 label。 除了 instruction 以及 input 组成的人类最终输入和模型回答 output ,KTO 数据集还需要额外添加一个 kto_tag 列(true/false)来表示人类的反馈。
在一轮问答中其格式如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"kto_tag": "人类反馈 [true/false](必填)"
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"kto_tag": "kto_tag"
}
}
3.1.5 多模态数据集
多模态数据集需要额外添加一个 images 列,包含输入图像的路径。目前我们仅支持单张图像输入。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"images": [
"图像路径(必填)"
]
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"images": "images"
}
}
3.2 ShareGPT格式数据集
针对不同任务,数据集格式要求如下:
- 指令监督微调
- 偏好训练
- OpenAI格式
- ShareGPT 格式中的 KTO数据集(样例)和多模态数据集(样例) 与 Alpaca 格式的类似。
- 预训练数据集不支持 ShareGPT 格式。
3.2.1 指令监督微调数据集
指令监督微调样例数据集:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/glaive_toolcall_zh_demo.json/
相比 alpaca 格式的数据集, sharegpt 格式支持 更多 的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。 下面是 sharegpt 格式的一个例子:
{
"conversations": [
{
"from": "human",
"value": "你好,我出生于1990年5月15日。你能告诉我我今天几岁了吗?"
},
{
"from": "function_call",
"value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"
},
{
"from": "observation",
"value": "{\"age\": 31}"
},
{
"from": "gpt",
"value": "根据我的计算,你今天31岁了。"
}
],
"tools": "[{\"name\": \"calculate_age\", \"description\": \"根据出生日期计算年龄\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
3.2.2 偏好数据集
偏好数据样例数据集:https://github.com/hiyouga/LLaMA-Factory/blob/main/data/dpo_zh_demo.json/
Sharegpt 格式的偏好数据集同样需要在 chosen 列中提供更优的消息,并在 rejected 列中提供更差的消息。 下面是一个例子:
{
"conversations": [
{
"from": "human",
"value": "老虎会吃哪一个,草还是树叶?"
}
],
"chosen": {
"from": "gpt",
"value": "我很高兴能帮助你解答问题!不过,我必须指出,这个问题本身可能没有意义。老虎是食肉动物,通常不吃草或树叶。它们的饮食主要包括大型有蹄动物、小型哺乳动物和鸟类。\n\n如果你提出这个问题是出于好奇或有特定原因,我很乐意帮助你找到更多关于老虎饮食习惯的信息,或者建议资源让你更多了解这些壮丽的生物。请告诉我如何进一步协助你!"
},
"rejected": {
"from": "gpt",
"value": "一只老虎是食肉动物,这意味着它的饮食主要是肉类。老虎主要猎捕和吃其他动物,如鹿和野猪。它们不会选择吃草或树叶,因为这些不是它们自然饮食的一部分。"
}
}
其格式为:
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "gpt",
"value": "模型回答"
},
{
"from": "human",
"value": "人类指令"
}
],
"chosen": {
"from": "gpt",
"value": "优质回答"
},
"rejected": {
"from": "gpt",
"value": "劣质回答"
}
}
]
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"ranking": true,
"columns": {
"messages": "conversations",
"chosen": "chosen",
"rejected": "rejected"
}
}
3.2.3 OpenAI格式
OpenAI 格式仅仅是 sharegpt 格式的一种特殊情况,其中第一条消息可能是系统提示词。
[
{
"messages": [
{
"role": "system",
"content": "系统提示词(选填)"
},
{
"role": "user",
"content": "人类指令"
},
{
"role": "assistant",
"content": "模型回答"
}
]
}
]
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}
四、WebUI
LLaMA-Factory 支持通过 WebUI 零代码微调大语言模型。 在完成 安装 后,您可以通过以下指令进入 WebUI:
llamafactory-cli webui
WebUI 主要分为四个界面:训练、评估与预测、对话、导出。
4.1 训练
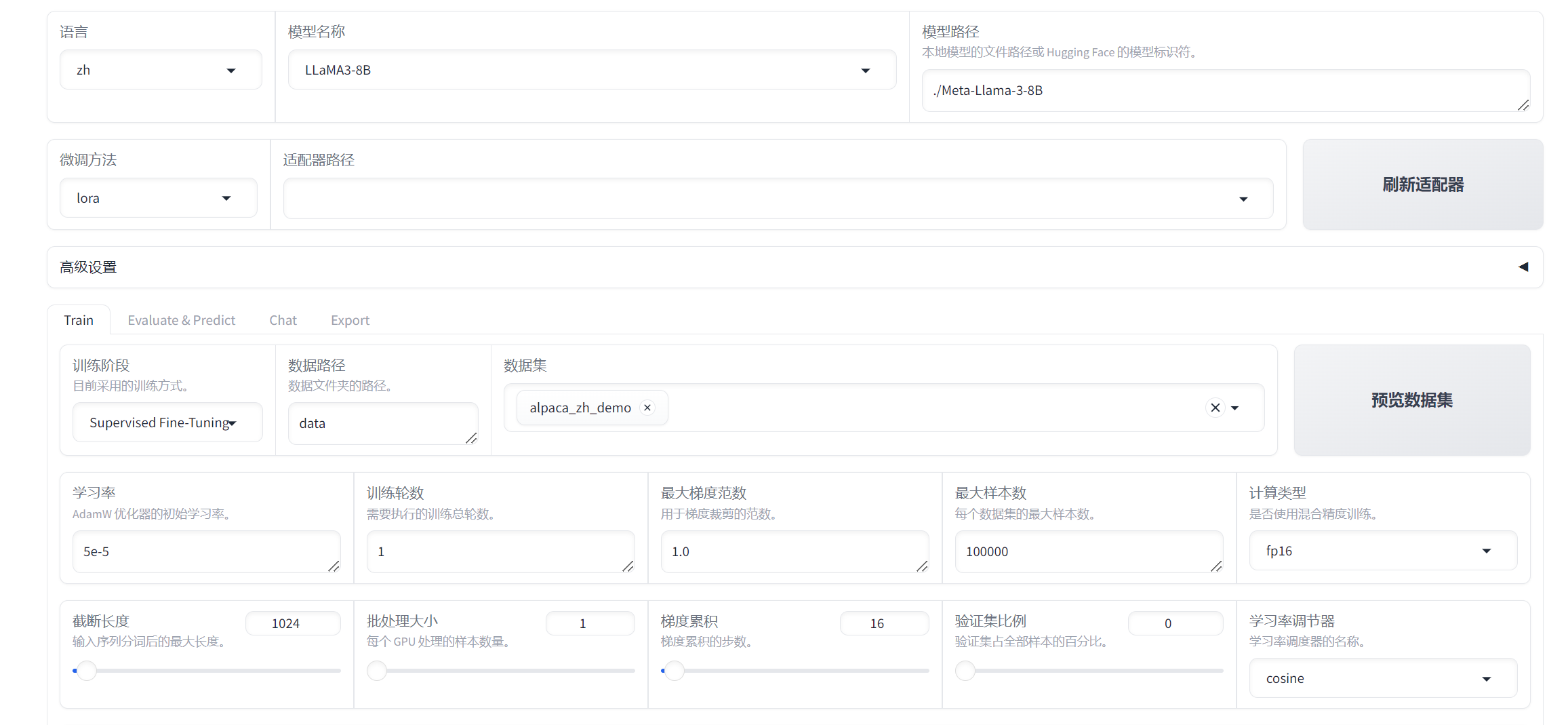
在开始训练模型之前,您需要指定的参数有:
- 模型名称及路径
- 训练阶段
- 微调方法
- 训练数据集
- 学习率、训练轮数等训练参数
- 微调参数等其他参数
- 输出目录及配置路径
随后,您可以点击 开始 按钮开始训练模型。
关于断点重连:适配器断点保存于 output_dir 目录下,请指定 适配器路径 以加载断点继续训练。
如果您需要使用自定义数据集,请在 data/data_info.json 中添加自定义数据集描述并确保 数据集格式 正确,否则可能会导致训练失败。
4.2 评估预测与对话
模型训练完毕后,您可以通过在评估与预测界面通过指定 模型 及 适配器 的路径在指定数据集上进行评估。
您也可以通过在对话界面指定 模型、 适配器 及 推理引擎 后输入对话内容与模型进行对话观察效果。
4.3 导出
如果您对模型效果满意并需要导出模型,您可以在导出界面通过指定 模型、 适配器、 分块大小、 导出量化等级及校准数据集、 导出设备、 导出目录 等参数后点击 导出 按钮导出模型。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









