










Facebook AI Research 的文章,刚刚开源到github,代码: https://github.com/facebookresearch/deepmask 。其开源代码主要来自于两篇文章,想学习一下这个代码,还是先把出处的两篇文章看完吧。
简介与思想:
经典的目标检测系统主要包括两个部分:提取proposal、将每一个候选proposal输入进行目标分类。本文则提出另一种思路:基于discriminative convolutional network的方法。
该模型将两个部分进行合并:输入图像patch,输出一个segmentation mask;然后第二部分判断是一个特点目标的可能性大小。在test时候,模型可以产生一系列segmentation mask,每一个mask对应是各种目标的可能性分数。实验证明,该模型显著优于proposal算法。同时,该方法的recall精度十分突出,并且可以检测出训练时没有出现的类别。
对于proposal算法来说,重点在于以下几点:高recall(proposed regions应该最大程度包含可能存在目标的区域);regions的数量整体尽可能少;regions应该与目标精确一致。
现有proposal算法分类:1)目标打分:通过对bounding box的打分确定proposal
2)种子点分割:multiple seed regions开始,产生分离的前景-背景分割作为每个种子点
3)超像素融合:用各种heuristics算法对过度分割进行融合。
不同proposal算法的不同主要在于产生proposal方法(bounding box/segmentation mask)和proposal是否进行排序。本文的主要不同在于和一般的segmentation mask产生proposal方法相比,本文并不适用low-level segmentation,而是使用deep-network结构。即产生segmentation的proposal部分已经使用深度网络。
本文认为该算法优于其他。
样本包含3个部分:1)输入RGB图像patch:Xk;
2)对应图像patch的二维mask:Mk,Mk为{1,-1};
3)标签:Yk,Yk为{1,-1},来指明是否patch含有目标。
当一个patch Xk赋予的标签Yk=1,则说明他满足以下条件:1)输入patch大约中心包含目标;2)目标满满存在并在指定的尺度大小范围内。否则,即便目标一部分存在,Yk=-1。
网络结构:
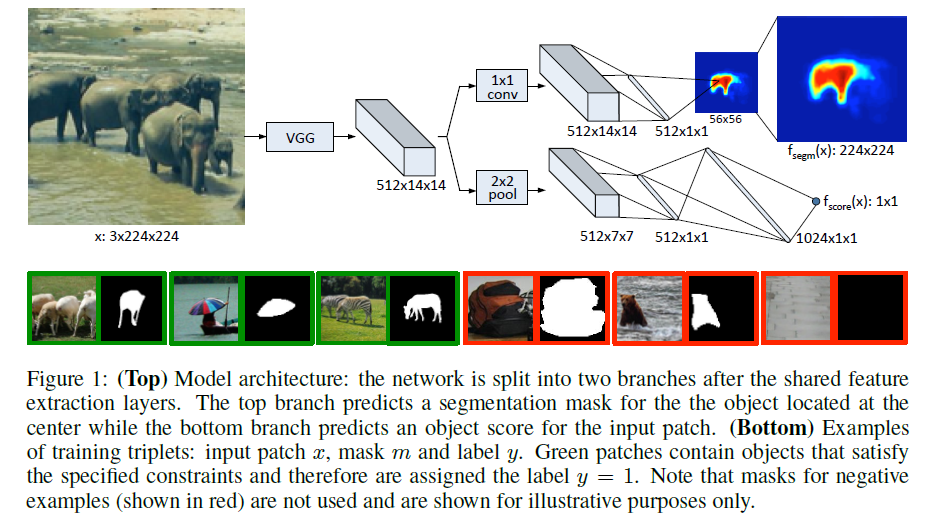
上图为本文的模型结构。其中,本文使用的网络结构(图中的前半部分)是VGG-A结构(包含8个3*3的卷积层,5个2*2的max-pooling层)。由于卷积层特征图提供的空间信息对于分割的重要性,本文去除了最后一个max-pooling层,因此最终使用4个pooling层的结构。
Segmentation:分割部分的网络如图中所示,由一个单独的1*1卷积层(包含ReLU非线性层)+分类层组成。分类的classification layer由h*w个像素分类器组成,每一个负责识别给定的像素是否属于patch中心的目标。每一个像素分类器都要能够充分利用整个feature map的信息,来获得对目标的完整的view。这里注明:和语义分割不同的是,本文的网络旨在获得单一目标,而不是多个目标。
这里还存在一个问题,每一个分类器只有一个对于目标的partial view,因此最后的分类器将存在大量多余参数。因此这里讲分类层改成2个线性层+1个非线性层,来减少参数。同时进一步降采样减少h*w的输出尺度来配合输入维度。
Scoring:这部分主要用来判断该图像patch满足条件:1)输入patch中心包含目标;2)在指定的尺度大小范围内。这部分主要由2*2的max-pooling层+2个全连接层(含ReLU非线性层)组成,输出为一个反应目标是否在输入patch中心的可能性分数。
Loss函数:
每个位置(Xk, Mk, Yk)的segmentation 网络+object分数的和。

从loss函数可以看出,网络尝试在每一个patch处产生一个segmentation mask,甚至当no known object is present.
Full Scene Inference:
有多个位置和尺度时,考虑解决方案是十分必要的。这里通过在多个location和scale下应用模型解决。下图展示了在单一图像尺度下多次运用模型下的segmentation输出(主要是在最后的全连接层得到特征图上多次处理得到分割结果):
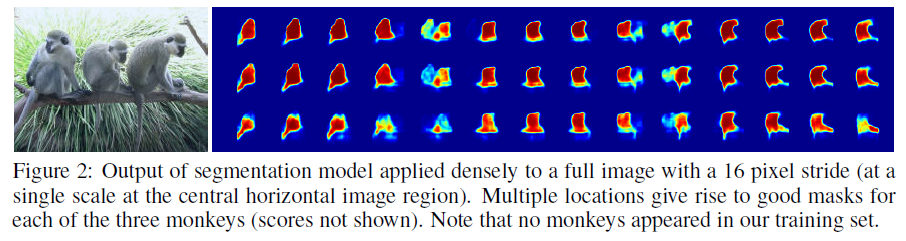
后面略去一些实施过程中的参数设置等具体问题,作者在文章中有非常仔细的介绍。
思路与结构部分的码字到此结束,实验结果如下图,具体实验结果的分析下篇详细介绍。
















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









