










看了这波作者的第二篇文章,不知不觉还是想看看他们的第一篇,ICCV2015的文章。
文章主要提出了一种通过利用不同层的CNN特征,进行 online visual tracking 的方法。
三个观察(之所以提出不同层CNN特征的利用,主要是基于下面3个观察):
(1)CNN 特征图的感受域很大,但是特征图中的激活点是很局部且稀疏的,被激活区域和目标有很强的相关性
(2)许多CNN 特征图是多噪声而不能用于区分特定目标与背景的
(3)高层往往包含不同目标类别的信息,而底层更容易区分同一类内的不同物体
作者实验发现,对于16层(13个卷积层+3个全连接层)的在ImageNet图像分类上预训练的VGG网络,conv4-3层和conv5-3层的特征刚刚好对于tracking很有意义。(conv4-3:第10层卷积层,conv5-3:第13层卷积层)
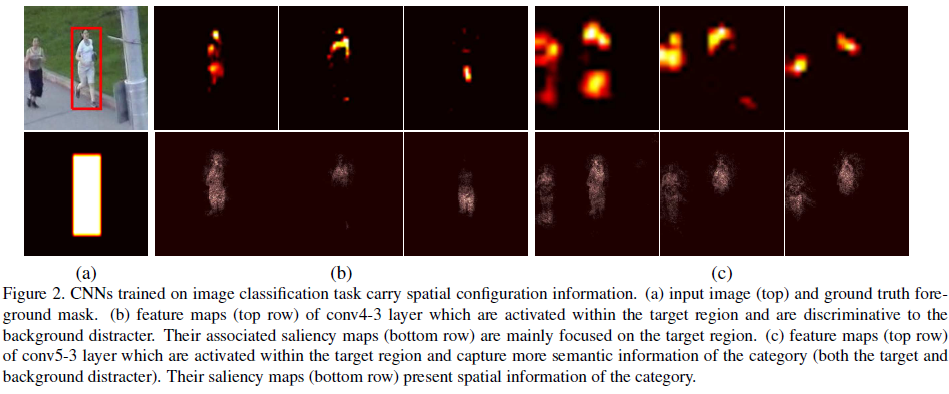
下图(b)conv4-3 layer可以用于该目标物体与背景区分;
图(c)conv5-3 layer可以用于该目标同类物体与非同类物体区分。
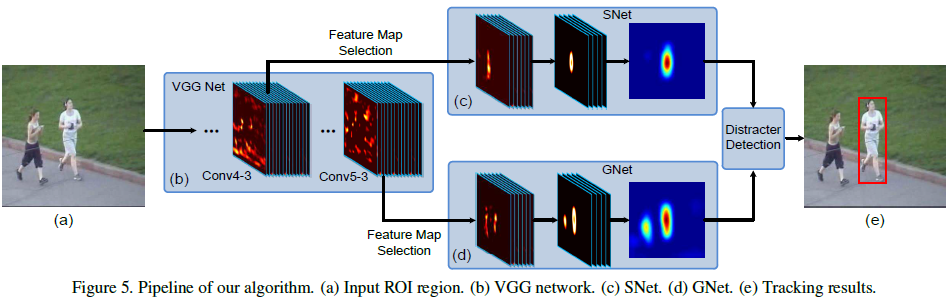
算法流程如下:
算法步骤如下:
(1)通过VGG网络获得conv4-3和conv5-3 layers
(2)A general network (GNet)通过conv5-3层获得同一类的信息,即用于不同类的区分
(3)A specific network (SNet)通过conv4-3层获得待跟踪目标与背景区分,即用于类内是否目标的区分
(4)GNet,SNet均采用第一帧进行初始化,通过第一帧图像得到一个前景heat map regression
(5)对于后面新的一帧,对以上一帧目标位置为中心的感兴趣区域(ROI)进行剪切,包含目标和背景上下文信息,通过全卷积网络进行传递
(6)GNet和SNet网络各自产生一个前景heat map,基于这两个热度图进行目标定位
(7)干扰项检测决定采用前一步产生的哪一个热图,作为最后目标的位置。
这里还有一个重要的细节,作者在后面详细介绍,概述就是(4)的heat map regression,通过第一帧具有groundtruth标记的图像,和热度图回归模型,sel-CNN,迭代得到该目标的热度图模型。即使得:输入为第一帧图像的sel-CNN,在迭代多次后输出热度图与groundtruth的热度图一致,数学上即为,该sel-CNN的Loss函数如下:
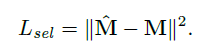
因此,当(4)完成后,对于新的一帧图像,输入sel-CNN,则认为输出的热度图反应了新一帧图像上目标的热度图,因此而通过输出的热度图,可以定位新帧的目标位置。
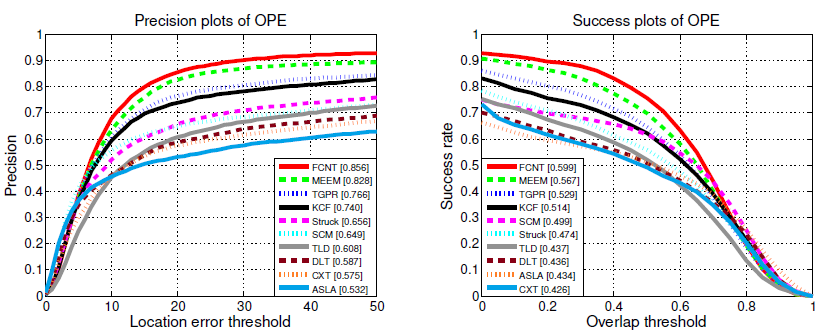
部分结果:















 5346
5346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









