










reference:http://blog.csdn.net/carrierlxksuper/article/details/48918297
两个属性
1)不同层上的CNN特征可以针对不同的tracking问题。越top层的特征越抽象,并且具有语义信息。这些特征的优势在于区分不同类别,同时对于形变和遮挡robust(下图a)。但是他们的缺点是无法区别类内的物体,比如不同人(下图b)。而底层的特征更多的是局部特征,可以帮助将目标从背景中分离出来(下图b)。但是无法处理目标外表剧烈变化(下图a)。于是在tracking中作者将两个特征根据干扰的情况,实时切换两种特征。

三个观察以及三个方面的贡献:
作者提到CNN网络在tracking的三个observations是非常重要的,因为这个启发了作者如何将imageNet pretrained CNN应用到visual tracking上去。同时作者cvpr2016的文章仍然是这个思路的延续[1].
下面说一下三个observations:
1.Although the receptive field 1 of CNN feature maps is large, the activated feature maps are sparse and localized. The activated regions are highly correlated to the regions of semantic objects . 意思就是说CNN的feature map来定位目标位置是可行的,这个是基础
2.Many CNN feature maps are noisy or unrelated for the task of discriminating a particular target from its background. 意思是feature map虽然有用,但是不是所有的都有用,有的是噪声或者冗余的,因此需要有个选择机制
3.Different layers encode different types of features. Higher layers capture semantic concepts on object categories, whereas lower layers encode more discriminative features to capture intra class variations. 意思是不同层feature map(conv4和conv5)具有不同的特性,要针对tracking出现的不同情况,利用不同的feature maps.
对应的三个贡献如下:
1) 分析了从大规模图像分类中学到的CNN特征,找出适合于visual tracking的一些属性。也就是不同的computer vision tasks需要 不同的特征。
2)作者提出了一种新的tracking的方法,同时考虑两个不同卷积层的特征输出,使他们相互补充来处理剧烈的外观变化和区分目标本身。
3)设计了一种方法来自动选择区分性的feature maps,同时忽略掉另外一个以及噪声。
整体框架:

解释如下:
第一步,对于给定的target,对VGG网络的conv4-3和conv5-3层执行feature map selection,目的是选出最相关的feature maps,具体原因就是构建一个L1范数的正则化目标函数。
第二步,在conv5-3的feature maps基础上,构造一个通用网络GNet,用来捕捉目标的类别信息
第三步,在conv4-3的feature maps基础上,构造一个特定网络SNet,用来将目标从背景中区分出来。
第四步,利用第一帧图像来初始化GNet和SNet,但是两个网络采用不用的更新方法
第五步, 对于新的一帧图像,感兴趣区域(ROI)集中在上一帧的目标位置,包含目标和背景上下文信息,通过全卷积网络传递。
第六步,GNet和SNet网络各自产生一个前景heat map。于是对下一帧目标位置的预测就基于这两个热图。
第七步,干扰项检测用来决定采用上一步产生的哪一个热图,从而决定最后目标的位置。
reference:
http://blog.csdn.net/cv_family_z/article/details/50748236(可参考多篇文章)
简而言之就是:
1.对conv5-3和conv4-3进行特组图筛选;
2.广义网络GNet根据conv5-3筛选建立;
3.针对性网络SNet根据conv4-3筛选建立;
4.SNet,GNet使用第一帧初始化并进行目标热度图回归。
5.对于新的一帧,上次位置的ROI抠取并送到全卷积网。
6.SNet,GNet 生成两个热度图,distractor选择策略决定哪个图使用。
特征图筛选
sel-CNN筛选conv4-3,conv5-3。最小化目标热度图与预测热度图的损失,使用BP学习模型参数,根据特征图对损失函数的影响选择特征图:
Lsel=||M̂ −M||2
特征图变化带来的损失变化为:
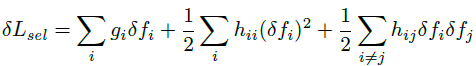
特征图中某个特征的显著性为:
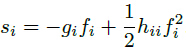
特征图的显著性为所有元素显著性的和:
Sk=∑x,ys(x,y,k)
位置预测
目标定位首先在GNet上进行,当前帧的位置由上一帧位置,使用高斯模型预测:
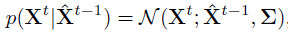
为了避免相似物体干扰,当目标外与目标内置信度比值超过一定阈值时,选择SNet预测最终位置:
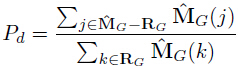
实验结果对比:
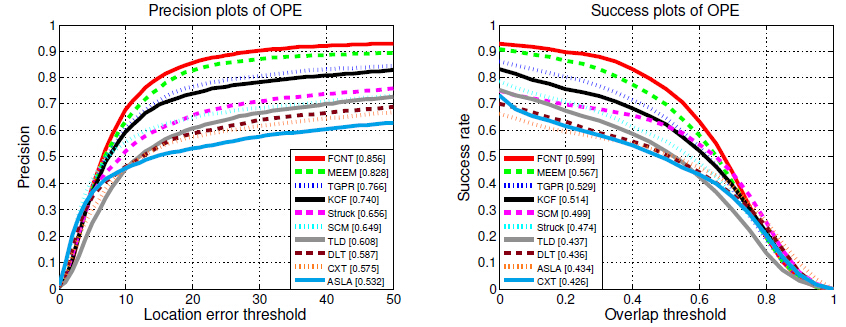
值得一提的是作者采用了很多细节的技术,这些对于提升效果很有帮助。
比如对于模型的更新,作者将目标漂移以及热图匹配同时考虑在内。
参考文献
[1] Lijun Wang, Wanli Ouyang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "STCT: Sequentially Training Convolutional Networks for Visual Tracking", In Proc. CVPR 2016.















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









