










本文主要解决未知目标在视频流中的跟踪问题,跟踪结果通过目标在单帧中的定位表示。重点提出了TLD的框架和P-N学习的方法。本笔记主要介绍TLD方法的思想部分。
Related Work:
1)目标跟踪
目标跟踪着眼于目标运动的消除,不同的方法主要利用目标的关键点,articulated models,轮廓信息,光流信息等完成。
本文采用目标几何形状和连续帧之间运动估计的模型,来完成跟踪。Template tracking是这类方法中最直接的一种,其通过一个目标模板来描述物体(如图像patch,颜色直方图),用目标模板和候选patch之间最小错误匹配变形的情况定义运动过程。
Template tracking在目标静态和运动时都有较好结果,但是其只描述物体的单一外形特征,因此为了对物体外形变化的适应,通常做法是添加generative models。
为了进一步适应不同场景下的跟踪(如大雾情况),现有方法又对环境进行建模模拟。这里有2种环境模拟:一种是建立在目标运动支持下的环境模型,该模型和目标本身密切相关,后期还可以解决感兴趣目标消失和巨大形变时的问题,另一种将环境看做负样本,让跟踪算子进行区别,最常见的是让跟踪算子完成目标和背景的二分类。对于后者中的区别环境类跟踪算子,分为静态的区分(Static discriminative trackers)和适应性区分(Adaptive discriminative trackers),前者跟踪前完成二分类问题的训练,对目标变化的适应性较差,后者的本质是update,在跟踪的同时完成分类。Adaptive discriminative trackers在各方面跟踪效果较好,但是在目标长时间离开屏幕后效果不佳,为了解决,一般在第一帧建立一个辅助的分类器或者训练一个独立分类器,和更新的分类器结合。
2)目标检测
目标检测对输入图片定位目标所在的位置,这里的目标概念多样,可以是定位某一个物体,也可以是一类物体。目标检测的方法通常基于图像特征提取或者滑动窗,特征提取类方法的流程为特征提取-特征识别-模型拟合,滑动窗类方法对输入图片扫描出一个个小窗口,对每一个窗口判断是否包含目标。(本文是2012年的,较早,看得出related work都比较陈旧,是当时的技术概况)
3)机器学习
传统的目标检测是在大量样本上训练的,但是本文希望实现的是在视频流的第一帧标记的样本训练,即半监督学习,需要同时利用标记和没有标记的数据,常见的解决此问题算法有Expectation-Maximization (EM), Self-learning, Cotraining。
Tracking-Learning-Detection
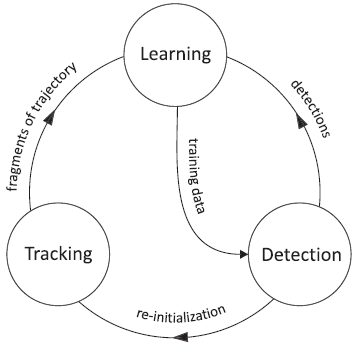
TLD是设计的一个视频流上未知物体长期跟踪的框架,如下图,Tracker在假设连续帧之间目标运动连续的基础上,完成对目标相邻帧之间的运动估计,在目标出镜头视角时,tracker容易出错。Detector对每一帧看做独立的,并扫描每一帧画面观察知否有之前学习到特征的目标,detector主要有误检和漏检两种错误。Learning监督tracker和detector两方面的成效,估计detector的错误,并产生训练样本使得未来这些错误得以避免。凭借learning部分,强化detector对目标的识别和背景的区分能力。
P-N Learning
该部分,主要探讨TLD 的learning部分实现,该部分旨在实现视频流中在线学习方法提高detector的效果。我们希望在每一帧都对当前detector进行评价,识别其错误,并更新使在未来减少错误。思想核心是:P-expert识别漏检(false negatives),N-expert识别误检(false positives)。
P-N learning主要由以下几个模块组成:1)学习过的分类器 classifier;2)training set:一组标记过的训练样本;3)Supervised training:从训练集上训练得到分类器的一个方法;4)P-N experts:在学习过程中产生正负样本的函数。其流程如下:
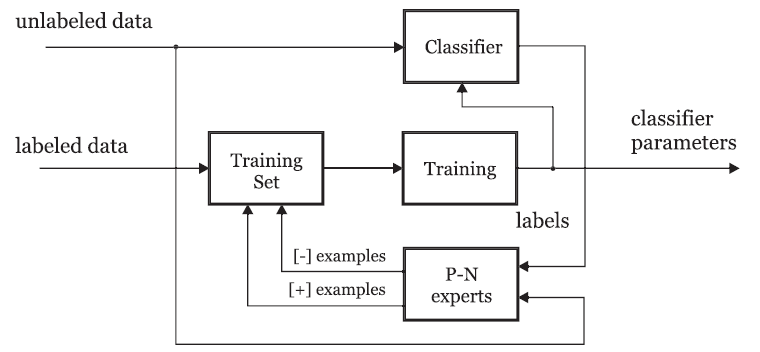
整个过程开始于对已经标记好的训练集的训练,得到一个分类器。然后在第k次迭代中,用分类器在未标记数据上分类,针对分类结果中的误检和漏检情况,通过P-expert和N-expert,将漏检补充到正样本中,错检部分到负样本中,进一步训练得到新的分类器。该部分即bootstrapping方法。
P-expert:利用视频中的temporal structure,并且假定物体的运动有一定的轨道。P-expert记录目标在前一帧中的位置,并通过frame-to-frame的跟踪算法,评价当前帧的位置是否合理。如果detector对现在位置无标记,即记为漏检,P-expert对该位置生成一个正样本。
N-expert:利用视频中的spatial structure,并假定物体只能出现在一个位置。因此N-expert对detector检测出的所有响应和tracker的响应一起进行分析,选择一个作为最佳。其他非最佳的响应,作为负样本。最佳响应处作为现阶段的位置,再启动tracker。
如下图是P-N expert的一个例子。

部分结果如下:
















 8317
8317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









