






ARM指令集介绍是本书的基础章节,因为这里提供的信息将贯穿整本书。因此,在深入探讨优化和高效算法之前,我们首先进行了介绍。本章介绍了最常见和最有用的ARM指令,并构建在上一章所涵盖的ARM处理器基础知识之上。第4章介绍了Thumb指令集,附录A给出了所有ARM指令的完整描述。
不同的ARM架构修订版本支持不同的指令。然而,新的修订版本通常会添加指令并保持向后兼容性。你在ARMv4T架构下编写的代码应该可以在ARMv5TE处理器上执行。表3.1提供了ARMv5E指令集架构(ISA)中可用的所有ARM指令的完整列表。该ISA包括所有核心ARM指令以及ARM指令集中的一些新功能。"ARM ISA"列出了引入该指令的ISA修订版本。一些指令在后续架构中具有扩展功能;例如,CDP指令有一个名为CDP2的ARMv5变体。类似地,像LDR这样的指令具有ARMv5的扩展,但不需要新的或扩展的助记符。

我们使用具有预条件和后置条件的示例来说明处理器的操作,描述指令或指令执行之前和之后的寄存器和内存。我们将以0x为前缀表示十六进制数,以0b为前缀表示二进制数。示例遵循以下格式:
PRE <预条件>
<指令/指令集>
POST <后置条件>
在<预条件>和<后置条件>中,内存表示为 mem<数据大小>[地址]
这表示从给定字节地址开始的数据大小位内存。例如,mem32[1024]表示从1 KB地址开始的32位值。
ARM指令处理寄存器中保存的数据,并且只通过加载和存储指令来访问内存。ARM指令通常使用两个或三个操作数。例如,下面的ADD指令将存储在寄存器r1和r2中的两个值(源寄存器)相加。它将结果写入寄存器r3(目标寄存器)。

在接下来的章节中,我们将按照指令类别来检视ARM指令的功能和语法,包括数据处理指令、分支指令、加载存储指令、软件中断指令以及程序状态寄存器指令。
3.1 Data Processing Instructions
数据处理指令用于在寄存器中操作数据。它们包括移动指令、算术指令、逻辑指令、比较指令和乘法指令。大多数数据处理指令可以使用移位器对其操作数进行处理。
如果在数据处理指令上使用S后缀,则会更新cpsr中的标志位。移动和逻辑操作会更新进位标志C、负数标志N和零标志Z。进位标志由移位操作的结果中的最后一位设置。N标志被设置为结果的第31位。如果结果为零,Z标志将被设置为1。
3.1.1 Move Instructions
Move是最简单的ARM指令。它将一个寄存器或立即数N的值复制到目标寄存器Rd中。该指令用于设置初始值和在寄存器之间传输数据。
语法: <instruction>{<cond>}{S} Rd, N

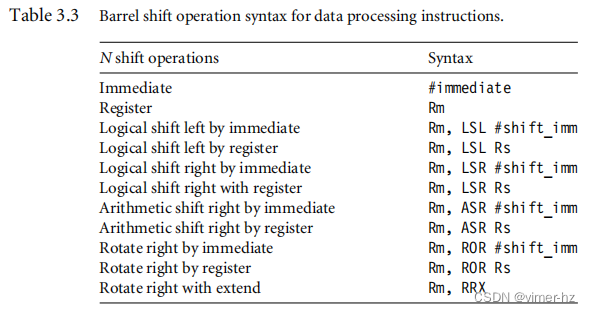
表3.3将在第3.1.2节中呈现,它给出了所有数据处理指令的第二个操作数N允许的完整描述。通常情况下,它可以是寄存器Rm或以#为前缀的常数。
示例3.1
这个例子展示了一个简单的移动指令。MOV指令将寄存器r5的内容复制到寄存器r7中,在这个例子中,将值5复制到寄存器r7,并覆盖了r7中原有的值8。
PRE
r5 = 5
r7 = 8
MOV r7, r5 ; let r7 = r5
POST
r5 = 5
r7 = 53.1.2 Barrel Shifter
在示例3.1中,我们展示了一个MOV指令,其中N是一个简单的寄存器。但是,N不仅可以是寄存器或立即数,还可以是经过移位器预处理后由数据处理指令使用的寄存器Rm。数据处理指令在算术逻辑单元(ALU)中进行处理。
ARM处理器的一个独特而强大的特性是能够在进入ALU之前,将一个源寄存器中的32位二进制模式向左或向右移动特定的位置数。这种移位操作提高了许多数据处理操作的功能和灵活性。
有些数据处理指令不使用移位器,例如乘法指令MUL、计算前导零CLZ和有符号饱和32位加法指令QADD。
预处理或移位操作发生在指令的周期内。这对于将常量加载到寄存器中,并实现快速乘法或2的幂次方除法特别有用。
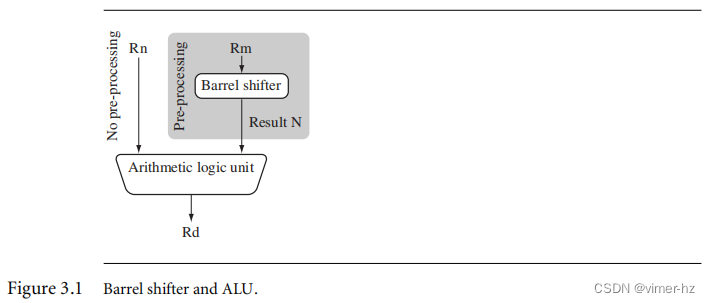
为了说明移位器,我们将采用图3.1中的例子,并在移动指令示例中添加一个移位操作。寄存器Rn在进入ALU之前没有经过任何寄存器的预处理。图3.1显示了ALU和移位器之间的数据流动。
示例3.2
PRE
r5 = 5
r7 = 8
MOV r7, r5, LSL #2 ; let r7 = r5*4 = (r5 << 2)
POST
r5 = 5
r7 = 20我们在将寄存器Rm移动到目标寄存器之前,对其应用逻辑左移(LSL)。这与将标准的C语言移位运算符<<应用于寄存器相同。MOV指令将移位运算符的结果N复制到寄存器Rd中。N表示在表3.2中描述的LSL操作的结果。

这个例子将寄存器r5乘以四,然后将结果放入寄存器r7。
你可以在移位器中使用的五种不同的移位操作在表3.2中进行了总结。
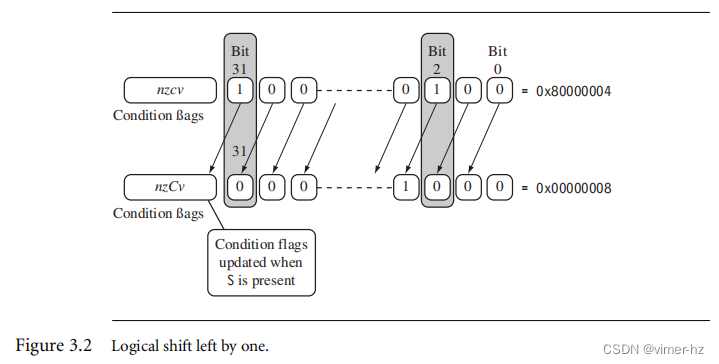
图3.2演示了逻辑左移一位。例如,位0的内容被移动到位1,位0被清除。C标志位会根据移出寄存器的最后一位进行更新。这是原始值的第(32-y)位,其中y是移位量。当y大于1时,将位移y个位置与执行一次位移一样,只是重复执行y次而已。
示例3.3
这个示例展示了一个MOVS指令,它将寄存器r1左移一位。这相当于将寄存器r1乘以21的值。正如你所看到的,因为指令助记符中有S后缀,所以C标志位在cpsr中得到了更新。
PRE
cpsr = nzcvqiFt_USER
r0 = 0x00000000
r1 = 0x80000004
MOVS r0, r1, LSL #1
POST
cpsr = nzCvqiFt_USER
r0 = 0x00000008
r1 = 0x80000004表3.3列出了数据处理指令中可用的不同移位操作的语法。第二个操作数N可以是以#为前缀的立即常数,寄存器的值Rm,或经过移位处理的Rm的值。
3.1.3 Arithmetic Instructions
算术指令实现了32位有符号和无符号值的加法和减法。
语法: <instruction>{<cond>}{S} Rd, Rn, N
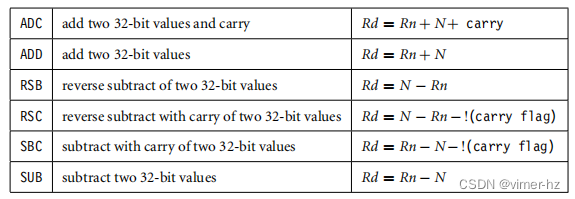
N是移位器操作的结果。移位器操作的语法在表3.3中显示。
示例3.4
这个简单的减法指令将寄存器r2中存储的值从寄存器r1中存储的值中减去。结果存储在寄存器r0中。
PRE
r0 = 0x00000000
r1 = 0x00000002
r2 = 0x00000001
SUB r0, r1, r2
POST
r0 = 0x00000001示例3.5
这个反向减法指令(RSB)将常数值#0减去r1的值,并将结果写入r0。你可以使用这个指令来对数字取反。
PRE
r0 = 0x00000000
r1 = 0x00000077
RSB r0, r1, #0 ; Rd = 0x0 - r1
POST
r0 = -r1 = 0xffffff89示例3.6
SUBS指令在递减循环计数器时非常有用。在这个例子中,我们从寄存器r1中存储的值1中减去立即值1。结果值0被写入寄存器r1。cpsr被更新,其中ZC标志被设置。
PRE
cpsr = nzcvqiFt_USER
r1 = 0x00000001
SUBS r1, r1, #1
POST
cpsr = nZCvqiFt_USER
r1 = 0x000000003.1.4 Using the Barrel Shifter with Arithmetic Instructions
ARM指令集中提供了广泛的第二操作数移位选项,这是一个非常强大的特性。示例3.7演示了在算术指令中使用内联移位器的用法。该指令将寄存器r1中存储的值乘以3。
示例3.7
首先,将寄存器r1向左移动一位,得到r1的两倍值。然后,ADD指令将移位操作的结果与寄存器r1相加。最终将计算结果传送到寄存器r0中,等于寄存器r1中存储值的三倍。
PRE
r0 = 0x00000000
r1 = 0x00000005
ADD r0, r1, r1, LSL #1
POST
r0 = 0x0000000f
r1 = 0x000000053.1.5 Logical Instructions
逻辑指令对两个源寄存器执行按位逻辑操作。
语法: <instruction>{<cond>}{S} Rd, Rn, N

示例3.8
这个示例展示了寄存器r1和r2之间的逻辑或操作。结果存储在寄存器r0中。
PRE
r0 = 0x00000000
r1 = 0x02040608
r2 = 0x10305070
ORR r0, r1, r2
POST
r0 = 0x12345678示例3.9
这个例子展示了一个更复杂的逻辑指令,称为BIC,它执行逻辑位清除操作。
PRE
r1 = 0b1111
r2 = 0b0101
BIC r0, r1, r2
POST
r0 = 0b1010
This is equivalent to
Rd = Rn AND NOT(N)在这个例子中,寄存器r2包含一个二进制模式,其中r2中的每个二进制1会清除寄存器r1中相应的位位置。这个指令在清除状态位时特别有用,并经常用于更改cpsr中的中断屏蔽位。逻辑指令仅在有S后缀时更新cpsr标志位。这些指令可以像算术指令一样使用移位的第二操作数。
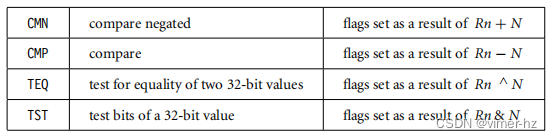
3.1.6 Comparison Instructions
比较指令用于将寄存器与32位值进行比较或测试。它们根据结果更新cpsr标志位,但不影响其他寄存器。在标志位设置后,可以通过条件执行来改变程序流程。关于条件执行的更多信息,请参阅第3.8节。对于比较指令,不需要使用S后缀来更新标志位。
语法: <instruction>{<cond>} Rn, N
N是移位操作的结果。移位操作的语法在表3.3中显示。
示例3.10
这个例子展示了一个CMP比较指令。在执行该指令之前,可以看到寄存器r0和r9都是相等的。执行前,z标志位的值为0(小写z表示)。执行后,z标志位变为1(大写Z表示)。这个变化表示相等。
PRE
cpsr = nzcvqiFt_USER
r0 = 4
r9 = 4
CMP r0, r9
POST
cpsr = nZcvqiFt_USERCMP指令实际上是一个减法指令,结果被丢弃;同样,TST指令是逻辑与操作,TEQ是逻辑异或操作。对于每个指令,结果被丢弃,但条件位在cpsr中被更新。重要的是要理解,比较指令只修改cpsr的条件标志位,不影响被比较的寄存器。
3.1.7 Multiply Instructions
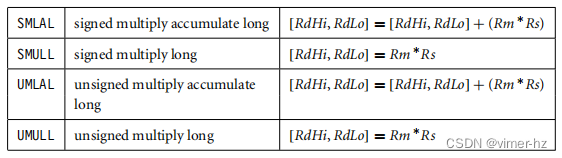
乘法指令将一对寄存器的内容相乘,并根据指令的不同将结果与另一个寄存器累加。长乘法将结果累积到代表64位值的一对寄存器中。最终结果放置在目标寄存器或一对寄存器中。
语法: MLA{<cond>}{S} Rd, Rm, Rs, Rn
MUL{<cond>}{S} Rd, Rm, Rs

Syntax: <instruction>{<cond>}{S} RdLo, RdHi, Rm, Rs
执行乘法指令所需的周期数取决于处理器的实现。对于某些实现,周期计时还取决于寄存器Rs中的值。有关周期计时的更多详细信息,请参阅附录D。
示例3.11
这个例子展示了一个简单的乘法指令,将寄存器r1和r2相乘,并将结果放置在寄存器r0中。在这个例子中,寄存器r1的值为2,r2的值也为2。结果4被放置在寄存器r0中。
PRE
r0 = 0x00000000
r1 = 0x00000002
r2 = 0x00000002
MUL r0, r1, r2 ; r0 = r1*r2
POST
r0 = 0x00000004
r1 = 0x00000002
r2 = 0x00000002长乘法指令(SMLAL、SMULL、UMLAL和UMULL)产生一个64位的结果。该结果太大,无法放入一个32位寄存器,因此结果被放置在两个标记为RdLo和RdHi的寄存器中。RdLo保存64位结果的低32位,而RdHi保存64位结果的高32位。示例3.12展示了一个长无符号乘法指令的示例。
示例3.12
该指令将寄存器r2和r3相乘,并将结果放置在寄存器r0和r1中。寄存器r0包含64位结果的低32位,而寄存器r1包含64位结果的高32位。
PRE
r0 = 0x00000000
r1 = 0x00000000
r2 = 0xf0000002
r3 = 0x00000002
UMULL r0, r1, r2, r3 ; [r1,r0] = r2*r3
POST
r0 = 0xe0000004 ; = RdLo
r1 = 0x00000001 ; = RdHi3.2 Branch Instructions
分支指令改变了程序的执行流程,用于跳转到不同的地址或调用一个子程序。这种类型的指令允许程序具有子例程、if-then-else结构和循环。执行流程的改变会使程序计数器PC指向一个新的地址。ARMv5E指令集包括四种不同的分支指令。
语法:
B{<cond>} label
BL{<cond>} label
BX{<cond>} Rm
BLX{<cond>} label | Rm

地址标签以带符号的PC相对偏移量的形式存储在指令中,并且必须在分支指令附近的32MB范围内。T代表cpsr中的Thumb位。当设置Thumb时,ARM会切换到Thumb状态。
示例3.13
这个例子展示了前向分支和后向分支。由于这些循环是特定地址的,我们不包括前置和后置条件。前向分支跳过了三个指令。后向分支创建了一个无限循环。
B forward
ADD r1, r2, #4
ADD r0, r6, #2
ADD r3, r7, #4
forward
SUB r1, r2, #4
backward
ADD r1, r2, #4
SUB r1, r2, #4
ADD r4, r6, r7
B backward分支指令用于改变执行流程。大多数汇编器通过使用标签来隐藏分支指令的编码细节。在这个例子中,"forward"和"backward"是标签。分支标签位于行的开头,用于标记一个地址,汇编器可以稍后使用该地址来计算分支偏移量。
示例3.14
带有链接的分支指令(BL)类似于B指令,但它会用返回地址覆盖链接寄存器LR,并执行一个子程序调用。此示例显示了一个简单的代码片段,使用BL指令跳转到一个子程序。要从子程序返回,您可以将链接寄存器复制到PC。
BL subroutine ; branch to subroutine
CMP r1, #5 ; compare r1 with 5
MOVEQ r1, #0 ; if (r1==5) then r1 = 0
:
subroutine
<subroutine code>
MOV pc, lr ; return by moving pc = lr分支交换(BX)和带链接的分支交换(BLX)是第三种类型的分支指令。BX指令使用存储在寄存器Rm中的绝对地址。它主要用于在Thumb代码中进行分支,如第4章所示。cpsr中的T位由分支寄存器的最低有效位更新。类似地,BLX指令使用最低有效位更新cpsr的T位,并额外设置链接寄存器以存储返回地址。
3.3 Load-Store Instructions
加载存储指令用于在内存和处理器寄存器之间传输数据。有三种类型的加载存储指令:单寄存器传输、多寄存器传输和交换。
3.3.1 Single-Register Transfer
这些指令用于在寄存器和内存之间传输单个数据项。支持的数据类型包括有符号和无符号的字(32位)、半字(16位)和字节。以下是各种加载存储单寄存器传输指令的语法:
语法:<LDR|STR>{<cond>}{B} Rd,addressing1
LDR{<cond>}SB|H|SH Rd, addressing2
STR{<cond>}H Rd, addressing2


示例: 3.15 LDR和STR指令可以在与要加载或存储的数据类型大小相同的边界对齐上加载和存储数据。例如,LDR只能在内存地址是四字节的倍数(0、4、8等)上加载32位字。下面是一个示例,首先从寄存器r1中的内存地址加载数据,然后将其存储回同一内存地址。
;
; load register r0 with the contents of
; the memory address pointed to by register
; r1.
;
LDR r0, [r1]
; = LDR r0, [r1, #0]
;
; store the contents of register r0 to
; the memory address pointed to by
; register r1.
;
STR r0, [r1]
; = STR r0, [r1, #0]第一条指令从存储在寄存器r1中的地址加载一个字,并将其放入寄存器r0中。第二条指令则相反,将寄存器r0中的内容存储到寄存器r1中包含的地址中。寄存器r1的偏移量为零。寄存器r1被称为基地址寄存器。
3.3.2 Single-Register Load-Store Addressing Modes
ARM指令集提供了多种内存寻址模式。这些模式包含一种索引方法:带写回的预索引(preindex with writeback)、预索引和后索引(详见表3.4)。
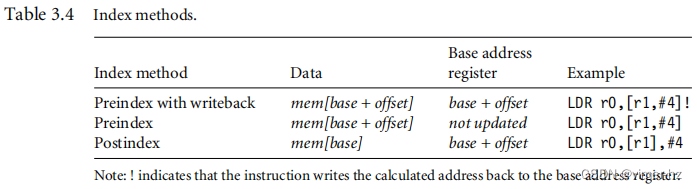
示例3.16中的带写回的预索引(preindex with writeback)模式通过将基址寄存器与地址偏移相加计算出一个地址,并将该新地址更新到基址寄存器中。相比之下,预索引(preindex)模式与带写回的预索引模式相同,但不会更新基址寄存器的值。后索引(postindex)模式只在使用地址后才更新基址寄存器的值。预索引模式适用于访问数据结构中的元素。后索引和带写回的预索引模式适用于遍历数组。
PRE
r0 = 0x00000000
r1 = 0x00090000
mem32[0x00009000] = 0x01010101
mem32[0x00009004] = 0x02020202
LDR r0, [r1, #4]!
Preindexing with writeback:
POST(1) r0 = 0x02020202
r1 = 0x00009004
LDR r0, [r1, #4]
Preindexing:
POST(2) r0 = 0x02020202
r1 = 0x00009000
LDR r0, [r1], #4
Postindexing:
POST(3) r0 = 0x01010101
r1 = 0x00009004示例3.15使用了预索引(preindex)方法。这个例子展示了每种索引方法对寄存器r1中保存的地址以及加载到寄存器r0中的数据产生的影响。每条指令都展示了相同前提条件下索引方法的结果。
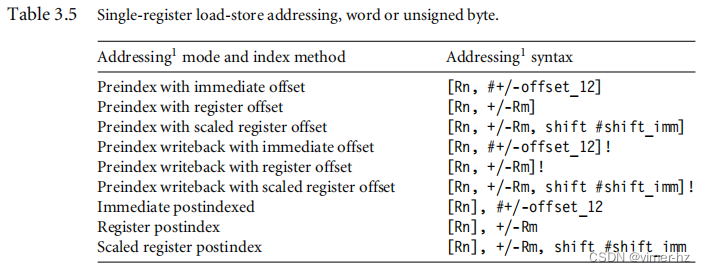
在特定的加载(load)或存储(store)指令中可用的寻址模式取决于指令类别。表3.5展示了加载和存储32位字或无符号字节的寻址模式。
"±"表示带符号的偏移量或寄存器,标识其是基址寄存器Rn的正偏移或负偏移。基址寄存器是指向内存中一个字节的指针,而偏移量指定了字节数。
"Immediate"表示地址是使用基址寄存器和指令中编码的12位偏移量计算得出的。"Register"表示地址是使用基址寄存器和特定寄存器的内容计算得出的。"Scaled"表示地址是使用基址寄存器和一个移位操作计算得出的。

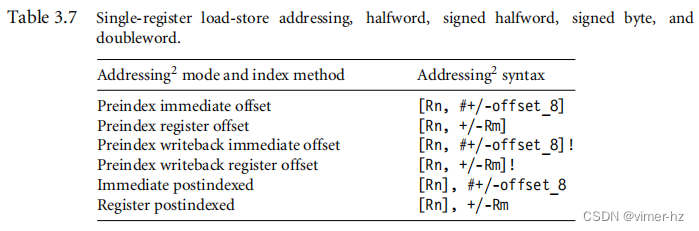
表3.6给出了LDR指令的不同变体的示例。表3.7展示了加载和存储指令使用16位半字或有符号字节数据时可用的寻址模式。

这些操作不能使用移位操作器。没有STRSB或STRSH指令,因为STRH存储有符号和无符号的半字;类似地,STRB存储有符号和无符号的字节。表3.8展示了STRH指令的变体。以上是例子中关于索引方法和寻址模式的说明。这些信息用于描述不同的内存访问方式和操作指令的使用规则。
3.3.3 Multiple-Register Transfer
加载-存储多个指令可以在一条指令中在内存和处理器之间传输多个寄存器。传输是从一个指向内存的基址寄存器Rn开始进行的。相比于逐个传输寄存器的单个传输指令,多寄存器传输指令在移动数据块、保存和恢复上下文和堆栈时更加高效。
加载-存储多个指令可能会增加中断延迟。ARM架构的实现通常不会在指令执行过程中中断它们。例如,在ARM7上,加载多个指令需要2 + Nt个周期,其中N是要加载的寄存器数量,t是每个连续访问内存所需的周期数。如果发生了中断,则中断对加载-存储多个指令没有影响,直到该指令执行完成。编译器(例如armcc)提供了一个开关来控制在加载-存储操作中传输的寄存器的最大数量,从而限制了最大的中断延迟。
语法如下:<LDM|STM>{<cond>}<addressing mode> Rn{!},<registers>{ˆ}

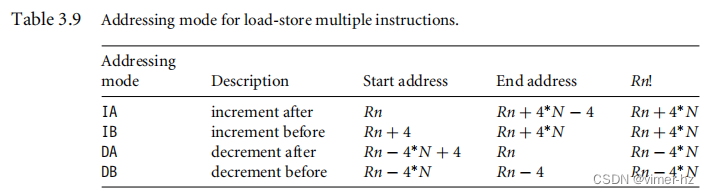
表格3.9展示了加载-存储多个指令的不同寻址模式。在这里,N是寄存器列表中的寄存器数量。可以将当前寄存器组中的任意子集传输到内存或从内存中获取。基址寄存器Rn确定加载-存储多个指令的源地址或目标地址。在传输之后,可以选择性地更新该寄存器。当寄存器Rn后面跟着感叹号(!)字符时,就会发生这种情况,类似于使用预索引和写回的单个寄存器加载-存储操作。
例如3.17
在这个例子中,寄存器r0是基址寄存器Rn,后面跟着感叹号(!),表示该寄存器在指令执行后将被更新。在加载多个指令中,你会注意到寄存器没有逐个列出。相反,“-”字符用于标识一系列寄存器。在本例中,范围从寄存器r1到r3(包括r1和r3)。
每个寄存器也可以使用逗号分隔,放在“{”和“}”括号中进行列表。
PRE
mem32[0x80018] = 0x03
mem32[0x80014] = 0x02
mem32[0x80010] = 0x01
r0 = 0x00080010
r1 = 0x00000000
r2 = 0x00000000
r3 = 0x00000000
LDMIA r0!, {r1-r3}
POST
r0 = 0x0008001c
r1 = 0x00000001
r2 = 0x00000002
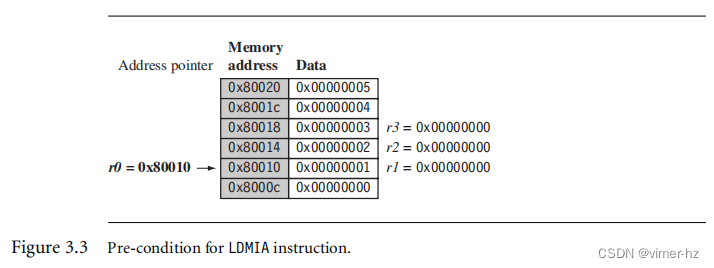
r3 = 0x00000003图3.3显示了一个图形表示。基址寄存器r0在PRE条件下指向内存地址0x80010。内存地址0x80010,0x80014和0x80018分别包含值1、2和3。执行加载多个指令后,寄存器r1、r2和r3包含了这些值,如图3.4所示。在最后一个加载的字之后,基址寄存器r0现在指向内存地址0x8001c。
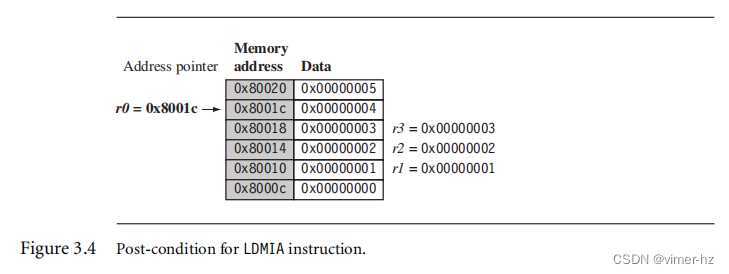
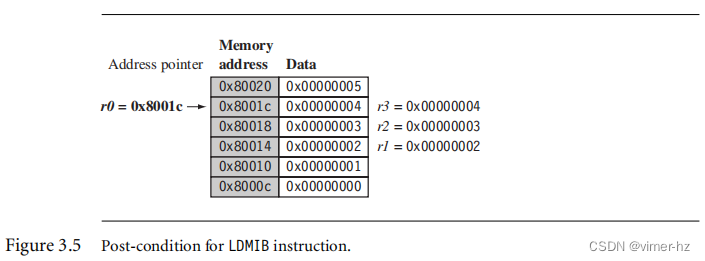
现在将LDMIA指令替换为在LDMIB指令之前进行递增的加载多个指令,并使用相同的PRE条件。忽略由寄存器r0指向的第一个字,并从下一个内存位置加载寄存器r1,如图3.5所示。执行后,寄存器r0现在指向最后加载的内存位置。这与LDMIA示例相反,它指向了下一个内存位置。
加载-存储多个指令的递减版本DA和DB会递减起始地址,然后按升序存储到内存位置。这相当于降序访问内存,但以相反的顺序访问寄存器列表。通过增量和递减加载多个指令,您可以正向或反向访问数组。它们还允许堆栈的推入和弹出操作,在本节后面会有进一步说明。
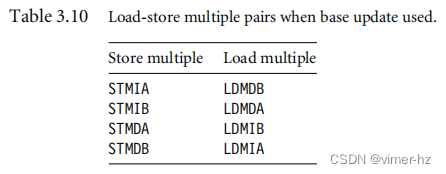
表格3.10显示了一组加载-存储多个指令对。如果使用带有基址更新的存储指令,那么相同数量寄存器的配对加载指令将重新加载数据并恢复基址指针。当您需要暂时保存一组寄存器并在以后恢复它们时,这是非常有用的。
例子3.18
这个例子展示了一个递增前STM指令,后跟一个递减后LDM指令。
PRE
r0 = 0x00009000
r1 = 0x00000009
r2 = 0x00000008
r3 = 0x00000007
STMIB r0!, {r1-r3}
MOV r1, #1
MOV r2, #2
MOV r3, #3
PRE(2) r0 = 0x0000900c
r1 = 0x00000001
r2 = 0x00000002
r3 = 0x00000003
LDMDA r0!, {r1-r3}
POST r0 = 0x00009000
r1 = 0x00000009
r2 = 0x00000008
r3 = 0x00000007STMIB指令将值7、8、9存储到内存中。然后我们破坏了寄存器r1到r3的值。
LDMDA指令重新加载了原始值并恢复了基址指针r0。
例子3.19
我们用一个块内存复制的例子来说明加载-存储多个指令的用法。这个例子是一个简单的例程,它将32字节的块从源地址位置复制到目标地址位置。
这个例子有两个加载-存储多个指令,它们使用相同的递增后寻址模式。
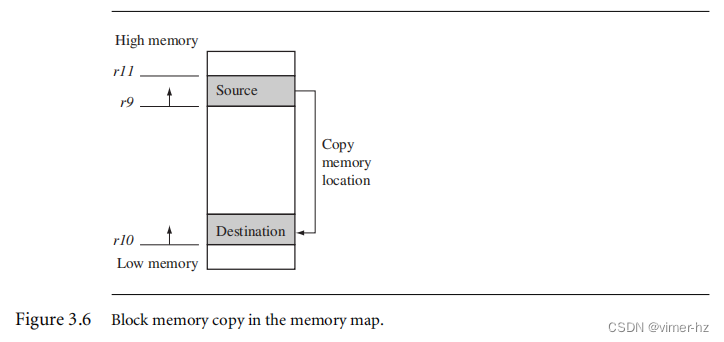
; r9 points to start of source data
; r10 points to start of destination data
; r11 points to end of the source
loop
; load 32 bytes from source and update r9 pointer
LDMIA r9!, {r0-r7}
; store 32 bytes to destination and update r10 pointer
STMIA r10!, {r0-r7} ; and store them
; have we reached the end
CMP r9, r11
BNE loop这个例程在执行代码之前依赖于寄存器r9、r10和r11的设置。
寄存器r9和r11确定要复制的数据,寄存器r10指向要复制数据的目标内存位置。LDMIA将寄存器r9指向的数据加载到寄存器r0到r7中。它还更新了r9,以指向下一个要复制的数据块。STMIA将寄存器r0到r7的内容复制到寄存器r10指向的目标内存地址。它还更新了r10,以指向下一个目标位置。CMP和BNE比较指针r9和r11,检查是否已经到达了块复制的末尾。如果块复制完成,则程序终止;否则,循环使用更新后的r9和r10的值重复执行。
BNE是带有条件助记符NE(不等)的分支指令B。如果前面的比较指令将条件标志设置为不相等,则执行分支指令。
图3.6显示了块内存复制的内存映射以及例程如何在内存中移动。理论上,这个循环可以用两条指令传输32字节(8个字),最大可能的吞吐量为每秒46 MB在33 MHz的速度下进行传输。这些数字假设存在一个完美的内存系统和快速的内存。
3.3.3.1 Stack Operations
ARM架构使用加载-存储多重指令来执行堆栈操作。弹出操作(从堆栈中移除数据)使用加载多重指令;类似地,推入操作(将数据放入堆栈)使用存储多重指令。
在使用堆栈时,您必须决定堆栈在内存中是向上增长还是向下增长。堆栈可以是升序(A)或降序(D)。升序堆栈向更高的内存地址增长,而降序堆栈向较低的内存地址增长。
当使用满堆栈(F)时,堆栈指针sp指向最后一个被使用或满的位置(即sp指向堆栈上的最后一个项目)。相反,如果使用空堆栈(E),sp指向第一个未使用或空的位置(即它指向堆栈上最后一个项目之后的位置)。
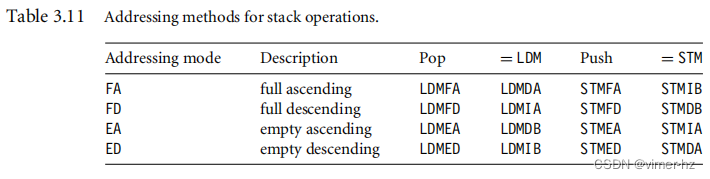
为了支持堆栈操作,有许多加载-存储多重寻址模式别名可用(参见表3.11)。在pop列旁边是实际的加载多重指令等效指令。例如,完整的升序堆栈将在加载多重指令后附加标注FA - LDMFA。这将被转换为LDMDA指令。
ARM规定了一个ARM-Thumb过程调用标准(ATPCS),定义了如何调用子程序以及如何分配寄存器。在ATPCS中,堆栈被定义为满降序堆栈。因此,LDMFD和STMFD指令分别提供了弹出和推入功能。
例子3.20
STMFD指令将寄存器推入堆栈并更新sp。图3.7显示了对满减序堆栈进行推入的情况。您可以看到,当堆栈增长时,堆栈指针指向堆栈中最后一个满的条目。
PRE
r1 = 0x00000002
r4 = 0x00000003
sp = 0x00080014
STMFD sp!, {r1,r4}
POST
r1 = 0x00000002
r4 = 0x00000003
sp = 0x0008000c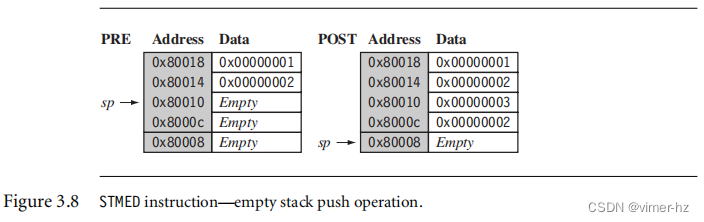
与之相反,例子3.21中的图3.8显示了在空堆栈上进行推入操作,使用的是STMED指令。STMED指令将寄存器推入堆栈,但会更新寄存器sp,使其指向下一个空位置。
PRE
r1 = 0x00000002
r4 = 0x00000003
sp = 0x00080010
STMED sp!, {r1,r4}
POST
r1 = 0x00000002
r4 = 0x00000003
sp = 0x00080008处理受检堆栈时,需要保留三个属性:堆栈基址、堆栈指针和堆栈限制。堆栈基址是堆栈在内存中的起始地址。堆栈指针最初指向堆栈基址;随着数据被推入堆栈,堆栈指针向内存递减,并持续指向堆栈顶部。 如果堆栈指针超过了堆栈限制,那么就会发生堆栈溢出错误。下面是一小段代码,用于检查降序堆栈的堆栈溢出错误:
; check for stack overflow
SUB sp, sp, #size
CMP sp, r10
BLLO _stack_overflow ; conditionATPCS将寄存器r10定义为堆栈限制或sl。这是可选的,因为只有在启用堆栈检查时才会使用它。BLLO指令是带链接的分支指令,加上条件词LO。如果在新项目被推入堆栈后,sp小于寄存器r10,则表示发生了堆栈溢出错误。如果堆栈指针回到堆栈基址之前,那么堆栈下溢错误就会发生。
3.3.4 Swap Instruction
交换指令是加载-存储指令的特例。它将内存中的内容与寄存器中的内容进行交换。这个指令是原子操作——它在同一个总线操作中读取和写入一个位置,防止其他指令在它完成之前读取或写入该位置。
语法:SWP{B}{<cond>} Rd,Rm,[Rn]

交换指令不能被其他任何指令或总线访问打断。我们说系统在事务完成之前"持有总线"。
示例3.22
交换指令将内存中的一个字加载到寄存器r0,并用寄存器r1覆盖内存。
PRE
mem32[0x9000] = 0x12345678
r0 = 0x00000000
r1 = 0x11112222
r2 = 0x00009000
SWP r0, r1, [r2]
POST
mem32[0x9000] = 0x11112222
r0 = 0x12345678
r1 = 0x11112222
r2 = 0x00009000这条指令在操作系统中实现信号量和互斥时非常有用。从语法可以看出,这条指令还可以有一个字节大小的限定符B,因此可以进行字和字节的交换。
示例3.23
这个示例展示了一个简单的数据保护器,可以用来防止其他任务对数据进行写入。SWP指令在事务完成之前"持有总线"。
spin
MOV r1, =semaphore
MOV r2, #1
SWP r3, r2, [r1] ; hold the bus until complete
CMP r3, #1
BEQ spin信号量指向的地址要么包含值0,要么包含值1。当信号量等于1时,表示该服务正在被另一个进程使用。该例程将不断循环,直到该服务被其他进程释放,也就是说,直到信号量地址位置包含值0为止。
3.4 Software Interrupt Instruction
软件中断指令(SWI)引发软件中断异常,为应用程序提供调用操作系统例程的机制。
语法:SWI{<cond>} SWI_number

当处理器执行SWI指令时,它将程序计数器pc设置为向量表中的偏移量0x8。该指令还强制处理器模式设置为SVC,允许以特权模式调用操作系统例程。
每个SWI指令都有一个关联的SWI编号,用于表示特定的函数调用或功能。
示例3.24
这是一个简单的SWI调用示例,使用SWI编号0x123456,被ARM工具包用作调试SWI。通常,SWI指令在用户模式下执行。
PRE
cpsr = nzcVqift_USER
pc = 0x00008000
lr = 0x003fffff; lr = r14
r0 = 0x12
0x00008000 SWI 0x123456
POST
cpsr = nzcVqIft_SVC
spsr = nzcVqift_USER
pc = 0x00000008
lr = 0x00008004
r0 = 0x12由于SWI指令用于调用操作系统例程,因此需要某种形式的参数传递。这是通过寄存器来实现的。在这个例子中,寄存器r0用于传递参数0x12。返回值也通过寄存器传递回来。
需要一个处理SWI调用的代码来处理调用SWI的操作。处理程序使用执行指令的地址确定SWI编号,该地址是从链接寄存器lr计算得出的。
SWI编号的确定方式为
SWI_Number = <SWI指令> AND NOT(0xff000000)
在这里,SWI指令是处理器执行的实际32位SWI指令。
示例3.25
这个例子展示了一个SWI处理程序实现的开头部分。代码片段确定所调用的SWI编号,并将该编号放入寄存器r10中。从这个示例可以看出,加载指令首先将完整的SWI指令复制到寄存器r10中。BIC指令屏蔽了指令的高位,只留下了SWI编号。我们假设SWI是从ARM状态调用的。
SWI_handler
;
; Store registers r0-r12 and the link register
;
STMFD sp!, {r0-r12, lr}
; Read the SWI instruction
LDR r10, [lr, #-4]
; Mask off top 8 bits
BIC r10, r10, #0xff000000
; r10 - contains the SWI number
BL service_routine
; return from SWI handler
LDMFD sp!, {r0-r12, pc}ˆ寄存器r10中的数字随后由SWI处理程序用于调用相应的SWI服务例程。
3.5 Program Status Register Instructions
ARM指令集提供了两个指令,用于直接控制程序状态寄存器(psr)。MRS指令将cpsr或spsr的内容传输到寄存器中;反过来,MSR指令将寄存器的内容传输到cpsr或spsr中。这些指令结合起来用于读写cpsr和spsr。
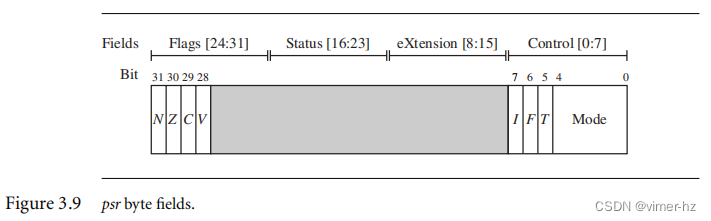
在语法中可以看到一个名为fields的标签。它可以是控制(c)、扩展(x)、状态(s)和标志(f)的任意组合。这些字段与psr的特定字节区域相关联,如图3.9所示。
语法:MRS{<cond>} Rd,<cpsr|spsr>
MSR{<cond>} <cpsr|spsr>_<fields>,Rm
MSR{<cond>} <cpsr|spsr>_<fields>,#immediate

c字段控制中断屏蔽、Thumb状态和处理器模式。
示例3.26展示了如何通过清除I屏蔽位来启用IRQ中断。此操作涉及使用MRS和MSR指令从cpsr读取然后写入。
示例3.26首先将cpsr复制到寄存器r1中。BIC指令清除r1的第7位。然后将寄存器r1复制回cpsr,从而启用IRQ中断。从这个示例可以看出,这段代码保留了cpsr中的所有其他设置,只修改了控制字段中的I位。
PRE
cpsr = nzcvqIFt_SVC
MRS r1, cpsr
BIC r1, r1, #0x80 ; 0b01000000
MSR cpsr_c, r1
POST
cpsr = nzcvqiFt_SVC这个示例是在SVC模式下的。在用户模式下,你可以读取cpsr的所有位,但只能更新条件标志字段f。
3.5.1 Coprocessor Instructions
协处理器指令用于扩展指令集。一个协处理器可以提供额外的计算能力,也可以用于控制内存子系统,包括高速缓存和内存管理。协处理器指令包括数据处理、寄存器传输和内存传输指令。我们只提供一个简要的概述,因为这些指令是特定于协处理器的。请注意,这些指令只被具有协处理器的核心使用。
语法:CDP{<cond>} cp, opcode1, Cd, Cn {, opcode2}
<MRC|MCR>{<cond>} cp, opcode1, Rd, Cn, Cm {, opcode2}
<LDC|STC>{<cond>} cp, Cd, addressing

在协处理器指令的语法中,cp字段表示协处理器编号,范围在p0到p15之间。opcode字段描述要在协处理器上执行的操作。Cn、Cm和Cd字段描述了协处理器内的寄存器。协处理器的操作和寄存器取决于你使用的具体协处理器。协处理器15(CP15)保留用于系统控制目的,如内存管理、写缓冲控制、缓存控制和识别寄存器。
示例3.27展示了将一个CP15寄存器复制到通用寄存器中的情况。
; transferring the contents of CP15 register c0 to register r10
MRC p15, 0, r10, c0, c0, 0在这里,CP15寄存器-0包含处理器的识别号。这个寄存器被复制到通用寄存器r10中。
3.5.2 Coprocessor 15 Instruction Syntax
CP15用于配置处理器核心,并有一组专用寄存器用于存储配置信息,如示例3.27所示。写入寄存器的值设置配置属性,例如打开缓存。
CP15被称为系统控制协处理器。MRC和MCR指令都用于读写CP15,其中寄存器Rd是核心目标寄存器,Cn是主寄存器,Cm是次级寄存器,opcode2是次级寄存器修改器。你偶尔会听到将次级寄存器称为“扩展寄存器”。
以下是将CP15控制寄存器c1的内容移动到处理器内核的寄存器r1中的指令:
MRC p15, 0, r1, c1, c0, 0
我们使用缩写符号来引用CP15,使得引用配置寄存器更易于跟踪。引用符号采用以下格式:
CP15:cX:cY:Z
第一个术语CP15将其定义为协处理器15。在分隔冒号之后的第二个术语是主寄存器。主寄存器X的值可以在0和15之间。第三个术语是次级或扩展寄存器。次级寄存器Y的值可以在0和15之间。最后一个术语opcode2是指令修改器,可以在0和7之间取值。某些操作也可能使用opcode1的非零值。我们将其写为CP15:w:cX:cY:Z。
3.6 Loading Constants
你可能已经注意到,ARM指令集中没有将32位常量移动到寄存器的直接指令。因为ARM指令的大小是32位,无法直接指定32位常量。
为了帮助编程,有两个伪指令可以将32位值移动到寄存器中。
语法:LDR Rd,=constant
ADR Rd,label

第一个伪指令使用可用的任何指令将32位常量写入寄存器。如果无法使用其他指令对常量进行编码,它会默认为内存读取操作。
第二个伪指令将相对地址写入寄存器,并使用PC相对表达式进行编码。
示例3.28
以下示例展示了一个LDR指令将32位常量0xff00ffff加载到寄存器r0中。
LDR r0, [pc, #constant_number-8-{PC}]
:
constant_number
DCD 0xff00ffff这个示例需要访问内存来加载常量,对于对时间非常敏感的程序可能会比较耗时。示例3.29展示了一种另外的方法,可以使用MVN指令将相同的常量加载到寄存器r0中。
示例3.29 使用MVN指令加载常量0xff00ffff。
PRE
none...
MVN r0, #0x00ff0000
POST
r0 = 0xff00ffff正如你所看到的,有多种替代方法可以避免访问内存,但这取决于你要加载的常量。编译器和汇编器使用巧妙的技术来避免从内存中加载常量。这些工具使用算法来找出生成寄存器中常量所需的最佳指令数量,并广泛使用移位器。如果这些方法无法生成常量,则从内存中加载。LDR伪指令将插入MOV或MVN指令来生成一个值(如果可能的话),或者生成一个带有PC相对地址的LDR指令,从字面常量池(嵌入在代码中的数据区域)中读取常量。
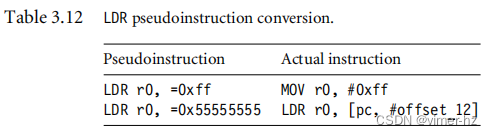
表3.12显示了两个伪代码转换。第一个转换生成一个简单的MOV指令;第二个转换生成一个PC相对加载指令。我们建议使用这个伪指令来加载常量。为了查看汇编器如何处理特定的加载常量,你可以通过反汇编器来传递输出,它将列出工具选择用于加载常量的指令。
另一个有用的伪指令是ADR指令,或者地址相关。该指令使用PC相对加法或减法,将给定标签的地址放入寄存器Rd中。
3.7 ARMv5E Extensions
ARMv5E扩展提供了许多新的指令(参见表3.13)。其中最重要的增强之一是对16位数据进行操作的带符号乘积累加指令。在许多ARMv5E实现中,这些操作只需要一个周期。
ARMv5E在操作16位值时提供了更大的灵活性和效率,这对于诸如16位数字音频处理等应用非常重要。
3.7.1 Count Leading Zeros Instruction
"Count Leading Zeros"(CLZ)指令用于计算从最高有效位到第一个置为1的位之间的零的数量。示例3.30展示了一个CLZ指令的示例。
示例3.30:
从这个例子中可以看出,第一个置为1的位之前有27个零。在需要对数字进行归一化的程序中,CLZ非常有用。
PRE
r1 = 0b00000000000000000000000000010000
CLZ r0, r1
POST
r0 = 273.7.2 Saturated Arithmetic
正常的ARM算术指令在整数值溢出时会进行循环。例如,0x7fffffff+1= -0x80000000。因此,在设计算法时,必须小心不要超过32位整数可表示的最大值。
示例3.31:
这个例子展示了超过最大值时会发生什么。
PRE
cpsr = nzcvqiFt_SVC
r0 = 0x00000000
r1 = 0x70000000 (positive)
r2 = 0x7fffffff (positive)
ADDS r0, r1, r2
POST
cpsr = NzcVqiFt_SVC
r0 = 0xefffffff (negative)在这个例子中,寄存器r1和r2包含正数。寄存器r2等于0x7fffffff,这是32位中可以存储的最大正值。在理想情况下,将这些数字相加应该得到一个很大的正数。然而,实际上这个值变为负数,并且溢出标志V被设置。
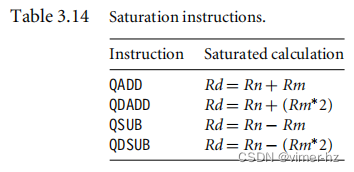
相比之下,使用ARMv5E指令你可以使结果饱和——一旦超过最大数值,结果将保持在0x7fffffff的最大值。这避免了需要额外的代码来检查可能的溢出的要求。表3.14列出了所有的ARMv5E饱和指令。
示例3.32: 这个例子展示了相同的数据被传递到QADD指令中。
PRE
cpsr = nzcvqiFt_SVC
r0 = 0x00000000
r1 = 0x70000000 (positive)
r2 = 0x7fffffff (positive)
QADD r0, r1, r2
POST
cpsr = nzcvQiFt_SVC
r0 = 0x7fffffff您会注意到饱和的数值返回在寄存器r0中。此外,Q位(cpsr的第27位)已被设置,表示发生了饱和。Q标志是粘滞的,直到明确清除之前都将保持设置状态。
3.7.3 ARMv5E Multiply Instructions
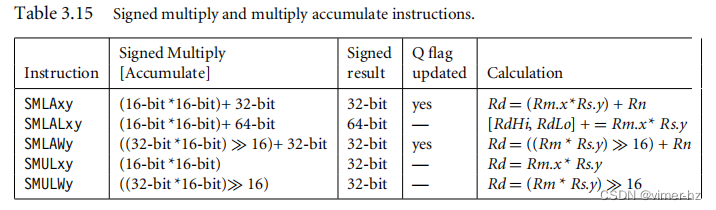
表3.15显示了ARMv5E乘法指令的完整列表。在表中,x和y分别选择32位寄存器中用于第一个和第二个操作数的哪16位。这些字段设置为字母T代表高16位,或字母B代表低16位。对于具有32位结果的乘加运算,Q标志指示累加是否溢出了有符号的32位值。
示例3.33: 这个例子展示了如何使用这些操作。该例使用了有符号乘积累加指令SMLATB。
PRE
r1 = 0x20000001
r2 = 0x20000001
r3 = 0x00000004
SMLATB r4, r1, r2, r3
POST
r4 = 0x00002004指令将寄存器r1的高16位与寄存器r2的低16位相乘,然后将结果加到寄存器r3中,并将最终结果写入目标寄存器r4。
3.8 Conditional Execution
大多数ARM指令都可以有条件地执行——您可以指定只有在条件码标志通过给定条件或测试时才执行指令。通过使用条件执行指令,您可以提高性能和代码密度。 条件字段是附加在指令助记符后面的两个字母缩写。默认助记符是AL,即总是执行。 条件执行减少了分支的数量,从而减少了流水线刷新的次数,从而提高了执行代码的性能。条件执行依赖于两个组件:条件字段和条件标志。条件字段位于指令中,条件标志位位于cpsr中。 示例3.34: 这个例子展示了带有EQ条件的ADD指令。只有当cpsr中的零标志被设置为1时,此指令才会被执行。
; r0 = r1 + r2 if zero flag is set
ADDEQ r0, r1, r2只有附加在助记符末尾的比较指令和带有S后缀的数据处理指令会更新cpsr中的条件标志。
示例3.35: 为了说明条件执行的优势,我们将使用这个示例中显示的简单C代码片段,并比较使用非条件和条件指令的汇编输出。
while (a!=b)
{
if (a>b) a -= b; else b -= a;
}让寄存器r1表示a,寄存器r2表示b。下面的代码片段展示了相同算法的ARM汇编版本。这个示例只在分支指令上使用条件执行。
; Greatest Common Divisor Algorithm
gcd
CMP r1, r2
BEQ complete
BLT lessthan
SUB r1, r1, r2
B gcd
lessthan
SUB r2, r2, r1
B gcd
complete
...现在让我们将代码与完全条件执行的版本进行比较。正如您所看到的,这显著减少了指令的数量:
gcd
CMP r1, r2
SUBGT r1, r1, r2
SUBLT r2, r2, r1
BNE gcd3.9 Summary
本章介绍了ARM指令集。所有的ARM指令长度都是32位。算术、逻辑、比较和移动指令都可以使用内联桶移位器,在第二个寄存器Rm输入ALU之前进行预处理。
ARM指令集有三种类型的载入-存储指令:单寄存器载入-存储、多寄存器载入-存储和交换。多载入-存储指令提供了对栈进行推入-弹出操作的功能。ARM-Thumb过程调用标准(ATPCS)将栈定义为一个完全降序的堆栈。
软件中断指令触发一个软件中断,将处理器强制置于SVC模式;该指令调用特权操作系统例程。程序状态寄存器指令用于写入和读取cpsr和spsr。还有一些特殊的伪指令,优化32位常数的加载。
ARMv5E扩展包括前导零计数、饱和和改进的乘法指令。前导零计数指令计算第一个二进制一之前的二进制零的数量。饱和处理超出32位整数值的算术计算。改进的乘法指令提供更好的灵活性,可以用于乘法16位值的操作。
大多数ARM指令都可以有条件地执行,这可以显著减少执行特定算法所需的指令数量。


















 2190
2190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









