






12.1极点几何 753
12.1.1整改 755
12.1.2平面扫描 757
12.2稀疏对应 760
12.2.1三维曲线和剖面 760
12.3密集通信 762
12.3.1相似性度量 764
12.4地方方法 766
12.4.1亚像素估计和不确定性 768
12.4.2应用:基于立体声的头部跟踪 769
12.5全球优化 771
12.5.1动态规划 774
12.5.2基于分割的技术 775
12.5.3应用:Z键和背景替换 777
12.6深度神经网络 778
12.7多视图立体 781
12.7.1场景流 785
12.7.2体积和三维表面重建 786
12.7.3从轮廓中提取形状 794
12.8单眼深度估计 796
12.9额外阅读材料 799
12.10Exercises 800

图12.1深度估计算法可以将一对彩色图像(a-b)转换为深度图(c) (Scharstein,Hirschm ller等,2014)©2014斯普林格,将一系列图像(d)转换为3D模型(e) (Knapitsch,Park等,2017)©2017 ACM,或将单个图像(f)转换为深度图(g) (Li,Dekel等,2019)©2019 IEEE。
立体匹配是通过找到图像中的匹配像素并将它们的二维位置转换为三维深度,从而构建场景的三维模型的过程。在第十一章中,我们介绍了恢复相机位置和构建场景或物体稀疏三维模型的技术。本章我们将探讨如何构建更完整的三维模型,例如,为输入图像中的像素分配相对深度的稀疏或密集深度图。我们还将讨论多视图立体算法,这些算法可以生成完整的三维体积或基于表面的对象模型,以及单目深度恢复算法,这些算法仅从一张图像推断出合理的深度。
为什么人们对深度估计和立体匹配感兴趣?从最早的视觉感知研究开始,我们就知道我们是根据左右眼外观差异来感知深度的。1作为一个简单的实验,将你的手指垂直放在眼前,交替闭上每只眼睛。你会注意到手指相对于场景背景在左右移动。同样的现象也出现在图12.1a-b所示的图像对中,其中前景物体相对于背景向左或向右移动。
正如我们即将看到的,在简单的成像配置下(无论是双眼还是直视前方的相机),水平运动或视差的量与观察者距离成反比。虽然视觉视差与场景结构之间的基本物理和几何关系已经非常清楚(第12.1节),但通过建立密集且准确的图像间对应关系来自动测量这种视差是一项具有挑战性的任务。
最早的立体匹配算法是在摄影测量领域开发的,用于从重叠的航拍图像中自动构建地形高程图。在此之前,操作员会使用摄影测量立体绘图仪,该设备向每只眼睛显示这些图像的偏移版本,并允许操作员在恒定高程轮廓上浮动一个点光标。全自动立体匹配算法的发展是这一领域的重大进步,使得航拍图像的处理速度更快、成本更低(Hannah 1974;Hsieh,McKeown和Perlant 1992)。
在计算机视觉领域,立体匹配一直是研究最为广泛且基础性的问题之一(Marr和Poggio 1976;Barnard和Fischler 1982;Dhond和Aggarwal 1989;Scharstein和Szeliski 2002;Brown、Burschka和Hager 2003;Seitz、Curless等2006),并且仍然是最活跃的研究领域之一(Poggi、Tosi等2021)。虽然摄影测量匹配主要集中在航空影像上,但计算机视觉应用还包括建模人类视觉系统(Marr 1982)、机器人导航和操作(Moravec 1983;Konolige 1997;Thrun、Montemerlo等2006;Janai,
1立体这个词来自希腊语,意思是“固体”;立体视觉就是我们感知固体形状的方式(Koenderink 1990)。

图12.2立体视觉的应用:(a)输入图像,(b)计算深度图,(c)多视图立体生成新视图(Matthies、Kanade和Szeliski 1989)©1989斯普林格;(d)两幅图像之间的视图变形(Seitz和Dyer 1996)©1996 ACM;(e–f)
3Dface建模(图片由Frdric Devernay提供);(g)z键实时和计算机
生成的图像(Kanade,Yoshida等人,1996)©1996 IEEE;(h-i)从虚拟现实中的多个视频流中构建建筑物三维表面模型(Kanade,Rander和Narayanan,1997)©1997 IEEE;(j)计算深度图以实现自主导航(Geiger,Lenz和Urtasun,2012)©2012 IEEE。
G ney等人(2020)和Figures12.2j和11.26,以及视图插值和基于图像的渲染(图12.2a-d),3D模型构建(图12.2e-f和h-i),将实拍与计算机生成的图像混合(图12.2g),以及增强现实(Valentin,Kowdle等人2018;Chaurasia,Nieuwoudt等人2020)和Figure11.28。
在本章中,我们描述了立体匹配背后的基本原理,遵循Scharstein和Szeliski(2002)提出的通用分类法。我们在第12.1节回顾了立体图像匹配的几何问题,即如何计算给定像素在一个图像中的可能位置范围,即其极线。我们介绍了如何预变形图像,使对应的极线重合(校正)。我们还介绍了一种称为平面扫描的一般重采样算法,该算法可用于具有任意相机配置的多图像立体匹配。
接下来,我们简要回顾用于稀疏立体匹配兴趣点和边缘特征的技术(第12.2节)。然后,我们将转向本章的主要主题,即以视差图形式估计大量像素级对应关系(图12.1c)。这首先涉及选择一个像素匹配标准(第12.3节),然后使用局部区域聚合(第12.4节)、全局优化(第12.5节)或深度网络(第12.6节),来帮助消除潜在匹配的不确定性。在第12.7节中,我们讨论了多视角立体技术,该技术利用超过两对图像来生成更高质量的深度图或完整的3D物体或场景模型(图12.1d-e)。最后,在第12.8节中,我们介绍了仅从单张图像推断深度的算法,这些算法现在已通过机器学习和深度网络成为可能。
在本章中,我们将经常提到用于开发深度推断算法并评估其性能的数据集和基准测试。其中最广泛使用且最具影响力的包括米德尔伯里立体和多视图数据集基准测试,这些是最早更新排行榜的数据集之一;EPFL多视图数据集;KITTI自动驾驶基准测试(包括立体、流场、场景流场等);DTU数据集;ETH3D基准测试;坦克与寺庙基准测试;以及BlendedMVS数据集,所有这些都在表12.1中进行了总结。更多数据集的指向可以参见
在Mayer,Ilg等人(2018)、Janai,G ney等人(2020)、Laga,Jospin等人(2020)和Poggi等人中,
Tosi等人(2021)。
给定一个图像中的像素,我们如何计算它在另一个图像中的对应关系?在第9章中,我们看到可以使用各种搜索技术来匹配基于
| 名称/网址 | 内容/参考 |
| 米德尔伯里立体声 https://vision.middlebury.edu/stereo 米德尔伯里多视图 https://vision.middlebury.edu/mview 伊诺克·普拉特自由图书馆 (不再活跃)KITTI 2015 http://www.cvlibs.net/datasets/kitti/eval-stereo-flow.php 丹麦技术大学 https://roboimagedata.compute.dtu.dk/?page-id=36 弗赖堡场景流 https://lmb.informatik.uni-freiburg.de/resources/datasets 三维 https://www.eth3d.net 坦克和寺庙 https://www.tanksandtemples.org 混合MVS https://github.com/YoYo000/BlendedMVS | 33高分辨率立体对 (Scharstein,Hirschm ller等人,2014) 从300+视图中扫描的6个3D对象(Seitz、Curless等人,2006) 6套室外多视角图像(Strecha,von Hansen等人,2008) 200个训练+ 200个测试立体声对(Menze和Geiger,2015) 124个场景,每个场景包含49-64张图像(Jensen,Dahl等人,2014) 39k合成立体声对(Mayer,Ilg等人,2018) 13次训练+ 12次测试高分辨率场景(Sch ps,Sch nberger等人,2017 ) 7次训练+ 14次测试4K视频场景(Knapitsch,Park等人,2017) 17k MVS图像,覆盖113个场景(Yao,Luo等人,2020) |
它们的局部外观以及邻近像素的运动。然而,在立体匹配的情况下,我们有一些额外的信息可用,即拍摄同一静态场景的照片的相机的位置和校准数据(第11.3节)。
我们如何利用这些信息来减少潜在对应点的数量,从而加快匹配速度并提高其可靠性?图12.3a展示了图像x0中的一个像素如何投影到另一张图像中的极线段。该线段一端由原始视线在无穷远处的投影p∞限定,另一端则由原始相机中心c0在第二台相机中的投影限定,这被称为极线e1。如果我们把第二张图像中的极线重新投影回第一张图像,就会得到另一条线(线段),这次由另一个对应的极点e0限定。将这两条线段延伸至无穷远,我们得到一对对应的极线(图12.3b),它们是两个图像平面与通过两台相机中心c0和c1以及兴趣点p的极平面相交的结果(Faugeras和Luong 2001;Hartley和Zisserman 2004)。
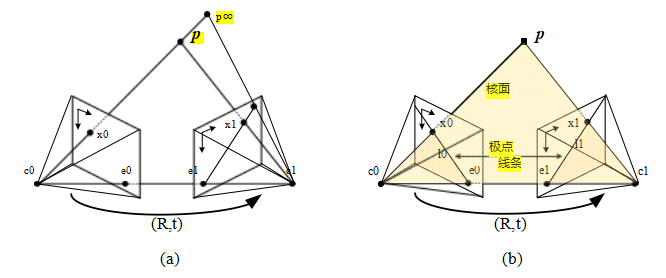
图12.3极线几何:(a)对应于一条射线的极线段;(b)对应的极线集合及其极平面。
正如我们在第11.3节中所见,一对相机的极线几何关系隐含于相机的相对姿态和校准中,可以使用基础矩阵(或校准后的本质矩阵,即五点或更多点)轻松计算出七个或更多点的匹配(Zhang1998a,b;Faugeras和Luong2001;Hartley和Zisserman2004)。一旦计算出这种几何关系,我们就可以利用一个图像中像素对应的极线来限制另一个图像中相应像素的搜索范围。一种方法是使用一般的对应算法,如光流(第9.3节),但仅考虑沿极线的位置(或将任何衰减的流向量投影回该线上)。
通过首先校正(即变形)输入图像,使相应的水平扫描线成为极线,可以得到更高效的算法(Loop和Zhang 1999;Faugeras和Luong 2001;Hartley和Zisserman 2004)。之后,可以在计算匹配分数的同时独立地匹配水平扫描线或水平移动图像(图12.4)。
校正两个图像的一种简单方法是首先旋转两个摄像机,使它们的视线垂直于连接摄像机中心c0和c1的直线。由于倾斜方向存在一定的自由度,因此应使用能够实现这一目标的最小旋转角度。接下来,
这在摄像机相邻时最为合理,尽管通过旋转摄像机,可以对任何未过度倾斜或尺度变化不大的摄像机对进行校正。在后一种情况下,使用平面扫描(见下文)或假设三维空间中的小平面区域位置(Goesele,Snavely等,2007)可能更为合适。

图12.4 Loop和Zhang(1999)提出的多级立体校正算法©
1999 IEEE。(a)原始图像对叠加了几条极线;(b)图像变换使极线平行;(c)图像校正使极线水平且垂直对应;(d)最终校正以最小化水平失真。
确定光轴上的期望扭曲,使向上向量(相机y轴)垂直于相机中心线。这确保了相应的极线是水平的,并且无穷远处点的视差为0。最后,如有必要,重新缩放图像以适应不同的焦距,放大较小的图像以避免混叠。(此过程的详细信息可参见Fusiello、Trucco和Verri(2000)及练习12.1。)当有关成像过程的更多信息可用时,例如图像是在共面的摄影板上形成的,可以开发更专业和准确的算法(Luo、Kong等人,2020)。需要注意的是,通常情况下,除非所有图像的光学中心共线,否则无法同时校正任意一组图像,尽管旋转相机使其指向同一方向可以将相机间的像素移动减少到平移和缩放。
由此产生的标准校正几何被用于许多立体相机设置和立体算法中,并导致3D深度Z和视差d之间非常简单的反向关系,
(12.1)
其中,f是焦距(以像素为单位),B是基线,和
x, = x + d(x, y), y, = y (12.2)

图12.5典型视差空间图像(DSI)的切片(Scharstein和Szeliski
2002)©2002斯普林格:(a)原始彩色图像;(b)地面真实视差;(c–e)=10、16、21的三个(x,y)切片;(f)y=151的一个(x,d)切片((b)中的虚线)。在(c–e)中可以看到各种深色(匹配)区域,例如书架、桌子和罐子,以及头部雕像,在(f)中可以看到三个视差水平作为水平线。DSIs中的深色条带表示在此视差下匹配的区域。(较小的深色区域通常是无纹理区域的结果。)鲍比克和因蒂勒(1999)讨论了更多关于DSI的例子。
描述了左右图像中对应像素坐标之间的关系(Bolles、Baker和Marimont,1987;Okutomi和Kanade,1993;Scharstein和Szeliski,2002)。从一组图像中提取深度的任务就变成了估计视差图d(x,y)。
校正后,我们可以轻松比较对应位置(x,y)和(x,y,)=(x+d,y)的像素相似度,并将它们存储在视差空间图像(DSI)C(x,y,d)中以供进一步处理(图12.5)。视差空间(x,y,d)的概念可以追溯到早期的立体匹配研究(Marr和Poggio 1976),而视差空间图像(体)的概念通常与Yang、Yuille和Lu(1993)以及Intille和Bobick(1994)相关联。
在匹配之前对图像进行预校正的替代方法是,在场景中扫过一组平面,并测量不同图像在重新投影到这些平面上时的光度一致性(图12.6)。这个过程通常被称为平面扫描算法(Collins1996;Szeliski和Golland1999;Saito和Kanade1999)。
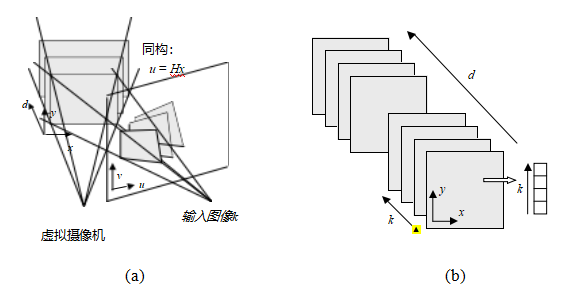
图12.6在场景中扫过一组平面(Szeliski和Golland 1999)©1999斯普林格出版社:(a)从虚拟摄像机看到的平面集合会在其他任何源(输入)相机图像中诱导出一组单应性。(b)来自所有其他相机的扭曲~图像可以堆叠成一个广义视差空间体I(x,y,d,k),该空间体由像素位置(x,y)、视差d和相机k编索引。
正如我们在第2.1.4节中介绍的那样,其中我们引入了投影深度(也称为平面加视差(Kumar、Anandan和Hanna1994;Sawhney~ 1994;Szeliski和Coughlan 1997)),一个满秩的4×4投影矩阵P的最后一行可以设置为任意平面
方程p3 = s3 [0 jc0]。由此得到的四维射影变换(共线变换)
(2.68)将三维世界点p = (X,Y,Z,1)映射到屏幕坐标xs =(xs,ys,1,d),其中投影深度(或视差)d(2.66)在参考平面上为0(图2.11)。
如图12.6a所示,通过一系列视差假设对d进行扫描,对应于将每个输入图像映射到定义视差空间的虚拟相机P上,通过一系列单应性(2.68–2.71),
k
~ k -1xs = k
如图2.12k所示,源图像和虚拟
(参考
)图像(Szeliski和Golland 1999)。齐次变换族Hk (d) = Hk + tk [0 0 d]通过添加一个秩为1的矩阵参数化,彼此之间通过平面同构关系相连(Hartley和Zisserman 2004,A5.2)。
虚拟摄像机的选择和参数化取决于应用,这也是该框架具有很大灵活性的原因。在许多应用中,其中一个输入摄像机(
研究的现象,但如果眼睛向内倾斜,垂直差异是可能的。
参考相机)被使用,从而计算出与输入图像之一注册的深度图,该深度图可以用于基于图像的渲染(第14.1节和第14.2节)。在其他应用中,例如视频会议中的视线校正视图插值(第12.4.2节)(Ott、Lewis和Cox 1993;Criminisi、Shotton等2003),最好使用位于两个输入相机之间的中央相机,因为它提供了所需的每像素视差,以虚拟生成中间图像。
选择视差采样,即零视差平面的设置和整数视差的缩放,也取决于具体应用,通常设定为涵盖感兴趣的范围,即工作体积,同时将视差缩放到像素(或亚像素)位移以采样图像。例如,在机器人导航中使用立体视觉进行障碍物避让时,最方便的是设置视差来测量每个像素相对于地面的高度(Ivanchenko,Shen,和Coughlan 2009)。
随着每个输入图像被扭曲到由视差d参数化的当前平面~s上,它可以堆叠成一个广义视差空间图像I(x,y,d,k),以便进一步处理(图12.6b) (Szeliski和Golland 1999)。在大多数立体算法中,相对于参考图像Ir的光一致性(例如平方和或鲁棒差异)会被计算并存储在DSI中。
x, y)). (12.4)
然而,也可以计算其他统计量,如稳健方差、焦点或熵(第12.3.1节)(Vaish,Szeliski等,2006年),或者利用这种表示来推理遮挡问题(Szeliski和Golland,1999年;Kang和Szeliski,2004年)。广义DSI在我们回到第12.7.2节多视图立体话题时将特别有用。
当然,飞机并不是唯一可以用来定义感兴趣空间三维扫描的表面。圆柱面,特别是与全景摄影结合使用时(第8.2节),经常被采用(石黑、山本和辻1992;康和斯泽利斯基1997;舒姆和斯泽利斯基1999;李、舒姆等人2004;郑、康等人2007)。还可以定义其他流形拓扑结构,例如相机绕固定轴旋转的情况(塞茨2001)。
一旦计算出DSI,大多数立体对应算法的下一步是在视差空间d(x,y)中生成一个最佳描述场景表面形状的单值函数。这可以视为在视差空间图像中找到具有某些最优性质的表面,例如最低成本和最佳(分段)平滑度(Yang,Yuille,和Lu 1993)。图12.5展示了典型DSI的切片示例。更多此类图可以在Bobick和Intille(1999)的论文中找到。
早期的立体匹配算法基于特征,即首先使用兴趣点算子或边缘检测器提取一组潜在可匹配的图像位置,然后利用基于块的度量方法在其他图像中搜索对应位置(Hannah 1974;Marr和Poggio 1979;Mayhew和Frisby 1980;Baker和Binford 1981;Arnold 1983;Grimson 1985;Ohta和Kanade 1985;Bolles、Baker和Marimont 1987;Matthies、Kanade和Szeliski 1989;Hsieh、McKeown和Perlant 1992;Bolles、Baker和Hannah 1993)。这种对稀疏对应关系的限制部分是由于计算资源的限制,但也出于希望将立体算法产生的结果限制为高置信度匹配的愿望。在某些应用中,还希望匹配具有非常不同光照条件的场景,在这些情况下,边缘可能是唯一稳定的特征(Collins 1996)。这样的稀疏三维重建可以使用表面拟合算法进行插值,如第4.2节和第13.3.1节中讨论的那些。
最近在这个领域的工作主要集中在首先提取高度可靠的特征,然后使用这些特征作为种子来生成更多的匹配(Zhang和Shan2000;Lhuillier和
Quan2002;ech和ra2007
)或作为密集的每个像素深度求解器的输入(Valentin,
Kowdle等人(2018))。类似的方法也被扩展到宽基线多视图立体问题,并与3D表面重建(Lhuillier和Quan,2005;Strecha、Tuytelaars和Van Gool,2003;Goesele、Snavely等人,2007)或自由空间推理(Taylor,2003)相结合,详见第12.7节。
稀疏对应关系的另一个例子是轮廓曲线(或遮挡轮廓)的匹配,这些曲线出现在物体边界处(图12.7),以及内部自遮挡处,表面从摄像机视点偏离。
匹配轮廓曲线的难点在于,通常情况下,轮廓曲线的位置会随着相机视角的变化而变化。因此,直接在两张图像中匹配曲线,然后对这些匹配进行三角测量,可能会导致形状测量出错。幸运的是,如果有三个或更多间隔较近的帧,可以将局部圆弧拟合到相应边缘点的位置(图12.7a),从而直接从匹配中获得半密集的曲面网格(图12.7c和g)。此外,匹配这些曲线的一个优势是,只要前景和背景颜色之间有明显的差异,就可以用于重建未纹理表面的形状。
多年来,已经开发出多种不同的技术,用于从轮廓曲线重建表面形状(Giblin和Weiss1987;Cipolla和Blake1992;Vaillant
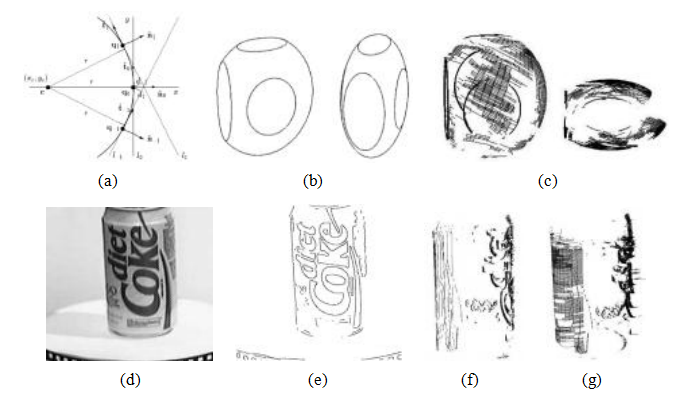
图12.7从遮挡轮廓重建表面(Szeliski和Weiss,1998)
©2002斯普林格:极线平面中的圆弧拟合;(b)假设一个截断侧面的椭球体及其椭圆形表面标记的合成示例;(c)从斜视和俯视角度看到的部分重建表面网格;(d)玻璃烟雾机转盘的真实图像序列;(e)提取的边缘;(f)部分重建的轮廓曲线;(g)部分重建的表面网格。(部分重建图为了不使图像过于拥挤而显示。)
以及Faugeras1992;Zheng1994;Boyer和Berger1997;Szeliski和Weiss1998)。Cipolla和Giblin(2000)描述了许多这些技术,以及相关的主题,如从轮廓曲线序列中推断相机运动。下面,我们总结了Szeliski和Weiss(1998)提出的方法,该方法假设一组离散的图像,而不是在连续微分框架中解决问题。
假设相机移动足够平滑,使得局部极线几何变化缓慢,即由连续的相机中心和待考虑的边缘所诱导的极线面几乎共面。处理流程的第一步是从每张输入图像中提取并连接边缘(图12.7b)。接下来,使用成对的极线几何、邻近性和(可选地)外观来匹配连续图像中的边缘。这在时空体积中提供了一组链接的边缘,有时称为编织墙(Baker1989)。
重建单个边缘的三维位置及其局部平面法线
对于曲率,我们将对应于其邻近点的视图光线投影到由相机中心、视图光线和相机速度定义的瞬时极线平面上,如图12.7a所示。然后,我们拟合一个切圆到这些投影线上,从而可以计算出三维点的位置(Szeliski和Weiss 1998)。
生成的3D点集及其空间(图像内)和时间(图像间)邻近点,构成了具有局部法线和曲率估计值的3D表面网格(图12.7c和g)。请注意,每当曲线是由表面标记或锐利折痕边缘引起时,而不是平滑的表面轮廓曲线,这会表现为0或小的曲率半径。这样的曲线会导致孤立的3D空间曲线,而不是平滑表面网格的元素,但在后续的表面插值阶段(第13.3.1节),仍可将其纳入3D表面模型中。
最近关于从RGB和RGB- D图像序列中重建三维曲线的例子包括(李、姚等,2018;刘、陈等,2018;王、刘等,2020),其中最新的一项研究甚至能够在没有纹理背景的情况下恢复相机姿态。当被建模的细小结构是平面流形,如叶子或纸张,而不是真正的三维曲线,例如电线时,特别定制的网格表示可能更为合适。
(Kim,Zimmer等人,2013;Y cer,Kim等人,2016;Y cer,Sorkine-Hornung等人,2016),如图所示
在第12.7.2节和第14.3节中进行了更详细的讨论。
虽然稀疏匹配算法偶尔仍被使用,但如今大多数立体匹配算法都集中在密集对应上,因为这适用于基于图像的渲染或建模等应用。这个问题比稀疏对应更具挑战性,因为在无纹理区域推断深度值需要一定的猜测。(想象一下透过栅栏看到的纯色背景,它的深度应该是多少?)
在本节中,我们回顾了由Scharstein和Szeliski(2002)首次提出的密集对应算法的分类体系。该分类体系包含一组算法“构建模块”,可以从中构建出大量算法。它基于这样的观察:立体算法通常执行以下四个步骤中的某些子集:
1.匹配成本计算;
2.成本(支持)聚合;
3.差异计算与优化;
4.差异细化。
例如,局部(基于窗口的)算法(第12.4节),其中给定点的视差计算仅依赖于有限窗口内的强度值,通常通过聚合支持来隐式假设平滑性。这些算法中的一些可以清晰地分解为步骤1、2、3。例如,传统的平方差之和(SSD)算法可以描述为:
1.匹配成本是给定视差下强度值的平方差。
2.聚合是通过在具有恒定视差的正方形窗口上求匹配成本之和来完成的。
3.通过选择每个像素的最小(获胜)聚合值来计算差异。
然而,一些局部算法结合了步骤1和2,并使用基于支持区域的匹配成本,例如归一化互相关(Hannah 1974;Bolles、Baker和Hannah 1993)以及秩变换(Zabih和Woodfill 1994)和其他序数度量(Bhat和Nayar 1998)。(这也可以视为预处理步骤;见第12.3.1节。)
另一方面,全局算法明确地假设平滑性,然后解决一个全局优化问题(第12.5节)。这类算法通常不执行聚合步骤,而是寻找一种视差分配(步骤3),以最小化由数据(步骤1)项和平滑性项组成的全局成本函数。这些算法之间的主要区别在于所使用的最小化过程,例如模拟退火(Marroquin、Mitter和Poggio 1987;Barnard 1989)、概率(平均场)扩散(Scharstein和Szeliski 1998)、期望最大化(EM)(Birchfield、Natarajan和Tomasi 2007)、图割(Boykov、Veksler和Zabih 2001)或循环信念传播(Sun、Zheng和Shum 2003),仅举几例。
在这两大类之间,存在一些迭代算法,它们不明确指定要最小化的全局函数,但其行为与迭代优化算法非常相似(Marr和Poggio 1976;Zitnick和Kanade 2000)。层次(粗到细)算法类似于这些迭代算法,但通常在图像金字塔上操作,其中较粗层次的结果用于限制更精细层次的局部搜索(Witkin、Terzopoulos和Kass 1987;Quam 1984;Bergen、Anandan等1992)。此外,在局部和全局方法之间还存在半全局匹配(SGM)(Hirschm ller 2008),该方法通过一维优化近似最小化二维成本函数(见第12.5.1节),以及避免探索整个搜索空间的方法,例如PatchMatch双目(Bleyer、Remann和Rother 2011)和局部平面扫描(LPS)。
(Sinha、Scharstein和Szeliski2014)。还开发了大量用于立体匹配的神经网络算法,我们将在第12.6节中回顾这些算法。
虽然大多数立体匹配算法针对参考输入图像生成单一视差图,或编码连续表面的视差空间路径(图12.13),但少数算法还计算每个像素的分数不透明度值以及深度和颜色(Szeliski和Golland 1999;Zhou、Tucker等2018;Flynn、Broxton等2019)。由于这些方法与体重建技术密切相关,我们将在第12.7.2节以及第14.2.1节关于基于图像的渲染层中讨论。
任何密集立体匹配算法的第一个组成部分是相似性度量,它通过比较像素值来确定它们对应的可能性。在本节中,我们将简要回顾第9.1节介绍的相似性度量,并提及一些专门为立体匹配开发的其他度量(Scharstein和Szeliski
2002年;Hirschm ller和Scharstein2009)。
最常见的基于像素的匹配成本包括平方强度差(SSD)(Hannah 1974)和绝对强度差(SAD)(Kanade 1994)。在视频处理领域,这些匹配标准被称为均方误差(MSE)和均绝对差(MAD);术语“位移帧差”也经常被使用(Tekalp1995)。
最近,提出了几种稳健的度量方法(9.2),包括截断二次函数和污染高斯分布(Black和Anandan 1996;Black和Rangarajan 1996;Scharstein和Szeliski 1998;Barron 2019)。这些度量方法之所以有用,是因为它们限制了聚合过程中不匹配的影响。Vaish、Szeliski等人(2006)比较了多种此类稳健度量方法,其中包括一种基于每个视差假设下像素值熵的新方法(Zitnick、Kang等人2004),该方法在多视图立体中特别有用。
其他传统的匹配成本包括归一化互相关(9.11)(Hannah 1974;Bolles、Baker和Hannah 1993;Evan Evangelidis和Psarakis 2008),其行为类似于平方差之和(SSD),以及基于二进制特征的二值匹配成本(即匹配或不匹配)(Marr和Poggio 1976),这些特征如边缘(Baker和Binford 1981;Grimson 1985)或拉普拉斯算子的符号(Nishihara 1984)。由于它们的区分能力较差,简单的二值匹配成本已不再用于密集立体匹配。 某些成本对相机增益或偏置的差异不敏感,例如基于梯度的测量(Seitz1989;Scharstein1994)、相位和滤波器组响应(Marr和Poggio1979;Kass1988;Jenkin、Jepson和Tsotsos1991;Jones和Malik1992)、滤波器

图12.8 Hirschm ller和Scharstein(2009)研究的各种相似性度量(预处理滤波器)©2009 IEEE。为了更好地可视化,(b)-(d)的对比度已提高。
这些方法包括移除常规或稳健(双边滤波)均值(Ansar,Castano和Matthies 2004;Hirschm ller和Scharstein 2009),密集特征描述符(Tola,Lepetit和Fua 2010),以及非参数度量如秩和普查变换(Zabih和Woodfill 1994),序数度量(Bhat和Nayar 1998),或熵(Zitnick,Kang等2004;Zitnick和Kang 2007)。普查变换将移动窗口内的每个像素转换为一个位向量,表示哪些邻居像素高于或低于中心像素,Hirschm ller和Scharstein(2009)发现这种变换对大规模、非平稳的光照变化具有很强的鲁棒性。图12.8展示了几种可以应用于图像以提高其在光照变化下的相似性的变换。
还可以通过执行预处理或迭代细化步骤来校正不同的全局摄像机特性,该步骤使用全局回归(Gennert1988)、直方图均衡(Cox、Roy和Hingorani 1995)或互信息(Kim、Kolmogorov和Zabih2003;Hirschm ller2008)估计图像间偏差增益变化。还提出了局部平滑变化补偿场(Strecha、Tuytelaars和Van Gool2003;Zhang、McMillan和Yu2006)。
为了补偿采样问题,即高频区域像素值的巨大差异,伯奇菲尔德和托马西(1998)提出了一种匹配成本,这种成本对图像采样的位移不那么敏感。他们不是仅仅比较整数倍移动的像素值(这可能会错过有效的匹配),而是将参考图像中的每个像素与另一图像的线性插值函数进行比较。关于这些及其他匹配成本的更详细研究见于斯泽利斯基和沙尔斯坦(2004)以及希施米勒和沙尔斯坦(2009)。特别是,如果你预期要匹配的图像之间存在显著的曝光或外观变化,那么在希施米勒和沙尔斯坦(2009)评估中表现良好的一些更稳健的度量方法,如普查变换(扎比和伍德菲尔德1994)、序数度量(巴特和纳亚尔1998)、双边减法(安萨尔、卡斯塔诺和马蒂斯2004)或层次互信息(希施米勒2008),应该被使用。有趣的是,当利用颜色信息时,似乎并没有帮助。
成本(Bleyer和Chambon 2010),尽管它对于聚合很重要(将在下一节讨论)。当匹配多于两对图像时,可以使用更复杂的相似性(照片一致性)度量变体,如第12.7节和(Furukawa和Hern ndez 2015,第2章)所述。
最近,深度学习在立体声方面的第一个成功之一就是学习
匹配成本。bontar和LeCun(2016)训练了一个神经网络来比较图像
在从中部伯里(Scharstein,Hirschm ller等人,2014)提取的数据上训练的补丁
以及KITTI(Geiger、Lenz和Urtasun2012)数据集。这种匹配成本仍然被广泛用于这两个基准上的顶级方法中。
局部和基于窗口的方法通过在DSI C(x,y,d)中的支撑区域求和或平均来聚合匹配成本。支撑区域可以是固定视差下的二维区域(有利于前平行表面),也可以是在x-y-d空间中的三维区域(支持倾斜表面)。二维证据聚合已使用方形窗口或高斯卷积(传统方法)、多个锚定在不同点的窗口,即可移动窗口(Arnold1983;Fusiello,Roberto和Trucco1997;Bobick和Intille1999)、具有自适应大小的窗口(Okutomi和Kanade1992;Kanade和Okutomi1994;Kang,Szeliski和Chai2001;Veksler2001,2003)、基于恒定视差连通组件的窗口(Boykov,Veksler和Zabih1998)、基于颜色分割的结果(Yoon和Kweon2006;Tombari,Mattoccia等2008),或带有引导滤波器的方法(Hosni,Rhemann等2013)实现。提出的三维支撑函数包括有限视差差异(Grimson1985)、有限视差梯度(Pollard,Mayhew,和Frisby1985)、Prazdny的相干性原理(Prazdny1985),以及Zitnick和Kanade(2000)的工作,其中包括可见性和遮挡推理。PatchMatch双目立体(Bleyer,Rhemann,和Rother2011)也在下文详细讨论,通过倾斜的支撑窗口在三维中进行聚合。
使用二维或三维卷积,C(x,y,d)= w(x,y,d)* C0(x,y,d),可以执行具有固定支持区域的聚合。 (12.5)
或者,在矩形窗口的情况下,使用高效的移动平均框滤波器(第3.2.2节)(Kanade,Yoshida等人,1996;Kimura,Shinbo等人,1999)。可移动窗口也可以通过使用可分离的滑动最小滤波器(图12.9) (Scharstein
4关于此类技术的两项调查和比较,请参见Gong、Yang等人(2007)和Tombari、Mattoccia等人(2008)的工作。
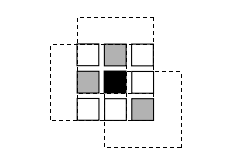
图12.9可移动窗口(Scharstein和Szeliski 2002)©2002斯普林格。尝试在黑色像素周围所有3×3移动窗口的效果,与在同一邻域内取所有居中(未移动)窗口的最小匹配得分相同。(为了清晰起见,这里仅显示了三个相邻的移动窗口。)

图12.10根据图像内容调整的聚合窗口大小和权重(Tombari,Mattoccia等人,2008)©2008 IEEE:(a)原始图像和选定的评估点;
(b)可变窗口(Veksler 2003);(c)自适应权重(Yoon和Kweon 2006);(d)基于分割(Tombari、Mattoccia和Di Stefano 2007)。注意,自适应权重和基于分割的技术会根据颜色相似的像素调整其支持范围。
以及Szeliski2002,第4.2节)。通过首先计算总和面积表(第3.2.3,3.30-3.32节)(Veksler2003),可以选择不同形状和大小的窗口,从而更高效地进行选择。选择合适的窗口非常重要,因为窗口必须足够大以包含足够的纹理,同时又不能太大以至于跨越深度不连续处(图12.10)。另一种聚合方法是迭代扩散,即反复将每个像素的成本与其邻近像素成本的加权值相加(Szeliski和Hinton 1985;Shah 1993;Scharstein和Szeliski 1998)。
贡、杨等人(2007)和汤巴里、马托奇亚等人(2008)比较的局部聚合方法中,维克勒(2003)的快速可变窗口方法和尹和奎恩(2006)开发的局部加权方法始终表现出在性能和速度之间最佳的平衡。局部加权技术,特别是
有趣的是,该方法没有使用具有均匀权重的方形窗口,而是让聚合窗口内的每个像素根据其颜色相似性和空间距离影响最终匹配成本,就像双边滤波一样(图12.10c)。实际上,他们的聚合步骤与对颜色/视差图像进行联合双边滤波密切相关,只是在参考图像和目标图像中都是对称进行的。汤巴里、马托奇亚和迪斯特凡诺(2007)提出的基于分割的聚合方法表现更好,尽管这种算法的快速实现尚未存在。另一种聚合方法是根据像素相似性沿一个或多个最小生成树进行聚合(杨2015;李、余等2017)。
在局部方法中,重点在于匹配成本计算和成本聚合步骤。计算最终的视差是简单的:只需在每个像素处选择与最小成本值相关的视差。因此,这些方法在每个像素处执行局部“胜者全得”(WTA)优化。这种方法(以及许多其他对应算法)的一个局限性是,匹配的独特性仅在一个图像(参考图像)中得到保证,而另一图像中的点可能与多个点匹配,除非
采用交叉检查和后续的孔洞填充(Fua1993;Hirschm ller和Scharstein
2009).
大多数立体对应算法在某种离散空间中计算一组视差估计值,例如整数视差(例外包括连续优化技术,如光流(Bergen,Anandan等1992)或样条(Szeliski和Coughlan 1997))。对于机器人导航或人员跟踪等应用,这些方法可能已经足够。然而,在基于图像的渲染中,这种量化地图会导致非常不吸引人的视图合成结果,即场景看起来由许多薄剪切层组成。为了改善这种情况,许多算法在初始离散对应阶段之后应用亚像素细化阶段。(另一种方法是从一开始就使用更离散的视差级别(Szeliski和Scharstein 2004)。)
亚像素视差估计可以通过多种方法计算,包括迭代梯度下降和在离散视差水平上拟合曲线(Ryan、Gray和Hunt 1980;Lucas和Kanade 1981;Tian和Huhns 1986;Matthies、Kanade和Szeliski 1989;Kanade和Okutomi 1994)。这提供了一种简单的方法,在不增加大量额外计算的情况下提高立体算法的分辨率。然而,为了有效工作,匹配的强度必须平滑变化,且这些估计计算区域必须位于同一(正确的)表面上。
关于拟合相关曲线的可取性,已经提出了一些问题
整数采样匹配成本(Shimizu和Okutomi2001)。当使用采样不敏感的差异度量时,这种情况甚至可能更糟(Birchfield和Tomasi 1998)。这些问题由Szeliski和Scharstein(2004)和Haller和Nedevschi(2012)进行了更深入的探讨。
除了子像素计算外,还有其他方法可以对计算出的视差进行后处理。可以通过交叉检查来检测遮挡区域,即比较左到右和右到左的视差图(Fua1993)。可以应用中值滤波器来清理虚假的不匹配,由于遮挡导致的空洞可以通过表面拟合或分配邻近视差估计来填补(Birchfield和Tomasi1999;Scharstein1999;Hirschm ller和Scharstein2009)。
另一种后处理方法,在后续处理阶段可能非常有用,是将置信度与逐像素深度估计(Figure12.11)关联起来。这可以通过观察相关曲面的曲率来实现,即在获胜视差处,DSI图像中的最小值有多强。Matthies、Kanade和Szeliski(1989)表明,在假设噪声较小、光度校准图像和密集采样的视差的情况下,局部深度估计的方差可以被估算为
(12.6)
其中a是DSI作为d的函数的曲率,可以使用局部方法来测量
抛物线拟合或通过平方窗口中的所有水平梯度,σ是变数-
图像噪声的强度可以通过最小SSD分数来估计。(参见第8.1.4节,(9.37),以及附录B.6。)多年来,提出了多种立体置信度测量方法。Hu和Mordohai(2012)及Poggi、Kim等人(2021)对此主题进行了详尽的综述。
实时立体算法的一个常见应用是跟踪用户与计算机或游戏系统互动的位置。使用立体技术可以显著提高此类系统的可靠性,相比之下,仅使用单目颜色和强度信息则效果较差(Darrell,Gordon等,2000)。一旦恢复这些信息,它们可以在多种应用中发挥作用,包括控制虚拟环境或游戏、在视频会议中校正视线方向以及背景替换。我们将在下文讨论前两个应用,并将背景替换的讨论推迟到第12.5.3节。
在计算机显示器上观看3D物体或环境时,使用头部跟踪来控制用户的虚拟视点有时被称为鱼缸虚拟现实,因为
图12.11立体深度估计的不确定性(Szeliski1991b):(a)输入图像;(b)估计的深度图(蓝色更近);(c)估计的置信度(红色更高)。如您所见,纹理区域的置信度更高。
用户仿佛置身于鱼缸中观察一个三维世界(Ware,Arthur,和Booth 1993)。早期版本的系统使用机械头部追踪设备和立体眼镜。如今,这些系统可以通过基于立体声的头部追踪来控制,而立体眼镜则被自动立体显示器所取代。头部追踪还可以用于构建“虚拟镜子”,用户可以通过各种视觉效果实时修改自己的头部(Darrell,Baker等1997)。
立体头追踪和三维重建的另一个应用是在注视校正(Ott,Lewis,和Cox 1993)。当用户参与桌面视频会议或视频聊天时,摄像头通常放置在显示器上方。由于人的眼睛注视着屏幕上的某个窗口,看起来像是他们向下看,而不是直接看向其他参与者。用两个或更多摄像头替换单个摄像头,可以在他们注视的位置构建虚拟视角,从而实现虚拟眼神交流。实时立体匹配用于构建精确的三维头部模型,视图插值(第14.1节)用于合成新的中间视图(Criminisi,Shotton等2003)。关于视频会议中注视校正的更近期出版物包括Kuster,Popa等(2012)和Kononenko和Lempitsky(2015),以及
全局立体匹配方法在视差计算阶段之后执行一些优化或迭代步骤,并且通常完全跳过聚合步骤,因为全局平滑约束具有类似的功能。许多全局方法是在能量最小化框架下构建的,在第4章(4.24–4.27)和第9章中我们看到,目标是找到一个解d,使全局能量最小化。
E (d) = ED (d) + λES (d). (12.7)
数据项ED (d)衡量了视差函数d与输入图像对的吻合程度。利用我们先前定义的视差空间图像,我们将这种能量定义为
(12.8)
其中C是(初始或聚合)匹配成本DSI。
平滑项ES (d)编码了算法所做出的平滑假设。为了使优化在计算上可行,平滑项通常仅限于测量相邻像素差异之间的差异,
其中P是视差差异的单调递增函数。也可以使用更大的邻域,例如N8,这可以产生更好的边界(Boykov和Kolmogorov 2003),或者使用二阶平滑项(Woodford、Reid等人2008),但这些项需要更复杂的优化技术。平滑函数的一个替代方案是使用低维表示,如样条(Szeliski和Coughlan 1997)。
在标准正则化(第4.2节)中,P是一个二次函数,这使得d在所有地方都是平滑的,但在物体边界处可能导致结果不佳。没有这个问题的能量函数被称为不连续性保持型,并基于稳健的P函数(Terzopoulos 1986b;Black和Rangarajan 1996)。Geman和Ge- man(1984)的开创性论文给出了这些能量函数的贝叶斯解释,并提出了一种基于马尔可夫随机场(MRFs)和附加线过程的不连续性保持型能量函数,这些附加的二进制变量控制是否施加平滑惩罚。Black和Rangarajan(1996)展示了如何用稳健的成对差异项替代独立线过程变量。
PD(d(x,y)—d(x + 1,y))·PI(ⅡI(x,y)—I(x + 1,y)Ⅱ), (12.10)
其中PI是强度差异的单调递减函数,在高强度梯度下降低平滑成本。这一想法(Gamble和Poggio 1987;Fua 1993;Bobick和Intille 1999;Boykov、Veksler和Zabih 2001)鼓励视差不连续性与强度或颜色边缘相吻合,并似乎解释了全局优化方法的一些良好性能。尽管大多数研究人员是启发式地设置这些函数,但Pal、Weinman等人(2012)展示了如何从真实视差图中学习此类条件随机场中的自由参数(第4.3节,(4.47))。
一旦定义了全局能量,可以使用多种算法来找到(局部)最小值。与正则化和马尔可夫随机场相关的传统方法包括连续法(Blake和Zisserman 1987)、模拟退火法(Geman和Geman 1984;Marroquin、Mitter和Poggio 1987;Barnard 1989)、最高置信度优先法(Chou和Brown 1990)以及平均场退火法(Geiger和Girosi 1991)。
最大流和图割方法已被提出用于解决一类特殊的全局优化问题(Roy和Cox 1998;Boykov、Veksler和Zabih 2001;Ishikawa 2003)。这些方法比模拟退火更高效,并且已经取得了良好的结果,基于循环信念传播的技术也是如此(Sun、Zheng和Shum 2003;Tappen和Freeman 2003)。附录B.5和关于MRF推理的综述论文(Szeliski、Zabih等2008;Blake、Kohli和Rother 2011;Kappes、Andres等2015)详细讨论并比较了这些技术。
尽管对于KITTI等具有大量训练图像和与测试分布高度重叠的数据集,深度学习方法(第12.6节)在很大程度上取代了全局优化技术,但它们在具有挑战性的立体对上仍然表现最佳
包括高分辨率的米德尔伯里对(Scharstein,Hirschm ller等人)等细节。
2014)。Taniai、Matsushita等人(2018)开发的局部扩展移动算法就是这种做法的一个例子。下面,我们描述一些具有历史意义、运行速度更快或专门用于处理特定情况的相关技术。
协同算法。受人类立体视觉计算模型启发的协同算法,是最早提出用于视差计算的方法之一(Dev 1974;Marr和Poggio 1976;Marroquin 1983;Szeliski和Hinton 1985;Zitnick和Kanade 2000)。这些算法通过基于邻近视差和匹配值的非线性操作迭代更新视差估计,其整体行为类似于全局优化算法。事实上,对于某些算法,可以明确地表述一个正在最小化的全局函数(Scharstein和Szeliski 1998)。

图12.12使用局部平面扫描进行立体匹配(Sinha、Scharstein和Szeliski
2014)©2014 IEEE:(a)输入图像;(b)初始稀疏匹配;(c)按倾斜平面分组的匹配;(d)平面和分组特征的3D可视化。
也是迭代算法,这些算法会查看图像中的较大邻域,例如Patch- Match Stereo (Bleyer、Remann和Rother 2011),该方法在每个像素处估计一个局部三维平面,并使用非局部Patch- Match算法(Barnes、Shechtman等2009)快速找到平面上的大致最近邻。这种方法最近被应用于多视图立体设置中,生成了一个极其高效且高质量的算法(Wang、Galliani等2021)。
粗到精和增量变形。当今大多数最佳算法首先枚举所有可能的匹配点及其所有可能的视差,然后以某种方式选择最佳匹配集。有时可以使用受经典(无穷小)光流计算启发的方法获得更快的处理速度。在此过程中,图像依次进行变形,视差估计逐步更新,直到达到满意的配准效果。这些技术通常在一个粗到精的层次细化框架内实现(Quam 1984;Bergen,Anandan等1992;Barron,Fleet和Beauchemin 1994;Szeliski和Coughlan 1997)。最近,粗到精或金字塔方法在现代深度网络中重新兴起,既应用于光流(Ranjan和Black 2017;Sun,Yang等2018),也应用于立体视觉(Chang和Chen 2018)。
局部平面扫描。除了垂直于观察方向的平面扫描外,还可以使用一组倾斜平面来建模场景,这在场景包含高度倾斜的平面表面如地板或墙壁时尤为有利,如图12.12所示(Sinha,Scharstein和Szeliski 2014)。一旦估计出这些平面并分配给每个平面的像素,就可以估算每个像素的平面外位移,以更好地建模曲面。倾斜平面在PatchMatch立体算法中也曾被使用过(Bleyer,Rhemann和Rother 2011),并且最近也在用于智能手机AR的平面双边求解器中得到了应用(Valentin,Kowdle等2018)。
图12.13使用动态规划进行立体匹配,如(a) Scharstein和Szeliski(2002)©2002斯普林格出版社和(b) Kolmogorov、Criminisi等人(2006)©2006 IEEE所展示。对于每对对应的扫描线,选择一条通过所有成对匹配成本矩阵(DSI)的最小路径。小写字母(a–k)表示沿每条扫描线的强度。大写字母代表通过矩阵的选择路径。匹配点用M表示,而部分遮挡点(具有固定成本)则用L或R表示,分别对应仅在左图像或右图像中可见的点。通常,只考虑有限的视差范围(图中为0–4,用未加阴影的方块表示)。(a)中的表示允许对角线移动,而(b)中的表示不允许。请注意,这些图使用了深度的独眼巨人表示法,即相对于两台输入相机之间的相机的深度,显示了DSI的“未偏斜”的x轴切片。
一类不同的全局优化算法基于动态规划。虽然对于常见的平滑函数类,方程(12.7)的二维优化可以证明是NP难的(Veksler1999),但动态规划可以在多项式时间内找到独立扫描线的全局最小值。动态规划最初用于稀疏、基于边缘的方法中的立体视觉(Baker和Binford1981;Ohta和Kanade 1985)。最近的方法则集中在密集(基于强度)的扫描线匹配问题上(Belhumeur1996;Geiger、Ladendorf和Yuille1992;Cox、Hingorani等人1996;Bobick和Intille1999;Birchfield和Tomasi1999)。这些方法通过计算两个对应扫描线之间所有成对匹配成本矩阵中的最小代价路径来工作,即通过DSI的一个水平切片。部分遮挡通过将一个图像中的像素组分配给另一个图像中的单个像素来显式处理。
图12.13示意性地显示了DP的工作原理,而图12.5f显示了应用DP的实DSI切片。
为了对扫描线y实施动态规划,二维成本矩阵D(m,n)中的每个条目(状态)通过结合其DSI匹配成本值与其前驱成本值之一,并同时包括遮挡像素的固定惩罚来计算。图12.13b所示的聚合规则由Kolmogorov、Criminisi等人(2006)给出,他们还使用了两态前景-背景模型进行双层分割。
动态规划立体问题包括选择正确的遮挡像素成本以及难以实现扫描线间的连贯性,尽管有几种方法提出了解决后者的方法(Ohta和Kanade 1985;Belhumeur 1996;Cox、Hingorani等1996;Bobick和Intille 1999;Birchfield和Tomasi 1999;Kolmogorov、Criminisi等2006)。另一个问题是动态规划方法需要强制单调性或排序约束(Yuille和Poggio 1984)。这一约束要求两个视图之间扫描线上的像素相对顺序保持不变,但在包含狭窄前景物体的场景中可能不成立。
一种替代传统动态规划的方法,由Scharstein和Szeliski(2002)提出,是忽略公式(12.9)中的垂直平滑约束,直接在全局能量函数(12.7)中优化独立的扫描线。这种扫描线优化算法的优点在于它计算出相同的表示,并且最小化了与完整二维能量函数(12.7)相同的能量函数的简化版本。不幸的是,它仍然存在与动态规划相同的条纹伪影问题。动态规划也可以应用于树结构,这可以改善条纹现象(Veksler2005)。
通过从多个方向,例如,从八个基本方向N、E、W、S、NE、SE、SW,来求和累积成本函数,可以获得更高质量的结果,
NW(Hirschm ller2008)。由此产生的半全局匹配(SGM)算法执行
表现良好且极其高效,能够实现实时低功耗应用(Gehrig,Eberli,和Meyer 2009)。Drori、Haubold等人(2014)指出,SGM在特定的信念传播变体中等同于提前停止。半全局匹配也通过学习组件得到了扩展,例如SGM-Net (Seki和Pollefeys 2017),该方法使用卷积神经网络调整转换成本;以及SGM-Forest (Sch nberger,Sinha,和Pollefeys 2018),该方法利用随机森林分类器融合来自不同方向的视差提议。
虽然大多数立体匹配算法以每个像素为基础进行计算,但一些技术首先将图像分割成区域,然后尝试给每个区域贴上视差。

图12.14基于分割的立体匹配(Zitnick,Kang等人,2004)©2004
ACM: (a)输入彩色图像;(b)基于颜色的分割;(c)初始视差估计;(d)最终分段平滑视差;(e)在视差空间分布中定义的MRF邻域(Zitnick和Kang 2007)©2007斯普林格。

图12.15自适应过度分割和遮罩的立体匹配(田口、威尔伯恩和齐特尼克2008)©2008 IEEE:在优化过程中细化了段边界,从而获得更准确的结果(例如,底部行中的细绿色叶);(b)在段边界处提取了alpha遮罩,这使得合成效果更加美观(中间列)。
例如,陶、索尼和库马尔(2001)对参考图像进行分割,使用局部技术估计每个像素的视差,然后在每个分割内进行局部平面拟合,之后在相邻分割之间应用平滑约束。齐特尼克、康等人(2004)和齐特尼克与康(2007)采用过度分割来缓解初始不良分割。在将每个分割的一组初始成本值存储到视差空间分布(DSD)后,通过迭代松弛(或在齐特尼克和康(2007)的最新工作中称为循环信念传播)调整每个分割的视差估计值,如图12.14所示。田口、威尔伯恩和齐特尼克(2008)在优化过程中细化分割形状,从而显著改善了结果,如图12.15所示。
克劳斯、索曼和卡纳(2006)通过首先使用均值漂移对参考图像进行分割,然后运行一个小的(3×3) SAD加梯度SAD(通过交叉验证加权),以获得初始视差估计,拟合局部平面,再用全局平面重新拟合,最后在平面分配上运行最终的MRF并采用循环信念传播。

图12.16使用边缘、平面和超像素的多帧匹配(Xue,Owens等人,2019)©2019 Elsevier。
当该算法在2006年首次引入时,它是现有米德尔伯里基准上的排名最高的算法。
王和郑(2008)的算法采用了类似的分割图像的方法,进行局部平面拟合,然后对邻近平面拟合参数进行协同优化。杨、王等人(2009)的算法则利用尹和奎恩(2006)的颜色相关方法和层次信念传播来获得初始的一组视差估计。加尔普、弗拉姆和波莱菲斯(2010)将图像分割为平面区域和非平面区域,并使用不同的表示方法处理这两类表面。
最近,Xue、Owens等人(2019)首先匹配多帧立体序列中的边缘,然后拟合重叠的方形补丁以获得局部平面假设。然后使用超像素和最终的边缘感知松弛来细化这些假设,以获得连续的深度图。
基于分割的立体算法还具备一种重要的能力,即在深度不连续处提取分数像素透明度(Bleyer,Gelautz等2009)。这一能力对于尝试创建虚拟视图插值时至关重要,可以避免边界粘连或撕裂伪影(Zitnick,Kang等2004),同时也能无缝插入虚拟对象(Taguchi,Wilburn,和Zitnick 2008),如图Figure12.15b所示。
实时立体匹配的另一个应用是z键,这是利用深度信息将前景演员从背景中分割出来的过程,通常是为了用一些计算机生成的图像替换背景,如图所示

图12.17使用z键替换背景,采用abi层分割算法(Kolmogorov,Criminisi等人,2006)©2006 IEEE。
图12.2g。
最初,Z键系统需要昂贵的定制硬件来实时生成所需的深度图,因此仅限于广播工作室应用(Kanade,Yoshida等1996;Iddan和Yahav 2001)。离线系统也被开发用于从视频流中估计三维多视角几何(第14.5.4节)(Kanade,Rander和Narayanan 1997;Carranza,Theobalt等2003;Zitnick,Kang等2004;Vedula,Baker和Kanade 2005)。高度准确的实时立体匹配随后使得在普通个人电脑上执行Z键成为可能,从而支持如图12.17所示的桌面视频会议应用(Kolmogorov,Criminisi等2006),但这些应用大多已被用于背景替换的深度网络所取代(Sengupta,Jayaram等2020)以及用于增强现实的实时3D手机重建算法(图11.28和Valentin,Kowdle等2018)。
与其他计算机视觉领域一样,深度神经网络和端到端学习对立体匹配产生了巨大影响。在本节中,我们将简要回顾深度神经网络在立体对应算法中的应用。我们遵循Poggi、Tosi等人(2021)和Laga、Jospin等人(2020)最近两篇综述的结构,将技术分为三类,即,
1.立体管道中的学习,
2.使用2D架构进行端到端学习,以及
我们简要讨论了每组中的几篇论文,并建议读者阅读完整的调查以了解更多信息
详情(Janai,G等人,2020;Poggi,Tosi等人,2021;Laga,Jospin等人,2020)。
立体管道中的学习
甚至在深度学习出现之前,一些作者就提出了学习传统立体管道组件的方法,例如,学习MRF和CRF立体模型的超参数
(Zhang和Seitz2007;Pal,Weinman等人2012)。bontar和LeCun(2016)是
首先通过训练特征优化成对匹配成本,将深度学习引入立体视觉。这些学到的匹配成本至今仍广泛应用于中伯里立体评估中的顶尖方法。此后,许多其他作者提出了用于匹配成本计算和聚合的卷积神经网络(Luo,Schwing和Urtasun 2016;Park和Lee 2017;Zhang,Prisacariu等2019)。
学习也被用于改进传统的优化技术,特别是
广泛使用的Hirschm ller(2008)的SGM算法。这包括SGM-Net (Seki和
Pollefeys2017)使用卷积神经网络调整过渡成本,SGM-Forest(Sch nberger,Sinha,和Pollefeys2018)则使用随机森林分类器从多个入射方向选择视差值。卷积神经网络还被用于细化阶段,取代了早期的技术如双边滤波(Gidaris和Komodakis2017;Batsos和Mordohai2018;Kn belreiter和Pock2019)。
使用2D架构的端到端学习
大型合成数据集及其真实差异的可用性,特别是弗赖堡场景流数据集(Mayer,Ilg等,2016,2018),使得立体网络能够进行端到端训练,并催生了大量新方法。这些方法在提供足够训练数据的基准测试中表现良好,使网络可以针对特定领域进行调整,特别是在KITTI(Geiger,Lenz和Urtasun,2012;Geiger,Lenz等,2013;Menze和Geiger,2015)中,基于深度学习的方法自2016年起开始主导排行榜。
最早的用于立体视觉的深度学习架构与设计用于密集回归任务如语义分割的架构相似(陈、朱等人,2018)。这些二维架构通常采用受U-Net启发的编码器-解码器设计(罗内伯格、菲舍尔和布罗克斯,2015)。首个此类模型是DispNet-C,由梅耶、伊尔格等人在开创性论文中提出(2016),利用相关层(多索维茨基、菲舍尔等人,2015)计算图像层之间的相似度。

图12.18由三种不同DNN立体匹配器计算的差异图,这些匹配器在合成数据上训练,并应用于真实图像对(Zhang,Qi等人,2020)©2020 Springer。
后续对2D架构的改进包括残差网络的概念,该网络对原始视差进行残差校正(Pang,Sun等2017),也可以采用迭代方式实现(Liang,Feng等2018)。可以使用粗到精的处理方法(Tonioni,Tosi等2019;Yin,Darrell,和Yu 2019),网络可以估计遮挡和深度边界(Ilg,Saikia等2018;Song,Zhao等2020)或使用神经架构搜索(NAS)来提高性能(Saikia,Marrakchi等2019)。HITNet结合了这些想法中的多个,并通过局部倾斜平面假设和迭代优化,产生了高效且最先进的结果(Tankovich,Hane等2021)。
由Kn belreiter、Reinbacher等人(2017)开发的2D架构使用联合
卷积神经网络和条件随机场(CRF)模型来推断密集视差图。另一种有前景的方法是多任务学习,例如,同时估计视差和语义分割(Yang、Zhao等人2018;Jiang、Sun等人2019)。通过将输出表示为双峰混合分布,还可以提高输出深度图的表观分辨率并减少过度平滑(Tosi、Liao等人2021)。
使用3D架构进行端到端学习
一种替代方法是使用三维架构,该架构通过处理三维体积中的特征来显式编码几何信息,其中第三个维度对应于视差搜索范围。换句话说,这种架构显式表示了视差空间图像(DSI),同时仍然保留多个特征通道,而不仅仅是标量成本值。与二维架构相比,它们需要更高的内存需求和运行时间。
此类架构的首批实例包括GC-Net(Kendall,Martirosyan等人,2017)和PSMNet (Chang和Chen,2018)。3D架构还允许整合传统的局部聚合方法(Zhang,Prisacariu等人,2019)和避免方法。
几何不一致(Chabra,Straub等,2019)。尽管资源限制通常意味着基于3D DNN的立体方法在较低分辨率下运行,但层次立体匹配(HSM)网络(Yang,Manela等,2019)采用金字塔方法,在较高分辨率下选择性地限制搜索空间,并支持随时按需推理,即在较高帧率下提前停止处理。Duggal,Wang等(2019)通过在循环神经网络中开发可微版本的PatchMatch(Bleyer,Rheumann和Rother,2011),解决了资源有限的问题。Cheng,Zhong等(2020)利用神经架构搜索(NAS)创建了最先进的3D架构。
虽然监督深度学习方法已经主导了包括KITTI等专用训练集在内的各个基准测试,但它们在不同领域中的泛化能力仍然不足(Zendel等人,2020)。在米德尔伯里基准测试中,该测试以高分辨率图像为主,并且仅提供非常有限的训练数据,深度学习方法仍然明显缺失。Poggi、Tosi等人(2021)指出了以下两个主要挑战:(1)跨不同领域的泛化,以及(2)在高分辨率图像上的应用。对于跨领域泛化,Poggi、Tosi等人(2021)描述了离线和在线自监督适应及引导深度学习的技术,而Laga、Jospin等人(2020)则讨论了微调和数据转换。一个最近的领域泛化示例是张、Qi等人(2020)提出的域不变立体匹配网络(DSMNet),其表现优于其他最先进的模型,如HD3 (Yin、Darrell和Yu 2019)和PSMNet (Chang和Chen 2018),如图12.18所示。另一个领域适应的例子是AdaStereo(Song、Yang等人,2021)。对于高分辨率图像,已经开发出技术以粗到精的方式提高分辨率(Khamis、Fanello等人,2018;Chabra、Straub等人,2019)。
虽然匹配图像对是获取深度信息的有效方法,但使用更多图像可以显著提高效果。在本节中,我们不仅回顾了创建完整3D物体模型的技术,还介绍了利用多源图像改善深度图质量的简单技术。关于截至2015年开发的技术的良好综述可以在Furukawa和Hern ndez(2015)中找到,而更近期的综述则可以在
Janai、G等(2020,第10章)。
正如我们在讨论平面扫描(第12.1.2节)时所见,可以在每个视差假设d下,将所有相邻的k张图像重新采样到一个广义视差空间体I(x,y,d,k)中。利用这些额外图像最简单的方法是求和。
图12.19极线平面图像(EPI)(Gortler,Grzeschuk等,1996)©1996 ACM和示意图EPI (Kang,Szeliski,和Chai,2001)©2001 IEEE。(a)光场图(Lumigraph)(第14.3节)是所有穿过空间体积的光线组成的四维空间。取二维切片结果是所有光线嵌入一个平面上,相当于从堆叠的EPI体积中获取的一条扫描线。不同深度的物体以与它们的倒数深度成比例的速度(斜率)横向移动。这种表示方式下可以轻松看到遮挡(和半透明)效果。(b)对应于图12.20的EPI显示了三个图像(中间、左和右)作为EPI体积的切片。黑色像素周围的时空偏移窗口用矩形标出,表明右侧图像未用于匹配。
将它们与参考图像Ir的差异如(12.4)所示,
(12.11)
这是著名的平方差总和(SSSD)和SSAD方法的基础(Okutomi和Kanade 1993;Kang、Webb等人1995),这些方法可以扩展到推断可能的遮挡模式(Nakamura、Matsuura等人1996)。Gallup、Frahm等人(2008)的最新研究展示了如何根据预期深度调整基线,以在几何精度(宽基线)和遮挡鲁棒性(窄基线)之间获得最佳平衡。替代的多视图成本度量包括合成焦点锐度和像素颜色分布的熵等指标(Vaish、Szeliski等人2006)。
一种有用的可视化多帧立体估计问题的方法是检查由所有图像中对应扫描线堆叠形成的极线平面图像(EPI),如图9.11c和12.19所示(Bolles,Baker,和Marimont 1987;Baker和Bolles 1989;Baker 1989)。从图12.19可以看出,当相机水平移动时(在
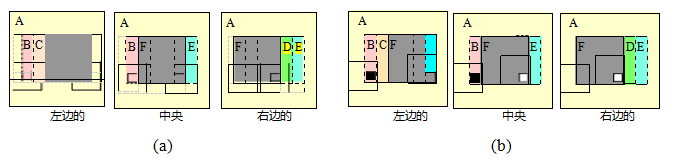
图12.20空间时间可移动窗口(Kang,Szeliski和Chai 2001)©2001 IEEE:一个简单的三帧序列(中间的图像作为参考图像),其中有一个移动的正面灰色方块(标记为F)和一个静止的背景。区域B、C、D和E部分被遮挡。(a)使用常规的SSD算法,在匹配这些区域的像素时(例如,以区域B中的黑色像素为中心的窗口)以及跨越深度不连续性的窗口中(以区域F中的白色像素为中心的窗口),会出错。(b)可移动窗口有助于缓解部分遮挡区域和接近深度不连续性的问题。以区域F中的白色像素为中心的移动窗口在所有帧中都能正确匹配。以区域B中的黑色像素为中心的移动窗口在左图中能正确匹配,但在右图中需要时间选择来禁用匹配。图12.19b显示了与该序列相对应的EPI,并详细描述了时间选择的工作原理。
标准水平校正几何),不同深度的物体以与其深度成反比的速度横向移动(12.1)。前景物体遮挡背景物体,这些背景物体可以被视为EPI条带(Criminisi,Kang等,2005)遮挡其他条带。如果我们有一组足够密集的图像,我们可以找到这样的条带,并推断它们之间的关系,从而重建三维场景并推断半透明物体(Tsin,Kang,和Szeliski,2006)和镜面反射(Swaminathan,Kang等,2002;Criminisi,Kang等,2005)。或者,我们可以将这组图像视为一系列连续的观测,并使用卡尔曼滤波(Matthies,Kanade,和Szeliski,1989)或最大似然推断(Cox,1994)进行合并。
当可用图像较少时,有必要采用聚合技术,如滑动窗口或全局优化。然而,随着输入图像的增加,遮挡的可能性也随之增加。因此,不仅应使用可移动窗口方法调整最佳窗口位置,如图12.20a所示,还应选择邻近帧的一个子集来排除那些感兴趣区域被遮挡的图像,如图12.20b所示(Kang,Szeliski,和Chai 2001)。图-
7 EPI的四维推广是光场,我们在第14.3节中研究了它。

图12.21局部(基于5×5窗口)匹配结果(Kang、Szeliski和Chai
2001)©2001 IEEE:不受空间扰动的窗口(居中);(b)受空间扰动的窗口;(c)使用十个相邻帧中的最佳五个;(d)使用较好的一半序列。请注意,使用时间选择后,靠近树干的结果得到了改善。
图12.19b显示了这种时空选择或窗口移动如何对应于在极线平面图像体积中选择最可能的未被遮挡的体积区域。
图12.21展示了将这些技术应用于多帧花园区图像序列的结果,比较了使用常规(未移位)SSSD与空间移位窗口以及全时空窗口选择的结果。(将立体视觉应用于用移动摄像机拍摄的刚性场景有时称为运动立体)。Kang和Szeliski(2004)报告了使用时空选择带来的类似改进,即使在局部测量与全局优化结合时也显而易见。
虽然从多个输入计算深度图优于成对立体匹配,但通过同时估计多个深度图可以获得更显著的改进(Szeliski1999a;Kang和Szeliski2004)。多张深度图的存在使得关于遮挡的推理更加准确,因为在一张图像中被遮挡的区域可能在其他图像中可见(且可匹配)。多视图重建问题可以表述为在关键帧处同时估计深度图(图9.11c),不仅最大化照片一致性和平滑的分段视差,还要保证不同帧之间视差估计的一致性。尽管Szeliski(1999a)和Kang与Szeliski(2004)使用软(基于惩罚)约束来鼓励多个视差图的一致性,Kolmogorov和Zabih(2002)展示了如何将这种一致性度量编码为硬约束,以确保多个深度图不仅相似,而且在重叠区域实际上是相同的。同时估计多个视差图的其他算法包括Maitre、Shinagawa和Do(2008)以及Zhang、Jia等人(2008)的算法,以及广泛使用的COLMAP算法(Sch nberger、Zheng等人2016),该算法通过视图选择和多张深度图之间的几何一致性来过滤匹配,如图12.26b所示。
最新的多视图立体算法使用深度神经网络来计算匹配

图12.22使用三种不同的多视图立体算法计算的深度图,如彩色点云所示(Yao,Luo等人,2018)©2018 Springer。红色框表示MVSNet表现更好的问题区域。
(成本)体积并将其融合成差异图。DeepMVS系统计算参考图像与邻近图像之间的两两匹配成本,然后通过最大池化将它们融合在一起,随后进行密集CRF优化(Huang,Matzen等,2018)。MVSNet计算所有编码图像在每个扫描平面上的差异,使用3D U-Net正则化这些成本,再通过软argmin和深度优化网络,在DTU和坦克与寺庙数据集上产生良好结果(Yao,Luo等,2018),如图12.22所示。
最近的此类网络变体包括P-MVSNet (Luo,Guan等,2019),该方法使用逐块匹配置信度聚合器;以及CasMVSNet(Gu,Fan等,2020)和CVP-MVSNet(Yang,Mao等,2020),两者均采用粗到精的金字塔处理。四篇更为近期的论文在DTU、ETH3D、Tanks and Temples和/或Blended MVS数据集上表现优异,分别是Vis-MVSNet(Zhang,Yao等,2020)、D2HC-RMVSNet(Yan,Wei等,2020)、DeepC-MVS(Kuhn,Sormann等,2020)和PatchmatchNet (Wang,Galliani等,2021)。这些算法结合了可见性和遮挡推理、置信度或不确定性图以及几何一致性检查,并采用了高效的传播方案以取得良好效果。随着越来越多的新多视图立体论文不断发表,ETH3D和Tanks and Temples排行榜(表12.1)是
12.7.1场景流
与多帧立体估计密切相关的一个主题是场景流,其中使用多个摄像头捕捉动态场景。任务是在每一刻同时恢复物体的三维形状,并估计每帧之间每个表面点的完整三维运动。该领域的代表性论文包括Vedula、Baker等人(2005),

图12.23三维场景流:(a)由围绕舞者的多摄像头穹顶计算得出,如图12.2h-j所示(Vedula,Baker等人,2005)©2005 IEEE;(b)由安装在移动车辆上的立体相机计算得出(Wedel,Rabe等人,2008)©2008 Springer。
Zhang和Kambhamettu(2003)、Pons、Keriven和Faugeras(2007)、Huguet和Devernay
(2007)、Wedel、Rabe等人(2008)和Rabe、M ller等人(2010)。图12.23a显示了一个-
图12.2h至j展示了探戈舞者在三维场景流中的年龄,而图12.23b则显示了为了避障从移动车辆中捕捉到的三维场景流。除了支持测量和安全应用外,场景流还可以用于空间和时间视图插值(第14.5.4节),这一点由Vedula、Baker和Kanade(2005)所证明。
KITTI场景流数据集的创建(Geiger,Lenz,和Urtasun 2012)以及自动驾驶兴趣的增加,加速了场景流算法的研究(Janai,G ney等2020,第12章)。一种帮助正则化问题的方法是采用分段平面表示(Vogel,Schindler,和Roth 2015)。另一种方法是将场景分解为刚性独立移动的对象,如车辆(Menze和Geiger 2015),使用语义分割(Behl,Hosseini Jafari等2017),以及其他分割线索(Ilg,Saikia等2018;Ma,Wang等2019;Jiang,Sun等2019)。3D传感器的更广泛可用性使得场景流算法能够扩展,利用这种模态作为额外输入(Sun,Sudderth,和Pfister 2015;
12.7.2体积和三维表面重建
最具挑战性但也最有用的多视图立体重建变体是构建全局一致的三维模型(Seitz,Curless等,2006)。这一主题在计算机视觉领域有着悠久的历史,始于表面网格重建技术,例如Fua和Leclerc(1995)开发的技术(图12.24a)。为了解决这个问题,人们采用了多种方法和表示形式,包括三维体素(Seitz和

图12.24多视图立体算法:(a)基于表面的立体(Fua和Leclerc 1995)©1995斯普林格;(b)体素着色(Seitz和Dyer 1999)©1999斯普林格;(c)深度图合并(Narayanan、Rander和Kanade 1998)©1998 IEEE;(d)水平集演化(Faugeras和Keriven 1998)©1998 IEEE;(e)线条和立体融合(Hern ndez和Schmitt 2004)©2004埃尔斯维尔;(f)多视图图像匹配(Pons、Keriven和Faugeras 2005)©2005 IEEE;(g)体积图割(Vogiatzis、Torr和Cipolla 2005)©2005 IEEE;(h)刻划视觉壳体(Furukawa和Ponce 2009)©2009斯普林格。
Dyer1999;Szeliski和Golland1999;De Bonet和Viola1999;Kutulakos和Seitz2000;Eisert、Steinbach和Girod2000;Slabaugh、Culbertson等人2004;Sinha和Pollefeys 2005;Vogiatzis、Hern和Diaz等人2007;
Hiep、Keriven等人2009),水平集(Faugeras和Keriven1998;Pons、Keriven和Faugeras2007),多边形网格(Fua和Leclerc1995;Narayanan、Rander和Kanade1998;Hern和Schmitt2004;Furukawa
和Ponce 2009),以及多个深度图(Kolmogorov和Zabih2002)。图12.24展示了使用这些技术重建的3D物体模型的一些代表性示例。
为了组织和比较所有这些技术,Seitz、Curless等人(2006)开发了一个六点分类法,可以帮助根据场景表示对算法进行分类,
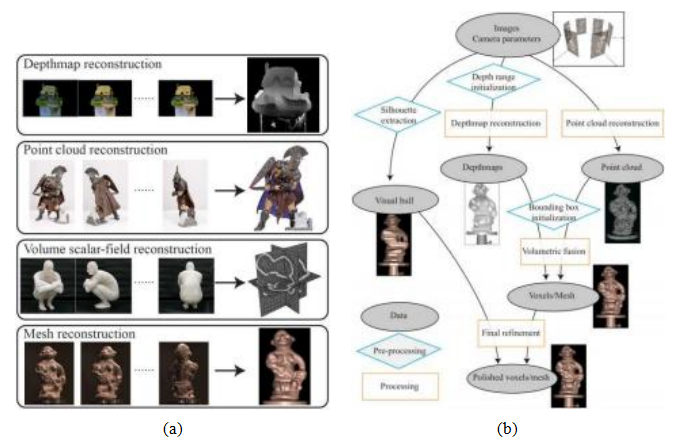
图12.25多视图立体(a)场景表示和(b)处理管道,来自Furukawa和Hern ndez(2015)©2015现在出版商。
光一致性度量、可见性模型、形状先验、重建算法以及它们使用的初始化要求。下面,我们总结了其中的一些选择,并列出了一些代表性论文。如需更多详细信息,请参阅完整的综述文章(Seitz,Curless等2006)以及Furukawa和Ponce(2010)和Janai,G ney等(2020,第10章)的最新综述。ETH3D和Tanks and Temples的排行榜列出了最新的结果和近期论文的链接。
场景表示。根据福川和庞斯(2010)提出的分类法,多视图立体算法主要使用四种场景表示,即深度图、点云、体场和三维网格,如图12.25a所示。这些通常被整合成一个完整的流程,包括相机姿态估计、每张图像的深度图或点云计算、体融合以及表面网格细化(波莱菲斯、尼斯特等人,2008),如Figure12.25b所示。
我们已经在本节前面讨论过多视图深度图估计。一个点云表示的例子是Furukawa和Ponce(2010)开发的基于补丁的多视图立体(PMVS)算法,该算法从稀疏的三维点重建开始

图12.26点云重建:(a)PMVS管道,显示一个样本输入图像、检测到的特征、初始重建的补丁、扩展和过滤后的补丁以及最终的网格模型(Furukawa和Ponce2010)©2010 IEEE;(b)深度地图和
来自COLMAP多视图立体管道两个阶段的表面法线(Sch nberger,
Zheng等人,2016)©2016 Springer;(c)从密集的梯度中恢复出薄结构
轨道摄像机光场(Y cer,Kim等人,2016)©2016 IEEE。
利用运动结构,然后优化并密集化局部定向补丁或表面像素(Szeliski和Tonnesen 1992;第13.4节),同时考虑可见性约束,如图12.26a所示。这种表示可以转换为网格以进行最终优化。此后,改进了视图选择和过滤以及法线估计的技术,例如Fuhrmann和Goesele(2014)以及Sch nberger、Zheng等人(2016)开发的系统,后者(见图11.20b和12.26b)提供了流行的COLMAP开源重建系统的密集多视图立体组件(Sch nberger和Frahm 2016)。当有高采样率的视频序列时,可以从跟踪
边缘重建点云。
如第12.2.1节Kim、Zimmer等人(2013)和Y cer所述,更合适,
Kim等人(2016)和Figure12.26c中所示。
一种较为流行的三维表示方法是均匀的三维体素网格,可以使用多种雕刻技术(Seitz和Dyer 1999;Kutulakos和Seitz 2000)或优化方法(Sinha和Pollefeys 2005;Vogiatzis、Hern和其他2007;Hiep、Keriven和其他2009;Jancosek和Pajdla 2011;Vu、Labatut
和其他2012)进行重建,其中一些方法如图12.24所示。水平集技术(第7.3.2节)同样基于均匀网格,但不是表示二进制占用图,而是表示到表面的有符号距离(Faugeras和Keriven 1998;Pons、Keriven和Faugeras 2007),这可以编码更精细的细节,并且还可以用于合并多个点云或范围数据扫描,这一点在第13.2.1节中进行了详细讨论。除了使用均匀采样的体积,后者最适合紧凑的三维对象外,还可以创建一个与输入图像相对应的视锥体,并以逆深度的形式采样z维,即一组共面相机的均匀视差(图14.7)。这种表示方法在Szeliski和Golland(1999)中被称为醋酸盐堆栈,在Zhou、Tucker等人(2018)中称为多平面图像。
多边形网格是另一种流行的表示方法(Fua和Leclerc 1995;Narayanan、Rander和Kanade 1998;Isidoro和Sclaroff 2003;Hern ndez和Schmitt 2004;Furukawa
和Ponce 2009;Hiep、Keriven等2009)。网格是计算机图形学中常用的表示方式,同时也便于计算可见性和遮挡。最后,正如我们在前一节讨论的那样,也可以使用多个深度图(Szeliski 1999a;Kolmogorov和Zabih 2002;Kang和Szeliski 2004)。许多算法还使用了多种表示方法,例如,它们可能首先计算多个深度图,然后将这些深度图合并成一个三维对象模型(Narayanan、Rander和Kanade 1998;Furukawa和Ponce 2009;Goesele、Curless和Seitz 2006;Goesele、Snavely等2007;Pollefeys、Nist r等2008;Furukawa、Curless等2010;Furukawa和Ponce 2010;Vu、Labatut等2012
;Sch nberger、Zheng等2016),如图Figure12.25b所示。
一个最近的系统将几种表示方法结合成一种可伸缩的分布式方法,可以处理包含数百张高分辨率图像的数据集
LTVRE Kuhn、Hirschm ller等人(2017)的多视图立体系统。该系统启动
用SGM(Hirschm ller2008)计算的成对差异图。这些深度估计-
使用学习到的立体误差模型,通过八叉树处理可变分辨率,然后根据可见性约束过滤冲突点,最后进行三角化,将伙伴与概率多尺度方法融合。图12.27显示了处理管道的示意图。
对于延伸至无穷的室外场景,空间倒置网格可能更可取(Slabaugh、Culbertson等人,2004;Zhang、Riegler等人,2020)。

图12.27 Kuhn、Hirschm ller等人(2017)的3D重建流程©2017
施普林格:(0)动态结构;(1)使用半全局匹配的立体匹配;(2)深度质量估计;(3)概率空间占用;(4+5)概率点优化和异常值过滤;(6)三角测量。图(4+5)和图(6)的图像一半采用纹理映射,另一半采用平面着色,以展示更多的表面细节。
光一致性度量。正如我们在(第12.3.1节)中讨论的那样,可以使用多种相似性度量来比较不同图像中的像素值,包括试图减少光照影响或对异常值不那么敏感的度量。在多视图立体中,算法可以选择直接在模型表面计算这些度量,即在场景空间中,或者将一个图像(或纹理模型)的像素值投影回另一个图像,即在图像空间中。(后者更接近贝叶斯方法,因为输入图像是对彩色3D模型的噪声测量。)当有物体几何信息时,例如其与每个相机的距离及其局部表面法线,可以用来调整计算中使用的匹配窗口,以考虑缩短和尺度变化(Goesele,Snavely等,2007)。
可见性模型。多视图立体算法相较于单深度图方法的一大优势在于其能够以原则性的方式推理可见性和遮挡。利用当前三维模型状态预测每张图像中哪些表面像素可见的技术(Kutulakos和Seitz 2000;Faugeras和Keriven 1998;Vogiatzis、Hern和其他2007;Hiep、Keriven等2009;Furukawa和Ponce 2010;Sch nberger、Zheng等2016)被归类
为使用几何可见性模型,在Seitz的分类体系中。
Curless等人(2006)提出,选择图像邻近子集以匹配的技术被称为准几何方法(Narayanan、Rander和Kanade 1998;Kang和Szeliski 2004;Hernandez和Schmitt
2004),而使用传统鲁棒相似性度量的技术则称为基于异常值的方法。尽管完整的几何推理是最合理且准确的方法,但其评估速度可能非常慢,并且依赖于当前表面估计质量的演变来预测可见性,这可能会成为一个先有鸡还是先有蛋的问题,除非采用保守假设,如Kutulakos和Seitz(2000)所做的一样。
形状先验。由于立体匹配通常约束不足,尤其是在纹理较少的区域,大多数匹配算法采用(无论是显式还是隐式)某种形式的形状预期先验模型。许多依赖优化的技术使用基于3D平滑度或面积的照片一致性约束,由于平滑表面有向内收缩的自然倾向,这通常会导致最小表面先验(Faugeras和Keriven 1998;Sinha和Pollefeys 2005;Vogiatzis、Hern和其他2007)。那些削减空间体积的方法通常在找到照片一致性解后就停止(Seitz和Dyer 1999;Kutulakos和Seitz 2000),这对应于最大表面偏差,即这些技术倾向于高估真实形状。最后,多深度图方法通常采用传统的基于图像的平滑度(正则化)约束。
高级形状先验也可以使用,例如曼哈顿世界假设,该假设认为大多数感兴趣的表面是轴对齐的(Furukawa,Curless等2009a,b),或以倾斜屋顶等相关的方向(Sinha,Steedly和Szeliski 2009;Osman Ulusoy,Black和Geiger 2017)。这些类型的建筑先验在第13.6.1节中详细讨论。还可以使用图像中的二维语义分割,例如墙、地面和植被类别,以在模型的不同区域应用不同种类的正则化和表面法线先验(H ne,Zach等2013)。
重建算法。实际的重建算法如何进行的细节是多视图立体算法中最大差异和最大创新的地方。
一些方法使用定义在三维照片一致性体积上的全局优化来恢复完整的表面。基于图割的方法使用多项式复杂度的二值分割算法来恢复定义在体素网格上的对象模型(Sinha和Pollefeys 2005;Vogiatzis、Hern ndez等2007;Hiep、Keriven等2009;Jancosek和Pajdla 2011;Vu、Labatut等2012)。水平集方法通过连续的
表面演化来找到势能表面配置空间中的良好最小值,因此需要一个相当好的初始化(Faugeras和Keriven 1998;Pons、Keriven,
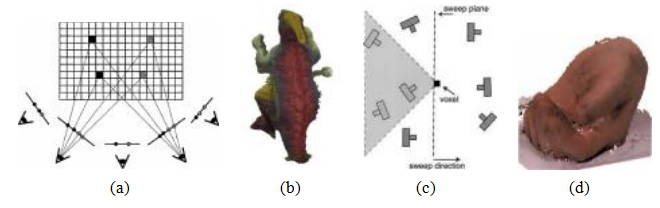
图12.28体素着色(Seitz和Dyer 1999)©1999斯普林格和空间雕刻(Kutulakos和Seitz 2000)©2000斯普林格。(a-b):体素着色以相机从前到后的顺序扫过场景中的平面。(c-d):空间雕刻使用多个扫描方向来处理更一般的相机配置。
以及Faugeras2007)。为了使照片一致性体积有意义,需要以某种稳健的方式计算匹配成本,例如使用有限视图集或通过聚合多个深度图。
一种替代全局优化的方法是在计算照片一致性与可见性的同时遍历三维体积。Seitz和Dyer(1999)的体素着色算法执行从前到后的平面扫描。在每个平面上,任何具有足够照片一致性的体素都被标记为物体的一部分。源图像中相应的像素可以被“擦除”,因为它们已经被考虑在内,因此不会对进一步的照片一致性计算产生影响。(Szeliski和Golland(1999)使用了类似的方法,但没有从前到后的扫描顺序。)在无噪声和无重采样的条件下,生成的三维体积可以保证产生一个照片一致的三维模型,并且包含生成图像的真实三维物体模型(图12.28a–b)。
不幸的是,体素着色只有在所有摄像机位于扫描平面同一侧时才有效,而在一般的环形摄像机配置中这是不可能的。库图拉科斯和塞茨(2000)将体素着色推广到空间雕刻,其中满足体素着色约束的摄像机子集被迭代选择,并且三维体素网格沿着不同的轴交替被雕刻(图12.28c-d)。
另一种流行的多视图立体方法是首先独立计算多个深度图,然后将这些部分图合并成一个完整的3D模型。关于深度图合并的方法,在第13.2.1节中详细讨论,包括由Goesele、Curless和Seitz(2006)使用的带符号距离函数(Curless和Levoy 1996),以及由Goesele、Kazhdan、Bolitho和Hoppe(2006)使用的泊松表面重建法,
初始化要求。Seitz、Curless等人(2006)讨论的最后一个要素是不同算法所需的初始化程度各不相同。由于某些算法需要细化或发展一个粗略的三维模型,因此它们需要一个相对准确(或过完备)的初始模型,这通常可以通过从物体轮廓重建体积来获得,如第12.7.3节所述。然而,如果算法执行全局优化(Kolev、Klodt等人2009;Kolev和Cremers2009),这种对初始化的依赖就不是问题了。
实证评估。数据集和基准的广泛采用,使得过去二十年多视角重建技术取得了快速进展。表12.1列出了其中一些最常用且有影响力的数据库,图12.1、12.22和12.26展示了样本图像和/或结果。更多数据集的指向可以参见Mayer,Ilg。
et al.(2018),Janai,G ney等人(2020),Laga,Jospin等人(2020)和Poggi,Tosi等人。
(2021)。在ETH3D和Tanks and Temples基准测试的排行榜上通常可以找到最新的算法。
在许多情况下,对感兴趣对象进行前景背景分割是初始化或拟合三维模型的好方法(Grauman、Shakhnarovich和Darrell 2003;Vlasic、Baran等人2008),或者对多视图立体施加一组凸约束(Kolev和Cremers 2008)。多年来,已经开发出多种技术,从投影到三维的二进制轮廓的交集重建三维体积模型。所得模型称为视觉壳(有时也称为线壳),类似于点集的凸包,因为该体积相对于视觉轮廓最大,且表面元素与沿轮廓边界的方向线(线)相切(Laurentini 1994)。还可以使用多视图立体(Sinha和Pollefeys 2005)或通过分析投射阴影(Savarese、Andreetto等人2007)来雕刻更精确的重建。
一些技术首先用多边形表示每个轮廓,然后在三维空间中相交生成的多面锥区域,以产生多面体模型(Baumgart1974;Martin和Aggarwal1983;Matusik、Buehler和McMillan2001),这些模型随后可以使用三角样条进行细化(Sullivan和Ponce1998)。其他方法则使用基于体素的表示,通常编码为八叉树(Samet1989),因为这能提高空间-时间效率。图12.29a-b展示了一个三维八叉树的例子。
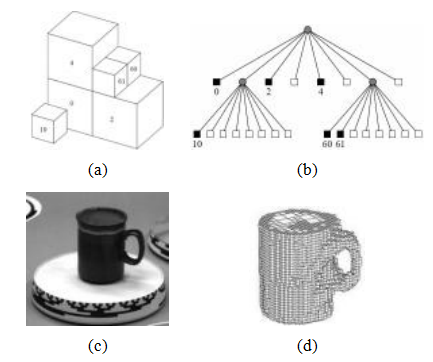
图12.29从二值轮廓中重建的体积八叉树(Szeliski1993)©
1993年爱思唯尔:(a)八叉树表示及其对应的(b)树结构;(c)转盘上物体的输入图像;(d)计算出的三维体积八叉树模型。
模型及其关联的彩色树,其中黑色节点表示模型内部,白色节点表示外部,灰色节点表示混合占用。基于八叉树的重建方法的例子包括Potmesil(1987)、Noborio、Fukada和Arimoto(1988)、Srivasan、Liang和Hackwood(1990)以及Szeliski(1993)。
斯泽利斯基(1993)的方法首先将每个二值轮廓转换为距离图的一种单边变体,其中图中的每个像素表示完全位于(或位于)轮廓内的最大正方形。这使得将八叉树单元投影到轮廓中以确认其是否完全位于物体内部或外部变得快速,从而可以将其着色为黑色、白色或保留为灰色(混合)以便在较小的网格上进一步细化。八叉树构建算法以粗到细的方式进行,首先在相对较低的分辨率下构建一个八叉树,然后通过重新访问和细分所有尚未确定占用情况的输入图像来细化灰色(混合)单元。图12.29d显示了从旋转盘上的咖啡杯计算出的结果八叉树模型。
最近关于视觉船体计算的研究借鉴了基于图像渲染的思想,因此被称为基于图像的视觉船体(Matusik,Buehler等,2000)。与预先计算全局三维模型不同,基于图像的视觉船体是针对每个新视角重新计算的,通过依次将视图光线段与二值轮廓相交来实现。

图12.30来自NYU深度数据集V2 (Wang,Geraghty等人,2020)的单目深度推断(以颜色编码的法线图显示)©2020 IEEE。
每个图像。这不仅导致了快速计算算法,而且能够使用来自输入图像的颜色值快速对恢复的模型进行纹理处理。这种方法还可以与高质量可变形模板结合,以捕捉和重新激活全身运动(Vlasic,Baran等人,2008)。
虽然上述方法以二值前景/背景轮廓图像为起点,但也可以提取出通常达到亚像素精度的轮廓曲线,并通过跟踪这些曲线来重建部分表面网格,如第12.2.1节所述。这样的轮廓曲线还可以与常规图像边缘结合,构建完整的
表面模型(Y cer,Kim等人,2016),如Figure12.26c所示。
从单张图像推断(或幻觉?)深度图的能力开启了各种创意可能性,例如以三维形式展示(图6.41和Kopf、Matzen等人2020年),创造柔焦效果(Section10.3.2),以及可能辅助场景理解。它还可以用于机器人应用,如自主导航(图12.31),尽管大多数(自主和常规)车辆配备了计算机视觉系统后,通常会安装多个摄像头或测距传感器。
我们在第6.4.4节中已经看到,自动照片弹出系统如何利用图像分割和分类来创建照片的“纸板剪影”版本(Hoiem、Efros和Hebert 2005a;Saxena、Sun和Ng 2009)。更近期的系统通过单张图像推断深度时使用了深度神经网络。这些内容在两篇最近的综述文章中有详细描述(Poggi、Tosi等2021,第7节;Zhao、Sun等2020),讨论了超过20种和50多种方法。

图12.31来自KITTI数据集(Godard、Mac Aodha和Brostow2017)的单目深度图估计值©2017 IEEE。
分别使用相关技术,并在Figure12.31中所示的KITTI数据集(Geiger、Lenz和Urtasun2012)上对其进行基准测试。
最早使用神经网络计算深度图的论文之一是Eigen、Pursh和Fergus(2014)开发的系统,该系统随后被扩展以推断表面法线和语义标签(Eigen和Fergus 2015)。这些系统在纽约大学深度数据集V2 (Silberman、Hoiem等2012)和KITTI数据集上进行了训练和测试,如图12.30所示。此后,大多数相关研究都在这两个相对受限的数据集(室内公寓或室外街道场景)上进行训练和测试,尽管有时作者也会使用Make3D (Saxena、Sun和Ng 2009)或Cityscapes (Cordts、Omran等2016),这两个都是室外街道场景,或者ScanNet (Dai、Chang等2017),它包含室内场景。在这样的“封闭世界”数据集上训练和测试的危险在于,网络可能会学习捷径,例如根据地面位置推断深度,或者未能识别出不属于常见类别的物体(van Dijk和de Croon 2019)。
早期系统使用了诸如NYU depth、KITTI和ScanNet等数据集中的深度图像进行训练,事实证明,在这些数据集中加入共面性等软约束可以提高性能(Wang,Shen等人,2016;Yin,Liu等人,2019)。后来,引入了“无监督”技术,利用变形立体图像对之间的光度一致性(Godard,Mac Aodha,和Brostow,2017;Xian,Shen等人,2018)或视频序列中图像对的光度一致性(Zhou,Brown等人,2017)。此外,还可以使用著名地标3D重建(Li和Snavely,2018),包含人们摆出“人体挑战”姿势的图像集(Li,Dekel等人,2019),或者采集更多样化的“野外图像”,并标注相对深度(Chen,Fu等人,2016)。
最近一篇将多个此类数据集联合起来的论文是Ranftl、Lasinger等人(2020)开发的MiDaS系统,他们不仅使用了大量现有的“野外”数据集来训练基于Xian、Shen等人(2018)提出的网络,还利用了来自十几部3D电影的数千对立体图像作为额外的训练、验证和测试数据。在他们的论文中,他们不仅展示了该系统比先前的方法产生了更优的结果。

图12.32COCO数据集(Ranftl,Lasinger等人,2020)中的单目深度地图估计和图像的新视图©2020 IEEE。
(图12.32),但同时也认为他们的零样本跨数据集转移协议,即在与训练集分开的数据集上进行测试,而不是使用随机的训练和测试子集,产生了一个在真实世界图像上工作更好的系统,并避免了意外的数据集偏差(Torralba和Efros2011)。
从单张图像推断深度图的另一种方法是推断完整的封闭3D形状,可以使用体素表示(Choy,Xu等2016;Girdhar,Fouhey等2016;Tulsiani,Gupta等2018)或基于网格的表示(Gkioxari,Malik和Johnson 2019;Han,Laga和Bennamoun 2021)。除了将深度网络应用于单张彩色图像外,还可以通过添加额外的线索和表示来增强这些网络,例如定向线和平面(Wang,Geraghty等2020),这些作为高层次的形状先验(第12.7.2节和第13.6.1节)。神经渲染也可用于创建新颖视角(Tucker和Snavely 2020;Wiles,Gkioxari等2020;图14.22d),并使单目深度预测随时间保持一致(Luo,Huang等2020;Teed和Deng 2020a;Kopf,Rong和Huang 2021)。单目深度推断的一个消费级应用示例是一次性3D摄影(Kopf,Matzen等2020),该系统使用紧凑高效的DNN在手机上实现,首先推断出深度图,然后将其转换为多层,修复背景,创建网格和纹理图集,
12.9额外阅读
立体对应和深度估计领域是计算机视觉中最古老且研究最为广泛的主题之一。多年来,许多优秀的综述文章已经问世(Marr和Poggio 1976;Barnard和Fischler 1982;Dhond和Aggarwal 1989;Scharstein和Szeliski 2002;Brown、Burschka和Hager 2003;Seitz、Curless等2006;Furukawa
以及Hern ndez2015
;Janai,G ney等人2020;Laga,Jospin等人2020;Poggi,Tosi等人。
(2021),它们可以作为这大量文献的良好指南。
由于计算限制和寻找外观不变对应关系的需要,早期算法通常专注于寻找稀疏对应关系(Hannah 1974;Marr和Poggio 1979;Mayhew和Frisby 1980;Ohta和Kanade 1985;Bolles、Baker和Marimont 1987;Matthies、Kanade和Szeliski 1989)。
计算极线几何和预校正图像的主题在第11.3节和第12.1节中有所涉及,同时也在多视图几何的教科书中(Faugeras和Luong 2001;Hartley和Zisserman 2004)以及专门讨论这一主题的文章中(Torr和Murray 1997;Zhang 1998a,b)有所涉及。视差空间和视差空间图像的概念通常与Marr(1982)的开创性工作以及Yang、Yuille和Lu(1993)和Intille和Bobick(1994)的论文联系在一起。平面扫描算法最初由Collins(1996)推广,随后由Szeliski和Golland(1999)将其扩展到完整的任意射影设置,Saito和Kanade(1999)也进行了类似的推广。平面扫描还可以使用圆柱面(Ishiguro、Yamamoto和Tsuji 1992;Kang和Szeliski 1997;Shum和Szeliski 1999;Li、Shum等2004;Zheng、Kang等2007)或更一般的拓扑结构(Seitz 2001)来表述。
一旦成本体积或DSI的拓扑结构已经建立,我们需要计算每个像素和潜在深度的实际照片一致性度量。如第12.3.1节所述,已提出了多种此类度量方法。其中一些在下文中进行了比较。
最近对匹配成本的调查和评估(Scharstein和Szeliski2002;Hirschm ller
和Scharstein2009)。
为了从这些成本计算出实际的深度图,必须使用某种形式的优化或选择标准。最简单的方法是各种类型的滑动窗口,相关内容在第12.4节中讨论,并由Gong、Yang等人(2007)和Tombari、Mattoccia等人(2008)进行了综述。全局优化框架常用于计算最佳视差场,如第12.5节所述。这些技术包括动态规划和真正的全局优化算法,例如图割和循环信念传播。最近,深度神经网络在计算对应关系和视差图方面变得流行,相关内容在第12.6节中讨论,并由Laga、Jospin等人(2020)进行了综述。
Poggi、Tosi等人(2021年)。表12.1中的基准列表是查找该领域最新结果的绝佳途径。
多视图立体算法通常分为两类(Furukawa和Hern ndez 2015)。第一类包括使用多张图像计算
传统深度图的算法,以计算照片一致性度量(Okutomi和Kanade 1993;Kang、Webb等1995;Szeliski和Golland 1999;Vaish、Szeliski等2006;Gallup、Frahm等2008;Huang、Matzen等2018;Yao、Luo等2018)。其中一些技术计算多个深度图,并使用额外的约束条件来鼓励不同的深度图相互匹配。
一致(Szeliski1999a;Kolmogorov和Zabih2002;Kang和Szeliski2004;Maitre、Shinagawa和Do2008;Zhang、Jia等人2008;Yan、Wei等人2020;Zhang、Yao等人2020)。
第二类论文是计算真实的三维体积或基于表面的对象模型。同样,由于关于这个主题发表的论文数量庞大,我们在这里不引用它们,而是将您引向第12.7.2节中的材料,Seitz的调查,
Curless等人(2006)、Furukawa和Hern ndez(2015
)以及Janai、G ney等人(2020)
表12.1中列出的在线评价网站。
单目深度推断这一主题目前非常活跃。除了第12.8节之外,Poggi、Tosi等人(2021,第7节)和Zhao、Sun等人(2020)的最新综述也是很好的起点。
例12.1:立体声对校正。实现以下简单算法(Section12.1.1):
1.旋转两个摄像机,使它们与连接两个摄像机中心c0和c1的直线垂直。最小旋转可以从原始和期望的光轴之间的交叉积计算得出。
2.旋转光轴,使每个摄像机的水平轴朝向另一个摄像机的方向。(同样,第一次旋转后当前x轴与连接摄像机的线之间的叉积给出了旋转。)
3.如果需要,放大较小(细节较少)的图像,使其具有与其他图像相同的分辨率(因此具有行与行对应关系)。
现在将您的结果与Loop和Zhang(1999)提出的算法进行比较。您是否可以想到在哪些情况下他们的方法可能更可取?


















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









