






10.1光度校准 610
10.1.1辐射响应函数 611
10.1.2噪声水平估计 614
10.1.3暗角 615
10.1.4光学模糊(空间响应)估计 616
10.2高动态范围成像 620
10.2.1色调映射 627
10.2.2应用:闪光灯摄影 634
10.3超分辨率、去噪和模糊消除 637
10.3.1彩色图像去马赛克 646
10.3.2镜头模糊(散景) 648
10.4图像抠像和合成 650
10.4.1蓝屏遮罩 651
10.4.2自然图像遮罩 653
10.4.3基于优化的抠像 656
10.4.4烟雾、阴影和闪光垫 661
10.4.5视频遮罩 662
10.5纹理分析与合成 663
10.5.1应用:孔洞填充和图像修复 665
10.5.2应用:非真实感渲染 667
10.5.3神经风格转换和语义图像合成 669
10.6额外阅读 671
10.7练习 674

图10.1计算摄影:(a)合并多张曝光以创建高动态范围图像(Debevec和Malik 1997)©1997 ACM;(b)合并闪光灯和非闪光灯照片;(Petschnigg、Agrawala等2004)©2004 ACM;(c)图像抠图和合成;(Chuang、Curless等2001)©2001 IEEE;(d)用修复技术填充孔洞
(Criminisi,P rez,和Toyama2004)©2004 IEEE。
在过去十年中,计算机视觉的所有进步中,计算摄影无疑具有最广泛的商业影响。2010年,亚当斯、塔尔瓦拉等人(2010)发表了开创性的《弗兰肯相机》论文,同时发布了一款最早广泛使用的相机内全景图像拼接应用。1纵观到2020年,每部智能手机都内置了全景拼接、高动态范围(HDR)曝光合并以及多图像去噪和超分辨率功能(哈辛诺夫、夏莱特等人2016;罗夫斯基、加西亚-多拉多等人2019;利巴、穆尔蒂等人2019),最新的手机还通过多个镜头或双像素模拟浅景深(散景)效果(巴伦、亚当斯等人2015;瓦德瓦、加尔格等人2018;加尔格、瓦德瓦等人2019;张、瓦德瓦等人2020)。
在第8.2节中,我们描述了如何将多张图像拼接成宽广视野的全景图,使我们能够创建普通相机无法捕捉的照片。这只是计算摄影的一个例子,在计算摄影中,图像分析和处理算法被应用于一张或多张照片,以生成超越传统成像系统能力的图像。
在本章中,我们将介绍一些额外的计算摄影算法。首先回顾光度图像校准(第10.1节),即相机和镜头响应的测量,这是后续许多算法的前提条件。接着讨论高动态范围成像(第10.2节),通过多次曝光捕捉场景中的全部亮度范围(图10.1a)。我们还介绍了色调映射操作符,这些操作符将宽色域图像重新映射到常规显示设备如屏幕和打印机上,以及合并闪光灯和普通图像以获得更好曝光的算法(图10.1b)。
接下来,我们将讨论如何通过合并多张照片或使用复杂的图像先验或深度网络来提高图像的分辨率和视觉质量(第10.3节)。这包括从大多数相机中存在的图案化拜耳马赛克中提取全彩色图像的算法。
在第10.4节中,我们讨论了从一张照片中切割图像片段并将其粘贴到其他照片中的算法(图10.1c)。在第10.5节中,我们描述了如何从真实世界的样本生成新颖的纹理,用于填补图像中的孔洞等应用(图10.1d)。最后,我们简要概述了非写实渲染(第10.5.2节),这种技术可以将普通照片转化为类似传统绘画的艺术渲染,并讨论了神经网络在风格迁移和语义图像合成中的应用(第10.5.3节)。
本书没有详细讨论的一个主题是新型计算传感器、光学和摄像机。Nayar(2006)的一篇文章可以找到一个很好的综述,这本书
Raskar和Tumblin(2010)以及Levin、Fergus等人(2007)的研究论文中也讨论了相关问题。第10.2节和第14.3节中也有相关讨论。
一篇面向大众的计算摄影入门文章可以在海耶斯(2008)的文章中找到,此外,奈亚尔(2006)、科恩和塞尔斯基(2006)、莱沃伊(2006)以及德贝韦克(2006).2Raskar和图姆布林(2010)的文章也对此领域进行了广泛覆盖,特别强调了计算相机和传感器。高动态范围成像这一子领域有专门讨论该研究的书籍(莱因哈德、海德里希等人,2010),还有一本更面向专业摄影师的优秀书籍(弗里曼,2008)。王和科恩(2009)提供了一篇关于图像抠图的良好综述。
还有几门计算摄影课程,讲师们提供了大量的在线资料,例如卡内基梅隆大学的扬尼斯·格基乌莱卡斯的课程,伯克利大学的阿廖沙·埃夫罗斯的课程,麻省理工学院的弗尔多·杜兰德的计算摄影课程,斯坦福大学的马克·莱沃伊的课程,以及一系列关于计算摄影的SIGGRAPH课程。
在成功合并多张照片之前,我们需要分析将入射辐照度映射到像素值的功能,以及每张图像中存在的噪声量。在本节中,我们将考察影响这种映射的成像流程中的三个组成部分(图10.2)。关于现代数字相机处理流程的更全面、可调模型,请参见Tseng、Yu等人(2019)的最新论文。
第一种是辐射响应函数(Mitsunaga和Nayar 1999),它将到达透镜的光子映射为存储在图像文件中的数字值(第10.1.1节)。第二种是暗角,它会使图像边缘附近的像素值变暗,尤其是在大光圈下(第10.1.3节)。第三种是点扩散函数,它描述了由透镜、抗锯齿滤波器和有限传感器面积引起的模糊(第10.1.4节)。本节的内容基于第2.2.3节中描述的成像过程。
以及2.3.3,所以如果您已经有一段时间没有查看这些部分,请返回并重新查看它们。
如图10.2所示,许多因素影响到达透镜的光强度如何映射到存储的数字值中。我们暂时忽略透镜内部可能发生的非均匀衰减,这将在第10.1.3节中讨论。
影响这一映射的第一个因素是光圈和快门速度(第2.3节),可以将其建模为入射光的全局乘数,最方便的是以曝光值(对数亮度比)来衡量。接下来,感光芯片上的模数(A/D)转换器应用电子增益,通常由相机上的ISO设置控制。理论上这种增益是线性的,但任何电子设备都可能存在非线性(无论是无意还是有意)。暂且忽略光子噪声、片上噪声、放大器噪声和量化噪声,我们稍后会讨论这些内容,通常可以假设入射光与RAW相机文件中存储的值之间的映射大致呈线性关系(如果您的相机支持这一点)。
如果图像以常见的JPEG格式存储,相机的图像信号处理器(ISP)接下来会执行拜耳模式去马赛克处理(第2.3.2节和第10.3.1节),这是一个主要线性的(但通常非平稳的)过程。在此阶段,通常还会应用一些锐化处理。接下来,颜色值会被乘以不同的常数(有时是一个3×3的颜色扭曲矩阵),以进行色彩平衡,即使白点更接近纯白色。最后,每个颜色通道的强度都会应用标准伽玛校正,并将颜色转换为YCbCr格式,然后通过DCT变换、量化,最后压缩成JPEG格式(第2.3.3节)。图10.2以图形形式展示了所有这些步骤。
鉴于所有这些处理的复杂性,很难从原理上建模相机响应函数(图10.3a),即入射辐照度与数字RGB值之间的映射关系。更实际的方法是通过测量入射光与最终值之间的对应关系来校准相机。
最精确但最昂贵的方法是使用积分球,这是一种大型(通常直径为1米)的球体,内部仔细涂上白色哑光漆。顶部有一个精确校准的光源,控制着球体内辐射量(由于球体的辐射特性,其辐射强度在任何地方都是恒定的),侧面有一个小开口,可以安装相机/镜头组合。通过缓慢调节进入光源的电流,可以建立入射辐射与测量像素值之间的准确对应关系。此外,还可以研究相机的暗角和噪声特性。
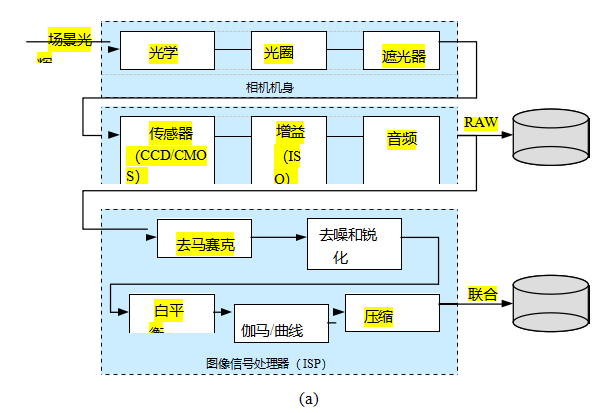
图10.2图像传感流程:(a)方框图展示了各种噪声源以及典型的数字后处理步骤;(b)等效信号变换,包括卷积、增益和噪声注入。缩写如下:RD =径向畸变,AA=抗混叠滤波器,CFA =彩色滤光阵列,Q1和Q2 =量化噪声。
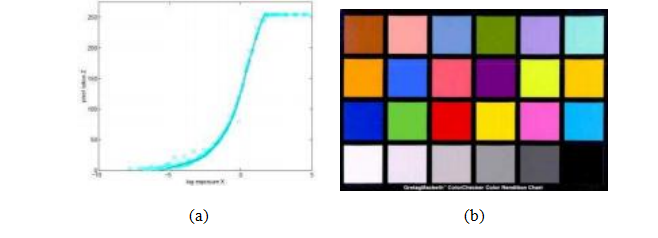
图10.3辐射响应校准:(a)典型相机响应函数,显示入射日志辐照度(曝光)与输出8位像素值之间的映射关系,针对一个颜色通道(Debevec和Malik1997)©1997 ACM;(b)颜色检查表。
simultaneously determined.
同时确定。
更实用的替代方法是使用校准图表(图10.3b),例如Mac- beth或Munsell色卡。这种方法最大的问题是确保照明均匀。一种方法是在远离图表且与图表垂直的大暗室中使用高质量光源。另一种方法是将图表放置在户外,远离任何阴影。(在这两种条件下,结果会有所不同,因为光源的颜色不同。)
最简单的方法可能是使用三脚架拍摄同一场景的多个曝光,并通过同时估计每个像素的入射辐照度和响应曲线来恢复响应函数(Mann和Picard 1995;Debevec和Malik 1997;Mitsunaga和Nayar 1999)。这种方法在第10.2节关于高动态范围成像中进行了更详细的讨论。
如果所有这些都失败了,即你只有一个或多个不相关的照片,你可以使用相机的国际色彩联盟(ICC)配置文件(Fairchild2013).11更简单的是,如果你的文件是RAW文件,你可以假设响应是线性的,并且图像有
如果为JPEG图像,则对每个RGB通道应用√= 2.2非线性(加上裁剪)。
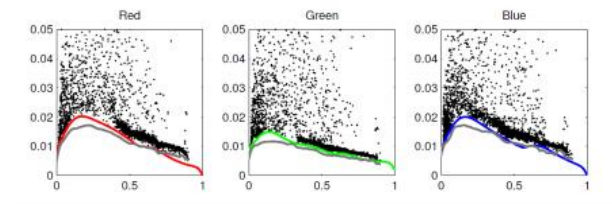
图10.4从单张彩色照片中获得的噪声水平函数估计值(Liu,Szeliski等,2008)©2008 IEEE。彩色曲线是测量到的带噪分段平滑图像之间偏差的概率下包络线,即估计的NLF拟合。通过平均29张图像得到的真实NLF以灰色显示。
10.1.2噪声水平估计
除了了解相机响应函数外,通常还需要知道在特定相机设置下(例如ISO/增益级别)注入的噪声量。最简单的噪声表征是单个标准差,通常以灰度级测量,与像素值无关。更精确的模型可以通过估计噪声水平作为像素值的函数来获得(图10.4),这被称为噪声水平函数(Liu,Szeliski等,2008)。
与相机响应函数一样,估计这些量最简单的方法是在实验室中使用积分球或校准图。噪声可以通过独立地在每个像素处进行多次曝光并计算测量值的时间方差来估算(Healey和Kondepudy 1994),或者通过假设某个区域内(例如,在颜色检查方块内)所有像素值都相同来计算空间方差。
这种方法可以推广到图像中存在强度恒定或缓慢变化区域的情况(Liu,Szeliski等,2008)。首先,将图像分割成这样的区域,并在每个区域内拟合一个常数或线性函数。接下来,在远离大梯度和区域边界的情况下,测量噪声输入像素与平滑拟合函数之间的差异的(空间)标准差。如图10.4所示,将这些差异作为输出级别的函数绘制出来。最后,拟合一个较低的包络线以忽略异常值或偏离。Liu,Szeliski等(2008)提出了一种完全贝叶斯的方法来建模每个量的统计分布。一种更简单的方法,在大多数情况下应该会产生有用的结果,即拟合低维

图10.5单图像暗角校正(郑、余等,2008)©2008 IEEE:(a)原始图像有明显的可见暗角;(b)郑、周等(2006)描述的暗角补偿;(c–d)郑、余等(2008)描述的暗角补偿。
将函数(例如,正值B样条)与下限包络线进行比较(见练习10.2)。
松下和林(2007b)提出了一种技术,基于水平依赖噪声分布的偏斜(不对称性),同时估计相机响应和噪声水平函数。他们的论文还包含了这些领域中先前工作的大量参考文献。
使用广角和大光圈镜头时常见的问题是图像在角落处会变暗(图10.5a)。这个问题通常被称为暗角,有多种形式,包括自然暗角、光学暗角和机械暗角(第2.2.3节)(Ray2002)。与辐射响应函数校准一样,最准确的暗角校准方法是使用积分球或均匀着色且照明良好的空白墙面的照片。
一种替代方法是拼接全景场景,并假设每个像素的真实辐射来自每张输入图像的中心部分。如果辐射响应函数已知(例如,通过RAW模式拍摄)且曝光保持恒定,则这种方法更容易实现。如果响应函数、图像曝光和暗角函数未知,仍可以通过优化大规模最小二乘拟合问题来恢复这些参数(Litvinov和Schechner 2005;Goldman 2010)。图10.6展示了一个同时估计暗角、曝光和辐射响应函数的例子,该例子基于一组重叠的照片(Goldman 2010)。请注意,除非对暗角进行建模并补偿,否则常规梯度域图像融合(第8.4.4节)将无法生成吸引人的图像。
如果只有一个图像可用,可以通过在径向方向上寻找缓慢一致的强度变化来估计暗角。Zheng、Lin和Kang(2006)提出的原始算法首先将图像预分割成平滑变化的区域,然后

图10.6同时估计暗角、曝光和辐射响应
(Goldman2010)©2011 IEEE:(a)原始输入图像的平均值;(b)补偿暗角后的平均值;(c)仅使用梯度域混合(注意剩余的斑点状外观);(d)补偿暗角和混合后的平均值。
在每个区域内进行了分析。郑、余等人(2008)没有预先分割图像,而是计算所有像素的径向梯度,并利用这种分布的不对称性(因为远离中心的梯度平均来说略为负)来估计暗角效应。图10.5展示了将这些算法应用于具有大量暗角效应的图像的结果。练习10.3要求你实现上述的一些技术。
最后一个需要校准的成像系统特性是空间响应函数,它编码了与入射图像卷积以生成点采样图像时产生的光学模糊。卷积核的形状,也称为点扩散函数(PSF)或光学传递函数,取决于多个因素,包括镜头模糊和径向畸变(第2.2.3节),传感器前的抗混叠滤波器,以及每个活动像素区域的形状和范围(第2.3节)(图10.2)。对于多图像超分辨率和去模糊等应用,准确估计该函数是必需的(第10.3节)。
理论上,可以通过在图像中任意位置观察一个无限小的点光源来估计PSF。实际上,通过钻穿一块暗板并用一个非常亮的光源进行背光照射来创建样本阵列是困难的。
一个更实用的方法是观察由长直线组成的图像或

图10.7校准图案,边缘在所有方向上均匀分布,可用于PSF和径向畸变估计(Joshi、Szeliski和Kriegman2008)©2008 IEEE。中间显示了实际感知图像的一部分,右侧是理想图案的放大图。
条形,因为这些可以精确到任意精度。由于水平或垂直边缘的位置在采集过程中可能会产生混叠,因此稍微倾斜的边缘更为理想。这种边缘的轮廓和位置可以估计到亚像素精度,这使得在亚像素分辨率下估计点扩散函数成为可能(Reichenbach,Park和Narayanswamy 1991;Burns和Williams 1999;Williams和Burns 2001;Goesele,Fuchs和Seidel 2003)。Murphy(2005)的论文对相机校准的所有方面进行了很好的综述,包括空间频率响应(SFR)、空间均匀性、色调再现、色彩再现、噪声、动态范围、色彩通道注册和景深。该论文还描述了一种称为sfrmat2的斜边校准算法。
斜边技术可用于恢复二维点扩散函数的一维投影,例如,利用略微垂直的边缘来恢复水平线扩展函数(LSF)(Williams 1999)。随后,LSF通常转换到傅里叶域,并将其幅度绘制为一维调制传递函数(MTF),这表明了在采集过程中丢失(模糊)和混叠的图像频率(第2.3.1节)。对于大多数计算摄影应用而言,直接估计完整的二维点扩散函数更为理想,因为从其投影中恢复可能较为困难(Williams 1999)。
图10.7展示了一种包含所有方向边缘的图案,可以直接用于恢复二维PSF。首先,通过提取感知图像中的边缘、连接这些边缘并找到圆弧的交点来定位图案中的角点。接下来,将已知解析形式的理想图案(使用单应性变换)扭曲以适应输入图像的中心部分,并调整其强度以匹配感知图像中的强度。如果需要,可以将图案渲染为比输入图像更高的分辨率,这使得PSF的估计能够达到亚像素分辨率(图10.8a)。最后

图10.8使用校准目标估计点扩散函数(Joshi,Szeliski和Kriegman 2008)©2008 IEEE。(a)随着分辨率逐渐提高,次像素点扩散函数的变化(注意方形传感区域与圆形镜头模糊之间的相互作用)。(b)还可以估计并消除径向畸变和色差。(c)不聚焦(模糊)镜头的点扩散函数显示了角落处的一些衍射和暗角效应。
K = arg
n ⅡB - D
(10.1)
其中,B是感知(模糊)图像,I是预测(清晰)图像,D是一个可选的下采样算子,用于匹配理想图像和感知图像的分辨率(Joshi,Szeliski和Kriegman 2008)。另一种解决方案是首先估计一维点扩散函数文件,然后使用拉东变换将它们组合起来(Cho,Paris等2011)。
如果在图像的重叠区域局部估计PSF,也可以用来估计由镜头引起的径向畸变和色差(图10.8b)。由于理想目标到感知图像的单应性映射是在图像中心(未畸变)部分估计的,因此任何(每个通道)由光学系统引起的位移都会表现为PSF中心的偏移。补偿这些位移可以消除无色径向畸变和导致不可见色差的各通道位移。色差引起的依赖颜色的模糊(图2.21)也可以使用讨论中的去模糊技术来去除。
12这个过程混淆了几何校准和光度校准之间的区别。原则上,任何几何畸变都可以通过空间变化的位移PSF来建模。实际上,将任何大的位移折叠到几何校正部分更容易。
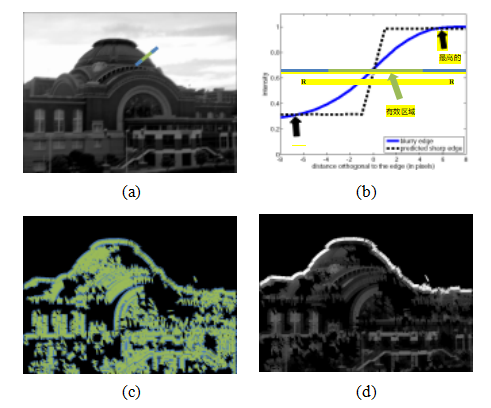
图10.9不使用校准图案估计PSF(Joshi、Szeliski和
Kriegman2008)©2008 IEEE:(a)输入图像,蓝色横截面(轮廓)位置,(b)检测和预测的台阶边缘轮廓,(c-d)边缘位置附近的预测颜色的位置和值。
第10.3节。图10.8b显示了径向畸变和色差如何表现为拉长和位移的PSF,以及在校准目标区域中消除这些效应的结果。
局部二维PSF估计技术也可用于估算暗角。图10.8c展示了机械暗角如何表现为图像角落处的PSF剪切。为了正确捕捉与暗角相关的整体变暗,需要从中心推断理想图案的修改强度,这最好通过均匀照明的目标来完成。
在处理RAW拜耳阵列图像时,正确估计点扩散函数的方法是仅在检测像素值处评估公式(10.1)中的最小二乘项,同时将理想图像插值到所有值。对于JPEG图像,应首先线性化强度,例如,移除伽马和其他任何非线性因素,以获得估计的辐射响应函数。
如果你有一个用未经校准的相机拍摄的图像,你仍然可以恢复PSF并用它来校正图像吗?事实上,通过稍作修改,之前的

图10.10展示了室内图像的样本,其中窗外区域曝光过度,而室内区域则太暗。
算法仍然有效。
不是假设已知的校准图像,你可以检测出强烈的拉长边缘,并在这些区域拟合理想的阶梯边缘(图10.9b),从而得到如图10.9d所示的清晰图像。对于每个被完整有效估计邻居包围的像素(图10.9c中的绿色像素),应用最小二乘公式(10.1)来估计核K。由此产生的局部估计PSF可用于校正色差(因为可以计算各通道PSF之间的相对位移),正如Joshi、Szeliski和Kriegman(2008)所展示的那样。
练习10.4提供了更多关于实现和测试基于边缘的PSF估计算法的详细说明。Fergus、Singh等人(2006)提出了一种替代方法,该方法不需要明确检测边缘,而是使用图像统计(梯度分布)。
正如我们在本章前面提到的,不同曝光度拍摄的注册图像可以用来校准相机的辐射响应函数。更重要的是,它们可以帮助你在具有挑战性的条件下创建曝光良好的照片,例如在明亮场景中,任何单一曝光都包含饱和(过曝)和暗部(欠曝)区域(图10.10)。这个问题相当普遍,因为自然界中的辐射值范围远大于任何摄影传感器或胶片所能捕捉到的范围(图10.11)。通过一组包围曝光(相机在自动包围曝光(AEB)模式下故意欠曝和过曝拍摄的曝光)来获得材料,从而创建正确曝光的照片,如图10.12所示(Freeman2008;Gulbins和Gulbins2009;Hasinoff,Durand,和Freeman

图10.11不同场景的相对亮度,从暗室里由显示器照亮的1到看太阳的200万。照片由Paul Debevec提供。

图10.12使用相机自动曝光包围(AEB)模式拍摄的一组带有括号的图像和由此产生的高动态范围(HDR)合成图像。
2010;Reinhard,Heidrich等人,2010)。
虽然可以直接将不同曝光的像素组合成最终合成图像(Burt和Kolczynski 1993;Mertens、Kautz和Reeth 2007),但这种方法有可能产生对比度反转和光晕。相反,更常见的方法是分三个阶段进行:
1.从对齐的图像中估计辐射响应函数。
2.通过选择或混合来自不同曝光的像素来估算辐射度图。
3.将生成的高动态范围(HDR)图像转换回可显示的色域。
估计辐射响应函数的想法相对简单(Mann和Picard 1995;Debevec和Malik 1997;Mitsunaga和Nayar 1999;Reinhard、Heidrich等2010)。假设你拍摄了三组不同曝光度(快门速度)的图像,比如±2个曝光值。如果我们能够确定每个像素点的辐射度(曝光)Ei(2.102),就可以将其与每个曝光时间tj测量的像素值zij进行对比,如图10.13所示。
改变快门速度比改变光圈更可取,因为后者会影响暗角和对焦。使用±2个“光圈值”(技术上称为曝光值或EV,因为光圈值指的是光圈)通常是捕捉良好动态范围与确保所有像素曝光正确之间的最佳折衷。
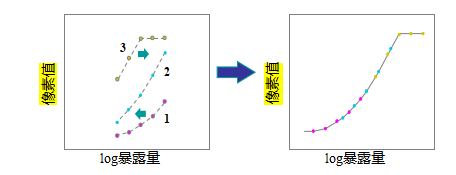
图10.13使用多次曝光进行辐射校准(Debevec和Malik1997)。将相应的像素值作为对数曝光(辐照度)的函数绘制出来。左图中的曲线被移动,以考虑每个像素的未知辐射度,直到它们全部排列成一条平滑曲线。
不幸的是,我们不知道它们的辐射值Ei,因此必须在估计辐射响应函数f的同时估计这些值,该函数可以写为(Debevec和Malik 1997)
zij = f (Ei tj ), (10.2)
其中,tj是第j张图像的曝光时间。逆响应曲线f-1由f-1(zij)= Ei tj给出。 (10.3)
两边取对数(以2为底是方便的,因为现在我们可以用ev来测量量),我们得到
g(zij)= log f-1(zij)= logEi + log tj, (10.4)
其中g = log f-1(将像素值zij映射到logirradiance)是我们在估计的曲线(图10.13侧视)。
贝德韦克和马利克(1997)假设曝光时间tj是已知的。(请注意,这些时间可以从相机的EXIF标签中获得,但它们实际上是按2的幂次递增……,1/128,1/64,1/32,1/16,1/8,……而不是标记的……,1/125,1/60,1/30,1/15,1/8,……——见练习2.5。)因此,未知数是每个像素的曝光时间Ei和响应值gk = g(k),其中g可以根据八位图像中常见的256个像素值进行离散化。(响应曲线分别针对每个颜色通道进行了校准。)
为了使响应曲线平滑,Debevec和Malik(1997)添加了二阶平滑约束
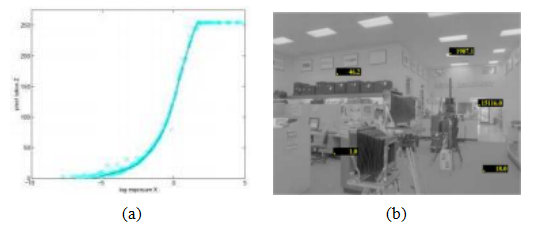
图10.14实际数码相机(DCS460)的恢复响应函数和辐射图像(Debevec和Malik1997)©1997 ACM。
这与蛇中使用的函数(7.27)类似,因为像素值在其范围的中间部分更可靠(并且g函数在饱和值附近变得奇异),因此它们还添加了一个加权(hat)函数w(k),该函数在像素值的两端衰减为零
一系列
(10.6)
将所有这些项放在一起,他们得到了一个未知数{gk }和{Ei }的最小二乘问题,
(为了消除响应曲线和辐照度值的整体偏移模糊性,将响应曲线的中间设置为0。)Debevec和Malik(1997)展示了如何在21行MATLAB代码中实现这一点,这在一定程度上解释了他们技术的流行。
虽然Debevec和Malik(1997)假设暴露时间tj是精确已知的,但没有理由认为这些附加变量不能被加入到最小二乘法中
问题,限制他们的最终估计值接近他们的名义值j
附加项η Σj
图10.14展示了数字相机的恢复辐射响应函数以及整体辐射图中选定(相对)辐射值。图10.15显示了彩色胶片拍摄的括号内输入图像及其对应的辐射图。请注意,尽管大多数关于高动态范围成像的研究假设辐射响应函数(或相机响应函数)与曝光无关,但实际情况并非如此。罗德里格斯,

图10.15用胶片相机拍摄的带有括号的曝光集,以及以伪彩色显示的结果辐射图像(Debevec和Malik1997)©1997 ACM。
Vazquez-Corral和Bertalm o(2019)描述了如何考虑这一点以获得更好的结果。
Debevec和Malik(1997)使用一般二阶平滑曲线g来参数化他们的响应曲线,而Mann和Picard(1995)使用三参数函数
f (E) = α + βE , (10.8)
虽然三浦和奈亚(1999)使用低阶(N≤10)多项式作为逆响应函数g。帕尔、泽利斯基等人(2004)推导出一个贝叶斯模型,该模型为每张图像估计一个独立的平滑响应函数,能够更好地模拟当今数码相机中更复杂(因此也更不可预测)的自动对比度和色调调整。
一旦响应函数被估计出来,创建高动态范围照片的第二步就是将输入图像合并成一个复合辐射图。如果响应函数和图像完全已知,即没有噪声,你可以使用任何非饱和像素值通过逆响应曲线E = g(z)来估算相应的辐射值。
不幸的是,像素存在噪声,尤其是在低光条件下,到达传感器的光子较少。为了补偿这一点,Mann和Picard(1995)使用响应函数的导数作为权重来确定最终的辐射度估计值,因为曲线中“更平坦”的区域告诉我们关于入射辐照度的信息较少。Debevec和Malik(1997)使用了一个帽函数(10.6),该函数强调中间色调像素,同时避免饱和值。Mitsunaga和Nayar(1999)表明,为了最大化信噪比(SNR),

图10.16合并多个曝光以创建高动态范围合成
(Kang,Uyttendaele等人,2003年):(a-c)三种不同的曝光;(d)使用经典算法合并曝光(注意由于马头移动造成的重影);(e)使用运动补偿合并曝光。
加权函数必须强调传输函数中的较高像素值和较大梯度,即,
w(z) = g(z)/g, (z), (10.9)
其中权重w用于形成最终辐照度估计值
logEi =
(10.10)
练习10.1要求您实现一种辐射响应函数校准技术,然后使用它创建辐射度图。
在实际条件下,随意获取的图像可能无法完美对齐,并且可能包含移动物体。Ward(2003)使用全局(参数)变换来对齐输入图像,而Kang、Uyttendaele等人(2003)提出了一种算法,该算法结合了全局配准与局部运动估计(光流),以准确对齐图像,然后融合它们的辐射估计(图10.16)。由于图像的曝光可能差异很大,在估计运动时必须谨慎,这些运动本身也必须检查一致性,以避免产生鬼影和物体碎片。
然而,即使这种方法,在摄像机同时进行大幅度的平移运动和曝光变化时也可能不起作用,这是随意拍摄全景图时常见的现象。在这种情况下,图像的不同部分可能在一处被看到。

图10.17 HDR与大量运动的合并(Eden、Uyttendaele和Szeliski
2006)©2006 IEEE: (a)注册括号内的输入图像;(b)第一次图像选择后的结果:参考标签、图像和色调映射图像;(c)第二次图像选择后的结果:最终标签、压缩HDR图像和色调映射图像
或者更多的曝光。设计一种方法来融合所有这些不同的来源,同时避免急剧的过渡并处理场景运动是一个具有挑战性的问题。一种方法是首先找到一个共识马赛克,然后有选择地计算欠曝和过曝区域的辐射度(Eden,Uyttendaele和Szeliski 2006),如图Figure10.17所示。关于构建和显示高动态范围视频的其他技术,在Myszkowski、Mantiuk和Krawczyk(2008)、Tocci、Kiser等人(2011)、Sen、Kalantari等人(2012)、Dufaux、Le Callet等人(2016)、Banterle、Artusi等人(2017)以及Kalantari和Ramamoorthi(2017)中有所讨论。另一种方法是使用深度学习技术从单个低动态范围图像推断出高动态范围辐射度图像(Liu、Lai等人2020b)。
一些相机,如索尼α550和宾得K-7,已经开始将多重曝光合并和色调映射直接集成到相机机身中。未来,随着相机传感器技术的进步,可能不再需要通过计算多张曝光来生成高动态范围图像(杨、埃尔·加马尔等,1999;奈亚尔和米茨纳加,2000;奈亚尔
以及Branzoi2003;Kang、Uyttendaele等人2003;Narasimhan和Nayar2005;Tumblin、Agrawal和Raskar2005)。然而,将这些图像混合并将其色调映射到低色域显示器的需求可能仍然存在。
HDR图像格式。在我们讨论将HDR图像映射回可显示色域的技术之前,我们应该讨论用于存储HDR图像的常用格式。
如果存储空间不是问题,将每个红、绿、蓝值分别存储为32位IEEE浮点数是最佳解决方案。常用的便携式像素图(.ppm)格式支持未压缩的ASCII和原始二进制编码,通过修改头部可以扩展为便携式浮点图(.pfm)格式。TIFF也支持完整的浮点值。
更紧凑的表示形式是Radiance格式(.pic,.hdr)(Ward1994),它
使用一个共同的指数和每个通道的尾数。中间编码,ILM的OpenEXR,14为每个通道使用16位浮点数,这是大多数系统原生支持的格式
现代GPU。Ward(2004)对这些以及其他数据格式如LogLuv(Larson 1998)进行了更详细的描述,Freeman(2008)和Reinhard、Heidrich等人(2010)的书籍也对此进行了详细描述。一种更近的HDR图像格式是JPEG XR标准。
一旦计算出一个光辉图,通常需要将其显示在较低色域(即八位)的屏幕或打印机上。为此,已经开发了多种色调映射技术,这些技术要么计算空间变化的传输函数,要么减少图像梯度以适应可用的动态范围(Reinhard,Heidrich等,2010)。
将高动态范围辐射图像压缩到低动态范围色域的最简单方法是使用全局转移曲线(Larson,Rushmeier和Piatko 1997)。图10.18显示了一个这样的例子,其中使用了伽马曲线将HDR图像映射回可显示的色域。如果对每个通道分别应用伽马(图10.18b),颜色会变得暗淡(饱和度降低),因为高值颜色通道对最终颜色的贡献较少(按比例减少)。通过使用公式(2.104)从彩色图像中提取亮度通道,然后对亮度通道应用全局映射,再用公式(10.19)重建彩色图像,效果更好(图10.18c)。
不幸的是,当图像具有非常宽的曝光范围时,这种全局方法仍然无法在曝光范围广泛变化的区域中保留细节。需要的是,在-
稳住,这有点像摄影师在黑暗中躲闪和燃烧

图10.18全局色调映射:(a)输入HDR图像,线性映射;(b)对每个颜色通道独立应用gamma;(c)对强度应用gamma(颜色不那么褪色)。原始HDR图像由Paul Debevec,https://www.pauldebevec.com/提供
研究/HDR。处理过的图像由Frdo Durand提供,MIT 6.815/6.865课程
计算摄影。
从数学上讲,这与将每个像素除以该像素周围区域的平均亮度类似。
图10.19显示了这一过程的工作原理。与之前一样,图像被分解为其亮度和色度通道。对数亮度图像
H(x,y)= log L(x,y) (10.11)
然后进行低通滤波,生成基础层
HL (x, y) = B (x, y) * H (x, y), (10.12)和高通细节层
HH (x, y) = H (x, y) - HL (x, y). (10.13)然后通过缩放至所需的对数亮度范围来降低基底层的对比度,
HH, (x, y) = s HH (x, y) (10.14)
并添加到细节层以生成新的对数亮度图像
我(x,y) = HH,(x,y) + HL (x,y), (10.15)
然后可以进行指数运算,生成色调映射(压缩)的亮度图像。注意,这个过程等同于将每个亮度值除以(该像素周围区域的平均对数亮度值的单调映射)。

图10.19使用线性滤波器进行局部色调映射:(a)低通和高通滤波后的对数亮度图像及彩色(色度)图像;(b)经过处理的色调映射图像(在衰减低通对数亮度图像后)显示树木周围有可见的光环。处理过的图像由MIT 6.815/6.865计算摄影课程的Frdo Durand提供。

图10.20使用双边滤波器进行局部色调映射(Durand和Dorsey2002):(a)低通和高通双边滤波的对数亮度图像和彩色(色度)图像;(b)色调映射后的结果图像(在衰减低通对数亮度图像后)
没有显示光环。经过处理的图像由Frdo Durand提供,MIT 6.815/6.865课程
计算摄影。
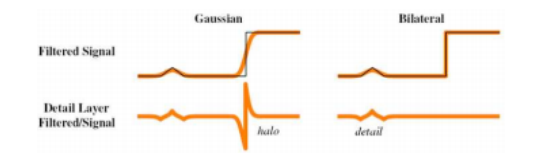
图10.21高斯滤波与双边滤波对比(Petschnigg,Agrawala等,2004)©2004 ACM:高斯低通滤波会在所有边缘上产生模糊效果,因此在细节图像中形成强烈的峰值和谷值,导致光环效应。而双边滤波不会平滑强边缘,从而减少光环效应,同时仍能捕捉到细节。
图10.19展示了低通和高通对数亮度图像以及最终的色调映射彩色图像。请注意,高对比度边缘处的细节层出现了可见的光环,这些光环在最终的色调映射图像中仍然可见。这是因为线性滤波不保留边缘特征,导致细节层中产生了光环(图10.21)。
解决这个问题的方法是使用边缘保持滤波器来创建基础层。杜兰德和多尔西(2002)研究了多种这样的边缘保持滤波器,包括各向异性和鲁棒各向异性扩散,并选择了双边滤波(第3.3.1节)作为他们的边缘保持滤波器。(法布曼、法塔尔等人(2008)的文章主张使用加权最小二乘(WLF)滤波器作为双边滤波器的替代方案,而帕里斯、科尔普罗斯特等人(2008)则回顾了双边滤波及其在计算机视觉和计算摄影中的应用。)图10.20展示了用双边滤波器替换线性低通滤波器后,生成的色调映射图像中没有可见的光晕。图10.22总结了这一过程中的完整信息流,从分解为对数亮度和色度图像开始,经过双边滤波、对比度降低,最后重新组合成最终输出图像。
压缩基础层的替代方法是压缩其衍生物,即对数亮度图像的梯度(Fattal、Lischinski和Werman 2002)。图10.23illus-
处理此过程。对对数亮度图像进行微分以获得梯度图像
H, (x, y) = ▽H(x, y). (10.16)
然后,该梯度图像通过空间变化衰减函数Φ(x,y)而衰减,
G(x, y) = H, (x, y) Φ(x, y). (10.17)
衰减函数I(x,y)旨在衰减大规模亮度变化(图10.24a),并考虑不同空间尺度的梯度(Fattal,
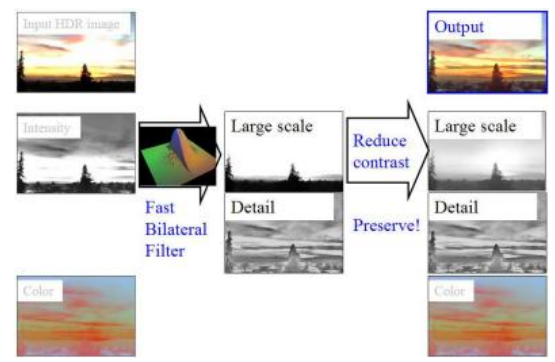
图10.22使用双边滤波器的局部色调映射(Durand和Dorsey2002):sum-
算法工作流程的玛丽。图片由MIT 6.815/6.865课程的Frdo Durand提供
计算摄影。
Lischinski和Werman2002)。
衰减后,通过求解一阶变分(最小二乘法)问题重新整合所得梯度场,
最小值∫∫Ⅱ▽I(x,y)-G(x,y)Ⅱ2 dx dy (10.18)
为了获得压缩的对数亮度图像I(x,y)。这个最小二乘问题与用于泊松混合的问题相同(第8.4.4节),并且首次在我们关于正则化的研究中引入(第4.2,4.24节)。可以使用多网格和层次基预处理等技术高效地解决这个问题(Fattal、Lischinski和Werman 2002;Szeliski 2006b;Farbman、Fattal等2008;Krishnan和Szeliski 2011;Krishnan、Fattal和Szeliski 2013)。一旦新的亮度图像计算完成,它将与原始彩色图像结合使用。
Cout = s Lout,
(10.19)
其中C =(R,G,B)和Lin、Lout分别是原始和压缩后的亮度图像。指数控制颜色的饱和度,通常在s∈[0.4,0.6]范围内(Fattal,Lischinski,和Werman 2002)。图10.24b显示了最终的色调映射颜色。
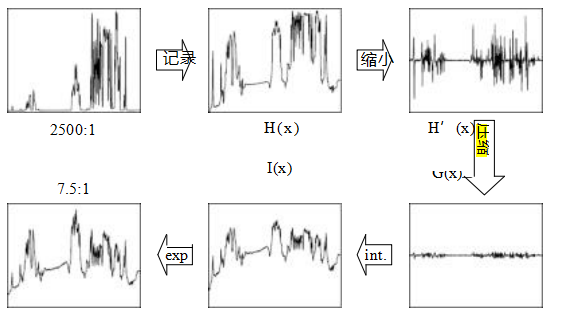
图10.23梯度域色调映射(Fattal、Lischinski和Werman 2002)©2002 ACM。原始图像的动态范围为2415:1,首先转换到对数域H(x),并计算其梯度H(x)。这些梯度根据局部对比度G(x)进行衰减(压缩),然后积分生成新的对数曝光图像I(x),再进行指数运算生成最终强度图像,其动态范围为7.5:1。
图像,尽管输入辐射值的差异极大,但没有可见的光环。
另一种替代方法是使用局部尺度选择算子进行局部遮挡和烧录(Reinhard,Stark等,2002)。图10.25展示了这种尺度选择算子如何确定一个半径(尺度),仅包含内圈内的相似颜色值,同时避免周围圈中更亮的值。实际上,在一系列尺度上评估由内高斯响应归一化的高斯差异,并选择其度量值低于阈值的最大尺度(Reinhard,Stark等,2002)。
另一种最近开发的基于多分辨率分解的色调映射方法是局部拉普拉斯滤波器(Paris、Hasinoff和Kautz 2011),我们在第3.5.3节中介绍过。拉普拉斯金字塔中的系数由局部对比度调整的补丁构建而成,这使得该技术不仅能够对HDR图像进行色调映射,还能增强局部细节并实现风格转换(Aubry、Paris等2014)。
所有这些技术的共同点是,它们能够自适应地减弱或增强图像的不同区域,从而可以在有限的色域内显示而不会损失对比度。Lischinski、Farbman等人(2006)介绍了一种交互式技术,该技术执行

图10.24梯度域色调映射(Fattal、Lischinski和Werman2002)©
2002 ACM:(a)衰减图,数值越深表示衰减越大;(b)最终色调映射图像。
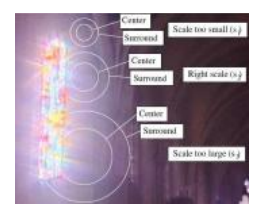
图10.25声调映射的尺度选择(Reinhard、Stark等人,2002)©2002 ACM。

图10.26交互式局部色调映射(Lischinski,Farbman等人,2006)©2006
ACM:(a)用户绘制的笔画,带有相关的曝光值g(x,y);(b)相应的分段平滑曝光调整图f (x,y)。
该操作是通过将一组稀疏的用户绘制的调整(笔画和相关的曝光值校正)插值到分段连续的曝光校正图中(图10.26)。插值是通过最小化局部加权最小二乘法(WLS)变分问题来完成的,
min∫∫wd(x,y)Ⅱf(x,y)- g(x,y)Ⅱ2 dx dy + λ∫∫ws(x,y)Ⅱ▽f(x,y)Ⅱ2 dx dy,
(10.20)其中g(x,y)和f(x,y)分别是输入和输出的对数曝光(衰减)图(图10.26)。数据加权项wd(x,y)在刻痕位置为1,其他地方为0。平滑度加权项ws(x,y)与对数亮度梯度成反比,
(10.21)
因此,鼓励f(x,y)映射在低梯度区域比高梯度不连续处更加平滑。同样的方法也可以用于完全自动化的色调映射,通过为每个像素设置目标曝光值,并允许加权最小二乘法将这些值转换为分段平滑的调整图。
加权最小二乘算法最初是为图像色彩校正应用开发的(Levin,Lischinski和Weiss 2004),后来被应用于一般的边缘保持平滑处理,例如对比度增强(Bae,Paris和Du-Rand 2006)和色调映射(Farbman,Fattal等2008),其中之前使用了双边滤波。该算法还可以同时执行HDR合并和色调映射(Raman和Chaudhuri 2007,2009)。
鉴于已经开发出多种局部自适应色调映射算法,实际应用中应该选择哪一种?弗里曼(2008)对市面上可用的算法、它们产生的伪影以及可用于控制这些伪影的参数进行了深入讨论。他还提供了大量关于HDR摄影和工作流程的建议。我强烈推荐这本书给任何考虑在此领域进行进一步研究(或个人摄影)的人。
虽然高动态范围成像结合了在不同曝光下拍摄的场景图像,但也可以结合闪光灯和非闪光灯图像以实现更好的曝光和色彩平衡,并减少噪声(Eisemann和Durand2004;Petschnigg、Agrawala等人2004)。
15在实践中,x和y离散导数分别进行加权(Lischinski、Farbman等人,2006)。它们的默认参数设置为λ = 0.2、Q = 1和∈= 0.0001。

图10.27闪光/非闪光摄影中的细节转移(Petschnigg,Agrawala等人。
2004)©2004 ACM:输入环境A和闪光F图像的细节;(b)联合双边滤波无闪光图像ANR;(c)细节层F从闪光图像F计算出的细节;(d)最终合并图像AFinal。
闪光灯照片的问题在于色彩往往不自然(无法捕捉环境光线),可能存在强烈的阴影或镜面反射,且远离相机处亮度呈径向衰减(图10.1b和10.27a)。在低光条件下拍摄的非闪光灯照片通常会受到过多噪点的影响(因为高ISO增益和低光子计数),以及模糊(由于曝光时间较长)。是否有一种方法可以将闪光前拍摄的非闪光灯照片与闪光灯照片结合,以产生色彩值良好、清晰度高且噪点低的图像?事实上,已停产的富士胶片FinePix F40fd相机可以快速连续拍摄一对闪光和非闪光的照片;然而,它只允许你选择保留其中一张。
Petschnigg、Agrawala等人(2004)首先使用一种称为联合双边滤波器16的双边滤波器变体对无闪光(环境)图像A进行滤波,其中范围核(3.36)
=
exp
(10.22)
评估基于闪光图像F而非环境图像A,因为闪光图像是噪声较少,因此边缘更可靠(图10.27b)。由于阴影和镜面反射区域内的内容可能不可靠,这些部分会被检测出来,从而使用经过常规双边滤波的环境图像ABase(图10.28)。
他们的算法的第二阶段计算一个闪光细节图像
(10.23)
16 Eisemann和Durand(2004)称其为交叉双边滤波器。
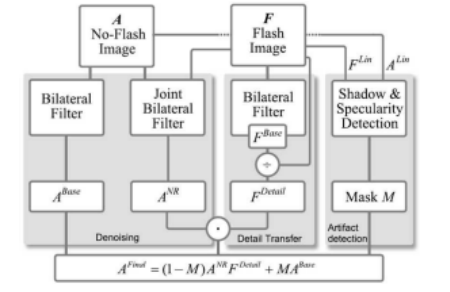
图10.28闪光/非闪光摄影算法(Petschnigg,Agrawala等,2004)©2004 ACM。环境(非闪光)图像A通过常规双边滤波器过滤生成ABase,用于阴影和镜面区域,以及一个联合双边滤波降噪图像ANR。闪光图像F通过双边滤波生成基础图像F base和细节(比例)图像F detail,后者用于调制去噪后的环境图像。阴影/镜面掩模M通过比较闪光和非闪光图像的线性化版本计算得出。
其中F Base是闪光图像F的双边滤波版本,∈= 0.02。这个细节图像(图10.27c)编码了可能被降噪后的无闪光图像ANR滤除的细节,以及由闪光相机产生的额外细节,这些细节通常增加了清晰度。细节图像用于调制降噪后的环境图像ANR,以生成最终结果。
最终=(1 - M)ANRF详细+ MABase (10.24)
如图10.1和10.27d所示。
Eisemann和Durand(2004)提出了一种替代算法,该算法与上述基本概念有相似之处。两篇文章都值得阅读并进行对比(练习10.6)。
闪光图像还可以用于多种其他应用,例如提取更可靠的物体前景遮罩(Raskar,Tan等2004;Sun,Li等2006)。给定足够大的训练集,也可以将单张闪光图像分解为其环境光和闪光光照成分,这些成分可用于调整其外观(Aksoy,Kim等2018)。闪光摄影只是主动照明这一更广泛主题的一个实例,该主题由Raskar和Tumblin(2010)以及Ikeuchi,Matsushita等(2020)进行了更详细的讨论。
虽然高动态范围成像技术使我们能够获得比单个普通图像具有更大动态范围的图像,但超分辨率技术使我们能够创建空间分辨率更高、噪声更少的图像(Chaudhuri 2001;Park等2003;Capel和Zisserman 2003;Capel 2004;van Ouwerkerk 2006;Anwar等2020)。通常情况下,超分辨率指的是通过对齐和组合多个输入图像来生成高分辨率合成图像的过程(Irani和Peleg 1991;Cheeseman等1993;Pickup等2009;Wronski等2019)。然而,一些技术可以对单个图像进行超分辨率处理(Freeman等2002;Baker和Kanade 2002;Fattal 2007;Anwar等2020),因此与去模糊技术密切相关(第3.4.1节和第3.4.2节)。Anwar、Khan和Barnes(2020)提供了关于单图像超分辨率技术的全面综述,特别关注最近基于深度学习的方法。
一种传统的超分辨率问题的表述方法是写出随机图像形成方程和图像先验,然后使用贝叶斯推断来恢复超分辨率(原始)清晰图像。我们可以通过推广用于图像去模糊的图像形成方程(第3.4.1节),以及用于模糊核(PSF)估计的图像形成方程(第10.1.4节)来实现这一点。在这种情况下,我们有多个观测图像{ok (x)},以及
作为每个观察图像的图像扭曲函数k(x)(图3.46)。组合所有
在这些元素中,我们得到(有噪声的)观测方程17
ok (x) = D{b(x) * s(k (x))} + nk (x), (10.25)
其中D是下采样算子,它在超分辨(清晰)扭曲图像s(k (x))与模糊核b(x)卷积之后进行操作。上述图像形成方程导致以下最小二乘问题,
(10.26)
在大多数超分辨率算法中,对齐(变形)k是使用其中一个输入帧作为参考帧来估计的;可以采用基于特征(Section8.1.3)或直接(图像基础)(第9.2节)参数化对齐技术。(一些算法,如舒尔茨和史蒂文森(1996)、卡佩尔(2004)以及沃恩斯基、加西亚-多拉多等人(2019)所描述的,使用密集(逐像素流)估计。)更好的方法是重新计算
在计算出s(x)的初始估计值后,通过直接最小化(10.26)进行对齐(Hardie、Barnard和Armstrong1997),或者完全边缘化运动参数(Pickup、Capel等人2007)。
点扩散函数(模糊核)bk是根据图像形成过程的知识推断出来的(例如,运动或失焦模糊的程度以及相机传感器光学特性),或者通过测试图像或观察到的图像{ok }使用第10.1.4节中描述的技术之一进行校准。同时推断模糊核和清晰图像的问题被称为盲图像去卷积(Kundur和Hatzinakos 1996;Levin 2006;Levin,Weiss等2011;Campisi和Egiazarian2017).18
给定k和bk (x)的估计值,可以使用矩阵/向量符号重新编写公式(10.26)。
Ⅱ
ok - DBkWksⅡ2 . (10.27)
(回忆(3.75),一旦变形函数k已知,s(k (x))的值就取决于
线性地处理s(x)中的值。)解决这个最小二乘问题的有效方法是使用预条件共轭梯度下降法(Capel2004),尽管一些早期算法,如Irani和Peleg(1991)开发的算法,使用了常规梯度下降法(在计算机断层扫描文献中也称为迭代反投影(IBP))。
上述公式假设变形可以表示为超分辨率锐利图像的简单(sinc或bicubic)插值重采样,随后是静态(空间不变)模糊(PSF)和面积积分过程。然而,如果表面严重缩短,我们必须考虑在图像变形过程中发生的空间变化滤波(第3.6.1节),然后才能建模由光学系统和相机传感器引起的PSF(王、康等2001;Capel 2004)。
这种最小二乘(MLE)方法在超分辨率中的表现如何?实际上,这很大程度上取决于相机光学系统的模糊和混叠程度,以及运动和点扩散函数估计的准确性(Baker和Kanade 2002;Jiang、Wong和Bao 2003;Capel 2004)。较少的模糊和更多的混叠意味着有更多(混叠的)高频信息可供恢复。然而,由于最小二乘(最大似然)公式不使用图像先验,因此可能会引入大量高频噪声到解决方案中(图10.29c)。
为此,经典超分辨率算法假设某种形式的图像先验。其中最简单的方法是像公式(4.29)那样对图像导数施加惩罚。
请注意,如果模糊核和超分辨率图像都未知,就会出现鸡生蛋还是蛋生鸡的问题。这个问题可以通过使用关于清晰图像的结构假设来“解决”,例如边缘的存在(Joshi、Szeliski和Kriegman 2008),或者使用图像的先验模型,如边缘稀疏性(Fergus、Singh等2006)。

图10.29使用各种图像先验的超分辨率结果(Capel2001):(a)
低分辨率ROI(双三次3倍放大);(b)平均图像;(c)MLE@1.25倍像素放大;(d)简单2x2先验(λ = 0.004);(e) GMRF(λ = 0.003);(f) HMRF(λ = 0.01,α = 0.04)。使用10张图像作为输入,在每种情况下生成一张3倍超分辨率图像,但不包括(c)中的MLE结果。
(4.42), e.g.,
(10.28)
正如第4.3节所述,当Pp是二次时,这属于Tikhonov正则化(第4.2节),整体问题仍然是线性最小二乘法。由此产生的先验图像模型是一个高斯马尔可夫随机场(GMRF),可以扩展到其他(例如对角)差异,如Capel(2004)和Figure10.29所述。
不幸的是,GMRFs生成的解往往带有可见的波纹,这也可以解释为中频噪声敏感度增加。更好的图像先验是一种稳健的先验,鼓励分段连续的解(Black和Rangarajan 1996),详见附录B.3。这类先验的例子包括Huber势函数(Schultz和Stevenson 1996;Capel和Zisserman 2003),它是高斯分布与长尾拉普拉斯分布的混合体,以及Levin、Fergus等人(2007)和Krishnan和Fergus(2009)使用的更稀疏(重尾)的超拉普拉斯分布。此外,还可以通过交叉验证学习这些先验的参数(Capel 2004;Pickup 2007)。
而稀疏(稳健)的导数先验可以减少波动效应并增加边缘

图10.30基于示例的超分辨率:(a)原始32×32低分辨率图像;(b)基于示例的超分辨率256×256图像(Freeman,Jones,和Pasztor 2002)©2002 IEEE;(c)通过施加边缘统计进行上采样(Fattal 2007)©2007 ACM。
清晰度方面,它们无法产生更高频率的纹理或细节。为此,可以使用一组训练样本图像来寻找低频原始图像与缺失的高频部分之间的合理映射关系。受我们在第10.5节讨论的一些基于示例的纹理合成算法启发,弗里曼、琼斯和帕斯特(2002)开发的基于示例的超分辨率算法利用训练图像学习局部纹理块与缺失的高频细节之间的映射关系。为了确保重叠的纹理块在外观上相似,使用了马尔可夫随机场,并通过信念传播(弗里曼、帕斯特和卡迈克尔2000)或光栅扫描确定性变体(弗里曼、琼斯和帕斯特2002)进行优化。图10.30展示了使用这种方法生成缺失细节的结果,并将其与法塔尔(2007)提出的更近期算法进行了比较。后者算法能够根据像素相对于最近检测到的边缘的位置及其相应的边缘统计信息(幅度和宽度),预测精细分辨率图像中的方向梯度幅度。此外,还可以将稀疏(鲁棒)导数先验与基于示例的超分辨率相结合,如塔彭、拉塞尔和弗里曼(2003)所示。
一种替代(但密切相关)的幻觉形式是识别训练图像数据库中低分辨率像素可能对应的部分。在他们的研究中,贝克和卡纳德(2002)使用局部高斯导数滤波器响应作为特征,然后以类似于德博内特(1997)的方式匹配父结构向量。每个识别出的训练图像位置的高频梯度随后被用作超分辨率图像的约束条件,同时结合常规的重建(预测)公式(10.26)。

图10.31基于识别的超分辨率(Baker和Kanade2002)©2002 IEEE。幻觉列显示了基于识别的算法与Hardie、Barnard和Armstrong(1997)的正则化方法的结果对比。
图10.31显示了从低分辨率输入中产生高分辨率人脸的幻觉结果;Baker和Kanade(2002)也展示了已知字体文本的超分辨率示例。练习10.7提供了更多关于如何实现和测试这些超分辨率技术之一或多个的详细信息。
超分辨率领域的最新趋势是使用深度神经网络直接预测超分辨率图像。这一方法始于Dong、Loy等人(2016)的开创性工作,已经产生了数十种不同的深度神经网络和架构,包括最新NVIDIA显卡中嵌入的深度学习超采样硬件(Burnes2020)。Anwar、Khan和Barnes(2020)最近关于单图像超分辨率的综述将这些算法分类为一个分类法(Figure10.32a),提供了网络架构的图示总结(图10.32b),并在无噪声已知双三次核降采样图像数据集上对超分辨率结果进行了数值和视觉比较。尽管图10.33所示的结果显示了算法之间的显著差异,但尚不清楚这些算法在面对未知模糊核的真实世界噪声输入时表现如何。由Cai、Zeng等人(2019)开发的RealSR真实世界超分辨率数据集,使用数码相机上的变焦镜头拍摄,提供了一种测试(和训练)算法在真实成像退化情况下的方法。该数据集构成了NTIRE的基础。

图10.33一些超分辨率算法的视觉比较(Anwar、Khan和Barnes2020)©2020 ACM。

图10.34 Gu和Timofte(2019)的去噪算法时间线©2019
蹦跳的人
真实图像超分辨率的挑战(Cai,Gu等人,2019),20提供了最近基于深度网络算法的经验比较。
虽然单图像超分辨率技术很有趣,但通过在智能手机摄像头中直接构建多帧超分辨率算法,可以取得更加令人印象深刻(且实用)的结果,这样处理过程可以与图像去马赛克同时进行。我们在Section10.3.1和图10.38中讨论了Wronski、Garcia-Dorado等人(2019年)关于彩色图像去马赛克的最新工作。此外,还可以使用帧插值在时间维度上提升视频质量(第9.4.1节),使用视频超分辨率在空间维度上提升视频质量(Liu和Sun 2013;Kappeler、Yoo等人2016;Shi、Caballero等人2016;Tao、Gao等人2017;Nah、Timo-ftp等人2019;Isobe、Jia等人2020;Li、Tao等人2020),或同时在空间和时间维度上提升视频质量(Kang、Jo等人2020)。
图像去噪是图像处理和计算机视觉中的经典问题之一(Per- ona和Malik 1990b;Rudin、Osher和Fatemi 1992;Buades、Coll和Morel 2005b)。在过去的四十年里,已经开发了数百种算法,该领域仍在积极研究中,最近的算法都基于深度神经网络。
最新的图像去噪算法比较基准,NTIRE 2020实际图像去噪挑战赛(Abdelhamed,Afifi等2020),基于智能手机图像去噪数据集(SIDD)(Abdelhamed,Lin和Brown 2018),其中无噪声的真实图像通过平均150张带噪图像获得。这比大多数先前基准中使用的合成带噪图像提供了更加真实多样的实际噪声和图像处理模型(除了(Pl tz和Roth 2017))。
Gu和Timofte(2019)最近(简短)的图像去噪调查包括以下开创性的去噪论文21(请参见图10.34的时间线):
总变差(TV)(Rudin、Osher和Fatemi1992;Chan、Osher和Shen2001;Chambolle2004;Chan和Shen2005),
高斯尺度混合(GSM)(Lyu和Simoncelli2009),
专家小组(FoE)(Roth和Black2009),
非局部方法(NLM)(Buades、Coll和Morel,2005a、b),
BM3D (Dabov,Foi等人,2007),
稀疏过完备字典(K-SVD)(Aharon,Elad和Bruckstein2006),
?预期补丁日志似然性(EPLL)(Zoran和Weiss2011),
MLP降噪器(Burger、Schuler和Harmeling,2012),
加权核范数最小化(WNNM)(Gu,Zhang等人,2014),
•收缩场(脑脊液)(Schmidt和Roth,2014),
?可训练的非线性反应扩散(TNRD)(Chen和Pock2016),
彩色图像的跨通道噪声模型(Nam,Hwang等人,2016),
20https://data.vision.ee.ethz.ch/cvl/ntire20/,https://data.vision.ee.ethz.ch/cvl/aim20/
21我添加了更多来自Brown(2019)的ICCV教程的论文,以及Abdelrahman Abdelhamed的几个额外建议。
•去噪残差CNN(DnCNN)(Zhang,Zuo等人,2017),现在被认为是DNN去噪的基线,以及
学习在黑暗中看东西(陈,陈等人,2018)。
尽管这些结果随着时间显著改善,但如今的成像传感器大多能产生相对干净的图像,除非在低光环境下,此时需要增加ISO相机增益,读取和光子噪声会与信号强度相当。在这种情况下,如果可能的话,最好快速拍摄一系列低ISO(增益)的照片,然后将这些照片合并以获得去噪后的图像(Hasinoff,Kutulakos等2009;Hasinoff,Durand和Freeman 2010;Liu,Yuan等2014)。这种方法被推广并应用于低光摄影中,例如Hasinoff、Sharlet等人的HDR+系统(2016)。近年来,在这一领域的一些研究结合了低光摄影、马赛克消除以及某些情况下的超分辨率技术,包括Godard、Matzen和Uyttendaele(2018)、Chen、Chen等(2018)、Mildenhall、Barron等(2018)、Wronski、Garcia-Dorado等(2019)以及Rong、Demandolx等(2020)的研究。Liba、Murthy等(2019)描述了谷歌夜间视图功能背后的技术,该功能不仅能够在嘈杂条件下稳健地对齐和合并不同的移动区域,还引入了“运动测光”概念来确定最佳帧数和曝光时间。
消除模糊
在有利条件下,超分辨率及相关上采样技术可以提高拍摄良好图像或图像集合的分辨率。当输入图像本身模糊时,通常所能期望的是减少模糊的程度。这个问题与超分辨率密切相关,最大的不同在于模糊核b通常要大得多(且未知),而下采样因子D为1。
关于图像去模糊的文献非常丰富;一些优秀的文献综述包括Fergus、Singh等人(2006年)、Yuan、Sun等人(2008年)和Joshi、Zitnick等人(2009年)。通过将清晰(但有噪声)的图像与更模糊(但更干净)的图像结合,也可以减少模糊(Yuan、Sun等人,2007年),快速多次曝光(Hasinoff和Kutulakos,2011年;Hasinoff、Kutulakos等人,2009年;Hasinoff、Durand和Freeman,2010年),或使用编码光圈技术同时估计深度并减少模糊(Levin、Fergus等人,2007年;Zhou、Lin和Nayar,2009年)。当可用时,机载惯性测量单元(IMU)的数据可用于确定模糊核(Joshi、Kang等人,2010年)。还可以利用双像素传感器的信息来辅助失焦图像的去模糊(Abuolaim和Brown,2020年)。
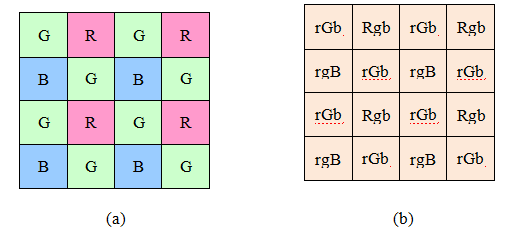
图10.35 Bayer RGB模式:(a)彩色滤光片阵列布局;(b)插值像素值,未知(猜测)值显示为小写字母。
过去十年间,大量基于学习的去模糊算法被引入(孙、曹等人2015;舒勒、希施等人2016;纳赫、金贤、李穆2017;库平、布德赞等人2018;陶、高等人2018;张、戴等人2019;库平、马尔蒂纽克等人2019)。此外,还有一些研究致力于在去模糊图像中人工重新引入纹理,以更好地匹配预期的图像统计特性(赵、乔希等人2012),即现在通常所说的感知损失(Section5.3.4)。
超分辨率的一个特例是日常大多数数码相机中使用的去马赛克过程,即将来自彩色滤光阵列(CFA)的样本转换为全彩RGB图像。图10.35展示了最常用的CFA,即拜耳模式,其中绿色(G)传感器的数量是红色和蓝色传感器的两倍。
从已知的CFA像素值转换到完整的RGB图像的过程相当具有挑战性。与常规超分辨率不同,后者中猜测未知值的小误差通常表现为模糊或混叠,而去马赛克伪影往往会产生虚假的颜色或高频图案化的拉链效应,这些现象肉眼可见(Figure10.36b)。
多年来,人们开发了多种图像去马赛克技术(Kim- mel1999)。Longere等人(2002)、Tappen、Russell和Freeman(2003)以及Li、Gunturk和Zhang(2008)对这一领域进行了综述,并使用感知动机指标比较了先前开发的技术。为了减少锯齿效应,大多数技术利用绿色通道的边缘或梯度信息,该信息更可靠,因为采样密度更高,来推断红色和蓝色通道的合理值,这些通道的采样更为稀疏。

图10.36 CFA去马赛克结果(Bennett,Uyttendaele等2006)©2006斯普林格:(a)原始全分辨率图像(算法输入使用了彩色子采样版本);(b)双线性插值结果,显示蓝色蜡笔尖端附近有色彩边缘效应,左侧(垂直)边缘处有锯齿状现象;(c)Malvar,He和Cutler(2004)的高质量线性插值结果(注意黄色蜡笔上的强烈晕圈/棋盘格伪影);(d)使用Bennett,Uyttendaele等(2006)的局部双色先验。
为了减少色彩边缘效应,一些技术会进行色彩空间分析,例如,在颜色对立通道上使用中值滤波(Longere,Delahunt等人,2002)。Bennett、Uyttendaele等人(2006)的方法是从初始去马赛克结果计算局部双色模型,使用移动的5×5窗口来找到两种主要颜色(图10.37)。22
一旦在每个像素处估计了局部颜色模型,就会使用贝叶斯方法来鼓励像素值沿着每条颜色线分布,并围绕主导颜色值聚集,这可以减少光晕(图10.36d)。贝叶斯方法还支持同时应用去马赛克、降噪和超分辨率处理,即多个彩色滤光阵列输入可以合并成高质量的全彩图像。最近结合去马赛克和降噪的研究包括查特吉、乔希等人(2011年)和加尔比、肖拉西亚等人(2016年)的论文。NTIRE 2020实际图像降噪挑战赛(阿卜杜勒哈迈德、阿菲菲等人2020年)包括一个关于去噪RAW(即彩色滤光阵列)图像的赛道。此外,金、法奇奥洛和莫雷尔(2020年)还有一篇有趣的研究,探讨了是否
22先前关于局部线性颜色模型的研究(Klinker、Shafer和Kanade 1990;Omer和Werman 2004)主要关注单个材料内的颜色和光照变化,而Bennett、Uyttendaele等人(2006)则使用双色模型来描述颜色(材料)边缘的变化。
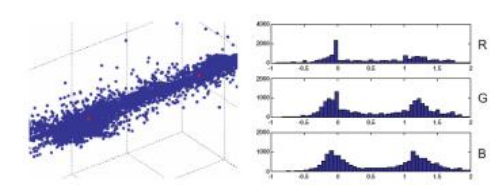
图10.37从局部5×5邻域集合计算出的双色模型(Bennett,Uyttendaele等,2006)©2006斯普林格。经过两均值聚类和沿两种主要颜色连线的重投影后,大多数像素集中在拟合线上。沿该线分布,沿RGB轴投影,在0和1这两个主要颜色处达到峰值。
在去马赛克之前或之后应用去噪。
正如我们之前提到的,爆发摄影(Cohen和Szeliski 2006;Hasinoff、Kutu- lakos等2009;Hasinoff和Kutulakos 2011),即快速获取图像序列的组合,在智能手机相机中变得越来越普遍。一个最近系统执行联合去马赛克和多帧超分辨率的例子是Wronski、Garcia-Dorado等人(2019)的论文,该论文基于局部适应核函数(图10.38),并支持谷歌Pixel智能手机中的“超级变焦”功能。
使用大光圈拍摄浅景深照片的能力(第2.2.3节)一直是大画幅相机,例如单反(SLR)相机的一大优势。人工模拟可重新对焦的浅景深相机的愿望是计算摄影(Levoy2006)背后的驱动力之一,并促成了光场相机的发展(Ng,Levoy等,2005),我们在Section14.3.4中对此进行了讨论。尽管一些商用型号,如Lytro已经问世,但用智能手机相机创建此类图像的能力直到最近才变得普遍。23
苹果iPhone 7 Plus配备了双镜头(广角/长焦),是首款引入这一功能的智能手机,他们称之为人像模式。尽管该功能背后的技术细节从未公布,但估计深度图像的算法(可以从人像图像的元数据中读取)可能使用了一些组合技术。
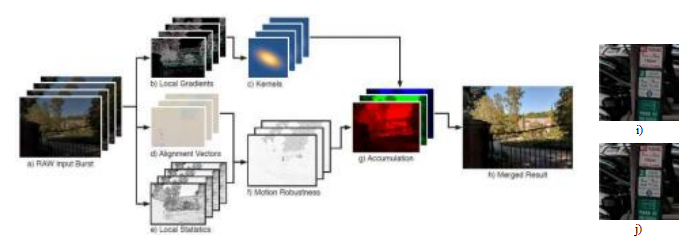
图10.38手持式多帧超分辨率(Wronski,Garcia-Dorado等人。
2019)©2019 ACM。处理管道,显示:(a)捕获的原始(拜耳
CFA)图像;(b)用于计算方向核的局部梯度(c);(d)运动估计,结合局部统计(e)以计算混合权重(f)。结果来自(i)Hasinoff、Sharlet等人(2016)的方法和(j)Wronski、Garcia-Dorado等人(2019)的方法。
立体匹配和深度学习的国度。不久之后,谷歌推出了自己的肖像模式,该模式利用了最初设计用于聚焦相机光学系统的双像素技术,结合人物分割计算深度图,正如瓦德瓦、加尔等人(2018)在论文中所述。一旦估计出深度图,就会使用一种快速近似的方法来实现从后向前模糊合成操作,从而正确地模糊背景而不包含前景颜色。最近,加尔、瓦德瓦等人(2019)通过使用深度网络提高了深度估计的质量,并且还使用了两个镜头(以及双像素)生成了更高品质的深度图(张、瓦德瓦等人,2020)。
关于散景,这是摄影师用来描述图像中出现的光斑或亮点形状的术语。这种形状由控制进入镜头光线量的光圈叶片配置决定(在大画幅相机上)。传统上,这些叶片是用直金属片制成的,导致形成了多边形光圈,但后来大多被弯曲的叶片取代,以产生更圆形的形状。使用计算摄影时,我们可以选择任何让摄影师满意的形状,但最好不是高斯模糊,因为高斯模糊不对应任何实际光圈,会产生模糊的亮点。Wadhwa、Garg等人(2018年)的论文中使用了圆形散景来实现景深效果,而最近的一个版本则在计算中采用了
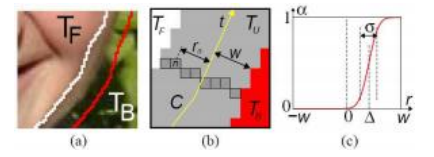
图10.39软化硬分割边界(边界遮罩)(Rother、Kolmogorov和Blake 2004)©2004 ACM:(a)是指分割边界周围区域,其中像素具有混合的前景和背景颜色;(b)沿边界的像素值用于计算软透明度遮罩;(c)在曲线t的每一点上,估计出位移△和宽度σ。
图像抠像和合成是将前景物体从一张图片中分离出来并粘贴到新背景上的过程(Smith和Blinn 1996;Wang和Cohen 2009)。它常用于电视和电影制作中,将真人演员与计算机生成的图像如天气图或3D虚拟角色和场景叠加在一起(Wright 2006;Brinkmann 2008),并且最近已成为视频会议系统中的一个流行功能。
我们已经看到许多用于图像中对象交互分割的工具,包括蛇形工具(第7.3.1节)、剪刀工具(第7.3.1节)和GrabCut分割(第4.3.2节)。虽然这些技术可以生成合理的像素级分割结果,但它们无法捕捉到边界处混合像素中前景和背景颜色之间的微妙相互作用(Szeliski和Golland 1999)(Figure10.39a)。
为了成功地将前景对象从一张图像复制到另一张图像中,而不产生明显的离散化伪影,我们需要提取一个遮罩,即从输入的合成图像C中估计出一个软不透明度通道α和未受污染的前景颜色F。回顾第3.1.3节(图3.4),合成方程(3.8)可以表示为
C = (1 - α)B + αF. (10.29)
该运算符以因子(1 - α)减弱背景图像B的影响,然后添加与前景元素F对应的(部分)颜色值。
虽然合成操作很容易实现,但反向遮罩操作,即根据输入图像C估计F、α和B则更具挑战性(图10.40)。要了解原因,请观察到,虽然合成像素颜色C提供了三个测量值,

图10.40自然图像遮罩(Chuang,Curless等人,2001)©2001 IEEE:(a)输入图像具有“自然”(非恒定)背景;(b)手绘三色图——灰色表示
未知区域;(c)提取的alpha图;(d)提取的(预乘)前景颜色;(e)在新背景上合成。
F、α和B未知数共有7个自由度。设计技术来估计这些未知数,尽管问题的约束不足,这是图像抠图的本质。
在本节中,我们回顾了多种图像抠图技术。首先介绍蓝幕抠图,该方法假设背景是已知的固定颜色,并讨论其变体,包括双屏抠图(当可以使用多个背景时)和差异抠图(已知背景为任意)。接着,我们讨论自然图像抠图的局部变体,在这些应用中,前景和背景都是未知的。通常情况下,首先指定一个三色标签,即将图像分为前景、背景和未知区域(图10.40b)。接下来,我们介绍一些用于自然图像抠图的全局优化方法。最后,我们讨论抠图问题的其他变体,包括阴影抠图、闪光灯抠图和环境抠图。
蓝幕抠像技术涉及在恒定的彩色背景前拍摄演员(或物体)。虽然最初首选的颜色是亮蓝色,但现在更常用的是亮绿色(Wright2006;Brinkmann2008)。Smith和Blinn(1996)讨论了多种
蓝屏遮罩技术,大多在专利中描述,而不是公开的研究文献。早期的技术使用对象颜色通道的线性组合和用户调整的参数来估计不透明度α。
创、柯尔斯等人(2001)描述了一种称为三岛算法的新技术,该技术涉及拟合两个多面体表面(以平均背景颜色为中心),分离前景和背景颜色分布,然后测量新颜色与这些表面之间的相对距离来估计α(Figure10.41e)。尽管这项技术在许多工作室环境中表现良好,但仍可能受到蓝色溢出的影响,即物体边缘的半透明像素会获得一些背景的蓝色色调。
双屏幕遮罩。在他们的论文中,Smith和Blinn(1996)还介绍了一种称为三角化遮罩的算法,该算法使用多个已知背景颜色来过度约束用于估计不透明度α和前景颜色F的方程。
例如,考虑在合成方程(10.29)中将背景颜色设置为黑色,即B = 0。因此,合成图像C等于αF。如果将背景颜色替换为不同的已知非零值B,则结果如下
C - αF = (1 - α)B; (10.30)
这是一组用于估计α的(颜色)方程,但约束过多。实际上,B的选择不应使C饱和,为了达到最佳精度,应使用多个B值。此外,在处理前对颜色进行线性化也很重要,这是所有图像抠图算法的共同做法。生成用于评估的真实alpha遮罩的论文通常会使用这些技术来获得准确的遮罩估计(Chuang,Curless等,2001;Wang和Cohen,2007a;Levin,Acha和Lischinski,2008;Remann,Rother等,2008,2009).25练习10.8也要求你这样做。
差异抠像。当背景不规则但已知时,一种相关的方法称为差异抠像(Wright 2006;Brinkmann 2008)。这种方法最常用于演员或物体在静态背景前拍摄的情况,例如办公室视频会议、人物跟踪应用(Toyama,Krumm等1999),或用于生成体积3D重建技术所需的轮廓(第12.7.3节)(Szeliski 1993;Seitz和Dyer 1997;Seitz,Curless等2006)。它也可以用于带有摇摄镜头的情况,其中背景是从前景被移除的帧中合成的,使用垃圾抠像(第10.4.5节)(Chuang,Agarwala等2002)。另一个应用是检测视图-
25请访问http://alphamatting.com上的alpha matting评估网站。
影片中的视觉连续性错误,即在稍后重新拍摄镜头时背景的差异(Pickup和Zisserman2009)。
在前景和背景运动都可以通过参数变换来指定的情况下,可以使用三角定位的推广方法(Wexler,Fitzgibbon和Zisserman 2002)提取高质量的遮罩。然而,当帧需要独立处理时,结果往往质量较差(图10.42)。在这种情况下,使用一对立体相机作为输入可以显著提高结果的质量(Criminisi,Cross等2006;Yin,Criminisi等2007)。
图像抠图最通用的版本是,在对背景一无所知的情况下,仅通过场景的粗略分割来区分前景、背景和未知区域,这被称为三色图(Figure10.40b)。然而,一些技术放宽了这一要求,允许用户在图像中画几笔或涂鸦:参见图10.45和10.46(王和科恩2005;王、阿格拉瓦拉和科恩2007;莱文、利辛斯基和韦斯2008;雷曼、罗瑟等人2008;雷曼、罗瑟和盖劳茨2008)。全自动单图像抠图的结果也已报道(莱文、阿查和利辛斯基2008;辛加拉朱、罗瑟和雷曼2009)。王和科恩(2009)的综述文章详细描述并比较了所有这些技术,下面简要介绍其中的一些,而网站http://alphamatting.com则提供了最新算法的最新列表和数值比较。
一种相对简单的自然图像抠图算法是Knockout,如Chuang、Curless等人(2001)所描述,并在图10.41f中展示。该算法首先确定最近的已知前景和背景像素(在图像空间中),然后与邻近的已知像素混合,以生成每个像素的前景F和背景B颜色估计值。接着调整背景颜色,使测量的颜色C位于F和B之间的直线上。最后,按通道估计不透明度α,并根据各通道的颜色差异将三个估计值结合在一起。(这是对α的最小二乘解的一种近似。)图10.42显示,当背景包含多个主导局部颜色时,Knockout存在问题。
如果我们把前景和背景颜色视为在某个区域内采样的分布(图10.41g-h),可以获得更准确的遮罩效果。Ruzon和Tomasi(2000)将局部颜色分布建模为(不相关的)高斯混合,并在条带中计算这些模型。然后,他们找到最能描述观察到的颜色C的混合成分F和B的配对,计算α作为这些均值之间的相对距离,并调整F和B的估计值,使其与C共线。
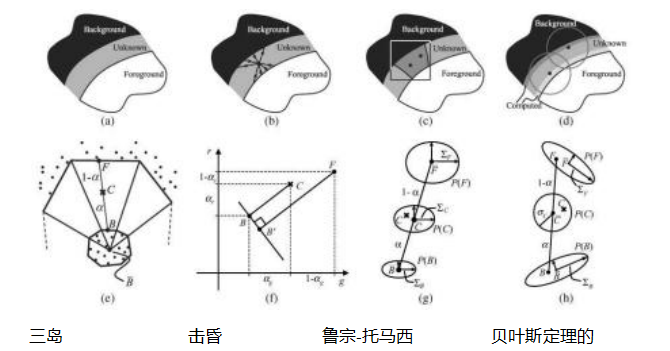
图10.41图像抠图算法(Chuang,Curless等,2001)©2001 IEEE。Mishima的算法将全局前景和背景颜色分布建模为以平均背景色(蓝色)为中心的多面体表面。Knockout使用每个像素的局部前景和背景颜色估计,并沿每个颜色轴计算Q。Ruzon和Tomasi的算法局部建模前景和背景的颜色及其变化。Chuang等人的贝叶斯抠图方法根据局部前景和背景分布计算(部分)前景颜色和不透明度的最大后验概率估计。
创、柯尔斯等人(2001)和希尔曼、汉娜、伦肖(2001)使用完整的3×3颜色协方差矩阵来建模相关高斯混合,并独立计算每个像素的估计值。马特提取以已知颜色值为起点,逐步扩展到未知区域,以便最近计算出的F和B颜色可以在后续阶段使用。
估计未知像素的不透明度和(未混合)前景的最可能值
在背景颜色方面,Chuang等人使用了最大化全贝叶斯公式
P (F, B, Q jC) = P (CjF, B, Q)P (F)P (B)P (Q)/P (C). (10.31)
这相当于最小化负对数似然
L (F, B, Q jC) = L (CjF, B, Q) + L (F) + L (B) + L (Q) (10.32)
(去掉L(C)项,因为它为常数)。
让我们依次检查这些术语。第一个是L(CjF,B,Q),即在未知值(F,B,Q)给定的情况下观察到像素颜色C的可能性。如果我们假设高斯分布

图10.42自然图像抠图结果(Chuang,Curless等人,2001)©2001 IEEE。差异抠图和遮罩效果在这类背景上表现不佳,而较新的自然图像抠图技术则表现出色。Chuang等人的结果略显平滑,更接近真实情况。
在我们的观测中存在方差σ的噪声,这个负对数似然(数据项)是
L(C) = 1/2ⅡC - [αF + (1 - α)B]Ⅱ2 /σ , (10.33)
如图10.41h所示。
第二项,L(F),对应于特定前景颜色F来自高斯混合模型的可能性。在将样本前景颜色聚类后,计算加权均值F和协方差ΣF,其中权重与给定前景像素的不透明度和与未知像素的距离成正比。因此,每个聚类的负对数似然值为
L(F) =
(F - F)T ΣF-1 (F - F). (10.34)
使用类似的方法来估计未知的背景颜色分布。如果背景已经已知,即对于蓝屏或差异遮罩应用,那么使用其测量的颜色值和方差代替。
除了将前景和背景颜色分布建模为高斯混合外,还可以保留原始颜色样本并计算最可能的配对来解释观察到的颜色C (Wang和Cohen2005,2007a)。这些技术在(Wang和Cohen2009)中进行了更详细的描述。
在他们的贝叶斯抠图论文中,Chuang、Curless等人(2001)假设L(α)的分布是恒定的(非信息性的)。后续的研究则假设该分布更集中在0和1附近,有时使用马尔可夫随机场(MRF)来定义P (α)的整体相关先验(Wang和Cohen 2009)。
为了计算最可能的估计值(F,B,α),贝叶斯抠图算法在计算(F,B)和α之间交替进行,因为这些问题都是二次方程,因此可以作为小型线性系统求解。当估计多个颜色簇时,使用前景和背景颜色簇的最可能配对。
贝叶斯图像抠图产生的结果比Ruzon和Tomasi(2000)的原始自然图像抠图算法有所改进,如Figure10.42所示。然而,与后来的技术(Wang和Cohen2009)相比,其在复杂背景或不准确的三色图上的表现并不好(图10.44)。
估计每个像素的不透明度和前景颜色的独立方法的替代方法是使用全局优化来计算一个考虑了邻近像素之间的相关性的遮罩。
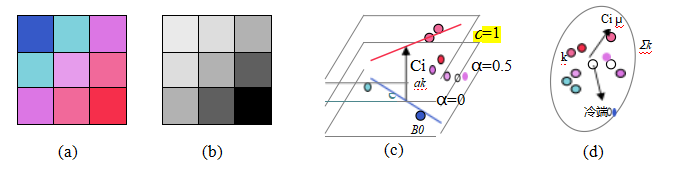
图10.43颜色线遮罩(Levin,Lischinski和Weiss 2008):(a)局部3×3颜色块;(b)潜在的Q值分配;(c)前景和背景颜色线,连接它们最近交点的向量ak,以及恒定Q值的平行平面族,Qi = ak·(Ci - B0);(d)两个样本颜色Ci和Cj的散点图及其与平均值μk的偏差。
无聊的Q值。两个例子是GrabCut交互式分割系统(Rother、Kolmogorov和Blake2004)中的边界遮罩和Poisson遮罩(Sun、Jia等人2004)。
边界垫片首先扩展由Grab-Cut(第4.3.2节)生成的二值分割区域,然后为边界上的每个点求解亚像素边界位置△和模糊宽度σ(图10.39)。通过正则化强制这些参数沿边界平滑,并使用动态规划进行优化。虽然这种方法可以为平滑的边界,如人脸,获得良好的结果,但在处理精细细节时,如头发,则存在困难。
Poisson matting (Sun,Jia等,2004)假设每个像素在三值图中具有已知的前景和背景颜色(与贝叶斯matting相同)。然而,它不是独立估计每个Q值,而是假设alpha遮罩的梯度与彩色图像的梯度之间存在关联。
· ▽C; (10.35)
可以通过对式(10.29)两边求梯度并假设前景和背景变化缓慢来推导。然后,使用第4.2节(4.24)首次描述的正则化(最小二乘法)技术,将每个像素的梯度估计值整合到一个连续的Q(x)场中,该技术随后在泊松混合(第8.4.4节,公式(8.75))和基于梯度的动态范围压缩映射(第10.2.1节,公式(10.18))中得到应用。当有良好的前景和背景颜色估计且这些颜色变化缓慢时,该技术效果良好。
莱文、利辛斯基和韦斯(2008)假设这些颜色分布可以局部近似为两种颜色的混合,这被称为颜色线模型(Figure10.43a-c)。在此假设下,对于窗口Wk中的每个像素i(例如,3×3),α的闭式估计值由下式给出:
αi = ak · (Ci — B0) = ak · C + bk , (10.36)
其中,Ci是被视为三向量的像素颜色,B0是背景色线上的任意像素,ak是连接前景和背景色线上最近两点的向量,如图10.43c所示。(请注意,图中所示的几何推导是Levin、Lischinski和Weiss(2008)提出的代数推导的替代方案。)最小化图像中所有重叠窗口Wk上的α值αi与其各自颜色线模型(10.36)之间的偏差,从而产生成本函数。
(10.37)
其中∈项用于在两种颜色分布重叠的情况下(即在常数α区域)对ak的值进行正则化。
因为这个公式是未知数{(ak,bk)}的二次方,所以它们可以在每个窗口Wk内被消除,从而得到最终的能量
Eα = αTLα, (10.38)
L矩阵中的条目由下式给出
其中,M = jWkj是每个(重叠的)窗口中的像素数,μk是窗口Wk中像素的平均颜色,k是像素颜色的3×3协方差加上∈/MI。
图10.43d展示了这个亲和矩阵背后的直觉,该矩阵被称为遮罩拉普拉斯矩阵。请注意,当Wk中的两个像素Ci和Cj指向远离均值μk的相反方向时,它们的加权点积接近—1,因此它们的亲和力接近0。颜色空间中相近的像素(因此具有相似的预期α值)将具有接近—2/M的亲和力。
最小化受已知值α = {0,1}限制的二次能量(10.38)仅需求解一组稀疏线性方程,因此作者称其技术为自然图像抠图的闭式解。一旦α已知,

图10.44中等精度trimap的比较着色结果。Wang和Co- hen(2009)描述了所比较的各个技术。

图10.45基于涂鸦输入的对比着色结果。Wang和Cohen
(2009)描述了正在比较的各个技术。
计算后,使用最小二乘法最小化合成方程(10.29),并用空间变化的一阶平滑度进行正则化来估计前景和背景颜色,
其中,j▽αij权重分别应用于F和B导数的x和y分量(Levin,Lischinski和Weiss2008)。
拉普拉斯(闭式)遮罩只是Wang和Cohen(2009)所审查和比较的众多基于优化的技术之一。其中一些技术使用α遮罩上的亲和力或平滑度项的替代公式,以及替代估计

图10.46基于血流的分割结果(Rhemann,Rother et al. 2008)©2008
电器和电子工程师学会
诸如信念传播等技术,或用于建模局部前景和背景颜色分布的替代表示(例如,局部直方图)(王和科恩2005,2007a,b)。这些技术中的一些还能够在用户绘制轮廓线或稀疏的涂鸦集时提供实时结果(王、阿格拉瓦拉和科恩2007;雷曼、罗瑟等人2008),甚至可以预先将图像分割成少量的区域,用户可以通过简单的点击选择(莱文、阿查和利辛斯基2008)。
图10.44展示了在指定了一个三值图的玩具动物毛皮区域上运行多个调查算法的结果,而图10.45则显示了仅需少量涂鸦作为输入即可生成哑光效果的技术的结果。图10.46展示了一种更为近期的算法(Rhemann,Rother等,2008)的结果,该算法声称优于王和科恩(2009)调查的所有技术。
最新的自然图像遮罩结果可以在Remann、Rother等人(2009)创建的http://alphamatting.com网站上找到。该网站目前列出了超过60种不同的算法,其中大多数较新的算法使用了深度神经网络。Xu、Price等人(2017)的《深度图像遮罩》论文提供了一个更大的数据库,包含49,300张训练图像和1,000张测试图像,这些图像是通过在各种背景上叠加手动创建的颜色前景遮罩构建的。27
粘贴。一旦从图像中提取出一个哑光,通常会直接将其合成到新背景上,除非需要隐藏抠图区域与背景区域之间的接缝,在这种情况下可以使用泊松混合(P rez、Gangnet和Blake2003)(第8.4.4节)。
在后一种情况下,如果哑光边界通过的区域在旧图像和新图像中纹理很少或看起来相似,则是有帮助的。Jia、Sun等人(2006)的论文

图10.47烟雾垫(Chuang,Agarwala等人,2002)©2002 ACM:(a)输入视频
框架;(b)移除前景对象后;(c)估计的透明度;(d)将新对象插入背景。
除了用分数边界遮罩实物体之外,还可以遮罩半透明介质,如烟雾(Chuang,Agarwala等,2002)。从视频序列开始,每个像素被建模为其(未知的)背景颜色和所有像素共有的恒定前景(烟雾)颜色的线性组合。通过颜色空间投票来估计这种前景颜色,并沿每条颜色线的距离用于估计每个像素的时间变化透明度(图10.47)。
提取并重新插入阴影也是可能的,这需要使用一种相关技术(Chuang,Goldman等2003;Wang,Curless和Seitz 2020)。这里,不是假设前景颜色是恒定的,而是假设每个像素在其完全光照和完全阴影的颜色之间变化,这些颜色可以通过在阴影经过场景时(练习10.9)取(稳健的)最小值和最大值来估计。由此产生的部分阴影遮罩可以用于将阴影重新投影到新场景中。如果目标场景具有非平面几何结构,可以通过挥动一根直棍的阴影扫描整个场景。然后,新的阴影遮罩可以根据计算出的变形场进行扭曲,使其正确地覆盖在新场景上(图10.48)。还可以通过扩展视频对象分割算法(第9.4.3节)来从视频流中提取阴影和其他效果,如烟雾(Lu,Cole等2021)。照片中有用的阴影处理示例包括去除或柔化人物肖像中的强烈阴影(Sun,Barron等2019;Zhou,Hadap等2019;Zhang,Barron等2020),这一功能可在Google Photos中作为“肖像光”功能提供。28
使用更复杂的采集系统也可以提高马特算法的质量和可靠性。例如,拍摄闪光灯和非闪光灯图像对支持
可靠地提取前景遮罩,这些遮罩显示为大光照区域

图10.48阴影遮罩(Chuang,Goldman等人,2003)©2003 ACM。阴影遮罩不是简单地用阴影(c)使新场景变暗,而是正确地用新阴影使已照明的场景变暗,并将阴影覆盖在3D几何体(d).上。
两种图像之间的转换(Sun,Li等人,2006)。同时聚焦于不同距离的视频流(McGuire,Matusik等人,2005)或使用多摄像头阵列(Joshi,Matusik和Avidan,2006)也是生成高质量母版的好方法。这些技术在(Wang和Cohen,2009)中有更详细的描述。
最后,拍摄一个折射物体在多个图案背景前,可以将该物体置于新颖的三维环境中。这些环境遮罩技术(Zongker,Werner等人,1999;Chuang,Zongker等人,2000)将在第14.4节中讨论。
虽然可以将常规单帧遮罩技术,如蓝幕或绿幕遮罩(Smith和Blinn1996;Wright2006;Brinkmann2008)应用于视频序列,但移动物体的存在有时会使遮罩过程变得更容易,因为背景的某些部分可能在前一帧或后一帧中被揭示出来。
创、阿加瓦拉等人(2002)提出了一种处理视频抠像问题的巧妙方法,首先使用保守的垃圾遮罩去除前景物体,然后对剩余的背景图进行对齐和合成,以获得高质量的背景估计。他们还描述了如何利用稀疏关键帧绘制的三张图通过双向光流插值到中间帧。关于视频抠像的其他方法,如旋转描边法,即在视频序列的关键帧中绘制曲线或线条(阿加瓦拉、赫茨曼等人,2004;王、巴特等人,2005),在王和科恩(2009)的抠像综述论文中有所讨论。此外,还有由埃罗费耶夫、吉特曼等人(2015)创建的一个精心抠像的定格动画视频的新数据集。
自从视频遮罩技术最初开发以来,改进的算法已经出现
已经开发了交互式和全自动视频对象分割,如dis-

图10.49纹理合成:(a)给定一小块纹理,任务是合成一个看起来相似的较大块;(c)其他半结构化的纹理,这些纹理很难合成。(图片由Alyosha Efros提供。)
在第9.4.3节中讨论。Sengupta、Jayaram等人(2020)的论文使用深度学习和对抗损失,以及运动先验,从小动作手持视频中提供高质量的抠图,同时捕捉到背景中的干净画面。Wang、Curless和Seitz(2020)描述了一个系统,通过观察场景中的人行走来确定阴影和遮挡,从而能够在正确的时间尺度和光照条件下插入新人。后续工作中,Lin、Ryabtsev等人(2021)描述了一种高分辨率实时视频抠图系统,并提供了两个新的视频和图像抠图数据集。最后,Lu、Cole等人(2021)描述了如何提取视频中被跟踪和分割对象相关的阴影、反射和其他效果。
虽然纹理分析和合成乍看之下似乎不是计算摄影技术,但事实上,它们被广泛用于修复图像中的缺陷,如小洞,或从普通照片中创建非逼真的绘画渲染。
纹理合成问题可以表述如下:给定一个小样本
“纹理”(图10.49a)生成一个更大的相似图像(图10.49b)。可以想象,对于某些样本纹理,这个问题可能相当具有挑战性。
传统的纹理分析和合成方法试图匹配光谱
在生成形状噪声时,匹配频率特性本身并不充分,这相当于匹配空间相关性。不同频率下的响应分布也必须匹配。Heeger和Bergen(1995)开发了一种算法,在多尺度(可转向金字塔)响应直方图和最终图像直方图之间交替匹配。Portilla和Simoncelli(2000)改进了这一技术,通过在尺度和方向上进行成对统计匹配。De Bonet(1997)采用从粗到细的策略,寻找源纹理中具有相似父结构的位置,即类似的多尺度定向滤波器响应,然后随机选择其中一个匹配位置作为当前样本值。Gatys、Ecker和Bethge(2015)也使用了金字塔式的精细到粗再到精细的算法,但使用了为对象识别训练的深度网络。在深度网络的每一层,他们收集各种特征之间的相关统计信息。在生成过程中,他们迭代更新随机图像,直到这些更符合感知的统计量(Zhang,Isola等,2018)得到匹配。我们将在Section10.5.3上关于神经风格转换的神经纹理合成的其他神经方法,如Shaham、Dekel和Michaeli(2019),提供更多细节。
基于范例的纹理合成算法通过寻找与当前合成图像相似的源纹理邻域来依次生成纹理像素(Efros和Leung 1999)。考虑图10.50左侧部分构建的纹理上的未知像素pin。由于其一些相邻像素已经合成,我们可以在右侧的样本纹理图像中寻找类似的局部邻域,并随机选择其中一个作为新的p值。此过程可以沿着新图像重复进行,无论是以光栅方式还是在填充孔洞时绕着边缘扫描(“洋葱剥皮”),如第10.5.1节所述。在实际实现中,Efros和Leung(1999)找到最相似的邻域,然后包括所有距离在d=(1+∈)范围内的其他邻域,其中∈= 0.1。他们还可选地根据相似度度量d来加权随机像素选择。
为了加快这一过程并提高其视觉质量,Wei和Levoy(2000)扩展了该技术,采用了一种从粗到精的生成过程,在匹配过程中还会考虑金字塔中已经合成的较粗层次(De Bonet 1997)。为了加速最近邻查找,使用了树状向量量化。一种更快的最近邻搜索版本是广泛使用的随机补丁匹配迭代更新算法,由Barnes、Shechtman等人(2009)开发。
Efros和Freeman(2001)提出了一种替代的加速和视觉质量提升技术。他们没有一次合成一个像素,而是根据与先前合成区域的相似性选择重叠的方形块(图10.51)。一旦选择了合适的块,新重叠块之间的接缝就会被确定。

图10.50使用非参数采样进行纹理合成(Efros和Leung1999)。最新像素p的值是从源纹理(输入图像)中相似的局部(部分)区域中随机选择的。(图由Alyosha Efros提供。)
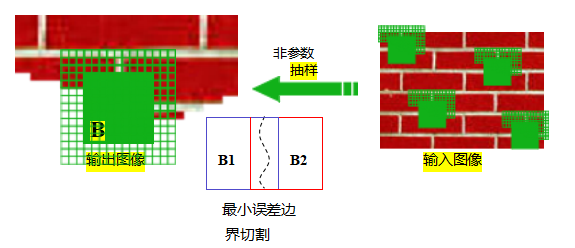
图10.51图像拼接的纹理合成(Efros和Freeman2001)。与一次生成一个像素不同,从源纹理中复制较大的块。然后使用动态编程优化所选块之间重叠区域的过渡。(图由Alyosha Efros提供。)
使用动态规划。(无需进行完整的图割缝选择,因为垂直边界只需要每行一个缝的位置。)由于这一过程涉及选择小块并将其拼接在一起,Efros和Freeman(2001)将其系统称为图像绗缝。Komodakis和Tziritas(2007)提出了一种基于MRF的块合成算法版本,该算法使用他们称为“优先BP”的新高效循环信念传播方法。Wei、Lefebvre等人(2009)对2009年之前的基于示例的纹理合成工作进行了全面综述。
填补从照片中切除物体或缺陷后留下的孔洞,即所谓的修复,是纹理合成最常见的应用之一。

图10.52图像修复(孔洞填充):(a-b)沿等光度方向传播(Bertalmio,Sapiro等人,2000年)©2000 ACM;(c-d)基于示例的修复,采用基于置信度的填充顺序(Criminisi,P rez和Toyama,2004年)。
技术不仅用于从照片中移除不想要的人或入侵者(King1997),还用于修复旧照片和电影中的小缺陷(如去除划痕)或移除拍摄过程中悬挂在空中的道具或演员的钢丝(如去除钢丝)。Bertalmio、Sapiro等人(2000)通过沿等光度(恒定值)方向传播像素值并穿插一些各向异性扩散步骤来解决问题(图10.52a-b)。Telea(2004)开发了一种更快的技术,利用了来自水平集的快速行进方法(第7.3.2节)。然而,这些技术不会在缺失区域中产生纹理幻觉。Bertalmio、Vese等人(2003)通过向填充区域添加合成纹理来增强他们早期的技术。
前一节讨论的基于示例(非参数)纹理生成技术也可以通过从外部向内填充孔洞(“洋葱皮”顺序)来使用。然而,这种方法可能无法传播强烈的定向结构。克里米尼西、普雷兹和富山(2004)采用基于示例的纹理合成方法,其中合成的顺序由区域边界上的梯度强度
决定(图10.1d和10.52c-d)。孙、袁等人(2004)提出了一种相关的方法,用户可以绘制交互式线条以指示应优先传播的结构位置。与这些方法相关的其他技术包括多里、科恩-奥尔和耶舒伦(2003)、夸特拉、施德尔等人(2003)、夸特拉、埃萨等人(2005)、威尔奇科维亚克、布罗斯托等人(2005)、科莫达基斯和齐里塔斯(2007)以及韦克斯勒、谢赫特曼和伊拉尼(2007)所开发的技术。
大多数孔洞填充算法借用原始图像的小片段来填补孔洞。当有大量源图像数据库可用时,例如从照片分享网站或互联网获取的图像,有时可以复制一个连续的图像区域来填补孔洞。Hays和Efros(2007)提出了一种这样的技术,该技术利用图像上下文和边界兼容性选择源图像,然后使用图割和泊松混合方法将其与原始(有孔洞的)图像融合。这一技术被讨论如下:
与其他图像处理领域一样,深度神经网络被应用于所有最新的技术中(杨、陆等,2017;余、林等,2018;刘、雷达等,2018;曾、付等,2019;余、林等,2019;张、刘等,2019;纳泽里、吴等,2019;任、余等,2019;施、苏等,2020;易、唐等,2020)。其中一些论文介绍了神经网络架构的一些有趣的新扩展,如部分卷积(刘、雷达等,2018)和部分卷积(余、林等,2019),边缘结构的传播(纳泽里、吴等,2019;任、余等,2019),多分辨率注意力机制和残差(易、唐等,2020),以及迭代置信反馈(曾、林等,2020)。图像修复也被应用于视频序列(例如,高、萨拉夫等,2020)。关于图像修复最近挑战的结果可以在AIM 2020研讨会和挑战中找到(恩塔维利斯、罗梅罗等,2020a)。
基于示例的纹理合成思想还有两个应用,即纹理转移(Efros和Freeman2001)和图像类比(Hertzmann、Jacobs等人2001),它们都是非照相真实渲染的例子(Gooch和Gooch2001)。
除了使用源纹理图像外,纹理传递还采用参考(或目标)图像,并尝试将目标图像的某些特征与新合成的图像相匹配。例如,图10.53c中渲染的新图像不仅试图满足与图10.53b中的源纹理通常相似性的约束,还尝试匹配参考图像的亮度特性。Efros和Freeman(2001)提到,模糊图像强度或局部图像方向角是可替代的匹配量。
Hertzmann、Jacobs等人(2001年)提出了以下问题:
给定一对图像A和A(分别为未过滤的源图像和已过滤的源图像),以及一些额外的未过滤的目标图像B,合成一个新的已过滤的目标图像B,使得
A : A, :: B : B,.
用户无需对非真实感渲染效果进行编程,只需向系统提供前后图像示例,然后让系统使用基于示例的合成来合成新图像,如图10.54所示。
用于解决图像类比的算法以类似于Efros和Leung(1999)以及Wei和Levoy(2000)的纹理合成算法的方式进行。一旦Gaus-
图10.53纹理转移(Efros和Freeman2001)©2001 ACM:(a)参考(目标)图像;(b)源纹理;(c)使用纹理(部分)渲染的图像。

图10.54图像类比(Hertzmann,Jacobs等人,2001年)©2001 ACM。给定源图像A及其渲染(过滤)版本A的一对示例,从另一个未过滤的源图像B生成渲染版本B。
对于所有源图像和参考图像的金字塔,算法会在A生成的源过滤金字塔中寻找与B中部分构建的邻域相似的区域,同时这些区域在A和B的相应位置具有类似的多分辨率外观。与纹理传递类似,外观特征不仅包括(模糊)颜色或亮度值,还包括方向。
这一通用框架允许图像类比应用于各种渲染任务。除了基于示例的非真实感渲染外,图像类比还可用于传统的纹理合成、超分辨率和纹理迁移(使用同一张纹理图像作为A和A)。如果只有经过滤波(渲染)的图像A可用,如绘画的情况,缺失的参考图像A可以通过智能(边缘保持)模糊操作来“幻觉”生成。最后,可以训练系统通过手动用伪颜色覆盖自然图像来执行“数字纹理”,这些伪颜色对应于像素的语义含义,例如水、树和草(图10.55a-b)。最终得到的系统

图10.55图像纹理与数字(Hertzmann,Jacobs等人,2001)©2001 ACM。给定一个纹理图像A和一个手工标记的(绘制的)版本A,仅根据绘制的版本B合成一个新的图像B。
然后可以将一个简略的草图转换为完全渲染的合成照片(图10.55c-d)。在最近的研究中,程、维什瓦纳坦和张(2008)将图像拼接(埃夫罗斯和弗里曼2001)和MRF推理(科莫达基斯、齐里塔斯和帕拉吉奥斯2008)的思想加入到基本的图像类比算法中,而拉马纳拉亚南和巴拉(2007)则将这一过程重新表述为能量最小化,这意味着它可以被视为条件随机场(第4.3.1节),并设计了一种高效的算法来找到一个好的最小值。
传统的滤波和特征检测技术也可用于非真实感渲染。例如,钢笔画(温肯巴赫和塞利辛1994)和绘画渲染技术(利特维诺维奇1997)使用局部颜色、强度和方向估计作为其程序化渲染算法的输入。风格化和简化照片及视频的技术(德卡洛和桑特拉2002;温内勒、奥尔森和古奇2006;法布曼、法塔尔等人2008),如Figure10.56中所述,结合了边缘保持模糊(第3.3.1节)和边缘检测与增强(第7.2.3节)。
随着深度学习的兴起,基于图像引导示例的纹理合成大多已被深度网络中的统计匹配所取代(Gatys,Ecker,和Bethge 2015)。图10.57展示了神经风格迁移网络的基本思想。在Gatys、Ecker和Bethge(2016)的原始工作中,风格图像ys和内容图像yc(见图10.58以获取示例)被输入到一个损失网络中,该网络比较从风格和目标图像中提取的特征与从正在生成的图像中提取的特征。这些损失通常包括感知损失。这些损失的梯度用于迭代地调整生成的图像,这使得这一过程
30有关论文的精选,请参见非真实感动画和渲染研讨会(NPAR)。

图10.56非照相抽象照片:(a) (DeCarlo和Santella
2002)©2002 ACM和(b) (Farbman,Fattal等人,2008)©2008 ACM。
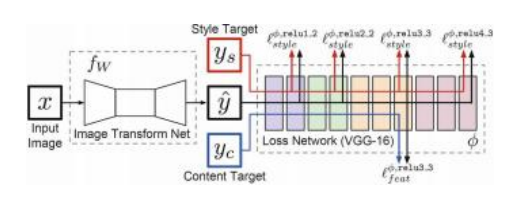
图10.57神经风格迁移的网络架构,该架构学习将图像转换为特定风格(Johnson,Alahi,和Fei-Fei 2016)©2016斯普林格。在训练过程中,内容目标图像yc被输入到图像变换网络作为输入x,同时输入风格图像ys,网络权重会更新以最小化感知损失,即风格重建损失lstyle和特征重建损失lfeat。早期由Gatys、Ecker和Bethge(2015)提出的网络没有图像
转换网络,而不是利用损失来优化转换后的图像。
为了加速这一过程,约翰逊、阿拉希和费-菲(2016)训练了一个前馈图像变换网络,该网络使用固定风格的图像和多个不同的内容目标,调整网络权重,使得由目标yc生成的风格化图像符合所需的统计特性。当新的图像x需要进行风格化时,只需将其通过图像变换网络即可。图10.58a展示了Gatys、埃克尔和贝特格(2016)与约翰逊、阿拉希和费-菲(2016)之间的一些比较。
感知损失现在已成为图像合成系统(Doso- vitskiy和Brox 2016)的标准组件,通常作为生成对抗损失的附加组件(第5.5.4节)。它们有时也被用作替代旧的图像质量指标,如SSIM (Zhang、Isola等2018;Talebi和Milanfar 2018;Tariq、Tursun等2020;Czolbe、Krause等2020)。
约翰逊、阿拉希和费-菲(2016)的基本架构由乌里亚诺夫、韦达利和莱姆皮茨基(2017)扩展,他们发现使用实例归一化而非批量归一化显著提升了结果。杜穆林、什伦斯和库德勒(2017)以及黄和贝隆吉(2017)进一步扩展了这些想法,通过条件实例归一化和自适应实例归一化来训练一个网络以模仿不同的风格,如图10.58b所示。
神经风格迁移仍然是一个活跃的研究领域,相关方法致力于更广泛的图像到图像转换(Isola,Zhu等,2017)和语义照片生成(Chen和Koltun,2017;Park,Liu等,2019;Bau,Strobelt等,2019;Ntavelis,Romero等,2020b)应用——详见Tewari,Fried等(2020,第6.1节)的最新综述。大多数较新的架构使用生成对抗网络(GANs)(Kotovenko,Sanakoyeu等,2019;Shaham,Dekel和Michaeli,2019;Yang,Wang等,2019;Svoboda,Anoosheh等,2020;Wang,Li等,2020;Xia,Zhang等,2020;H rk nen,Hertzmann等,2020),我们在Section5.5.4中讨论过。此外,最近还有一门关于基于学习的图像合成更广泛
主题的课程(Zhu,2021)。
关于计算摄影第一个十年的优秀综述可以在Raskar和Tumblin(2010)的书中找到,以及Nayar(2006)、Cohen和Szeliski(2006)、Levoy(2006)、Debevec(2006)和Hayes(2008)的调查文章中。此外,还有Bimber(2006)和Durand与Szeliski(2007)编辑的两期特刊。本章开头提到的计算摄影课程笔记也是了解这一领域的另一重要来源。

图10.58两个神经风格迁移的例子:(a)约翰逊、阿拉希和费-菲(2016)的预训练网络©2016斯普林格(标记为“我们的”)与(加蒂斯、埃克尔和贝特格2016)(标记为“[11]”);(b)一个使用条件实例归一化的网络,用于模仿不同风格(上排)应用于各种内容(左列)©(杜穆林、什伦斯和库德勒2017)。
最近的材料和参考文献。31
高动态范围成像的子领域有专门讨论该领域研究的书籍(Reinhard,Heidrich等,2010),以及一些描述相关摄影技术的书籍(Freeman,2008;Gulbins和Gulbins,2009)。校准相机射电响应函数的算法可以在Mann和Picard(1995)、Debevec和Malik(1997)以及Mitsunaga和Nayar(1999)的文章中找到。
色调映射的主题在(Reinhard,Heidrich等人,2010)中得到了广泛讨论。关于这一主题的大量文献中,具有代表性的论文包括(Tumblin和Rushmeier,1993;Larson,Rushmeier和Piatko,1997;Pattanaik,Ferwerda等人,1998;Tum-blin和Turk,1999;Durand和Dorsey,2002;Fattal,Lischinski和Werman,2002;Reinhard,Stark等人,2002;Lischinski,Farbman等人,2006;Farbman,Fattal等人,2008;Paris,Hasinoff和Kautz,2011;Aubry,Paris等人,2014)。
关于超分辨率的文献相当丰富(Chaudhuri2001;Park,Park和Kang2003;Capel和Zisserman 2003;Capel 2004;van Ouwerkerk2006)。超分辨率通常指通过对多张图像进行配准和合并,以生成更高分辨率合成图像的技术(Keren,Peleg和Brada1988;Irani和Peleg1991;Cheese-man,Kanefsky等1993;Mann和Picard1994;Chiang和Boult1996;Bascle,Blake和Zisserman1996;Capel和Zisserman1998;Smelyanskiy,Cheese-man等2000;Capel和Zisserman2000;Pickup,Capel等2009;Gulbins和Gulbins2009;Hasinoff,Sharlet等2016;Wronski,Garcia-Dorado等2019)。然而,单图像超分辨率技术也已开发(Freeman,Jones和Pasztor2002;Baker和Kanade 2002;Fattal2007;Dong,Loy等2016;Cai,Gu等2019;Anwar,Khan和Barnes 2020)。这些技术与去噪(Zhang,Zuo等2017;Brown 2019;Liba,Murthy等2019;Gu和Timofte2019)、去模糊和盲图像反卷积(Campisi和Egiazarian2017;Zhang,Dai等2019;Kupyn,Martyniuk等2019)以及去马赛克(Chatterjee,Joshi等2011;Gharbi,Chaurasia等2016;Abdelhamed,Afifi等2020)密切相关。
王和科恩(2009)对图像抠图进行了很好的综述。代表性论文包括与先前工作的广泛比较,如(Chuang,Curless等2001;Wang和Cohen 2007a;Levin,Acha和Lischinski 2008;Rhemann,Rother等2008,2009;Xu,Price等2017)。您可以在Rhemann,Rother等(2009)创建的http://alphamatting.comwebsite上找到最近的论文和结果的链接。抠图理念
也可用于操纵阴影(Chuang,Goldman等人,2003;Sun,Barron等人。
31 CMU 15-463,http://graphics.cs.cmu.edu/courses/15-463/2008秋季,伯克利CS194-26/294-26,https:// inst.eecs.berkeley.edu/~ cs194-26/fa20,MIT 6.815/6.865,https://stellar.mit.edu/S/course/6/sp08/6.815/materials. html,斯坦福CS 448A,https://graphics.stanford.edu/courses/cs448a-08-spring,CMU 16-726,https:// learning-image-synthesis.github.io,以及SIGGRAPH课程,https://web.media.mit.edu/~raskar/photo。
2019;Zhou,Hadap等人2019;Zhang,Barron等人2020;Wang,Curless和Seitz2020)和视频(Chuang,Agarwala等人2002;Wang,Bhat等人2005;Erofeev,Gitman等人2015;Sengupta,Jayaram等人2020;Lin,Ryabtsev等人2021)。
关于纹理合成和孔洞填充的文献包括传统的纹理合成方法,这些方法试图匹配源图像和目标图像之间的统计特性(Heeger和Bergen 1995;De Bonet 1997;Portilla和Simoncelli 2000),以及寻找源样本内部匹配邻域或块的方法(Efros和Leung 1999;Wei和Levoy 2000;Efros和Freeman 2001;Wei、Lefebvre等2009)或使用神经网络(Gatys、Ecker和Bethge 2015;Shaham、Dekel和Michaeli 2019)。类似地,传统的孔洞填充方法涉及解决局部变分(平滑延续)问题(Bertalmio、Sapiro等2000;Bertalmio、Vese等2003;Telea 2004)。下一波技术采用数据驱动的纹理合成方法(Drori、Cohen-Or和Yeshurun 2003;Kwatra、Sch dl等2003;Criminisi、P rez和Toyama 2004;Sun、Yuan等2004;Kwatra、Essa等2005;Wilczkowiak、Brostow等2005;Komodakis和Tziritas 2007;Wexler、Shechtman和Irani 2007)。最新的图
和视频修复算法使用深度
神经网络(Yang、Lu等2017;Yu、Lin等2018;Liu、Reda等2018;Shih、Su等2020;Yi、Tang等2020;Gao、Saraf等2020;Ntavelis、Romero等2020a)。除了生成孤立的纹理块或修复缺失区域外,相关技术还可以用于将图像或绘画的风格转移到另一张图像(Efros和Freeman2001;Hertzmann,Jacobs等人2001;Gatys,Ecker和Bethge2016;Johnson,Alahi和Fei-Fei2016;Dumoulin,Shlens和Kudlur2017;Huang和Belongie2017;Shaham,Dekel和Michaeli2019)。
例10.1:辐射校准。实现第10.2节中描述的多曝光辐射校准算法之一(Debevec和Malik 1997;Mitsunaga和Nayar 1999;Reinhard、Heidrich等人2010)。这种校准将在多种不同应用中发挥作用,例如拼接图像或使用不同曝光和阴影形状进行立体匹配。
1.使用三脚架拍摄一系列带有包围曝光的图像。如果你的相机有自动包围曝光(AEB)模式,拍摄三张照片可能就足以校准相机的大部分动态范围,特别是当场景中有很多明暗区域时。(在晴天户外或透过窗户拍摄效果最佳。)


















 3468
3468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









