







 本文详细介绍了高通的Data Free Quantization技术,包括Weight Equalization和Bias Correction两个关键步骤,旨在解决深度学习模型量化中精度下降的问题。通过对weight均衡化和bias校正,即使在没有数据的情况下,也能实现量化效果接近per-channel的per-layer量化。Weight Equalization通过调整卷积核的数值分布,使得不同卷积核间数值均衡,而Bias Correction则用于消除量化引起的数值偏移误差。实验表明,这两种方法在MobileNetV2上效果显著。
本文详细介绍了高通的Data Free Quantization技术,包括Weight Equalization和Bias Correction两个关键步骤,旨在解决深度学习模型量化中精度下降的问题。通过对weight均衡化和bias校正,即使在没有数据的情况下,也能实现量化效果接近per-channel的per-layer量化。Weight Equalization通过调整卷积核的数值分布,使得不同卷积核间数值均衡,而Bias Correction则用于消除量化引起的数值偏移误差。实验表明,这两种方法在MobileNetV2上效果显著。
(本文首发于公众号,没事来逛逛)
前面介绍了一些后训练量化的基本方法,从这篇文章开始我们来学习一些高阶操作。
首先登场的是高通提出的一篇论文:Data-Free Quantization Through Weight Equalization and Bias Correction。之所以介绍它是因为笔者在使用高通的模型量化工具 Snapdragon Neural Processing Engine (SNPE) 时感觉效果奇好,而 weight qualization 和 bias correction 就是该工具中提供的常用算法,应该说是比较成熟的量化技术了,况且算法本身也有很多巧妙之处,值得学习。
三个关键点
这篇论文发表于 2019 年的 ICCV 会议,但在此之前高通就已经将它落地到自己的工具中了,算是有一定知名度的论文。学习这篇论文只要把握住三个点就可以:Data-Free、Weight Equalization、Bias Correction (好的题目可以把握住读者的心)。
Data-Free Quantization
第一点 Data-Free,也是最不重要的一点,我觉得是高通搞出来的一点噱头。
高通在论文提出了模型量化算法的四重境界。
第一重,不需要数据,不需要重训练,不 care 模型结构,看一眼你的网络就可以自动帮你量化好。这一重即论文提到的 Data-Free。但这种一般只对 weight 量化起作用。高通说它的方法是 Data-Free 的,意思就是说它对 weight 的量化方法非常鲁棒,数据都不用就给你量化好了,效果还很好。当然对 feature 的量化还是得老老实实用数据来统计数值范围的。
第二重,需要数据,但不需要重训练,也不 care 模型结构。这种是目前大部分后训练量化追求的,用少量的数据达到最好的量化效果。这也是对 feature 进行量化的最低要求。但有些论文为了对 weight 做更好的量化,也会需要一点数据来辅助优化 (高通说:弟弟们,我不用,我 Data-Free)。
第三重,需要数据,也需要重训练,但不 care 模型结构。这种就是量化训练追求的最高境界了。
第四重,需要数据,也需要重训练,模型结构还不能乱来。这种指的是最 navie 的量化训练,一遇到特殊的结构或者压缩很厉害的模型就 gg 的那种。
Weight Equalization
weight equalization 是论文的关键点之一,这在另一篇论文 Same, Same But Different 1 ^1 1 中也有所提及。
weight equalization,顾名思义,就是对 weight 进行均衡化操作。为什么要有这个操作呢?因为高通研究人员在剖析 MobileNetV2 的时候发现,这个网络用 per-layer 量化精度下降极其严重,只有用上 per-channel 的时候才能挽救一下。具体实验数据出自 Google 的白皮书。我特意去翻了一下,发现还真是:
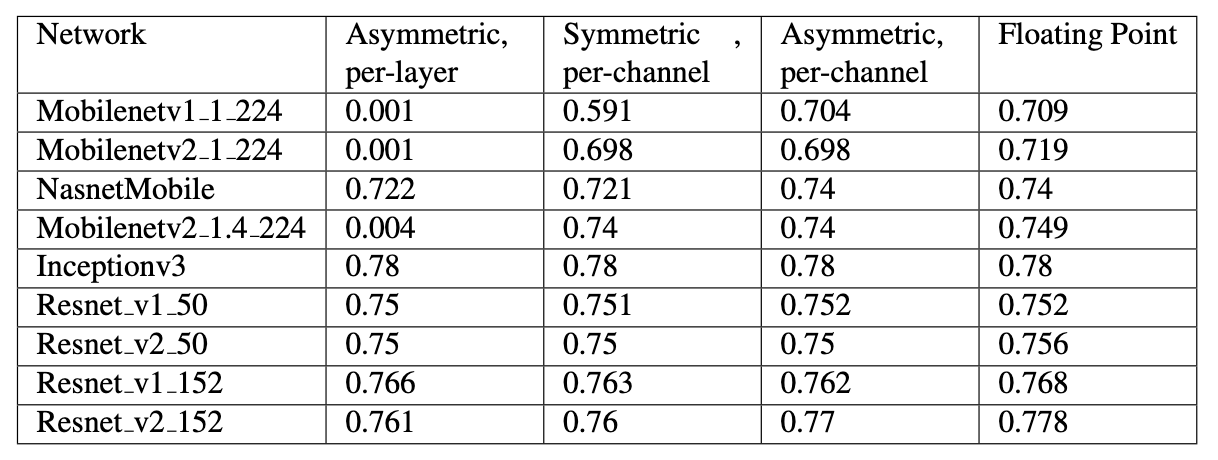 Mobilenet 类的网络在 per-layer 量化下,精度直接掉到 0.001 了,而同样作为小网络的 Nasnet 下降很小 (per-layer 精度一般是比 per-channel 低一些,但这么严重的精度下降,我怀疑是不是 Google 的程序员跑错代码了)。
Mobilenet 类的网络在 per-layer 量化下,精度直接掉到 0.001 了,而同样作为小网络的 Nasnet 下降很小 (per-layer 精度一般是比 per-channel 低一些,但这么严重的精度下降,我怀疑是不是 Google 的程序员跑错代码了)。
为什么会有这种情况呢?原因在于 MobileNetV2 中用了大量的可分离卷积 (depthwise conv),这个卷积的特殊之处是每个 output channel 都只由一个 conv kernel 计算得到,换句话说,不同 channel 之间的数值是相互独立的。研究人员调查了某一层可分离卷积的 weight 数值,发现不同的卷积核,其数值分布相差非常大:
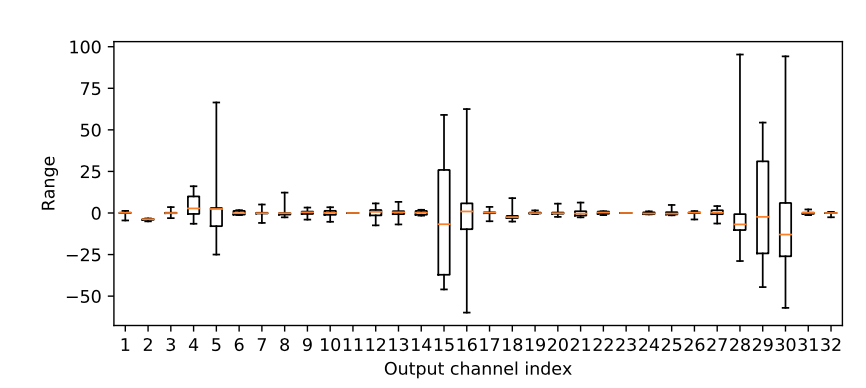
纵坐标是数值分布,横坐标表示不同的卷积核。你会发现,有些 weight 的数值分布在 0 附近,有些数值范围就非常大。在这种情况下,如果使用 per-layer 量化,那这些大范围的 weight 就会主导整体的数值分布,导致那些数值分布很小的 weight 在量化的时候直接压缩没了。这也是为什么 per-channel 对可分离卷积效果更好的原因。
而 weight equalization 要做的事情,就是在使用 per-layer 量化的情况下,使用一些方法使得不同卷积核之间的数值分布能够均衡一些,让大家的数值分布都尽量接近,这样就可以用 per-layer 量化实现 per-channel 的精度 (毕竟 per-channel 实现上会比 per-layer 复杂一些)。
高通说他们实现这一步并不需要额外的数据,可以优雅地在 Data-Free 的情况下实现,这也是他们给论文起名 Data-Free 的缘由。具体的算法我们后面再说。
Bias Correction
除了 weight 的问题之外,研究人员发现,模型量化的时候总是会产生一种误差,这种误差对数值分布的形态影响不大,但却会使整个数值分布发生偏移 (biased)。
假设有 N N N 个样本,那么对于 feature map 上面的每一个数值,我们可以用下面这种方式计算偏移误差 (biased error):
E [ y j ~ − y j ] ≈ 1 N ( ∑ n ( W ~ x n ) j − ( W x n ) j ) (1) E[\widetilde{y_j}-y_j]\approx\frac{1}{N}(\sum_n(\widetilde{W}x_n)_j-(Wx_n)_j) \tag{1} E[yj
−yj]≈N1(n∑(W
xn)j−(Wxn)j)(1)
其中, W ~ \widetilde{W} W
是量化后再反量化的 weight (即带了量化误差), W W W 是原先的 weight, x n x_n xn 是输入,对应的 y j ~ \widetilde{y_j} yj
是量化后的输出, y j y_j yj 是原输出。
用这个公式可以算出引入量化误差后的 feature map 上每个点和原先的相差了多少,统计一下这些误差,就得到下面这张图:
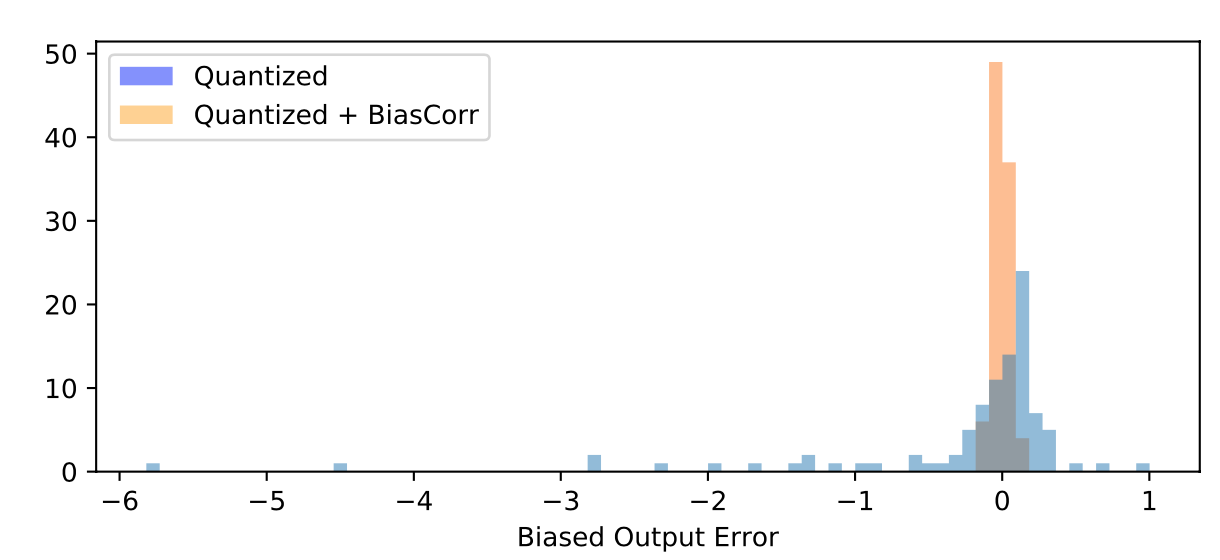
这里面蓝色的柱状图就统计了量化后的误差分布,看得出,有不少 feature 的误差已经超过了 1,而理想状态下,我们是希望量化后的误差能集中到 0 附近,越接近 0 越好,就像橙色直方图那样。
其实,这种 biased error 不仅仅只有量化的时候会出现,在做模型压缩的时候也会遇到。做过画质类任务模型剪枝的同学可能有这种体验,就是当你把一个大模型里面某些卷积的通道数砍掉时,会发现模型的输出结果出现一种整体上的色彩变化。比如,我在一个图像去噪的实验中用了剪枝后,出现下面这种现象:

模型剪枝后,你会发现模型的输出结果和原来相比,好像整体的颜色上多了一个偏移 (biased),但图像里面的物体基本还能辨识 (数值分布的形态没有发生变化)。
我自己画了幅简图描述这种现象:
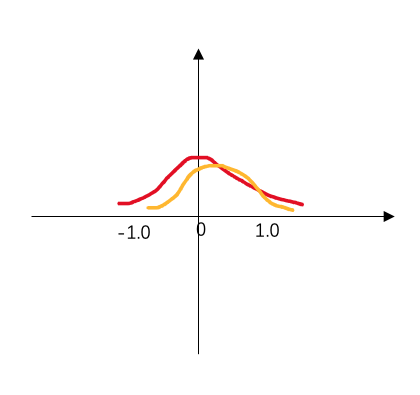
以上是我对 biased error 的一些理解。
研究人员发现,用上 weight equalization 后,这种 biased error 会更加地突出。而 Bias Correction 就是为了解决该问题提出的。
具体方法
Weight Equalization
要实现 Weight Equalization,一个很直接的想法就是对卷积核的每个 kernel (或者是全连接层的每个权重通道) 都乘上一个缩放系数,对数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1621
1621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









