







在前面的文章中,我们通过TechMart的案例详细探讨了数据驱动决策的实施过程。现在,让我们将视野扩展到更广阔的领域,看看数据驱动决策如何在不同行业中发挥作用,以及新兴技术如何推动这一领域的发展。

目录
1. 跨行业应用案例
数据驱动决策在各个行业都有其独特的应用。让我们看几个具体的例子:
1.1 医疗保健:预测性维护和个性化治疗
在医疗保健领域,数据驱动决策可以用于预测设备故障和个性化治疗方案。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
def predict_equipment_failure(data):
# 准备特征和目标变量
X = data[['age', 'usage_hours', 'temperature', 'vibration']]
y = data['failure']
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测和评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
return model
# 使用示例(假设数据)
equipment_data = pd.DataFrame({
'age': [5, 3, 7, 2, 6],
'usage_hours': [1000, 500, 1500, 300, 1200],
'temperature': [80, 70, 90, 75, 85],
'vibration': [0.5, 0.3, 0.7, 0.2, 0.6],
'failure': [1, 0, 1, 0, 1]
})
failure_prediction_model = predict_equipment_failure(equipment_data)
1.2 金融服务:风险评估和欺诈检测
在金融领域,数据驱动决策可以用于信用风险评估和欺诈交易检测。
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import IsolationForest
def detect_fraudulent_transactions(transactions):
# 准备特征
features = ['amount', 'time_since_last_transaction', 'distance_from_last_transaction']
X = transactions[features]
# 标准化特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 训练孤立森林模型
model = IsolationForest(contamination=0.05, random_state=42)
model.fit(X_scaled)
# 预测
predictions = model.predict(X_scaled)
transactions['is_fraud'] = predictions
# 输出结果
fraud_transactions = transactions[transactions['is_fraud'] == -1]
print(f"检测到 {len(fraud_transactions)} 笔可疑交易,占总交易的 {len(fraud_transactions)/len(transactions):.2%}")
return model, fraud_transactions
# 使用示例(假设数据)
transactions = pd.DataFrame({
'amount': np.random.normal(100, 50, 1000),
'time_since_last_transaction': np.random.exponential(2, 1000),
'distance_from_last_transaction': np.random.gamma(2, 2, 1000)
})
fraud_detection_model, suspicious_transactions = detect_fraudulent_transactions(transactions)
print(suspicious_transactions.head())
1.3 零售:需求预测和个性化推荐
零售业可以使用数据驱动决策来预测产品需求和提供个性化推荐。
from sklearn.decomposition import NMF
from sklearn.preprocessing import MinMaxScaler
def recommend_products(user_item_matrix):
# 标准化数据
scaler = MinMaxScaler()
user_item_scaled = scaler.fit_transform(user_item_matrix)
# 应用非负矩阵分解
nmf_model = NMF(n_components=20, random_state=42)
user_features = nmf_model.fit_transform(user_item_scaled)
item_features = nmf_model.components_
# 生成推荐
recommendations = np.dot(user_features, item_features)
recommendations = scaler.inverse_transform(recommendations)
return recommendations
# 使用示例(假设数据)
user_item_matrix = pd.DataFrame(np.random.randint(0, 5, size=(100, 50)))
recommendations = recommend_products(user_item_matrix)
# 为特定用户生成Top 5推荐
user_id = 0
top_5_recommendations = user_item_matrix.columns[np.argsort(recommendations[user_id])[-5:][::-1]]
print(f"用户 {user_id} 的Top 5推荐产品: {', '.join(map(str, top_5_recommendations))}")
2. 新兴技术与数据驱动决策
随着技术的发展,一些新兴技术正在改变数据驱动决策的实践方式。
2.1 人工智能和机器学习
AI和ML正在使数据驱动决策变得更加智能和自动化。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
import numpy as np
def create_time_series_model(input_shape):
model = Sequential([
LSTM(50, activation='relu', input_shape=input_shape),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')
return model
# 使用示例(假设数据)
time_steps = 10
features = 5
X = np.random.random((1000, time_steps, features))
y = np.random.random((1000, 1))
model = create_time_series_model((time_steps, features))
model.fit(X, y, epochs=10, batch_size=32, validation_split=0.2, verbose=0)
# 预测
new_data = np.random.random((1, time_steps, features))
prediction = model.predict(new_data)
print(f"预测结果: {prediction[0][0]:.4f}")
2.2 物联网(IoT)和边缘计算
IoT设备产生的海量数据为决策提供了新的机会,而边缘计算则使得实时决策成为可能。
import random
import time
class IoTDevice:
def __init__(self, device_id):
self.device_id = device_id
self.temperature = random.uniform(20, 30)
self.humidity = random.uniform(30, 70)
def read_sensor_data(self):
# 模拟传感器读数
self.temperature += random.uniform(-0.5, 0.5)
self.humidity += random.uniform(-1, 1)
return {
'device_id': self.device_id,
'temperature': self.temperature,
'humidity': self.humidity,
'timestamp': time.time()
}
def edge_processing(data, temp_threshold=28, humidity_threshold=60):
if data['temperature'] > temp_threshold or data['humidity'] > humidity_threshold:
return True
return False
# 模拟IoT设备网络
devices = [IoTDevice(f"device_{i}") for i in range(5)]
# 模拟数据收集和边缘处理
for _ in range(10): # 模拟10个时间步
for device in devices:
data = device.read_sensor_data()
if edge_processing(data):
print(f"警报: 设备 {data['device_id']} 异常. 温度: {data['temperature']:.2f}, 湿度: {data['humidity']:.2f}")
time.sleep(1) # 模拟1秒的数据收集间隔
2.3 区块链技术
区块链可以为数据驱动决策提供更高的透明度和可追溯性。
import hashlib
import json
from time import time
class Blockchain:
def __init__(self):
self.chain = []
self.current_transactions = []
# 创建创世块
self.new_block(previous_hash='1', proof=100)
def new_block(self, proof, previous_hash=None):
block = {
'index': len(self.chain) + 1,
'timestamp': time(),
'transactions': self.current_transactions,
'proof': proof,
'previous_hash': previous_hash or self.hash(self.chain[-1]),
}
# 重置当前交易列表
self.current_transactions = []
self.chain.append(block)
return block
def new_transaction(self, sender, recipient, amount):
self.current_transactions.append({
'sender': sender,
'recipient': recipient,
'amount': amount,
})
return self.last_block['index'] + 1
@property
def last_block(self):
return self.chain[-1]
@staticmethod
def hash(block):
block_string = json.dumps(block, sort_keys=True).encode()
return hashlib.sha256(block_string).hexdigest()
# 使用示例
blockchain = Blockchain()
# 添加一些交易
blockchain.new_transaction("Alice", "Bob", 50)
blockchain.new_transaction("Bob", "Charlie", 30)
# 创建新块
last_proof = blockchain.last_block['proof']
proof = 4 # 在实际应用中,这里应该有一个工作量证明算法
blockchain.new_block(proof)
print(json.dumps(blockchain.chain, indent=2))
3. 伦理和社会考量

随着数据驱动决策变得越来越普遍,我们必须考虑其伦理和社会影响。
3.1 算法偏见
我们需要确保我们的模型不会无意中加强社会偏见。
from aif360.datasets import BinaryLabelDataset
from aif360.metrics import BinaryLabelDatasetMetric
from aif360.algorithms.preprocessing import Reweighing
def check_and_mitigate_bias(data, protected_attribute, privileged_groups, unprivileged_groups):
# 创建数据集
dataset = BinaryLabelDataset(df=data, label_name='label',
protected_attribute_names=[protected_attribute])
# 计算初始偏见指标
metric = BinaryLabelDatasetMetric(dataset, unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups)
print(f"初始统计均等差: {metric.statistical_parity_difference():.4f}")
# 应用重新加权算法
rw = Reweighing(unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups)
dataset_transformed = rw.fit_transform(dataset)
# 计算缓解后的偏见指标
metric_transformed = BinaryLabelDatasetMetric(dataset_transformed,
unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups)
print(f"缓解后统计均等差: {metric_transformed.statistical_parity_difference():.4f}")
# 使用示例(假设数据)
data = pd.DataFrame({
'feature1': np.random.random(1000),
'feature2': np.random.random(1000),
'gender': np.random.choice(['male', 'female'], 1000),
'label': np.random.choice([0, 1], 1000)
})
check_and_mitigate_bias(data, 'gender',
privileged_groups=[{'gender': 'male'}],
unprivileged_groups=[{'gender': 'female'}])
3.2 隐私保护
在收集和使用数据时,我们必须尊重个人隐私。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import numpy as np
def anonymize_data(data, sensitive_columns):
# 移除敏感列
non_sensitive_data = data.drop(columns=sensitive_columns)
# 标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(non_sensitive_data)
# 应用PCA
pca = PCA(n_components=0.95) # 保留95%的方差
anonymized_data = pca.fit_transform(scaled_data)
return pd.DataFrame(anonymized_data, columns=[f'feature_{i}' for i in range(anonymized_data.shape[1])])
# 使用示例
data = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'income': [50000, 60000, 70000],
'city': ['New York', 'Los Angeles', 'Chicago']
})
sensitive_columns = ['name', 'city']anonymized_data = anonymize_data(data, sensitive_columns)
print(anonymized_data.head())
3.3 可解释性和透明度
随着决策变得越来越复杂,确保模型的可解释性变得至关重要。
import shap
from sklearn.ensemble import RandomForestClassifier
def explain_model_predictions(model, X, feature_names):
# 创建SHAP解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# 绘制摘要图
shap.summary_plot(shap_values, X, feature_names=feature_names, show=False)
plt.title("特征重要性和影响")
plt.tight_layout()
plt.show()
# 为单个预测生成解释
shap.force_plot(explainer.expected_value[1], shap_values[1][0,:], X.iloc[0,:], feature_names=feature_names, show=False)
plt.title("单个预测的解释")
plt.tight_layout()
plt.show()
# 使用示例
X = pd.DataFrame(np.random.random((100, 5)), columns=['feature_'+str(i) for i in range(5)])
y = (X.sum(axis=1) > 2.5).astype(int)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X, y)
explain_model_predictions(model, X, X.columns)
4. 跨行业案例研究:智慧城市
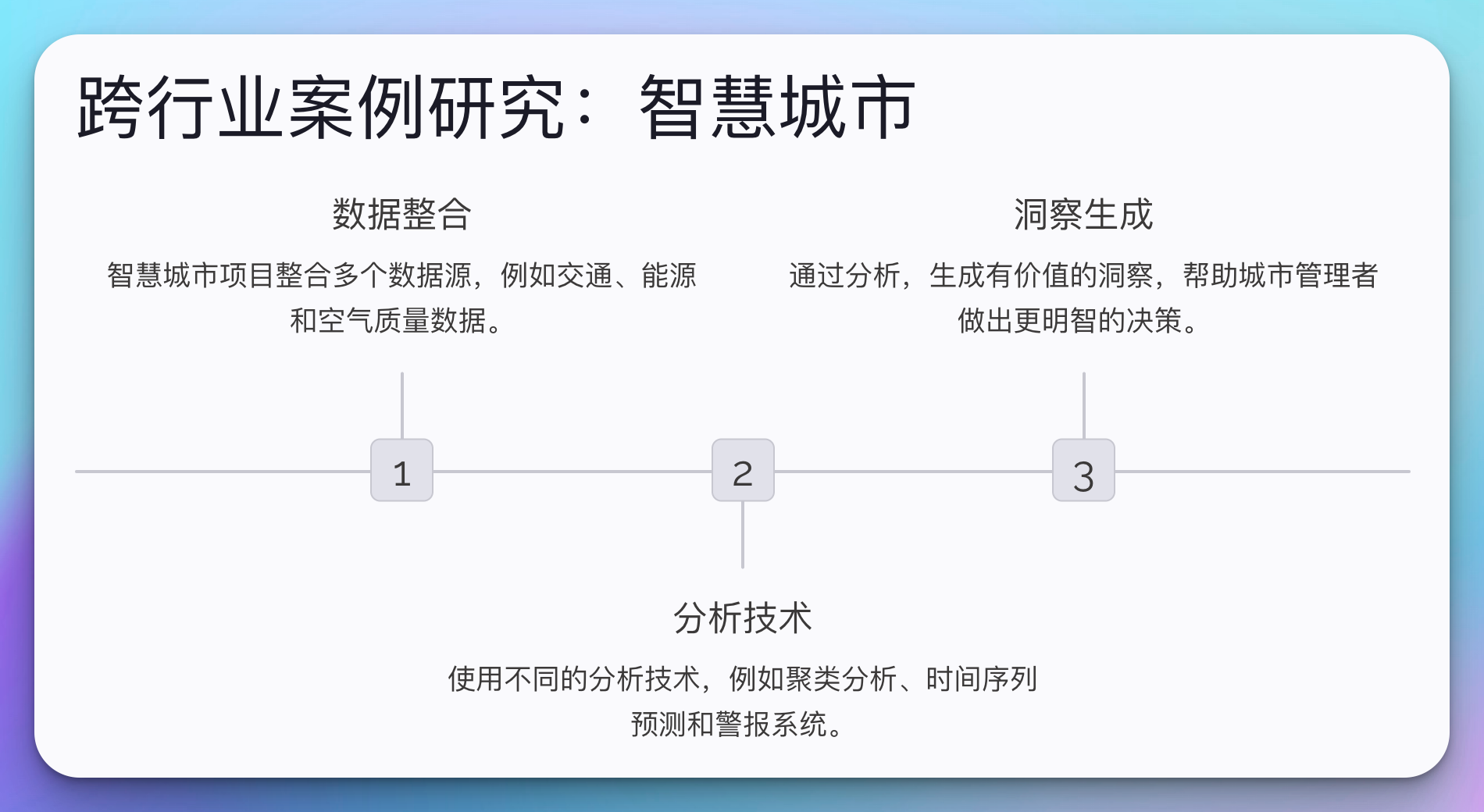
让我们通过一个综合性的智慧城市项目来看看数据驱动决策如何在复杂的环境中应用。
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
class SmartCity:
def __init__(self):
self.traffic_data = None
self.energy_consumption = None
self.air_quality = None
def collect_data(self, days):
# 模拟数据收集
self.traffic_data = pd.DataFrame({
'date': pd.date_range(start='2023-01-01', periods=days),
'vehicle_count': np.random.randint(1000, 5000, days),
'average_speed': np.random.uniform(20, 60, days)
})
self.energy_consumption = pd.DataFrame({
'date': pd.date_range(start='2023-01-01', periods=days),
'consumption_kwh': np.random.uniform(10000, 50000, days)
})
self.air_quality = pd.DataFrame({
'date': pd.date_range(start='2023-01-01', periods=days),
'pm25': np.random.uniform(10, 100, days),
'ozone': np.random.uniform(20, 80, days)
})
def analyze_traffic_patterns(self):
# 使用K-means聚类分析交通模式
features = ['vehicle_count', 'average_speed']
X = self.traffic_data[features]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
kmeans = KMeans(n_clusters=3, random_state=42)
self.traffic_data['cluster'] = kmeans.fit_predict(X_scaled)
print("交通模式聚类结果:")
print(self.traffic_data.groupby('cluster')[features].mean())
def predict_energy_consumption(self):
# 简单的时间序列预测
from statsmodels.tsa.arima.model import ARIMA
model = ARIMA(self.energy_consumption['consumption_kwh'], order=(1,1,1))
results = model.fit()
forecast = results.forecast(steps=7)
print("\n未来7天能源消耗预测:")
print(forecast)
def monitor_air_quality(self):
# 监控空气质量并发出警报
pm25_threshold = 75
ozone_threshold = 70
alerts = self.air_quality[(self.air_quality['pm25'] > pm25_threshold) |
(self.air_quality['ozone'] > ozone_threshold)]
print("\n空气质量警报:")
print(alerts)
def generate_insights(self):
self.analyze_traffic_patterns()
self.predict_energy_consumption()
self.monitor_air_quality()
# 使用示例
smart_city = SmartCity()
smart_city.collect_data(days=90)
smart_city.generate_insights()
这个智慧城市案例展示了如何将多个数据源整合在一起,并使用不同的分析技术来生成有价值的洞察。这种综合性的方法可以帮助城市管理者做出更明智的决策,例如优化交通流量、提高能源效率和改善空气质量。
5. 未来展望

随着技术的不断发展,数据驱动决策的未来充满了可能性:
- 自主决策系统:AI系统可能会在某些领域自主做出决策,人类的角色更多是监督和干预。
- 量子计算:量子计算可能会彻底改变我们处理复杂数据的方式,使我们能够解决当前无法解决的问题。
- 增强现实决策支持:AR技术可能会改变决策者与数据交互的方式,提供更直观的数据可视化。
- 情感智能:未来的决策系统可能会考虑人类的情感因素,实现更全面的决策过程。
def simulate_future_decision_system(data, human_input, ai_recommendation, emotion_factor):
decision_weight = {
'data': 0.4,
'human': 0.3,
'ai': 0.2,
'emotion': 0.1
}
final_decision = (
data * decision_weight['data'] +
human_input * decision_weight['human'] +
ai_recommendation * decision_weight['ai'] +
emotion_factor * decision_weight['emotion']
)
return final_decision
# 使用示例
data_input = 0.7 # 基于数据的决策分数
human_input = 0.8 # 人类决策者的输入
ai_recommendation = 0.9 # AI系统的建议
emotion_factor = 0.5 # 情感因素
decision = simulate_future_decision_system(data_input, human_input, ai_recommendation, emotion_factor)
print(f"最终决策分数: {decision:.2f}")
结语

数据驱动决策正在重塑各个行业的决策方式。从医疗保健到金融服务,从零售到智慧城市,数据的力量无处不在。然而,随着我们越来越依赖数据和算法来指导决策,我们必须保持警惕,确保这些决策是公平、透明和负责任的。
新兴技术如AI、IoT和区块链正在为数据驱动决策开辟新的可能性,但它们也带来了新的挑战。我们需要不断学习和适应,以充分利用这些技术的潜力,同时管理相关的风险。
最重要的是,我们必须记住,数据驱动决策的终极目标是改善人们的生活和工作。无论是优化城市交通,提供个性化医疗保健,还是创造更安全的金融系统,我们的焦点应该始终是为社会创造积极的影响。
随着我们进入数据时代的下一个阶段,让我们共同努力,确保数据驱动决策不仅仅是高效的,而且是符合道德、以人为本的。只有这样,我们才能真正实现数据的变革性潜力,为所有人创造一个更美好的未来。


















 944
944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











