






现已进入测试阶段,带来了丰富的新功能,可简化企业开发者创建、使用和共享 AI 和机器学习 (ML) 项目的方式。在 SIGGRAPH 2023 上发布的 NVIDIA AI Workbench,使开发者能够在支持 GPU 的环境中轻松创建、协作和迁移 AI 工作负载。欲了解更多信息,请参阅借助 NVIDIA AI Workbench 无缝开发和部署可扩展的生成式 AI 模型。
本文介绍了 NVIDIA AI Workbench 如何帮助简化 AI 工作流程,并详细介绍了测试版的新功能。本文还介绍了编码副驾驶参考示例,该示例使您能够使用 AI Workbench 在所选平台上创建、测试和自定义预训练的生成式 AI 模型。
什么是 NVIDIA AI Workbench?
借助 AI Workbench,开发者和数据科学家可以在 PC 或工作站上灵活地在本地启动 AI 或 ML 项目,然后将其迁移到任何地方。项目可以推送到数据中心、公有云或 NVIDIA DGX 云,或者根据项目需求迁移到本地 RTX PC 或工作站进行推理和轻量级定制。
AI Workbench 通过提供处理所选异构计算资源的能力,帮助开发者简化和缩短 AI 工作流程的设置、开发和迁移。优势包括:
- 使用直观的 UX 或 CLI 在所选系统上免费快速安装,以创建和管理项目。
- 简化计算资源和运行时配置,为使用不同的 GPU 资源提供再现性和灵活性。
- 简化容器和 Git 存储库的版本控制和管理,以及与 GitHub、GitLab 和 NVIDIA NGC 目录 的集成。
- 实现自动化和简化,以处理基于 Git 和容器的开发者环境,使用户能够选择系统、笔记本电脑、工作站、服务器或云。
- 跨用户和系统的可再现性,可以透明地处理凭据、机密和文件系统更改等特性,而不会产生额外费用。
- 可扩展地创建和分发适用于生成式 AI、支持 GPU 的机器学习和数据科学的复杂工作流程和应用。
测试版新增功能
AI Workbench 测试版包含以下令人兴奋的新功能,包括用户界面更新以及对容器运行时和 Git 服务器的扩展支持。
简化设置和安装,支持在 Windows 11、Ubuntu 22.04 和 macOS 11 或更高版本上运行。
- 通过两种方式快速安装 AI Workbench:在本地系统上使用桌面应用程序进行单击安装,或在远程系统上进行命令行安装。
- 支持三大操作系统,随时随地开展工作,获得统一体验。AI Workbench 可在支持 WSL2、Ubuntu 22。04 和 macOS 版本 11 及更高版本的 Windows 发行版上运行。
借助容器化环境简化版本控制和开发。
- 使用桌面应用程序和 CLI 访问简单且全面的 Git 兼容版本控制。现在包含 Push、Pull 和 Fetch 功能。
- 创建具有隔离和可再现性的容器化 JupyterLab 环境,而无需处理细节。
- 从两个容器运行时选项中进行选择:Docker 或 Podman。
扩展了用户界面和 CLI 之间的功能一致性。
- 直接在桌面应用程序中查看提交历史记录和摘要。
- 在桌面应用程序中查看改进的容器状态和应用程序状态通知。
扩展了默认基础图像。
- 访问三个新的基础图像以创建项目,此外,NGC 目录中已有的 Python 基础版 和 PyTorch 基础版。适用于 CUDA 11.0、CUDA 12.0 和 CUDA 12.2 的新基础图像为进一步定制提供了基础。
三个新的示例项目供参考。
- Mistral:使用 QLoRA PEFT 在自定义代码指令数据集上微调 Mistral 7B 大型语言模型 (LLM)。
- RAG:使用用户友好型本地开发者工作流程与数据进行对话,实现检索增强生成(RAG)。
- NeMotron-3 中文关键词:在自定义 QA 数据集上微调 NVIDIA NeMo 的 Nemotron-3 8B LLM。
创建您自己的编码副驾驶
本节介绍了 AI Workbench 如何显著简化在用户选择的 GPU 系统上使用和微调生成式 AI 模型的过程。
关键概念
本示例中使用的几个关键概念概述如下。
AI 工作台项目
AI Workbench 项目是一个 Git 存储库,其中包含一组可由 AI Workbench 读取的配置文件,以自动创建和管理容器化开发环境。项目引用了已配置的容器化开发环境所需的一切,包括:
- 代码、数据和模型
- 驱动 AI Workbench 自动化的简单配置文件,用于容器自定义和软件包安装
- 项目规格元数据文件,以与 AI Workbench 兼容的方式包装资源库
访问 GitHub 上的 NVIDIA 项目,这些项目为调整自己的数据和用例提供了起点。此外,AI Workbench 抢先体验成员可以贡献和使用第三方社区项目示例。
我们的 Mistral 7B 微调参考项目 详细介绍了如何在您的系统中利用 AI Workbench 的强大功能,构建一个基本的编码副驾驶。
微调
虽然 Mistral 7B 是多个下游任务的坚实基础,但它可能缺乏基于专有或其他敏感信息的特定领域知识。在这些情况下,微调用于改善模型的响应。
微调有两个版本。第一个版本是完全微调,使用新数据更新所有模型权重。这可以改善特定领域的结果,但通常需要更多的时间、更大、更昂贵的 GPU。其次,参数高效微调 (PEFT)是一系列用于更新模型权重子集的技术。PEFT 通常优于完全微调,因为它可以在更短的时间内生成类似的结果,并且使用更小、更便宜的 GPU。
此示例主要关注 PEFT 的量化低排名适应 (QLoRA) 方法。低排名适应 (LoRA) 是一种 PEFT 方法,在重新训练中使用较小的权重矩阵作为近似值,而不是更新全权重矩阵。这种排名分解优化技术可以提高内存效率,并减少成功微调所需的 GPU 大小。
QLoRA 是一种进一步的优化,它降低了模型权重的精度,从而在内存和空间效率方面取得了更大的进步。在 LoRA 微调工作流程中,最常见的量化是 4 位量化,它在模型性能和微调可行性之间提供了适当的平衡。
NVIDIA AI Workbench 中的 Mistral 7B 微调项目演练
此演示包含高级代码和详细信息。欲了解更多信息,请参阅完整的Mistral 7B 微调参考项目,该项目基于 Mistral 7B 基础模型。此外,TokenBender 代码说明数据集提供了 12.2 万个 Alpaca 风格的代码指令和相应的代码解决方案。
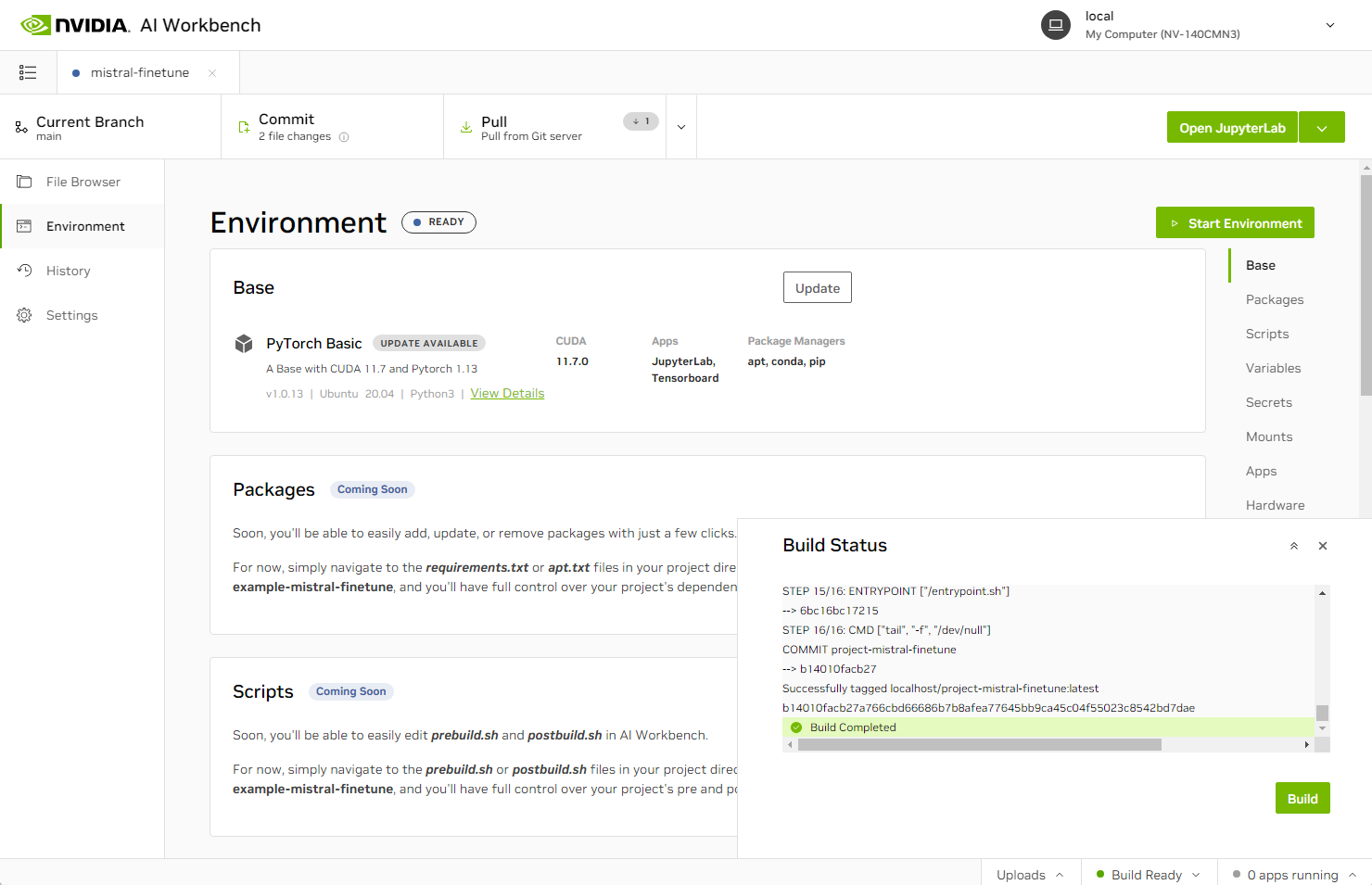
图 1.在 NVIDIA AI Workbench 中构建 Mistral 7B 微调项目
首先,下载数据并将其分为 80%的训练数据集、10%的验证数据集和 10%的测试数据集。数据集中的一个指令条目如下所示:
|
|
接下来,下载 Mistral 7B 模型权重至此项目:
|
|
请注意,已为基础模型指定 4 位量化配置。
接下来,根据特定的示例编程问题评估基础模型的性能。这将为基础模型和最终微调模型之间的比较建立基准。
|
|
请注意,基础模型开箱即用的表现不佳。首先,基础模型似乎认为 2023 的 Prime factorization 是 13 x 157.这相当于 2041。实际答案是 7 x 17 x 17、
其次,模型输出的 Python 函数也不正确。运行建议的代码会给出[7、17、119、289、2023]的答案,而实际上 119、289 和 2023 不是主要因素。
为了提高模型性能,必须进行微调。首先,通过重新格式化数据集条目以更好地适应用于微调的指令提示[INST],对数据集进行预处理。然后对每个提示进行标记化。
接下来,配置 QLoRA 微调的参数,并开始微调过程。默认情况下,微调包括 1000 次迭代,每 50 步进行一次检查点和评估。这些超参数可以根据硬件资源进行调整。在配备 NVIDIA A100 80 GB GPU 的系统中,此配置大约需要 6.5 小时。
|
|
使用最终微调检查点,定义更新的 Mistral 7B 模型:
|
|
要评估微调模型的性能,请提出与初始问题类似的编码问题,并请求生成代码片段:
|
|
经过微调的模型生成的代码片段响应效果会更好。使用沙盒环境亲自试用代码。
这就是微调 Mistral 7B LLM 的全部内容。此项目为您的开发需求提供了参考工作流。您可以随时选择自定义项目,以更好地适应您的企业数据或用例。将数据集切换为您自己的数据集,或将模型微调为另一个用例,例如文本摘要或问答。















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









