







lossAbstract
我们提出了一种新颖的深度学习架构,用于融合静态多重曝光图像。 当前的多重曝光融合(MEF)方法使用手工制作的特征来融合输入序列。 然而,弱的手工表示对于不同的输入条件并不鲁棒。 此外,它们对于极端曝光的图像对表现不佳。 因此,非常需要一种对变化的输入条件具有鲁棒性并且能够在没有伪影的情况下处理极端曝光的方法。 众所周知,深度表示对于输入条件具有鲁棒性,并且在监督环境中表现出惊人的性能。 然而,将深度学习用于 MEF 的绊脚石是缺乏足够的训练数据和为监督提供基础事实的预言机。 为了解决上述问题,我们收集了用于训练的大型多重曝光图像堆栈数据集,并为了避免对地面真实图像的需求,我们提出了一种利用无参考质量指标作为损失函数的 MEF 无监督深度学习框架。 所提出的方法使用一种新颖的 CNN 架构,经过训练可以学习融合操作,而无需参考地面实况图像。 该模型融合了从每幅图像中提取的一组常见的低级特征,以生成无伪影的、令人愉悦的感知结果。 我们进行了广泛的定量和定性评估,并表明所提出的技术优于各种自然图像的现有最先进方法。
1. Introduction
高动态范围成像 (HDRI) 是一种摄影技术,有助于在困难的照明条件下拍摄出更好看的照片。 它有助于存储人眼可感知的所有范围的光(或亮度),而不是使用相机实现的有限范围。 由于此属性,场景中的所有对象在 HDRI 中看起来都更好、更清晰,否则不会饱和(太暗或太亮)。
HDR 图像生成的流行方法称为多重曝光融合 (MEF),其中将一组具有不同曝光度的静态 LDR 图像(进一步称为曝光堆栈)融合为单个 HDR 图像。 所提出的方法属于这一类。 当曝光堆栈中每个 LDR 图像之间的曝光偏差差异最小时,大多数 MEF 算法效果更好1。 因此,它们需要曝光堆栈中更多的 LDR 图像(通常超过 2 个图像)来捕获场景的整个动态范围。 它导致更多的存储需求、处理时间和功率。 原则上,长曝光图像(以高曝光时间捕获的图像)在暗区域具有更好的颜色和结构信息,短曝光图像(以较少曝光时间捕获的图像)在亮区域具有更好的颜色和结构信息。 尽管融合极端曝光图像实际上更有吸引力,但它相当具有挑战性(现有方法无法保持整个图像的均匀亮度)。 此外,应该注意的是,拍摄更多照片会增加功耗、捕获时间和计算时间要求。 因此,我们建议使用曝光包围图像对作为我们算法的输入。
在这项工作中,我们提出了一种数据驱动的学习方法,用于融合包围曝光的静态图像对。 据我们所知,这是第一个使用深度 CNN 架构进行曝光融合的工作。 初始层由一组滤波器组成,用于从每个输入图像对中提取常见的低级特征。 输入图像对的这些低级特征被融合以重建最终结果。 整个网络使用无参考图像质量损失函数进行端到端训练。
我们使用在不同设置(室内/室外、白天/夜间、侧光/背光等)下捕获的大量曝光堆栈来训练和测试我们的模型。 此外,我们的模型不需要针对不同的输入条件进行参数微调。 通过广泛的实验评估,我们证明所提出的架构对于各种输入场景都比最先进的方法表现得更好。
这项工作的贡献如下:
• 基于CNN 的无监督图像融合算法,用于融合曝光堆叠静态图像对。
• 可用于比较各种MEF 方法的新基准数据集。
• 针对各种自然图像的 7 种最先进算法进行了广泛的实验评估和比较研究。
本文的结构如下。 第二节,我们简要回顾文献中的相关作品。 第 3 部分,我们介绍基于 CNN 的曝光融合算法并讨论实验细节。 第 4 节,我们提供融合示例,然后在第 5 节中进行富有洞察力的讨论来结束本文。
2. Related Works
多年来已经提出了许多用于曝光融合的算法。 然而,所有算法的主要思想都是相同的。 该算法以局部或像素方式计算每个图像的权重。 融合图像将是输入序列中图像的加权和。
伯特等人[3] 对图像进行拉普拉斯金字塔分解,并使用局部能量和金字塔之间的相关性来计算权重。 拉普拉斯金字塔的使用减少了不必要的伪影的可能性。 戈什塔斯比等人[5]从每幅图像中获取具有最高信息的非重叠块以获得融合结果。 这很容易受到块伪影的影响。 默滕斯等人[16]使用简单的质量指标(例如对比度和饱和度)执行曝光融合。 然而,这会受到幻觉边缘和不匹配的颜色伪影的影响。
[19] 中提出了利用双边滤波器等边缘保留滤波器的算法。 由于这没有考虑图像的亮度,因此融合图像具有暗区,导致结果较差。 张等人提出了一种基于梯度的权重分配方法。 [28]。 在李等人的一系列论文中。 [9]、[10]已经报道了不同的曝光融合方法。 在他们的早期工作中,他们解决了二次优化以提取更精细的细节并将它们融合。 在他们后来的一项工作 [10] 中,他们提出了一种基于引导过滤器的方法。
沉等人。 [22]提出了一种使用局部对比度和颜色一致性等质量指标的融合技术。 他们执行的随机游走方法以概率方式为融合问题集提供了全局最优解。
上述所有工作都依赖于手工制作的特征来进行图像融合。 这些方法并不稳健,因为参数需要针对不同的输入条件(例如线性和非线性曝光、滤波器大小取决于图像大小)而变化。 为了避免这种参数调整,我们提出了一种使用 CNN 的基于特征学习的方法。 在这项工作中,我们学习了融合曝光包围图像的合适特征。 最近,卷积神经网络(CNN)在各种计算机视觉任务中表现出了令人印象深刻的性能[8]。 虽然 CNN 在许多高级计算机视觉任务中产生了最先进的结果,例如识别([7]、[21])、对象检测 [11]、分割 [6]、语义标记 [17]、视觉 问题回答[2]等等,它们在低级图像处理问题(例如过滤[4]和融合[18])上的性能尚未得到广泛研究。 在这项工作中,我们探讨了 CNN 在多重曝光图像融合任务中的有效性。
据我们所知,文献中尚未报道使用 CNN 进行多重曝光融合。 另一种机器学习方法基于称为极限学习机 (ELM) [25] 的回归方法,它将饱和度、曝光度和对比度输入回归器以估计每个像素的重要性。 我们不使用手工制作的特征,而是使用数据直接从原始像素中学习表示。
3. Proposed Method
在这项工作中,我们提出了一个使用 CNN 的图像融合框架。 在几年内,卷积神经网络在高端计算机视觉任务中取得了巨大的成功。 研究表明,它们可以借助足够的训练数据来学习输入和输出之间的复杂映射。 CNN 通过优化损失函数来学习模型参数,以便预测结果尽可能接近真实情况。 例如,假设输入 x 通过某种复杂的变换 f 映射到输出 y。 可以训练 CNN 来估计函数 f,以最小化预期输出 y 和获得的输出 ˆy 之间的差异。 y 和 ˆy 之间的距离是使用损失函数(例如均方误差函数)计算的。 最小化该损失函数可以更好地估计所需的映射函数。
让我们将输入曝光序列和融合算子表示为 I 和 O(I)。 假设输入图像使用现有的配准算法进行配准和对齐,从而避免相机和物体运动。 我们使用前馈过程 FW(I) 对 O(I) 进行建模。 这里,F表示网络架构,W表示通过最小化损失函数学习到的权重。 由于 MEF 问题不存在预期输出 O(I),因此无法使用平方误差损失或任何其他完整参考误差度量。 相反,我们利用 Ma 等人提出的无参考图像质量度量 MEF SSIM。 [15]作为损失函数。 MEF SSIM 基于结构相似性指数度量(SSIM)框架[27]。 它利用输入图像序列中各个像素周围的补丁的统计数据来与结果进行比较。 它测量结构完整性的损失以及多个尺度的亮度一致性(更多详细信息请参见第 3.1.1 节)。
该方法的总体方案如图1所示。输入的曝光堆栈被转换为YCbCr颜色通道数据。 CNN 用于融合输入图像的亮度通道。 这是因为图像结构细节存在于亮度通道中,并且亮度通道中的亮度变化比色度通道中的亮度变化更显着。 将获得的亮度通道与使用 3.3 节中描述的方法生成的色度(Cb 和 Cr)通道组合。 以下小节详细介绍了网络架构、损失函数和训练过程。
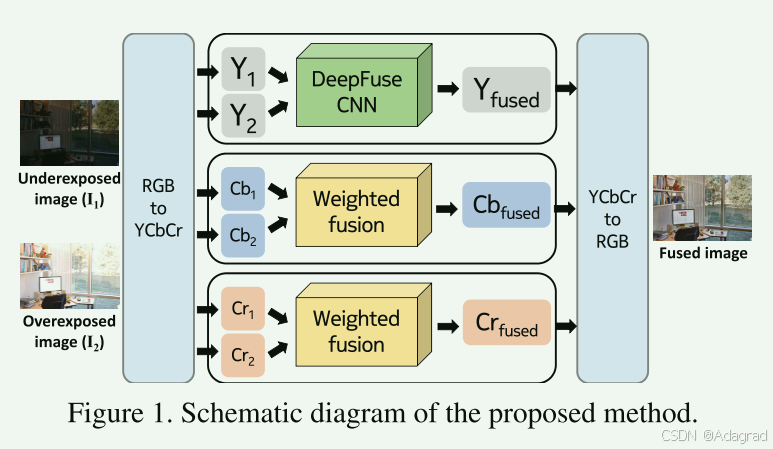
3.1. DeepFuse CNN
CNN 的学习能力很大程度上取决于架构和损失函数的正确选择。 一个简单朴素的架构是一系列按顺序连接的卷积层。 该架构的输入将是在三维空间中堆叠的曝光图像对。 由于融合发生在像素域本身,这种类型的架构并没有在很大程度上利用 CNN 的特征学习能力。
所提出的图像融合网络架构如图 2 所示。所提出的架构具有三个组成部分:特征提取层、融合层和重建层。 如图2所示,曝光不足和曝光过度的图像(Y1和Y2)被输入到单独的通道(通道1由C11和C21组成,通道2由C12和C22组成)。 第一层(C11 和 C12)包含 5 × 5 滤波器,用于提取边缘和角点等低级特征。 融合前通道的权重是绑定的,C11和C12(C21和C22)共享相同的权重。 构造层数的优势。 如图2所示,曝光不足和曝光过度的图像(Y1和Y2)被输入到单独的通道(通道1由C11和C21组成,通道2由C12和C22组成)。 第一层(C11 和 C12)包含 5 × 5 滤波器,用于提取边缘和角点等低级特征。 融合前通道的权重是绑定的,C11和C12(C21和C22)共享相同的权重。 这种架构的优点有三个:首先,我们强制网络学习输入对的相同特征。 即F11和F21是相同的特征类型。 因此,我们可以通过融合层简单地组合各个特征图。 这意味着,图像 1 (F11) 的第一个特征图和图像 2 (F21) 的第一个特征图被添加,并且该过程也适用于其余特征图。 此外,添加这些功能比组合功能的其他选择带来更好的性能(参见表 1)。 在特征添加中,来自两个图像的相似特征类型被融合在一起。
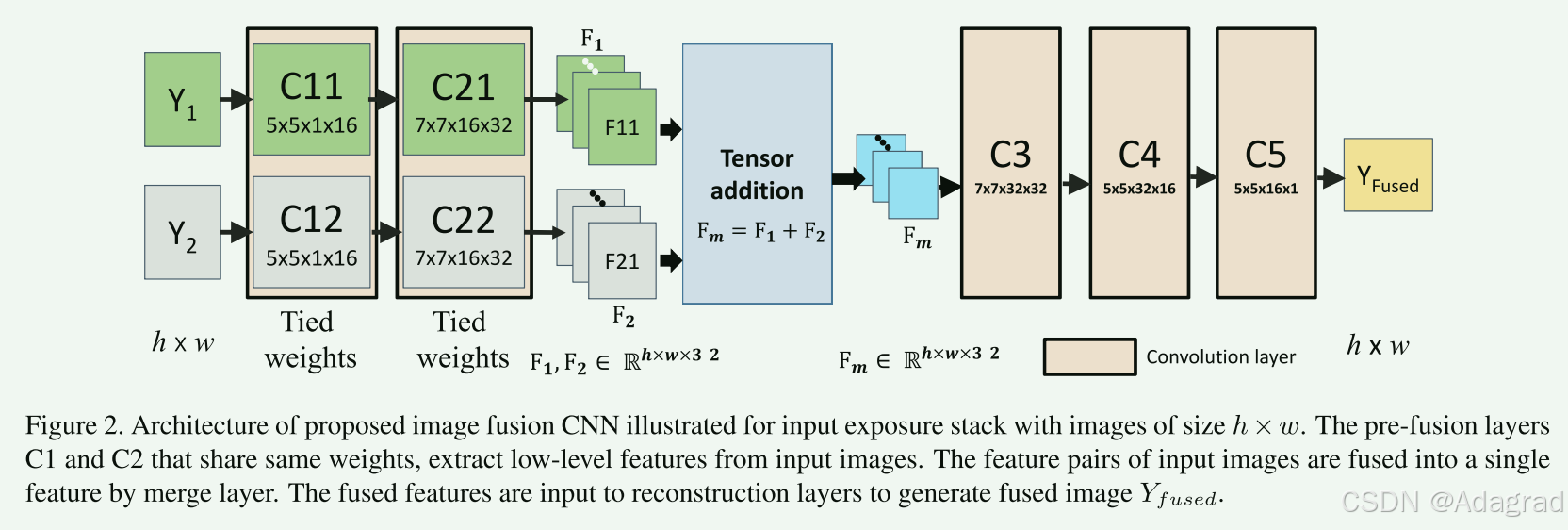
(可选)人们可以选择连接特征,通过这样做,网络必须计算出合并它们的权重。 在我们的实验中,我们观察到特征串联也可以通过增加训练迭代次数、增加 C3 之后的滤波器和层数来实现类似的结果。 这是可以理解的,因为网络需要更多次数的迭代来找出合适的融合权重。 在这种捆绑权重设置中,我们强制网络学习对亮度变化不变的滤波器。 这是通过可视化学习的过滤器来观察的(见图 8)。 在重量有限的情况下,很少有高激活滤波器具有中心环绕感受野(通常在视网膜中观察到)。 这些滤波器已经学会了去除邻域的均值,从而有效地使特征亮度不变。 其次,可学习滤波器的数量减少了一半。 第三,由于网络参数数量少,收敛速度快。 从 C21 和 C22 获得的特征通过合并层进行融合。 然后,融合层的结果通过另一组卷积层(C3、C4 和 C5),以根据融合特征重建最终结果(Yfused)。
3.1.1 MEF SSIM loss function
在本节中,我们将讨论通过 MEF SSIM 图像质量度量[15]在不使用参考图像的情况下计算损失。 令 {yk}={yk|k=1,2} 表示从输入图像对的像素位置 p 处提取的图像块,yf 表示在同一位置 p 处从 CNN 输出融合图像提取的块。 目标是计算一个分数来定义给定 yk 输入补丁和 yf 融合图像补丁的融合性能。
在SSIM [27]框架中,任何块都可以使用三个组件进行建模:结构(s)、亮度(l)和对比度(c)。 给定的补丁被分解为以下三个组件:

其中加权函数根据输入补丁之间的结构一致性分配权重。 当补丁具有不同的结构组件时,加权函数会为补丁分配相同的权重。 在另一种情况下,当所有输入块具有相似的结构时,具有高对比度的块被赋予更大的权重,因为它对失真更鲁棒。 估计的 ˆs 和 ˆc 组合起来产生所需的结果补丁,如下所示:

由于局部斑块中的亮度比较不显着,因此从上面的方程中丢弃亮度分量。 比较较低空间分辨率下的亮度并不能反映全局亮度一致性。 相反,在多个尺度上执行此操作将有效地捕获较粗尺度的全局亮度一致性和较细尺度的局部结构变化。 使用SSIM框架计算像素p的最终图像质量得分,
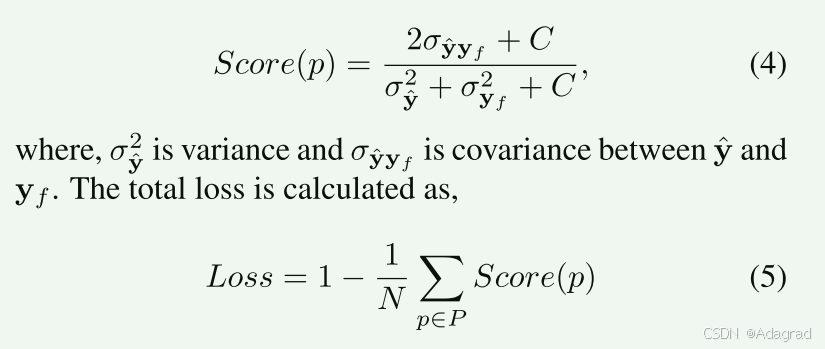
其中 N 是图像中的像素总数,P 是输入图像中所有像素的集合。 计算出的损失被反向传播以训练网络。 MEF SSIM 的更好性能归因于其目标函数最大化融合图像和每个输入图像之间的结构一致性。
3.2. Training
我们收集了 25 个公开可用的曝光堆栈 [1]。 除此之外,我们还策划了 50 个具有不同场景特征的曝光堆栈。 这些图像是使用标准相机设置和三脚架拍摄的。 每个场景由 2 个具有 ±2 EV 差异的低动态范围图像组成。 输入序列的大小调整为 1200 × 800 尺寸。 我们优先覆盖室内和室外场景。 从这些输入序列中,裁剪出 30000 个大小为 64 × 64 的块用于训练。 我们将学习率设置为 10−4,并训练网络 100 个时期,每个时期处理所有训练补丁。
3.3. Testing
我们遵循标准交叉验证程序来训练我们的模型并在不相交的测试集上测试最终模型,以避免过度拟合。 在测试时,经过训练的 CNN 获取测试图像序列并生成融合图像的亮度通道 (Yfused)。 融合图像的色度分量Cbfused 和Crfused 是通过输入色度通道值的加权和获得的。
图像的关键结构细节往往主要出现在 Y 通道中。 因此,文献中针对 Y 和 Cb/Cr 融合遵循不同的融合策略([18]、[24]、[26])。 此外,MEF SSIM 损失被制定为计算 2 个灰度 (Y) 图像之间的分数。 因此,测量 Cb 和 Cr 通道的 MEF SSIM 可能没有意义。 或者,可以选择使用不同的网络单独融合 RGB 通道。 然而,RGB 通道之间通常存在很大的相关性。 独立融合 RGB 无法捕获这种相关性,并会引入明显的色差。 此外,MEF-SSIM 不是为 RGB 通道设计的。 另一种替代方法是在单个网络中回归 RGB 值,然后将其转换为 Y 图像并计算 MEF SSIM 损失。 在这里,网络可以更多地关注改进 Y 通道,而不太重视颜色。 然而,我们在输出中观察到了输入中最初不存在的虚假颜色。
我们遵循 Prabhakar 等人使用的程序。 [18]用于色度通道融合。 如果 x1 和 x2 表示图像对任意像素位置处的 Cb(或 Cr)通道值,则融合色度值 x 的获得方式如下:
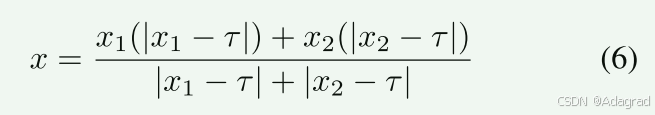
融合色度值是通过对两个色度值进行加权并减去自身的τ值得到的。 τ 的值选择为 128。这种方法背后的直觉是为良好的颜色分量赋予更多的权重,而为饱和的颜色值赋予更少的权重。 将{Yfused, Cbfused, Crfused}通道转换为RGB图像得到最终结果。
4. Experiments and Results
我们针对各种自然图像2对最先进的算法进行了广泛的评估和比较研究。 为了进行评估,我们选择了标准图像序列来涵盖不同的图像特征,包括室内和室外、白天和夜晚、自然光和人造光、线性和非线性曝光。 将所提出的算法与七种性能最佳的 MEF 算法进行比较,(1)Mertens09 [16],(2)Li13 [10](3)Li12 [9](4)Ma15 [14](5)Raman11 [20](6) )Shen11 [23] 和(7)Guo17 [12]。 为了客观地评价算法的性能,我们采用MEF SSIM。 尽管也报道了许多其他用于一般图像融合的 IQA 模型,但它们都没有对主观意见做出足够的质量预测 [15]。
4.1. DeepFuse - Baseline
到目前为止,我们已经讨论了无监督方式训练 CNN 模型。 其中一个有趣的变体是使用其他最先进方法的结果作为基本事实来训练 CNN 模型。 该实验可以测试CNN在不借助MEF SSIM损失函数的情况下从数据本身学习复杂融合规则的能力。 基于 MEF SSIM 评分 3,地面实况被选为 Mertens [16] 和 GFF [10] 方法中的最佳方法。 选择损失函数来计算真实值和估计输出之间的误差对于以监督方式训练 CNN 非常重要。 通常选择均方误差或 ℓ2 损失函数作为训练 CNN 的默认成本函数。 ℓ2 成本函数因其平滑的优化特性而受到欢迎。 虽然 ℓ2 损失函数更适合分类任务,但它们可能不是图像处理任务的正确选择[29]。 众所周知,MSE 与人类对图像质量的感知没有很好的相关性 [27]。 为了获得视觉上令人愉悦的结果,损失函数应该与 HVS 良好相关,如结构相似度指数(SSIM)[27]。 我们尝试了不同的损失函数,例如 ℓ1、ℓ2 和 SSIM。
当使用 ℓ2 损失函数训练 CNN 时,融合图像显得模糊。 这种效应被称为均值回归,是由于 ℓ2 损失函数以逐像素的方式比较结果和真实情况。 ℓ1 损失的结果比 ℓ2 损失的结果更清晰,但沿边缘有光环效应。 与 ℓ1 和 ℓ2 不同,使用 SSIM 损失函数训练的 CNN 结果既清晰又无伪影。 因此,本实验中使用 SSIM 作为损失函数来计算生成的输出与真实值之间的误差。
DeepFuse 基线和无监督方法之间的定量比较如表 2 所示。表 2 中的 MEF SSIM 分数显示了 DeepFuse 无监督方法在几乎所有测试序列中均优于基线方法。 原因是由于基线方法的学习量是其他算法的上限,因为基线方法的基本事实来自 Merterns 等人。 [16] 或李等人。 [10]。 从表2中我们可以看出,基线方法并没有超过这两者。 这个实验背后的想法是结合以前所有方法的优点,同时避免每种方法的缺点。 从图 3 中,我们可以观察到,虽然 DF-baseline 是使用其他方法的结果进行训练的,但它可以产生在其他结果中没有观察到的任何伪影的结果。
4.2. Comparison with State-of-the-art
与 Mertens 等人的比较: Mertens 等人。 [16]是一种简单有效的基于加权的图像融合技术,具有多分辨率混合以产生平滑的结果。 然而,它存在以下缺点:(a)它使用饱和度和曝光良好等手工制作的特征来选择每个图像的“最佳”部分进行融合。 这种方法对于具有许多曝光图像的图像堆栈效果更好。 但对于曝光图像对,它无法保持整个图像的均匀亮度。 与 Mertens 等人相比,DeepFuse 生成的图像在整个图像上具有一致且均匀的亮度。 (b) 默滕斯等人。 不能保留曝光不足的图像的完整图像细节。 在图 4(d) 中,Mertens 等人的结果中缺少图块区域的细节。 图 4(j) 中的情况也是如此,Mertens 等人的论文中没有显示灯的细节。 结果。 而 DeepFuse 已经学习了过滤器,可以提取 C1 和 C2 中的边缘和纹理等特征,并保留场景的更精细的结构细节。
与李等人的比较 [9] [10]:值得注意的是,与 Mertens 等人类似。 [16],李等人。 [9][10]也受到不均匀亮度伪影的影响(图5)。 相比之下,我们的算法提供了更令人愉悦的图像,具有清晰的纹理细节。
与沉等人的比较。 [23]:Shen 等人生成的结果。 显示对比度损失和不均匀的亮度失真(图 5)。 在图5(e1)中,云区域存在亮度畸变。 与其他区域相比,气球之间的云区域显得更暗。 这种失真也可以在其他测试图像中观察到,如图 5(e2)所示。 然而,DeepFuse(图 5(f1) 和 (f2))已经学会在没有任何这些伪影的情况下生成结果。
与马等人的比较。 [14]:图6和7显示了Ma等人的结果之间的比较。 以及用于 Lighthouse 和 Table 序列的 DeepFuse。 马等人。 提出了一种基于补丁的融合算法,该算法根据输入图像的补丁强度融合补丁。 补丁强度是使用每个补丁的功率加权函数来计算的。 这种加权方法会沿边缘引入令人不快的光晕效应(见图 6 和 7)。
与拉曼等人的比较。 [20]:图3(f)显示了Raman等人的融合结果。 对于众议院序列。 结果表现出颜色失真和对比度损失。 相比之下,所提出的方法产生的结果具有鲜艳的色彩质量和更好的对比度。
通过主观和客观评估检查结果后,我们发现我们的方法能够忠实地再现输入对中的所有特征。 我们还注意到 DeepFuse 获得的结果没有诸如较暗区域和不匹配颜色之类的伪影。 我们的方法保留了更精细的图像细节以及更高的对比度和鲜艳的色彩。 表2中所提出的方法与现有方法之间的定量比较也表明,所提出的方法在大多数测试序列中都优于其他方法。 从表 3 中显示的执行时间我们可以观察到我们的方法比 Mertens 等人的方法大约快 3-4 倍。 通过在合并层之前添加额外的流,DeepFuse 可以轻松扩展到更多输入图像。 我们已经针对包含 3 个和 4 个图像的序列训练了 DeepFuse。 对于具有 3 个图像的序列,DF 的平均 MEF SSIM 得分为 0.987,Mertens 等人为 0.979。 对于具有 4 个图像的序列,DF 的平均 MEF SSIM 得分为 0.972,Mertens 等人的平均 MEF SSIM 得分为 0.978。 对于具有 4 个图像的序列,我们将性能下降归因于训练数据不足。 通过更多的训练数据,DF 也可以被训练得在这种情况下表现得更好。
4.3. Application to Multi-Focus Fusion
在本节中,我们讨论应用 DeepFuse 模型解决其他图像融合问题的可能性。 由于当今相机的景深有限,只有有限深度范围内的物体被聚焦,其余区域显得模糊。 在这种情况下,多焦点融合(MFF)技术用于融合以不同焦点拍摄的图像,以生成单个全焦点图像。 MFF 问题与 MEF 非常相似,不同之处在于输入图像的焦点变化而不是 MEF 的曝光变化。 为了测试 CNN 的泛化能力,我们使用已经训练好的 DeepFuse CNN 来融合多焦点图像,而无需针对 MFF 问题进行任何微调。 图 9 显示了 DeepFuse 在公开的多焦点数据集上的结果表明 CNN 的滤波器已经学会识别每个输入图像中的适当区域并成功地将它们融合在一起。 还可以看出,学习到的 CNN 滤波器是通用的,可以应用于一般的图像融合。
5. Conclusion and Future work
在本文中,我们提出了一种方法,可以有效地融合一对具有不同曝光级别的图像,以产生无伪影且令人愉悦的输出。 DeepFuse 是第一个执行静态 MEF 的无监督深度学习方法。 所提出的模型从每个输入图像中提取一组常见的低级特征。 所有输入图像的特征对通过合并层融合成单个特征。 最后,将融合后的特征输入到重建层,得到最终的融合图像。 我们使用大量在不同设置下捕获的曝光堆栈来训练和测试我们的模型。 此外,我们的模型无需针对不同的输入条件进行参数微调。 最后,通过广泛的定量和定性评估,我们证明所提出的架构在各种输入场景中都比最先进的方法表现更好。
总之,DF 提供的优点如下: 1)更好的融合质量:即使对于极端曝光的图像对也能产生更好的融合结果,2)SSIM 优于 ℓ1 :在[29]中,作者报告 ℓ1 损失优于 SSIM 损失函数 。 在他们的工作中,作者实现了 SSIM 的近似版本,并发现它的性能低于 ℓ1。 我们已经实现了精确的 SSIM 公式,并观察到 SSIM 损失函数的表现比 MSE 和 ℓ1 好得多。 此外,我们还表明,在缺乏真实数据的情况下,复杂的感知损失(例如 MEF SSIM)可以成功地与 CNN 合并。 结果鼓励研究界检查其他感知质量指标,并将其用作损失函数来训练神经网络。 3)对其他融合任务的通用性:所提出的融合本质上是通用的,并且也可以很容易地适应其他融合问题。 在我们当前的工作中,DF 被训练来融合静态图像。 对于未来的研究,我们的目标是推广 DeepFuse,将图像与物体运动融合。
code
model.py
import torch.nn as nn
import torch
"""
This script defines the DeepFuse model and related module
Author: SunnerLi
"""
# -------------------------------------------------------------------------------------------------------
# Define layers
# -------------------------------------------------------------------------------------------------------
class ConvLayer(nn.Module):
def __init__(self, in_channels = 1, out_channels = 16, kernel_size = 5, last = nn.ReLU):
super().__init__()
if kernel_size == 5:
padding = 2
elif kernel_size == 7:
padding = 3
self.main = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size = kernel_size, stride = 1, padding = padding),
nn.BatchNorm2d(out_channels),
last()
)
def forward(self, x):
out = self.main(x)
return out
class FusionLayer(nn.Module):
def forward(self, x, y):
return x + y
# -------------------------------------------------------------------------------------------------------
# Define model
# -------------------------------------------------------------------------------------------------------
class DeepFuse(nn.Module):
def __init__(self, device = 'cpu'):
super().__init__()
self.layer1 = ConvLayer(1, 16, 5, last = nn.LeakyReLU)
self.layer2 = ConvLayer(16, 32, 7)
self.layer3 = FusionLayer()
self.layer4 = ConvLayer(32, 32, 7, last = nn.LeakyReLU)
self.layer5 = ConvLayer(32, 16, 5, last = nn.LeakyReLU)
self.layer6 = ConvLayer(16, 1, 5, last = nn.Tanh)
self.device = device
self.to(self.device)
def setInput(self, y_1, y_2):
self.y_1 = y_1
self.y_2 = y_2
def forward(self):
c11 = self.layer1(self.y_1[:, 0:1])
c12 = self.layer1(self.y_2[:, 0:1])
c21 = self.layer2(c11)
c22 = self.layer2(c12)
f_m = self.layer3(c21, c22)
c3 = self.layer4(f_m)
c4 = self.layer5(c3)
c5 = self.layer6(c4)
return c5loss.py
from math import exp
import torch.nn.functional as F
import torch.nn as nn
import torch
"""
This script defines the MEF-SSIM loss function which is mentioned in the DeepFuse paper
The code is heavily borrowed from: https://github.com/Po-Hsun-Su/pytorch-ssim
Author: SunnerLi
"""
L2_NORM = lambda b: torch.sqrt(torch.sum((b + 1e-8) ** 2))
class MEF_SSIM_Loss(nn.Module):
def __init__(self, window_size = 11, size_average = True):
"""
Constructor
"""
super().__init__()
self.window_size = window_size
self.size_average = size_average
self.channel = 1
self.window = self.create_window(window_size, self.channel)
def gaussian(self, window_size, sigma):
"""
Get the gaussian kernel which will be used in SSIM computation
"""
gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
return gauss/gauss.sum()
def create_window(self, window_size, channel):
"""
Create the gaussian window
"""
_1D_window = self.gaussian(window_size, 1.5).unsqueeze(1)
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()
return window
def _ssim(self, img1, img2, window, window_size, channel, size_average = True):
"""
Compute the SSIM for the given two image
The original source is here: https://stackoverflow.com/questions/39051451/ssim-ms-ssim-for-tensorflow
"""
mu1 = F.conv2d(img1, window, padding = window_size//2, groups = channel)
mu2 = F.conv2d(img2, window, padding = window_size//2, groups = channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1*mu2
sigma1_sq = F.conv2d(img1*img1, window, padding = window_size//2, groups = channel) - mu1_sq
sigma2_sq = F.conv2d(img2*img2, window, padding = window_size//2, groups = channel) - mu2_sq
sigma12 = F.conv2d(img1*img2, window, padding = window_size//2, groups = channel) - mu1_mu2
C1 = 0.01**2
C2 = 0.03**2
ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
if size_average:
return ssim_map.mean()
else:
return ssim_map.mean(1).mean(1).mean(1)
def w_fn(self, y):
"""
Return the weighting function that MEF-SSIM defines
We use the power engery function as the paper describe: https://ece.uwaterloo.ca/~k29ma/papers/15_TIP_MEF.pdf
Arg: y (torch.Tensor) - The structure tensor
Ret: The weight of the given structure
"""
out = torch.sqrt(torch.sum(y ** 2))
return out
def forward(self, y_1, y_2, y_f):
"""
Compute the MEF-SSIM for the given image pair and output image
The y_1 and y_2 can exchange
Arg: y_1 (torch.Tensor) - The LDR image
y_2 (torch.Tensor) - Another LDR image in the same stack
y_f (torch.Tensor) - The fused HDR image
Ret: The loss value
"""
miu_y = (y_1 + y_2) / 2
# Get the c_hat
c_1 = L2_NORM(y_1 - miu_y)
c_2 = L2_NORM(y_2 - miu_y)
c_hat = torch.max(torch.stack([c_1, c_2]))
# Get the s_hat
s_1 = (y_1 - miu_y) / L2_NORM(y_1 - miu_y)
s_2 = (y_2 - miu_y) / L2_NORM(y_2 - miu_y)
s_bar = (self.w_fn(y_1) * s_1 + self.w_fn(y_2) * s_2) / (self.w_fn(y_1) + self.w_fn(y_2))
s_hat = s_bar / L2_NORM(s_bar)
# =============================================================================================
# < Get the y_hat >
#
# Rather to output y_hat, we shift it with the mean of the over-exposure image and mean image
# The result will much better than the original formula
# =============================================================================================
y_hat = c_hat * s_hat
y_hat += (y_2 + miu_y) / 2
# Check if need to create the gaussian window
(_, channel, _, _) = y_hat.size()
if channel == self.channel and self.window.data.type() == y_hat.data.type():
window = self.window
else:
window = self.create_window(self.window_size, channel)
window = window.to(y_f.get_device())
window = window.type_as(y_hat)
self.window = window
self.channel = channel
# Compute SSIM between y_hat and y_f
score = self._ssim(y_hat, y_f, window, self.window_size, channel, self.size_average)
return 1 - score, y_hat
















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









