







有监督问题模型

1. 信息量与熵
1.1 自信息量
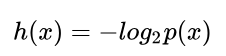
1.2 熵

自信息量与熵请参考信息量与熵_mjiansun的博客-CSDN博客_信息量与熵
举个例子

1.2.1 均匀分布的信息熵

2. 决策树
2.1 基本流程



这里我不推荐先看图4.2的流程。因为他不够直观,可以先看后面的内容。

2.2 划分选择(确定划分所依据的属性)

信息熵他只与真实值Y和当前节点的总数相关。
当前节点的类别看当前节点内占多数样本的类别。
2.2.1 ID3方法
ID3方法主要试用了信息增益,针对每一个属性,都计算信息增益Gain,选择信息增益最大的属性(其实就是提供的信息量最多)作为划分属性。


例子



2.2.2 C4.5方法
信息增益率Gain_ratio越大,表明该属性提供的信息越大,越应该选择该属性。
C4.5是计算每一个属性的信息增益和信息增益率,然后取大于信息增益平均值的属性,再从这些属性中选取信息增益率最大的属性作为划分属性。

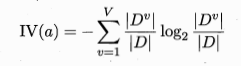



2.2.3 CART(classification and regression)决策树
计算每个属性的Gini指数,选择基尼指数最小的属性作为划分属性。


2.3 剪枝处理
剪枝处理共分为预剪枝和后剪枝。
预剪枝:在训练的时候,使用验证集验证每一个节点是否能会给验证集的准确率带来提升,如果不能,则该节点不再向下分枝。
后剪枝:模型训练结束后,针对模型的分枝自底向上用验证集来检查该属性值是否能给验证集准确率带来提升。如果准确率未提升,则删除当前节点依据该属性划分的叶节点。

2.3.1 预剪枝
 :
:





2.3.2 后剪枝


2.4 连续与缺失值
2.4.1 连续值处理
连续值属性可以多次使用,这就与离散值属性不同,离散值属性只能使用一次。




我写的代码用于验证连续值Gain信息增益的计算:
import numpy as np def ComputeEnt(data, clsSet, eps=1e-8): allLen = len(data) firstLen = len(np.where(data == clsSet[0])[0]) secondLen = len(np.where(data == clsSet[1])[0]) entropy = -(firstLen / allLen + eps) * np.log2(firstLen / allLen + eps) + \ -(secondLen / allLen + eps) * np.log2(secondLen / allLen + eps) return entropy if __name__=="__main__": # data = {0.697: True, 0.774: True, 0.634: True, 0.608: True, 0.556: True, 0.403: True, 0.481: True, 0.437: True, 0.666: False, 0.243: False, 0.245: False, 0.343: False, 0.639: False, 0.657: False, 0.36: False, 0.593: False, 0.719: False} x = [0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.481, 0.437, 0.666, 0.243, 0.245, 0.343, 0.639, 0.657, 0.360, .593, 0.719] y = ["是","是","是","是","是","是","是","是","否","否","否","否","否","否","否","否","否"] # only support cls 2 clsSet = list(set(y)) assert len(clsSet) == 2 x = np.array(x) y = np.array(y) index = np.argsort(x) _keys = x[index] _values = y[index] thrs = [] if len(_keys) > 1: for i in range(1, len(_keys)): thrs.append((_keys[i-1]+_keys[i])/2) _entropyAdd = [] rootEnt = ComputeEnt(_values, clsSet) for i, thr in enumerate(thrs): # np.where(_keys<=thr)[0] leftSet = _values[:i+1] rightSet = _values[i+1:] firstEnt = ComputeEnt(leftSet, clsSet) secondEnt = ComputeEnt(rightSet, clsSet) curEnt = len(leftSet)/len(_values) * firstEnt + len(rightSet)/len(_values) * secondEnt _entropyAdd.append(rootEnt-curEnt) _entropyAdd = np.array(_entropyAdd) maxIndex = np.argmax(_entropyAdd) maxEntAdd = _entropyAdd[maxIndex] maxThr = thrs[maxIndex] print(maxEntAdd, maxThr)
2.4.2 缺失值处理


部分属性缺失面对的2个问题:
(1)由于有缺失值,怎么确定划分属性?
(2)假设(1)解决了,确定了划分属性,但是由于有部分样本该属性值缺失,这部分样本该如何处理?




针对第二个问题,我做一点解释:
根据公式4.9~4.11知道了这三个值都是根据权重算出来的(默认权重值为1),例如上述的{8}会按照7/15,5/15,3/15进入三个分支。
此时我们选择第三个分支继续划分,当前分支中包含了{8,11,12,16},对应的权重为{3/15,1,1,1}。假设我们选择触感作为划分属性:
8 11 12 16 硬滑 - 软黏 硬滑 是 否 否 否 3/15 1 1 1 具体的数值都在上表中。
信息熵为
每个属性对应的信息熵
信息增益


2.5 多变量决策树(方法具体不清楚,我自己也没怎么懂)





















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









