







本质上就是将标签变得平滑,让预测的结果不那么相信所属的类别,起到增强鲁棒性的作用。
标签平滑的想法首先被提出用于训练 Inception-v2 [26]。它将真实概率的构造改成:
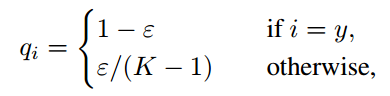
其中ε是一个小常数,K 是标签总数量。

图 4:ImageNet 上标签平滑效果的可视化。顶部:当增加ε时,目标类别与其它类别之间的理论差距减小。下图:最大预测与其它类别平均值之间差距的经验分布。很明显,通过标签平滑,分布中心处于理论值并具有较少的极端值。
import torch
import torch.nn as nn
class NMTCritierion(nn.Module):
"""
TODO:
1. Add label smoothing
"""
def __init__(self, label_smoothing=0.0):
super(NMTCritierion, self).__init__()
self.label_smoothing = label_smoothing
self.LogSoftmax = nn.LogSoftmax()
if label_smoothing > 0:
self.criterion = nn.KLDivLoss(size_average=False)
else:
self.criterion = nn.NLLLoss(size_average=False, ignore_index=100000)
self.confidence = 1.0 - label_smoothing
def _smooth_label(self, num_tokens):
# When label smoothing is turned on,
# KL-divergence between q_{smoothed ground truth prob.}(w)
# and p_{prob. computed by model}(w) is minimized.
# If label smoothing value is set to zero, the loss
# is equivalent to NLLLoss or CrossEntropyLoss.
# All non-true labels are uniformly set to low-confidence.
one_hot = torch.randn(1, num_tokens)
one_hot.fill_(self.label_smoothing / (num_tokens - 1))
return one_hot
def _bottle(self, v):
return v.view(-1, v.size(2))
def forward(self, dec_outs, labels):
scores = self.LogSoftmax(dec_outs)
num_tokens = scores.size(-1)
# conduct label_smoothing module
gtruth = labels.view(-1)
if self.confidence < 1:
tdata = gtruth.detach()
one_hot = self._smooth_label(num_tokens) # Do label smoothing, shape is [M]
if labels.is_cuda:
one_hot = one_hot.cuda()
tmp_ = one_hot.repeat(gtruth.size(0), 1) # [N, M]
tmp_.scatter_(1, tdata.unsqueeze(1), self.confidence) # after tdata.unsqueeze(1) , tdata shape is [N,1]
gtruth = tmp_.detach()
loss = self.criterion(scores, gtruth)
return loss














 2237
2237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









