






Feature Enhancement Network: A Refined Scene Text Detector
- intro: AAAI 2018
- arxiv: https://arxiv.org/abs/1711.04249
创新点:
1.现有问题:只利用3×3的滑动窗口特征和利用高维度的特征对目标检测窗口进行精修,对于小的场景文字来说是不够的。
创新点:提出Feature Enhancement Network,对高维度和低维度的语义特征进行融合。
2.现有问题:普通目标检测只有单一权重的position-sensitive RoI Pooling layer。
创新点:提出自适应权重(adaptively weighted)的 position-sensitive RoI pooling layer。
3.现有问题:如何解决在精修阶段的样本不平衡问题?
创新点:提出正样本挖掘策略(positives mining strategy)。
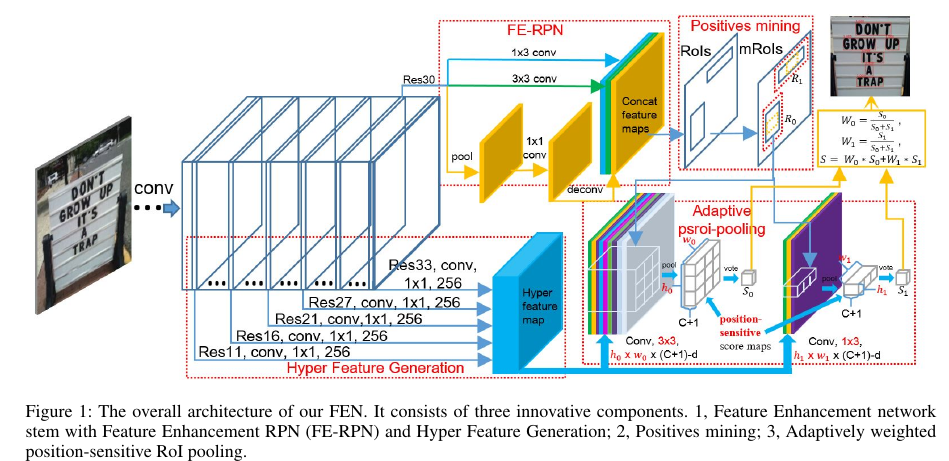
Feature Enhancement RPN:
1.单词的宽度大于高度,因此aspect ratio大于1。
2.高维的语义特征的感受野更大,拥有更多的上下文信息,便于区分前景目标和背景目标。
FE-RPN实现:
1.输入:Res30
2.连接两个分支,1)text-characteristic 和 task-specific的1×3卷积层;2)max pooling layer + 1×1convolution + deconvolution 层
3.将传统的3×3滑动窗口卷积特征与上述两层的输出进行连接。
4.最后,利用一个ResNet block进行特征增强。
Hyper Feature Generation
1)只利用高维度的语义特征会丢失细节信息,不利于小文本行的检测。
2)利用来自中间层的低维度的语义特征,可以较好的维持细节特征。
也就是,高维度的语义信息利于目标分类,而低维度的语义信息利于对目标进行精确定位。
思路借鉴:HyperNet
将来自不同中间层的特征压缩到bottleneck的卷积层的channel中
Text Proposals Generation
Text characteristic anchor design:
scales设计:32, 64, 112, 192, 304, 416
aspect ratios设计:1, 2, 3, 4, 6
很明显,有的anchor不太可能,例如scales为416,as为6,因为超出了图片边界。
因此,在FE-RPN的sub-network中的feature enhancement map中的每个点上,人工选择a=24个anchor。
Positive Mining:
1)在原有的origin proposals的基础上,对其进行扩展,生成两个额外的proposals,为原来的proposal的大小的0.7倍和1.3倍。
2)在排名前50的origin positive proposals只选取前15个,再对这15个proposals进行扩展。
Text Detection Refinement
Adaptively Weighted Position-Sensitive RoI Pooling

在池化的时候,不是单一的7×7格子,而是设计了四种池化方式:3×3,7×7,3×8,3×11,选取得分最高的池化方法。
量化评估:
1)FENS: 3% on recall rate,5% on F-measure
2)Positive Mining: 0.5% on F-measure
3)Adaptively weighted position-sensitive RoI Pooling: 1.9 on F-measure















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









