









目录
1. 背景
在当今数字化时代,文档版式分析是信息提取和文档理解的关键步骤之一。文档版式分析,也称为文档图像分析或文档布局分析,是指从扫描的文档图像中识别和提取文本、图像、表格和其他元素的过程。这项技术在自动化文档处理、电子数据交换、历史文档数字化等领域有着广泛的应用。
传统的文档版式分析模型往往难以准确区分文档中的段落和其他布局元素,这限制了文档信息的进一步处理和利用,而深度学习和模式识别技术的发展为文档版式分析带来了新的机遇,通过训练数据集,可以提高模型对文档结构的理解能力,但高质量的标注数据集是训练有效模型的基础。
在文档版式分析中,精细化的标注非常有必要,其中:段落的标注尤其关键,因为它直接影响到文本的语义理解和信息提取。当前,在版式分析领域,据我们了解,在论文场景中,以往的开源数据集如:CDLA(A Chinese document layout analysis),缺乏对段落信息的标注;在研报场景中的版式分析模型还相对空缺。
在大语言模型应用开发中,我们往往会用到RAG技术, 但读取的文件包含图片时,传统技术是直接通过OCR(Optical Character Recognition,光学字符识别)技术读取文字,但这里会有个弊端, 如低分辨率图像、模糊图像和多语言混合文本中, 特别是文本划分负责,OCR技术的识别准确性大大减弱。这时,我们就需要文档布局分析来模仿人眼看到的区域,再对区域内的文字进行提取。
这篇文章主要以360LayoutAnalysis的文档布局分析开源模型来对文档布局分析进行0基础学习。
2. 模型介绍
360AI通过人工标注的方式对论文文档进行细粒度标签改造以及数据优化,并构建起研报场景细粒度版式分析数据集,训练了多个全新的中文文档版式分析模型。
下载方式可以直接到Hugging Face下载: https://huggingface.co/qihoo360/360LayoutAnalysis/tree/main
如果嫌翻墙麻烦可以直接到我CSDN资源免费下载:LayoutAnalysis
| 模型权重 | 场景 | 标签类别 | |||
| paper-8n.pt | 中文论文场景 | Text:正文(段落) Title:标题 Figure:图片 Figure caption:图片标题 Table:表格 Table caption:表格标题 Header:页眉 Footer:页脚 Reference:注释 Equation:公式 | |||
| report-8n.pt | 中文研报场景 | Text:正文(段落) Title:标题 Figure:图片 Figure caption:图片标题 Table:表格 Table caption:表格标题 Header:页眉 Footer:页脚 Toc:目录 | |||
| publaynet-8n.pt | 英文论文场景 | text:正文 title:标题 list:列表 table:表格 figure:图片 | |||
| general6-8n.pt | 通用场景 | 元素:名称 Text:正文 Title:标题 Figure:图片 Table:表格 Equation:公式 Caption:表/图标题 | |||
| jiaocai-8n.pt | 教材场景 | 目录:catalogue 页脚:footer 脚注:footnote 章标题:chapter title 小节标题:subsection title 小标题:subhead 段落:paragraph 无序列表:unordered list 表格:table 图片:figure 代码:code 页眉:header 页码:page number 索引标签:index 节标题:section title 标题:headline 其他标题:other title 公式:formula 有序列表:ordered list 表注:table caption 图注:figure caption 代码注释:code caption |
2. 1 中文论文场景(paper-8n.pt)

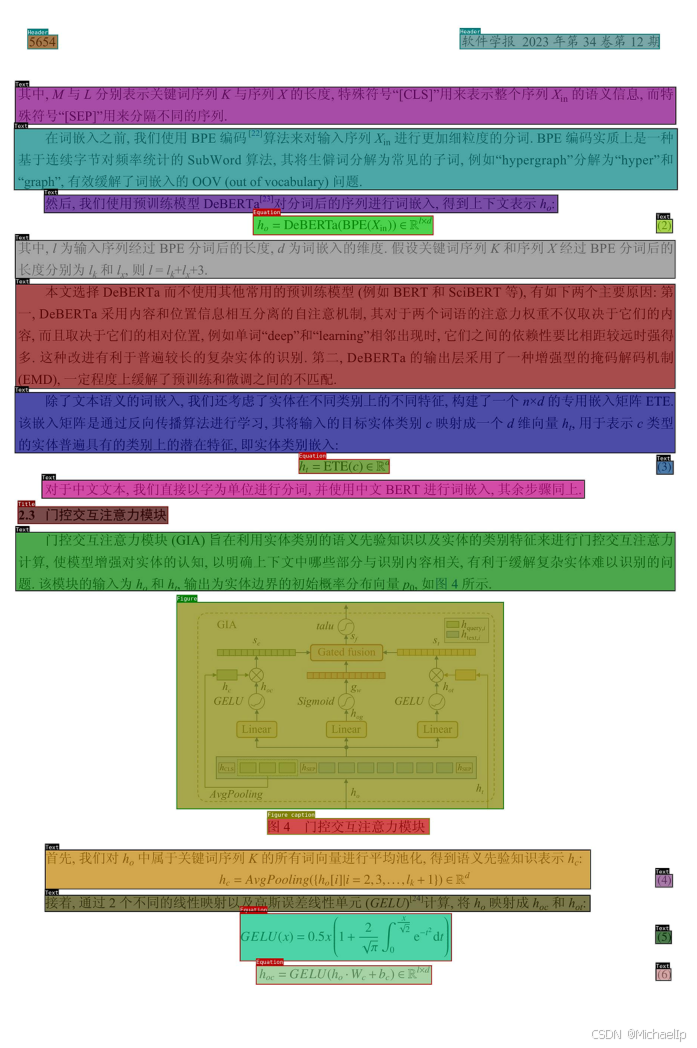
2. 2 中文研报场景(report-8n.pt)

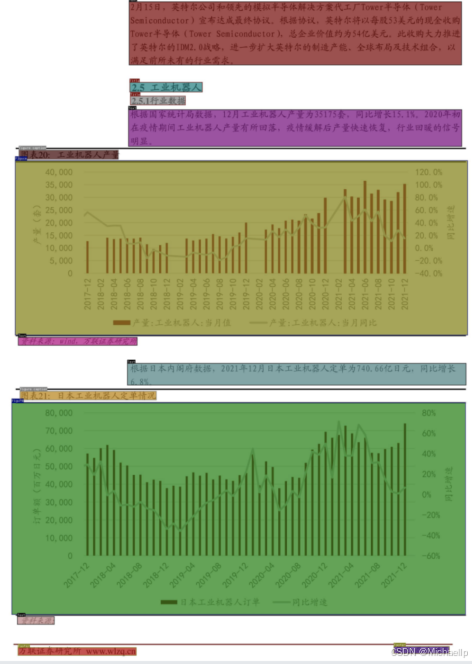
2. 3 英文论文场景(publaynet-8n.pt)


3. 模型使用
调用方法也很简单,开源权重使用yolov8进行训练,我们可以yolov8模型来加载上面的模型。
下面我们用通用场景模型general6-8n.pt来进行演示。
3. 1 代码
from ultralytics import YOLO
image_path = 'test.png' # 待预测图片路径
model_path = 'general6-8n.pt' # 权重路径
model = YOLO(model_path)
result = model(image_path, save=True, conf=0.5, save_crop=False, line_width=2)
print(result)
print('names:{}'.format(result[0].names)) # 输出id2label map
print('bounding box:{}'.format(result[0].boxes)) # 输出所有的检测到的bounding box
print('bounding box的左上和右下坐标:{}'.format(result[0].boxes.xyxy)) # 输出所有的检测到的bounding box的左上和右下坐标
print('bounding box类别对应的id:{}'.format(result[0].boxes.cls)) # 输出所有的检测到的bounding box类别对应的id
print('bounding box的置信度:{}'.format(result[0].boxes.conf)) # 输出所有的检测到的bounding box的置信度
测试图片,这是我谋篇文章的截图。

从图片可以看到,我们的文字分布极不均匀。
3. 1 运行代码
names: {0: 'Text', 1: 'Title', 2: 'Figure', 3: 'Table', 4: 'Caption', 5: 'Equation'}
bounding box的左上和右下坐标:tensor([[ 361.1839, 312.3868, 1328.6422, 385.8313],
[ 358.9572, 542.7421, 1319.7097, 588.2485],
[ 358.7808, 722.4692, 1325.1667, 795.4191],
[ 360.1758, 654.6621, 1326.4425, 700.4989],
[ 358.0524, 406.7491, 1326.4907, 451.8774],
[ 361.4114, 122.1360, 1320.8865, 193.5496],
[ 358.1216, 474.3237, 1327.0160, 520.1252],
[ 361.8612, 34.9993, 585.8664, 57.1699],
[ 44.2345, 725.2685, 312.2520, 786.0486],
[ 44.3943, 799.5723, 312.1590, 859.0953],
[ 362.0706, 88.0690, 764.5432, 107.6991],
[ 361.4779, 278.8552, 581.6951, 298.5094],
[ 45.0759, 372.3931, 312.8468, 411.0162],
[ 361.4462, 200.5699, 1324.1534, 247.4349],
[ 45.1576, 650.9905, 312.8714, 712.4406],
[ 44.1687, 426.8352, 307.8191, 464.9413],
[ 44.4814, 318.3806, 309.0818, 357.1922],
[ 45.9431, 599.9932, 309.3593, 637.6458],
[ 45.3699, 287.2047, 257.9633, 302.9389],
[ 361.1960, 620.4774, 672.5446, 641.0566],
[ 45.5600, 480.3405, 320.8538, 497.8641],
[ 19.0427, 0.0000, 336.6156, 215.3905]])
bounding box类别对应的id:tensor([0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 2.])
bounding box的置信度:tensor([0.9138, 0.9034, 0.9005, 0.9004, 0.8877, 0.8863, 0.8844, 0.8571, 0.8544, 0.8533, 0.8528, 0.8127, 0.8105, 0.7736, 0.7461, 0.7273, 0.7121, 0.6893, 0.6637, 0.6135, 0.5808, 0.5139])
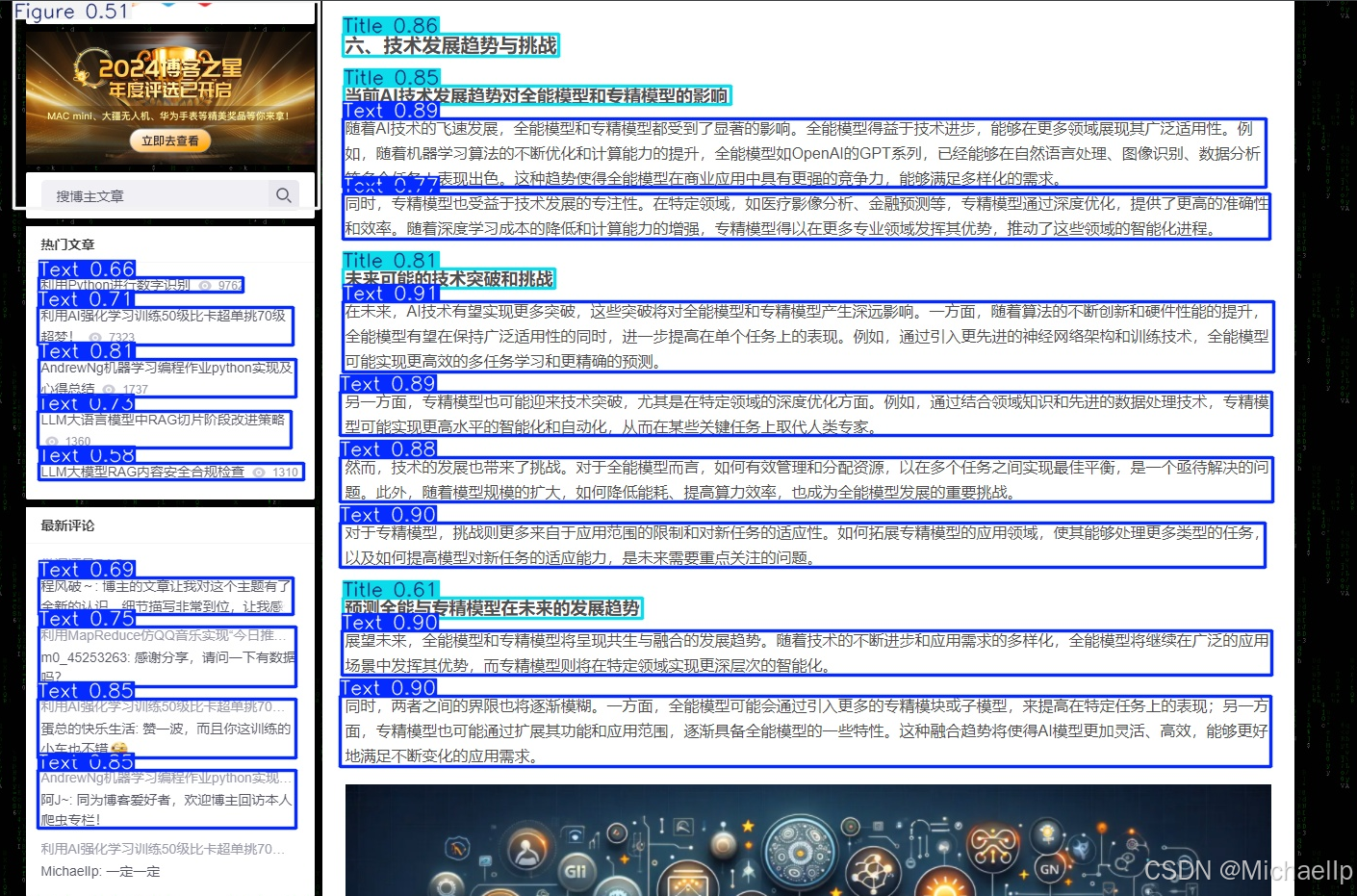
可以看出,模型能正确识别标题,内容,图片。这时再结合OCR模型就能清晰识别到想要的内容。
4. Referrence
https://github.com/360AILAB-NLP/360LayoutAnalysis?tab=readme-ov-file

















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









