









本文来源公众号“OpenMMLab”,仅用于学术分享,侵权删,干货满满。
原文链接:DocLayout-YOLO,让多样性文档布局检测更快、更准、更强
本文转载自OpenDataLab
布局检测是文档解析领域的核心任务之一,目标是精准定位文档中不同类型的元素(正文、标题、表格、图片等)。尽管布局检测已经研究很多年,但现有的布局检测算法多关注在论文类型的文档,当面对多样性的文档(如教材、考题、研报等)时,其检测效果还是不及预期。
上海人工智能实验室在2024年7月份开源的 PDF-Extract-Kit 中提供了使用多样性文档微调的 LayoutLMv3 模型,在众多类型的文档上均取得了不错效果,但其推理速度相对较慢。为了满足实时高质量的推理需求,作者团队近日推出全新布局检测模型 DocLayout-YOLO,其推理速度相比于LayoutLMv3提升一个数量级,在A100上每秒可以处理85.5个页面,检测结果也更加精准。一起来看看。
DocLayout-YOLO GitHub主页:
https://github.com/opendatalab/DocLayout-YOLO
DocLayout-YOLO 论文:
https://arxiv.org/abs/2410.12628
DocLayout-YOLO Demo体验:
https://huggingface.co/spaces/opendatalab/DocLayout-YOLO
1 DocLayout-YOLO技术解析
DocLayout-YOLO 基于YOLOv10模型,并从多样性文档预训练和模型结构优化方面对布局检测模型进行优化。
● 多样性文档预训练:DocLayout-YOLO文章中提出Mesh-candidate Bestfit算法,自动合成多样性的文档布局检测数据集DocSynth-300K,大幅提升模型在多样性文档上检测的鲁棒性;
● 检测结构优化:模型结构方面,针对文档元素尺度变化多样的特性,提出全局到局部的可控感知模块,更加灵活适配不同尺度元素,有效提升YOLO框架对文档元素检测效果。
创新点1:基于Mesh-candidate Bestfit的多样性文档合成
当前的布局检测数据集类型较为单一,多数集中于论文文档,例如PubLayNet和DocBank。相比之下,其他类型的文档数据集(如DocLayNet、D4LA、M6Doc)数据量较小,仅适用于下游任务的微调和测试,而不适合用于预训练。为了解决这一问题,DocLayout-YOLO项目引入了Mesh-candidate Bestfit算法。该算法将文档布局合成视作二维矩形拼图问题,通过在文档中不断搜索候选元素(candidate)和空闲块(mesh)的最佳匹配,生成多样化且美观的文档图像。具体的合成流程可以参考论文中的图1(DocSynth-300K文档数据合成流程图)。
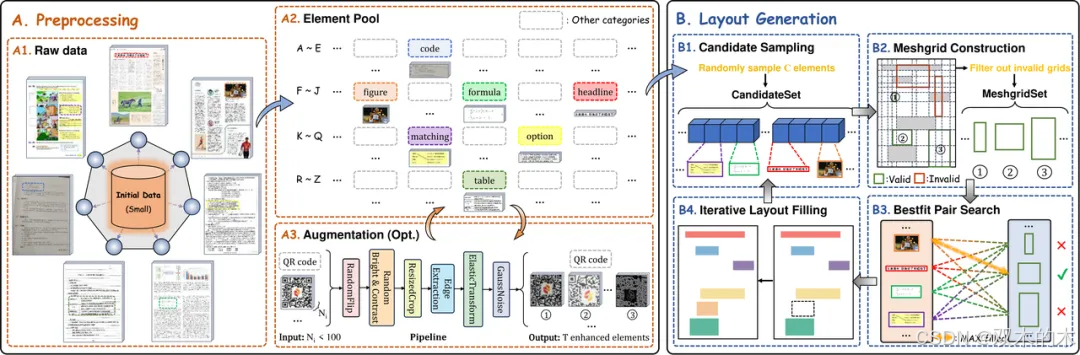
图1 DocSynth-300K文档数据合成流程图
合成的数据集在风格上多样且视觉真实度高。布局方面,涵盖了单栏、双栏以及多栏混合文档;在文档风格上,包括论文、报纸、杂志等多种类型的页面。DocSynth-300K和现有文档布局检测预训练数据集相比,样式更加多样化,经过DocSynth-300K预训练的模型在多种下游实际文档类型也体现出更强的泛化性。

图2 DocSynth-300K数据样例
目前DocSynth300K数据集已经上线OpenDataLab,
DocSynth300K数据集:
https://opendatalab.com/zzy8782180/DocSynth300K
预训练模型可以在🤗Huggingface获取:
https://huggingface.co/juliozhao/DocLayout-YOLO-DocSynth300K-pretrain
DocSynth300K和预训练模型下载方法如下:
snapshot_download(repo_id="juliozhao/DocSynth300K", repo_type="dataset")
创新点2:提出基于全局到局部的可控感知模块
针对文档图像中的尺寸变化挑战,DocLayout-YOLO中提出了GL-CRM,结合灵活可控制的特征提取模块(CRM)以及从全局到局部的特征感知架构(GL),来实现对不同尺度元素的感知增强。
具体来说,可控感知模块(Controllable Receptive Module,CRM),通过参数共享的卷积核,以及一系列不同膨胀率的分支,来提取不同粒度的上下文特征。除此之外,还通过一个特征选择模块,让模型学习到不同粒度特征的重要性程度,实现高效的特征选择和融合。

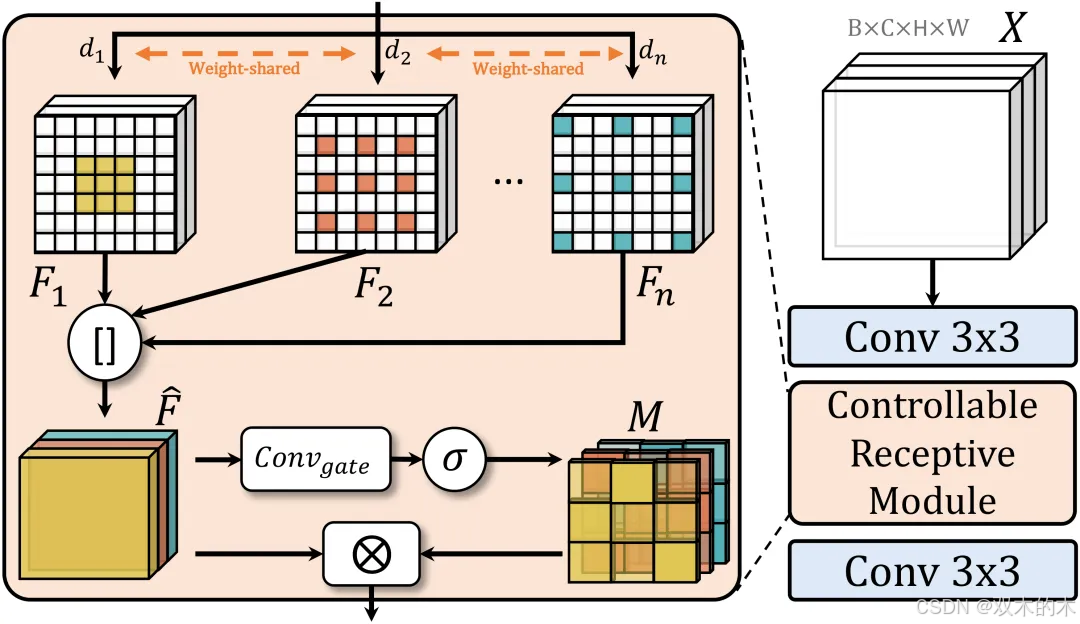
图3 可控感知模块CRM
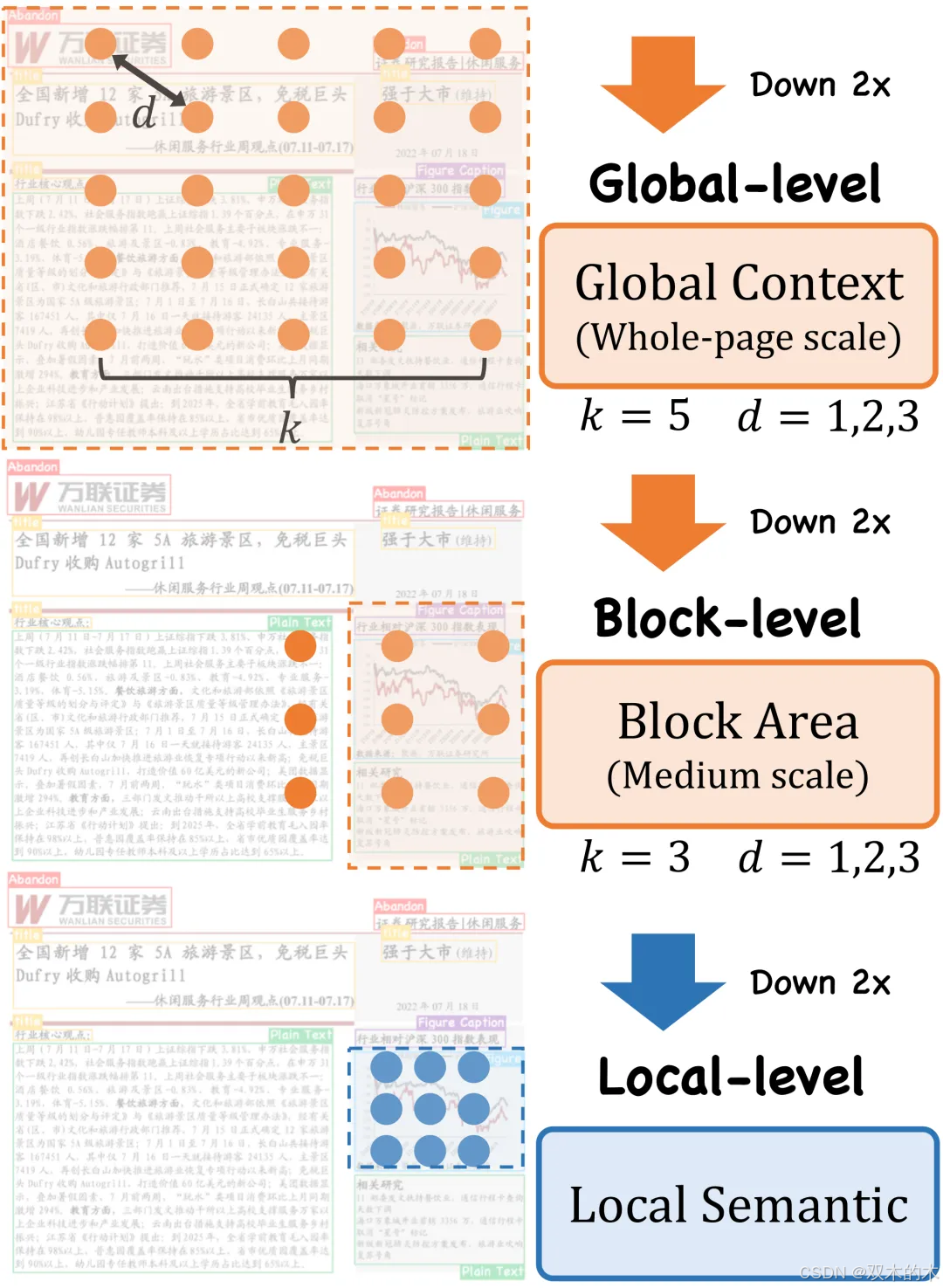
图4 全局到局部结构(GL)
2 效果展示
DocStructBench评测集上不同方法推理速度及精度对比,DocLayout-YOLO综合效果最佳。
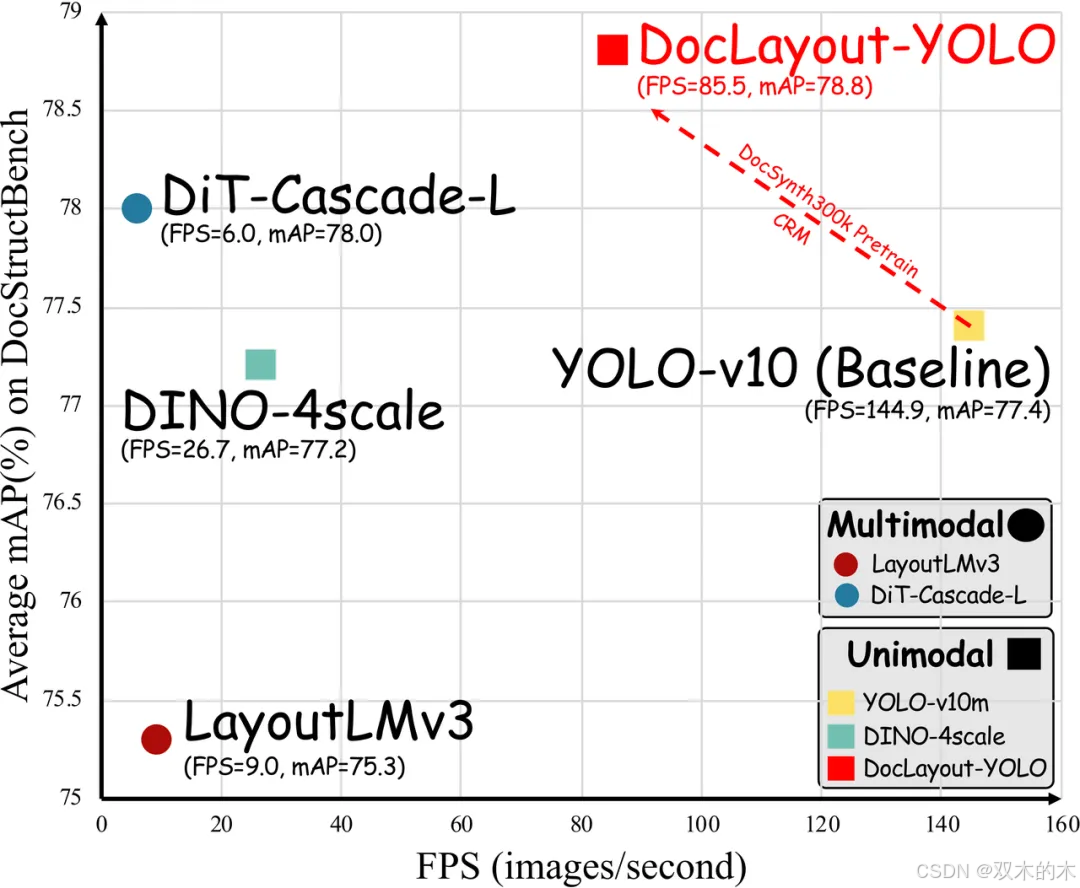
DocLayout-YOLO适用于多样性文档布局检测,包括但不局限于论文、教科书、试卷、幻灯片等多种文档类型。
如下图所示,DocLaytout-YOLO在各种类型的文档上检测效果都很好,且速度极快,可以满足真实场景实时高质量需求。

3 快速上手
如果想体验DocLayout-YOLO实际检测效果,请试用HuggingFace上的[🤗Demo]:
https://huggingface.co/spaces/opendatalab/DocLayout-YOLO
如果想批量处理文档,请安装配置DocLayout-YOLO环境。
● 方法一:根据DocLayout-YOLO GitHub项目安装配置(仅能用于页面布局检测)
pip install doclayout-yolo==0.0.2通过以下代码即可完成模型下载、加载,以及推理预测,并且保存结果:
import cv2
from doclayout_yolo import YOLOv10
# 下载并且加载模型
filepath = hf_hub_download(repo_id="juliozhao/DocLayout-YOLO-DocStructBench", filename="doclayout_yolo_docstructbench_imgsz1024.pt")
model = YOLOv10(filepath)
# 模型推理
det_res = model.predict("path/to/image", imgsz=1024, conf=0.2,device="cuda:0")
# 保存检测结果
annotated_frame = det_res[0].plot(pil=True, line_width=5, font_size=20)
cv2.imwrite("result.jpg", annotated_frame)● 方法二:使用PDF-Extract-Kit项目进行安装配置(可以使用各类SOTA文档解析算法)
先按照项目README要求安装环境,再执行以下命令即可完成基于DocLayout-YOLO的布局检测以及提取。
python scripts/layout_detection.py --config configs/layout_detection.yaml4 相关链接
DocLayout-YOLO GitHub主页:
https://github.com/opendatalab/DocLayout-YOLO
DocLayout-YOLO 论文:
https://arxiv.org/abs/2410.12628
DocLayout-YOLO Demo体验:
https://huggingface.co/spaces/opendatalab/DocLayout-YOLO
PDF-Extract-Kit (包含文档解析各类SOTA模型,使用便捷!):
https://github.com/opendatalab/PDF-Extract-Kit
MinerU (PDF转Markdown工具,超好用!):
https://github.com/opendatalab/
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









