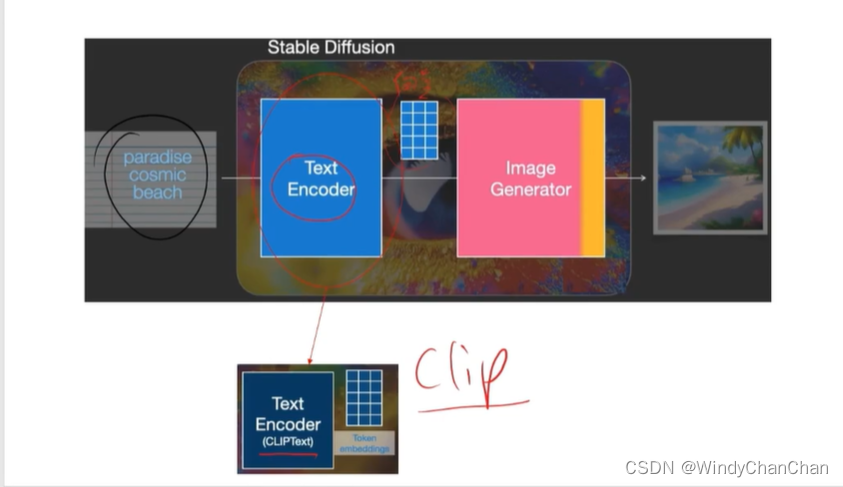
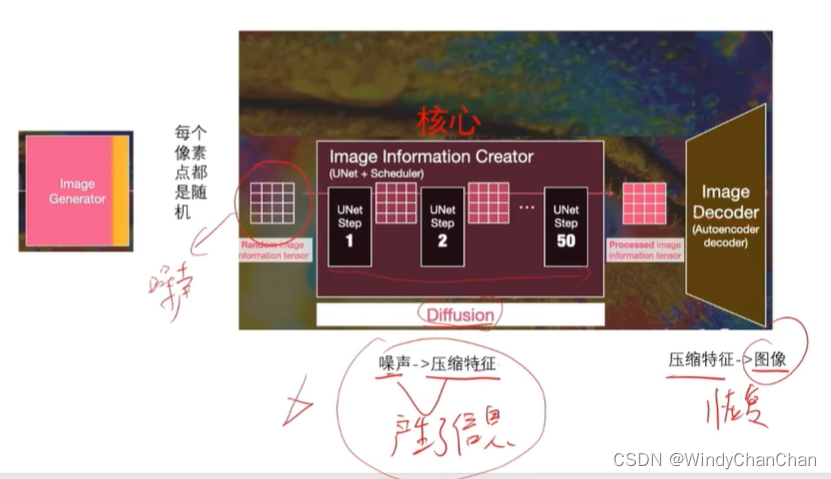
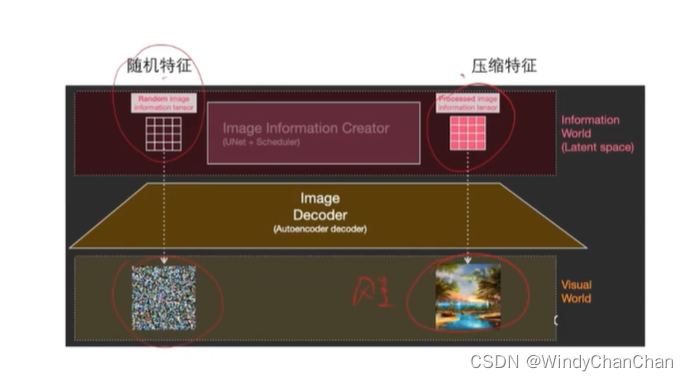
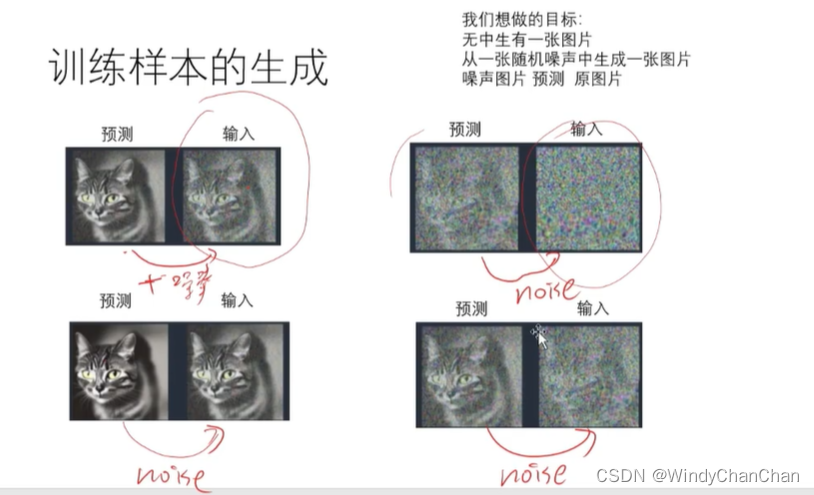
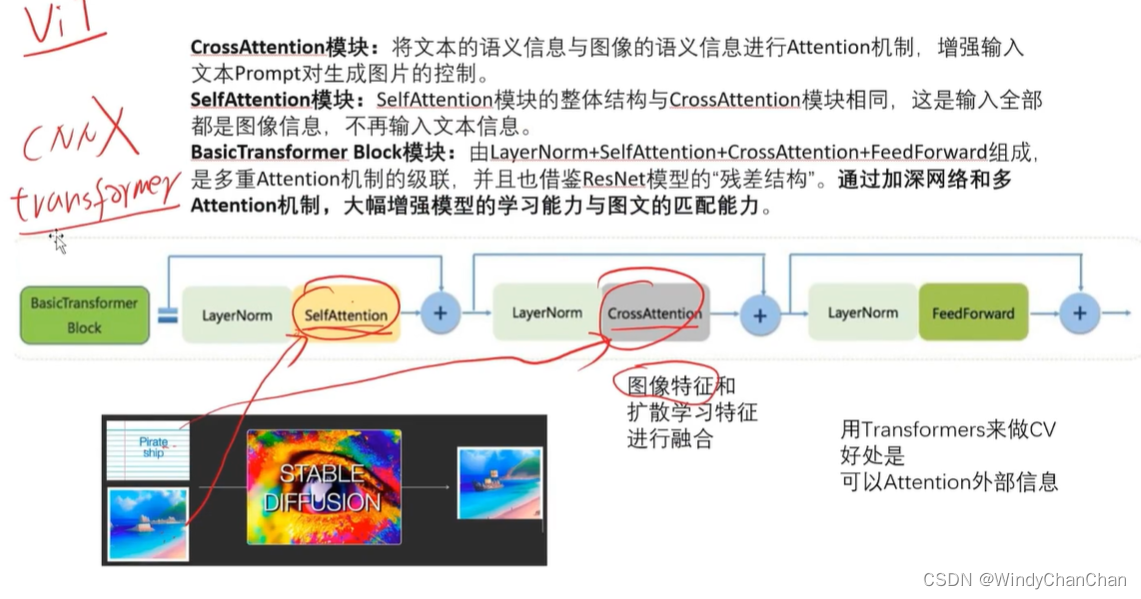
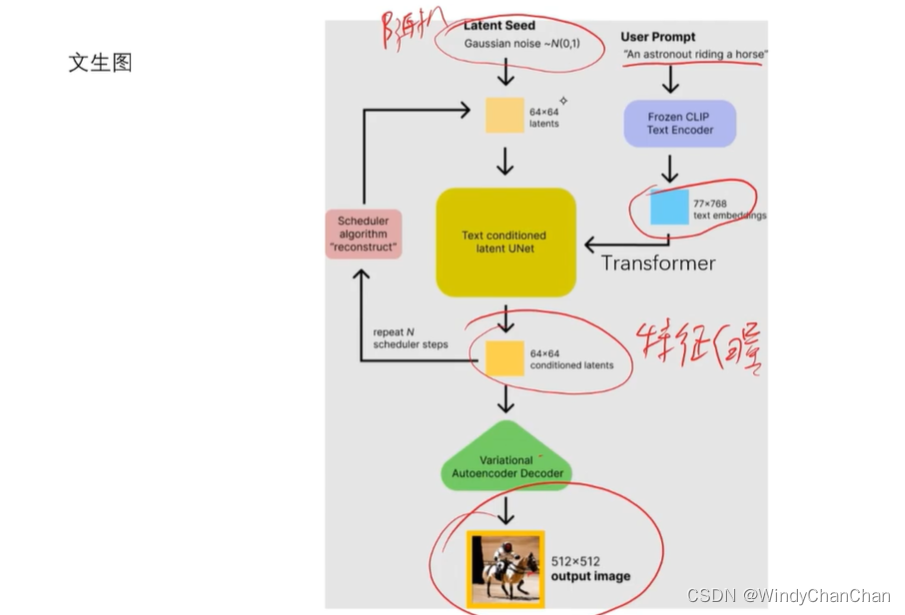
Stable Diffusion 详解







于 2024-03-10 13:55:41 首次发布
 1535
518
1535
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言