







论文
https://dl.acm.org/doi/pdf/10.1145/3219819.3219900
1. 摘要
车辆行程时间估计(ETA)是最重要的基于位置的服务之一。它作为导航系统和智能交通系统中的一项基本服务,正变得越来越重要并得到广泛的应用。提出了一种基于浮动车辆数据的车辆行驶时间预测的机器学习方法。首先,我们将ETA描述为一个基于大量有效特征的纯时空回归问题。其次,我们采用不同的机器学习模型来解决回归问题问题。而且在此基础上,提出了一种宽深度递归(WDR)学习模型来精确预测给定出发时间下沿给定路线的旅行时间。然后我们联合训练宽线性模型,
深度神经网络和递归神经网络相结合,充分利用了这三种模型的优点。我们使用数百万的历史车辆行驶数据离线评估我们的解决方案。我们还将建议的解决方案部署在滴滴初星的平台上,该平台可服务数十亿ETA请求,每天可使数百万客户受益。我们的广泛评估表明,我们提出的深度学习算法显著优于最先进的学习算法,以及领先的行业LBS提供商提供的解决方案。
近年来,共享经济的蓬勃发展正在改变着我们的生活方式生活的方方面面。一个代表是广泛使用的汽车共享和在线乘车移动应用程序重新定义了人们移动的方式。几家独角兽公司发展迅速,例如Uber、Lyft和滴滴初星,它们帮助人们高效使用车辆,每天造福数百万人。这一行业领域的迅速扩张使得定位成为可能服务(LBS)作为一种高效、可靠的服务,越来越成为一个重要的问题。精确LBS是搭车平台的基础之一提供优质的交通服务和愉快的旅行客户体验。

图1:预计到达时间(ETA)是指沿着给定路线(绿线)一对起点(绿线)和终点(红线)之间的预计旅行时间。它是数字地图和导航系统中最重要的基于位置的服务之一。它也是一个最重要的后端服务的搭车应用程序。
在本文中,我们考虑的估计到达时间(ETA)为一对出发地和目的地之间的旅行时间估计位置,如图1所示。这是一个重要的问题数字地图和导航系统的定位服务。
ETA在乘车平台上有着广泛的应用,例如旅行时间是司机和车手达成交易的关键问题之一。因此,准确估计行程时间是非常必要的在旅行开始之前。准确的ETA将提高系统的效率交通系统,降低用户出行成本,节约能源消耗,减少机动车污染。因此,ETA已经成为影响决策的核心因素在线乘车过程的不同阶段,包括路线选择、车辆调度、拼车等。
行程时间估计在地理学中得到了广泛的研究信息系统(GIS)[1、2、6、8、13、15、19、20、22]。和标准社区内已制定解决方案。现有的解决方案可分为两类。第一类是基于路线的解决方案,使用直观的物理模型:给定路线的总旅行时间为表示为通过每条道路的行驶时间的总和分段1以及每个交叉口的延误时间。旅行时间估算yˆ表示为
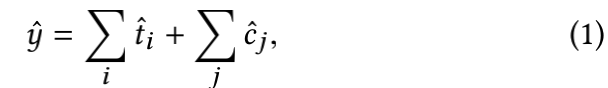
tˆi在哪里是第i个路段的预计行程时间,以及cˆj公司是第j个交叉口处的延误时间估计值。此解决方案已广泛应用于研究领域和工业应用中。它划分了整个路线的行程时间估计分为几个子问题,包括行程时间的估计每个路段和每个交叉口的延误时间。这些子问题的研究在国内外得到了广泛的关注文学。介绍了各种与GIS相关的数据来源,以估算路段或子线路的行程时间[11, 15, 18]. 机器学习算法,如回归并采用张量分解算法对其进行了分析预测道路网络上的旅行时间或交通速度[20]。其他的探索都集中在近似旅行时间上对于给定的路由,使用一个更通用的子程序,它可以是
给定路线的任意部分[15,21]。然而,问题是仍然很难妥善解决。这是一种经典的解决方案有几个固有的缺点:1)虽然数据和数据来源的多样性急剧增加可用数据的时空覆盖仍然非常稀疏。仅仅监视实时的交通模式是远远不够的整个路网;2)交通系统是一个动态的系统系统。很难对未来的运动模式进行物理建模以明确的形式。例如,很难预测交通状况
某一路段的状况和红绿灯是什么在特定的交叉口,当车辆在未来到达时。因此,可能无法保证每个tˆi的高估计精度和cˆj;3)(1)中的模型将整个行程时间分为几个部分。这可能导致估计误差的累积和不利于整体估计精度;4)个性化是影响预计到达时间的重要因素。给定旅行的旅行时间对于不同的驾驶员和骑手可能会有很大的不同。然而,它在现有工程中被忽视。
第二类是数据驱动的解决方案。近年来,数据仓库的迅速发展使得机器学习成为一种强有力的工具处理预测问题的工具。除了机器的使用基于路径的交通流速度预测方法研究在每个路段的行程时间上,进行了几次探索直接预测全线运行时间基于其历史旅行时间的未来时间段。几个方法对给定路线在不同时刻的旅行时间进行建模周期作为时间序列[6,22]。然后将ETA问题转化为一个多元时间序列预测问题。方法在[19]中,建议使用其相邻行程的加权平均值,指有相似的出发地和目的地。这种方法已经成功了更好的可扩展性。然而,上述第二类现有的解决方案存在以下缺点:1)数据不足覆盖问题仍然存在。很难获得旅行时间查询路线或类似路线的所有历史时间段路线。因此,这类方法主要是在路段少、交通条件比较稳定的高速公路上进行研究旅行时间预测受到限制多条固定路线。很难推广到不可见的路径,这限制了问题的可扩展性;3)很多这些方法忽略了关键信息,如交通信息和个性化信息,从而阻碍了它们的应用从获得高的预测精度。
随着大规模历史数据和机器学习工具在旅游业中的广泛应用时间估计问题,边界路径法数据驱动的方法变得越来越模糊。但其固有的缺点是数据覆盖不足,泛化能力弱能力不足和信息使用不足限制了信息系统的有效性现有的方法。本文提出了一种系统的机器学习解决方案对于行程时间估计,克服了现有方法。我们建立了一个丰富有效的特征系统对于基于位置的数据,包括浮动车数据、道路数据
网络数据和用户行为信息。基于提取的特征,我们将ETA描述为一个回归问题。这个这个问题可以通过流行的机器学习方法来解决,例如如梯度提升决策树(GBDT)[9]和因子分解机(FM)[17]。此外,我们还构建了一个新的深度学习模型解决这个问题的模型。在这一模式中,我们联合进行广泛的培训线性模型、深层神经网络和递归神经网络把他们的利益结合起来。它平衡了记忆,
一种模型的泛化和表示能力,有效地缓解了现有方法的局限性。上的结果大规模的旅游数据和实时在线系统证明了这一点提出的解决方案优于最先进的解决方案行程时间估算。建议的解决方案已部署在滴滴楚星的平台,每天为数十亿的ETA请求提供服务一天。
本文的主要贡献包括:
•我们将ETA问题描述为纯回归问题。
•我们提出了一种新的深度学习模型来解决ETA问题学习问题。该方法优于现有方法。
•我们为基于位置的数据构建了一个设计良好的特征系统。
•我们使用大规模历史数据评估我们的算法以及滴滴楚星的实时在线查询。所有结果
结果表明,所提出的解决方案明显优于最先进的解决方案。本文的剩余部分如下:第二节重新阐述了本文的研究内容ETA问题转化为一个端到端的机器学习问题介绍了本文提出的解决方案,第三节介绍了相关的工作,第四节提供了大规模的离线实验和实验严格的在线A/B测试,以验证我们在第5节中总结了本文的结论。
2方法
在本文中,我们将行程时间估计问题定义如下:
定义2.1(ETA学习)。假设我们有一个 trips,D={pi,si,ei}Ni=1,其中pi是 第i次行程,si为出发时间,ei为到达时间。这个 实际行程时间由ei−si给出。给定一个查询q=(oq,dq,sq),我们的目标是估计旅行时间tq与给定的起点oq,目的地dq和出发时间sq。
2.1特征提取
实时导航应用程序和在线乘车应用程序的广泛使用每天产生大量的浮动汽车数据。如此庞大的数据量使得行程时间的预测更加准确可以通过使用机器学习方法。然而,在传统的数据驱动方法中,实现良好的性能是模型训练中使用的有限功能。为了确保机器学习算法的有效性,我们首先系统地为基于位置的系统构建丰富的功能并为其建立高维特征映射。我们把这些特征归纳为几类:空间信息,时态信息、交通信息、个性化信息以及增强的信息。
- 空间信息:旅行时间与车辆经过的路线和地理位置旅行发生的区域。因此,我们提取特征集根据地理空间信息。首先将车辆轨迹映射到基础道路网中,得到道路序列线段和交点。然后我们提取了构成路线的所有构件,如道路路段、交叉口和红绿灯信息。例如,我们将为道路提取所有可以获得的特征路段,包括路段的长度、宽度和坡度,路段的车道数,路段的指数道路网中的路段等,我们还提取了poi路线经过区域内的信息。
- 时态信息:时态信息是另一种信息影响车辆行驶时间的关键因素,例如行程一条特定路线的时间通常在交通高峰时要长得多比非高峰时间短。因此我们指示出发具有不同特征的行程时间,包括时间段在一年,一个月,一天,假日指标和高峰时间指示剂等。
- 交通信息:交通网络中的交通状况对旅行时间有直接影响。我们建了一个交通监视器以及提供实时交通速度的预测系统
- 每两年交通网络中各路段的估算分钟。然后,我们对每条道路使用几种不同的行驶速度在我们的细分功能中,如实时估计速度、平均流速和自由流速等。
- 个性化信息:旅行时间是针对个人的,因为不同的人可能有非常不同的驾驶偏好。因此,我们在特征中引入了个性化信息,包括驾驶员特征、驾驶员特征和车辆特征等
- 增强信息:所有其他可用信息用作增强特征,包括天气信息和交通限制等艾尔。那个提取的特征包括实值、离散值和高维单热点特征形式的连续特征和分类特征。
经过复杂的特征工程,我们获得了一组数百个类别和数百万个维度的特征。
2.2学习估计旅行时间
基于设计良好的特征,我们将ETA学习问题改写成标准的机器学习形式。让我们表示
y=[y1,y2··,yN]作为每个样本的基本真值标签,式中,yi=ei si∈R+为每次行程的行程时间计算为到达时间ei和出发时间si之间的时间间隔. 让我们用X=[x1,x2,···,xN]表示样本,每个样本席沿路径对轨迹进行解码路径pi在路网中作为一个d维向量。我们的目标是为了训练一个模型,它可以准确地预测车辆的行驶时间未来看不见的数据xq<X。
在行程时间估计中,估计间隔的用户容差根据总行程时间而变化。因此,平均绝对百分比误差(MAPE)是我们在这个问题上更合理的度量。我们的目标是直接最小化MAPE
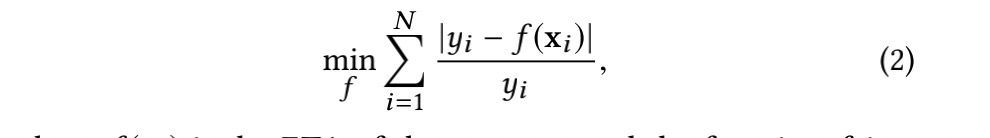
其中f(席)是路由席的η,函数f是回归模型。为了保证对不可见数据的良好预测性能,需要引入额外的正则化项来控制拟合的复杂度。因此,ETA学习问题的一般优化目标为:
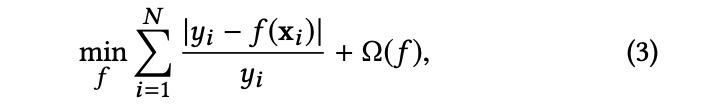
其中Ω(f)是控制模型f复杂性的正则化项。它可以通过使用适当的机器学习模型来学习。例如,我们可以使用梯度提升决策树(gradient boosting decision tree,GBDT)[4],这是现实问题中最常用的学习算法之一。另一个有效且实用的模型是因子分解机(FM)[17]。在GBDT中,预测模型可以表示为一个加性树模型
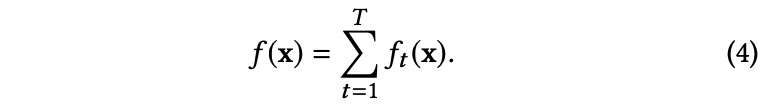
T是树的数目。ft(x)=wtu(x)是一个基本树模型,其中wt是叶上得分的向量,u是将每个数据点分配给相应叶的函数。因此,给定一个输入样本x,树模型返回x所属叶的得分。GBDT模型f的复杂性是由树的结构控制的。树的复杂性定义为
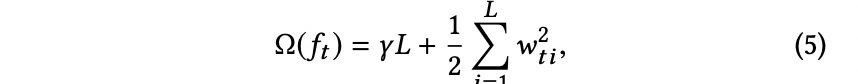
式中,γ是可调参数,L是叶数[4]。通过在目标中引入特定的GBDT模型和正则化项,优化问题变成:

这是一个凸优化问题。然而,目标是非光滑,因为MAPE函数是不可微的。我们可以用Huber损失近似MAPE函数或采用次梯度法求解优化问题(3)。
FM结合了因子分解模型的高预测精度和特征工程的灵活性。它已被广泛应用于推荐系统和在线广告系统中 [5,17],这与我们的问题相似,因为这两个问题都是针对为未来预测找到最合适的用户偏好。调频对d输入之间的k阶嵌套交互进行建模使用因子化交互参数的x变量。模型k=2阶定义为
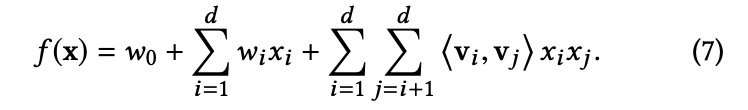
vj∈rm是m<d相互作用的嵌入变换。通过替换预测函数和必要的模型复杂性控制项,优化目标变为:
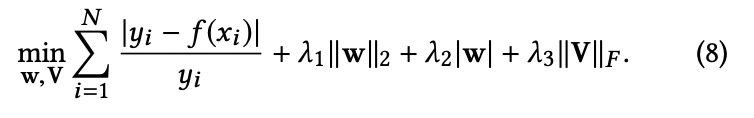
用梯度法求解。我们跟着其中一个基于V更新的MF在线优化算法自适应次梯度法(AdaGrad)[7]及利用跟随正规化领袖(FTRL)[16]。
2.3 广深循环学习
在实际应用中,我们发现GBDT和FM并不是最好的解决ETA学习问题的选择。GBDT难以适应到大型要素集。调频的性能在很大程度上取决于特征表示与模型表示能力有限。另一方面,我们有大量的具有复杂数据分布的历史数据。这使我们能够使用更复杂的模型来解决问题。因此,我们适应深入学习这个问题的技巧。广度和深度学习[5]被提出用于推荐系统,它联合训练广度线性模型和深度神经网络模型网络结合了学习系统的记忆和泛化能力的优点。模型有两个块结构,如图2所示

图2:广度和深度学习的模型结构:广度线性模型在左边,深度神经网络在右边。
wide模型首先将输入特性投影到一个高维度特征空间。这可以通过计算来实现输入特征的叉积,类似于FM中的功能交互。仿射变换y=w·x+b可在叉积变换后应用。宽的模型可以解释为广义线性模型,即类似于logistic等传统的推荐算法回归。与深部模型相比,宽部模型可能被认为是浅层模型。deep模型首先将稀疏的输入特征转换为利用特征嵌入层进行密集特征提取。这个嵌入表示每一类高维稀疏特征通过一个紧凑的特征向量(大小=20英寸设置)。稠密的然后将输入特征与嵌入的特征连接起来而前馈神经网络(FNN)又称为前馈神经网络作为多层感知器(MLP)。顶层的回归器结合宽模型和深模型的输出以提供最终预测。通常,稀疏特征用于表示分类信息和密集特征用于表示数字信息。例如司机id为稀疏特征,而路径长度是稠密特征。
上述所有型号都要求每个样品应对齐。我们只能提取这一要求下的出行统计信息,如路数不同行程的路段通常是不同的。广而深模型能够捕捉数据之间的全局统计信息车辆经过的路线和地理空间区域。然而,它们不善于捕捉每个路段的局部交通信息。因此我们需要引入额外的网络结构来捕捉路段的局部信息。在根据地图数据,将路网划分为不同的道路段和这些段可以被视为路线。各路段具有明显的时序结构。这与自然语言中的情况类似词是句子的组成部分。这个启发我们引入递归神经网络。
长-短期记忆(LSTM)[10]是一种特殊的复发性记忆神经网络(RNN)。它在几个方面取得了巨大的成功顺序数据的学习任务,如神经机器翻译[3]。LSTM可以捕获每个对象的本地信息
分段和沿序列的长期依赖性。因此我们将其引入到路段序列的建模中。标准LSTM结构如图4所示。LSTM缓解用一种新方法研究RNN的梯度消失和爆炸问题加法存储器单元,为梯度通过提供一条高速公路通过,并使用多个门来进一步控制信息流动。在LSTM的每个推理步骤中,输入门,遗忘门,输出门和调制输入更新为:

其中σ(·)是S形函数σ(u)=1/(1+e−u)。每个方程由一个仿射变换和一个非线性激活组成。
然后,存储单元和隐藏状态更新为:
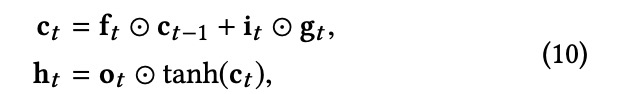

广深循环学习:我们将广深结合循环模型一起构建我们的深度学习模型学习估计旅行时间。模型结构是如图3所示。这种模式继承了它的优点祖先,并有效地利用了稠密的特征,高维数稀疏特征与道路沿线局部特征段序列。它能够正确地使用所有可用的信息在ETA学习问题中。WDR模型有三个主要模块:1)宽模型相似在广域网和深度网中建立广域模型。我们使用第二个命令仿射变换后的叉积变换获得256维的输出;2)深模型嵌入将稀疏特征转换为20维空间,然后处理由具有ReLU的3隐藏层MLP连接的特征[14]激活以获得256维输出。三个的大小MLP中的隐藏层是256;3)递归模型是一个变体标准RNN。首先投影每个路段的特征进入256维空间的一个完全连接层与ReLU作为激活函数。然后将变换后的特征输入到 到单元格大小为256的标准LSTM。hT的最后隐藏状态。
LSTM被输入到顶部回归器,其中T是数据的长度道路顺序。在MAPE损失下,采用BP算法对WDR模型中的所有参数进行联合训练。由于组合在三个模块中,很难找到合适的全局学习速率。因此,我们选择Adam[12],一个随机梯度下降采用自适应步长和动量的方法,对系统进行优化模型。我们将Adam的学习率设置为0.001,然后初始化遵循[12]指南的其他超参数。
2.4 总体管线
我们总结了我们的解决方案管道,以便学习评估旅行时间如图5所示。在数据聚合模块中,我们首先将GPS轨迹与路网进行匹配,得到相应的路段序列。然后是特征提取程序聚合路网信息、轨迹信息、顺序上下文信息和增广信息产生为培训模块输入数据。在特征提取之后,我们根据大规模历史数据启动离线培训。然后我们使用一组最新生成的数据进一步微调模型,以确保模型适应最新的数据分布。一旦微调完成,模型就会被推送到在线服务器上。
3 相关工作
在本文中,我们将旅行时间估计问题描述为时空回归问题与WDR学习去解决它。人工神经网络,包括MLP和RNN,已经被用来解决旅行时间估计问题文献[6,22]。然而,这些传统方法适用于
求解时间序列预测的标准深度学习模型问题。在这些工作中,神经网络的主要输入特征网络是查询路线的历史旅行时间。与如此小的功能集,很难充分利用深度学习模式。此外,这些解决方案在实际应用中效果不佳多步预测是一个普遍存在的问题在时间序列预测中。据我们所知,拟议的WDR学习模型是第一个专门设计的深度学习模型

解决行程时间估计问题。通过类比自然语言处理,解决了道路轨迹挖掘问题
(NLP)。每条路线被视为一个句子,每个路段以相应的互动作为一个词。WDR网络从广度和深度上捕捉旅行的总体统计特性模型,并捕获序列的详细特征按循环模型划分的路段。丰富性和有效性良好的特征设计保证了系统的泛化能力所学的深度学习模型,可用于预测道路网中任何看不见的行程的行程时间随时开始。
在本文中,我们还采用GBDT和FM来解决公式化的时空回归问题。他们两个都表现出来了
有竞争力的表现。我们试图简单地解释这个结果比较分析了本文采用的三种模型论文:GBDT、FM和WDR网络。GBDT引入了一种非线性基于决策的模型表示转换树。它可以看作是一个简单的深部模型。当可用时训练数据和特征集都是有限的,GBDT是一个合理的选择。调频可以看作是两种模式的结合部分:一是线性模型部分,这是一个广泛的线性模型;另一部分表示非线性特征交互作用,并对其进行了分析相当于两层MLP,也可以看作简单的深层模型。因此,FM是一种简化的宽深模型。它可以在训练数据和特征集处于同一状态时使用大尺寸。在WDR学习中,深度和广度的模型部分是有区别的比FM复杂得多,FM具有更好的表示性如果模型可以用足够的训练数据进行训练的话。递归模型部分引入了更多的表示能力每个路段的详细信息。利用更多信息,WDR学习得到更好的预测性能。和我们相信,随着可用数据和功能的增加,所提出的解决方案更有前景。除上述优点外,WDR模型还可以应用于更一般的序列学习问题。
4实验
我们在大规模离线数据集上对所提出的解决方案进行了实证评估。在此基础上,我们还构建了一个实时ETA服务
解决方案,并与主要ETA服务提供商进行比较。
4.1数据集
我们收集了北京市1月1日至5月31日的浮动车数据,2017年滴滴平台。然后将数据分为两个不同的部分根据驾驶员工作状态的类型-拾取数据和跳闸数据。当驾驶员做出响应时,采集采集样本
接受骑手的要求,直到他/她接上骑手为止。旅行样品当一个骑手在船上时被收集直到骑手到达目的地目的地。从真实场景收集的车辆轨迹可能非常复杂。例如,一条路线可能包含城市高速公路、当地街道和住宅区的私人道路社区。图1展示了滴滴平台上的一个典型示例,从当地的一条街道出发,经过几条高速公路最后驶入机场内部道路。准确地预测这种路线的旅行时间是一个具有挑战性的问题。
排除行程时间极短的异常情况后(<
60秒)或极高的旅行速度(>120公里/小时),我们获得了大约拾取数据集中有5700万个样本和6200万个样本在trip数据集中。表1列出了这两个数据集的统计数据。请注意,轨迹分布在整个道路上网络覆盖北京50万个独特的路段拾取和跳闸数据集。数据来自0.4每个数据集有100万个驱动程序。由于大多数ETA模型都存在数据稀疏的问题,我们分析了给定数据集上数据覆盖率的统计。我们在图6中绘制了一整天的平均链接覆盖率。结果表明,出行轨迹的覆盖率比传统的路径覆盖率高捡拾器的一般轨迹。出行数据统计显示滴滴司机的轨迹覆盖了大约45%的道路白天的链接。黎明前覆盖率降到最低。
4.2竞争方法
在离线数据集上,我们将我们的解决方案与几个竞争对手进行了比较,包括一个具有代表性的基于路径的解决方案routeETA和文献中两种最先进的方法TEMPrel[19] 和PTTE[20]。我们还评估了我们的机器学习解决方案采用不同的模型,如GBDT,FM和WD网络与MLP相结合。在线评估期间,我们比较了基于WDR模型的实时服务和三种基于WDR模型的实时服务通过严格的A/B测试领先的行业LBS提供商。路由ETA是实时地图服务中广泛使用的解决方案以及导航系统。在这个解中,给定路径的ETA是每个路段的行程时间和每次交互的延迟时间。路线ETA估计行程时间通过将路段长度除以实时交通量在赛段上加速。各路段的交通速度和每个交叉口的延误时间由实时交通流提供监控服务。TEMPrel[19]是一种无路线方法,用于估算行程基于相邻行程的查询行程时间。两次旅行如果他们之间的距离它们的目的地之间的距离小于某个阈值。这个查询行程的预计到达时间是通过平均它的邻居。TEMPrel的结果仅限于测试数据,因为TEMPrel要求测试样本至少有一个训练集中的邻居。这些子集包含大约68%的样本对于拾取数据集,61%的样本用于trip数据集2。PTTE[20]将ETA构建块建模为三维张量,是每个路段在行驶过程中的行驶时间每个驱动程序的每个时隙。它估计了该张量采用低秩张量完成算法。那么采用动态规划法求解最小行程时间在两个给定地点之间。验证在估计路段的行程时间时,我们比较了不同的路段我们框架下的机器学习模型,包括GBDT,FM和WDR网络的一个变种WD-MLP。在WD-MLP中,一个MLP被用来代替经常性模块。应用MLP然后对每个链路的输出向量进行平均沿途的链接。我们使用相同的输出大小的循环此MLP的模块。
4.3评价指标
我们在实验中使用了多种评估指标。对于离线实验中,我们采用了三种经典的测量方法,包括平均绝对百分比误差(MAPE)、平均平均误差(MAE)和均方误差(MSE)来评价竞争方法。对于在线比较,我们使用了四个评估指标,包括MAPE、APE20、不良病例率和低估率。这个最后三个指标在行业中普遍用于评估实时ETA服务的性能。它们的详细定义
具体如下:
•APE20:绝对百分比误差(APE)小于20%的预测百分比(越高越好)。
•不良病例率:APE更高的预测百分比
大于50%或绝对误差(AE)大于180秒,
衡量极端恶劣案例的百分比(降低
更好)。
•低估率:低估预测的百分比(越低越好)。














 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









