







学习笔记
Tensorflow 2.12 电影推荐项目搭建记录~
Tensorflow是谷歌开源的机器学习框架,可以帮助我们轻松地构建和部署机器学习模型。这里记录学习使用tensorflow来搭建一个电影项目demo,包含召回模型搭建、排序模型搭建,以及整合两个模型进行完整的推荐。
相关文章:
电影推荐-召回模型
电影推荐-排序模型
工具、环境
开发工具:PyCharm 2023.1.1 (Community Edition)
使用环境:Python 3.10.6
使用框架:tensorflow 2.12.0、tensorflow-datasets 4.9.2、tensorflow-recommenders 0.7.3、numpy 1.23.5、pandas 2.0.3、tensorboard 2.12.3
创建项目
使用PyCharm创建一个新项目:MovieRecommenders,方便后续在项目中实现推荐模型、排序模型相关的代码:
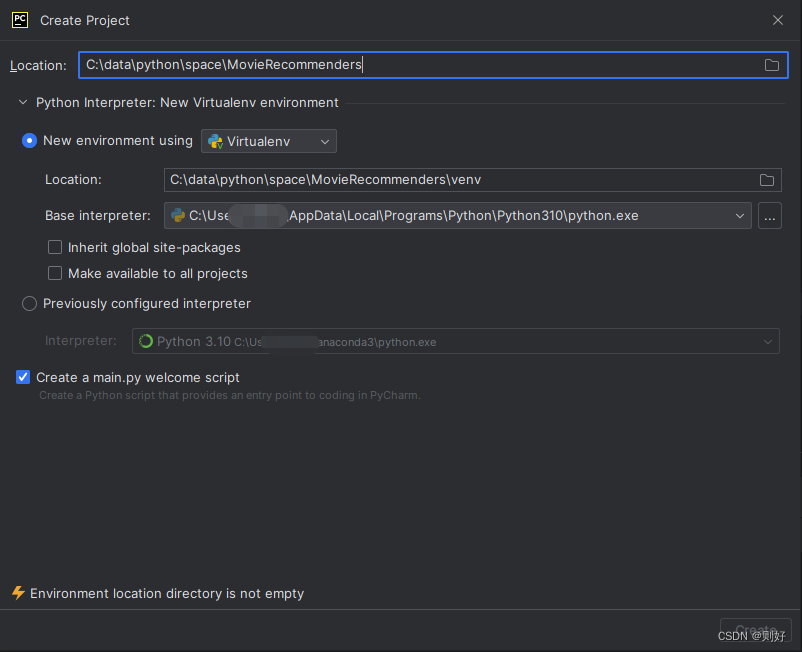
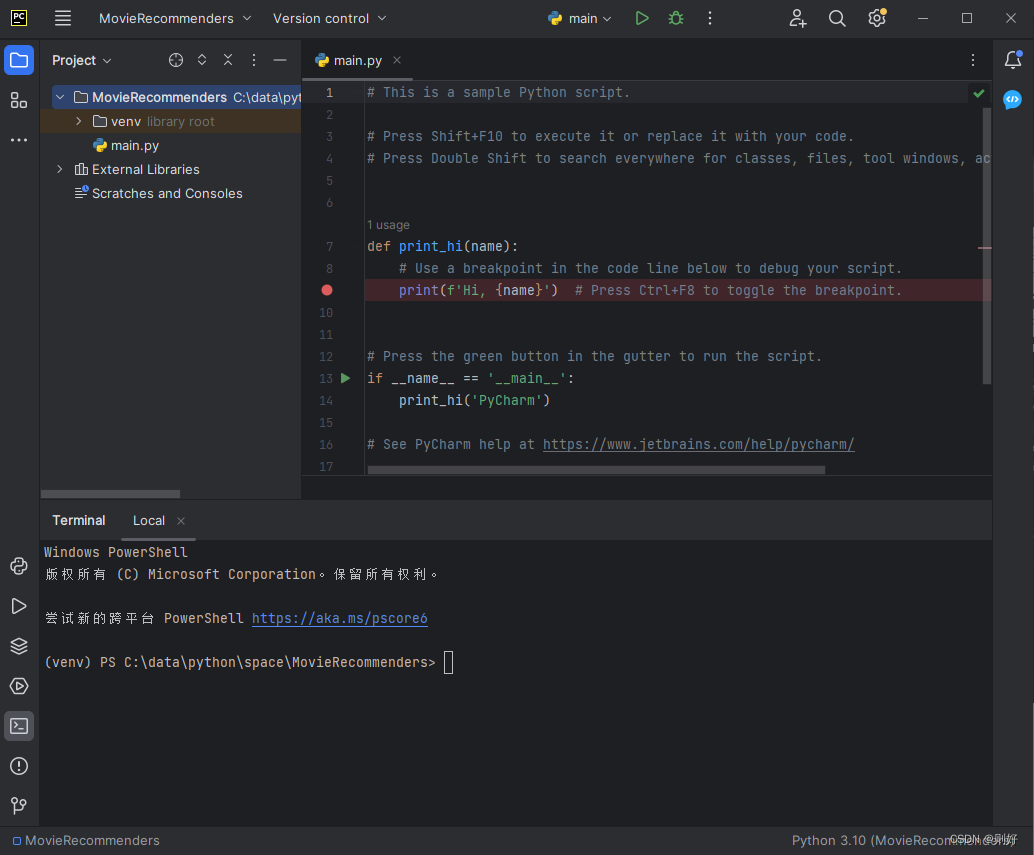
点击Create按钮,完成创建,新建项目截图如下:
项目配置
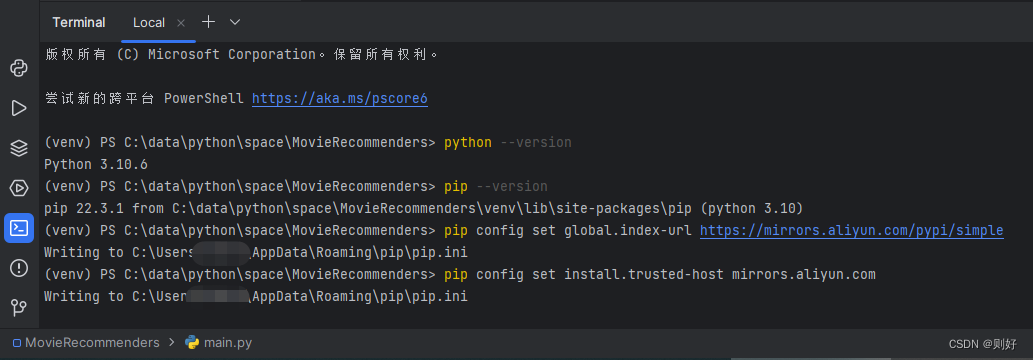
打开控制台,配置pip国内源,下包的速度会快一点,这里配置阿里源:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
pip config set install.trusted-host mirrors.aliyun.com
配置截图如下:
安装相关python包
使用pip安装tensorflow、tensorflow-recommenders、tensorflow-datasets三个包,注意对应版本,tensorflow的依赖包很多,整个过程估计5~10分钟:
pip install tensorflow==2.12.0
pip install tensorflow-recommenders==0.7.3
pip install tensorflow-datasets==4.9.2
安装截图如下:

召回模型实现
新建movie_recommenders包,在该包下创建Retrieval.py文件,如下:
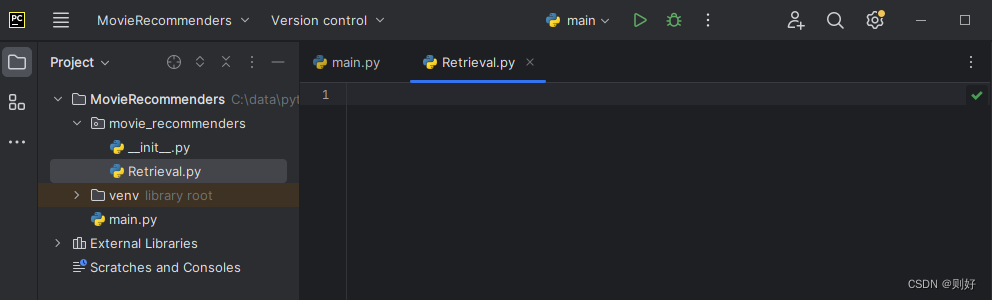
Retrieval.py主要为构建、训练、导出电影推荐召回模型,包含以下步骤(代码详见上面召回模型的文章):
- 导入相关模块
- 加载数据
- 数据预处理
- 生成词汇表
- 构建查询塔
- 构建候选条目塔
- 模型指标
- 损失函数
- 构建双塔召回模型
- 训练和评估
- 预测
- 导出和加载模型
这里我们改下保存模型的路径,把训练好的模型保存到项目路径下,为后续做推荐准备,其他代码不做变动:
# 保存模型和加载模型
# with tempfile.TemporaryDirectory() as tmp:
# path = os.path.join(tmp, "model")
path = "C:\data\python\space\MovieRecommenders\models\\retrieval\\"
tf.saved_model.save(index, path)
loaded = tf.saved_model.load(path)
scores, titles = loaded(["42"])
print(f"Recommendations: {scores[0][:3]}")
print(f"Recommendations: {titles[0][:3]}")
点击运行,控制台训练、评估、推荐结果相关日志输出如下:
C:\data\python\space\MovieRecommenders\venv\Scripts\python.exe C:\data\python\space\MovieRecommenders\movie_recommenders\Retrieval.py
Epoch 1/3
10/10 [==============================] - 44s 3s/step - factorized_top_k/top_1_categorical_accuracy: 0.0012 - factorized_top_k/top_5_categorical_accuracy: 0.0093 - factorized_top_k/top_10_categorical_accuracy: 0.0207 - factorized_top_k/top_50_categorical_accuracy: 0.0969 - factorized_top_k/top_100_categorical_accuracy: 0.1728 - loss: 69892.1080 - regularization_loss: 0.0000e+00 - total_loss: 69892.1080
Epoch 2/3
10/10 [==============================] - 35s 4s/step - factorized_top_k/top_1_categorical_accuracy: 0.0034 - factorized_top_k/top_5_categorical_accuracy: 0.0205 - factorized_top_k/top_10_categorical_accuracy: 0.0405 - factorized_top_k/top_50_categorical_accuracy: 0.1726 - factorized_top_k/top_100_categorical_accuracy: 0.2970 - loss: 67485.1641 - regularization_loss: 0.0000e+00 - total_loss: 67485.1641
Epoch 3/3
10/10 [==============================] - 36s 4s/step - factorized_top_k/top_1_categorical_accuracy: 0.0033 - factorized_top_k/top_5_categorical_accuracy: 0.0232 - factorized_top_k/top_10_categorical_accuracy: 0.0457 - factorized_top_k/top_50_categorical_accuracy: 0.1911 - factorized_top_k/top_100_categorical_accuracy: 0.3198 - loss: 66259.6726 - regularization_loss: 0.0000e+00 - total_loss: 66259.6726
5/5 [==============================] - 10s 1s/step - factorized_top_k/top_1_categorical_accuracy: 9.5000e-04 - factorized_top_k/top_5_categorical_accuracy: 0.0088 - factorized_top_k/top_10_categorical_accuracy: 0.0204 - factorized_top_k/top_50_categorical_accuracy: 0.1235 - factorized_top_k/top_100_categorical_accuracy: 0.2351 - loss: 31082.6670 - regularization_loss: 0.0000e+00 - total_loss: 31082.6670
Recommendations for user 42: [2.2189372 2.166171 2.132876 ]
Recommendations for user 42: [b'Homeward Bound: The Incredible Journey (1993)' b'Cinderella (1950)'
b'Rent-a-Kid (1995)']
Recommendations: [2.2189372 2.166171 2.132876 ]
Recommendations: [b'Homeward Bound: The Incredible Journey (1993)' b'Cinderella (1950)'
b'Rent-a-Kid (1995)']
Process finished with exit code 0
排序模型实现
同样在movie_recommenders包下创建Ranking.py文件,实现评分排序模型构建,包含以下步骤(代码详见上面排序模型的文章):
- 导入相关模块
- 加载数据
- 数据预处理
- 获取词汇表
- 构建评分排序模型
- 定义损失函数以及模型评估指标
- 构建完整的评分排序模型
- 训练和评估
- 预测
- 导出和加载模型
这里我们同样也改下排序模型保存的路径,把训练好的排序模型保存到项目路径下,为后续推荐做准备,其他代码不做变动:
# 保存模型路径
path = "C:\data\python\space\MovieRecommenders\models\\ranking\\"
# 保存模型
# tf.saved_model.save(model, "../export")
tf.saved_model.save(model, path)
# 加载模型
# loaded = tf.saved_model.load("../export")
loaded = tf.saved_model.load(path)
# 进行预测
loaded({"user_id": np.array(["42"]), "movie_title": ["Speed (1994)"]}).numpy()
点击运行,控制台训练、评估、推荐相关日志打印如下:
C:\data\python\space\MovieRecommenders\venv\Scripts\python.exe C:\data\python\space\MovieRecommenders\movie_recommenders\Ranking.py
Epoch 1/3
10/10 [==============================] - 7s 88ms/step - root_mean_squared_error: 2.2190 - loss: 4.5199 - regularization_loss: 0.0000e+00 - total_loss: 4.5199
Epoch 2/3
10/10 [==============================] - 1s 72ms/step - root_mean_squared_error: 1.1217 - loss: 1.2603 - regularization_loss: 0.0000e+00 - total_loss: 1.2603
Epoch 3/3
10/10 [==============================] - 1s 71ms/step - root_mean_squared_error: 1.1131 - loss: 1.2412 - regularization_loss: 0.0000e+00 - total_loss: 1.2412
5/5 [==============================] - 3s 37ms/step - root_mean_squared_error: 1.1077 - loss: 1.2225 - regularization_loss: 0.0000e+00 - total_loss: 1.2225
Ratings:
Dances with Wolves (1990): [[3.6061542]]
M*A*S*H (1970): [[3.598676]]
Speed (1994): [[3.5743594]]
Process finished with exit code 0
实现电影推荐
整合召回、排序两个模型,实现电影推荐。
召回模型主要帮助我们从百万级别、甚至千万级别的候选电影条目中筛选出一定数量的用户感兴趣的电影(通常为千级别,即百万级 ->千级别),接下来排序模型将这些筛选出来的条目按用户喜欢的程度进行排序,再取排序后的top10或者top100进行推荐(即千级别 ->百级别、十级别)。
导入模块
首先我们新建Recommender.py文件,导入相关的模块:
import numpy as np
import tensorflow as tf
设置要推荐的用户
这里假设要为用户Id为42的用户推荐电影(当然通常情况下是以接口的形式提供给前端调用来为某个用户进行推荐):
user_id = "42"
召回推荐
从之前保存的路径加载召回模型:
retrieval_path = "C:\data\python\space\MovieRecommenders\models\\retrieval\\"
retrieval = tf.saved_model.load(retrieval_path)
开始为用户Id为42的用户进行召回推荐,召回模型会返回电影标题以及召回该电影的评分依据:
# 保存召回的电影标题
retrieval_movie_titles = []
scores, titles = retrieval([user_id])
# 打印召回推荐的电影以及电影对应的评分
for score, title in zip(scores[0], titles[0]):
print(score, title)
# 保存电影标题,为后续排序做准备
retrieval_movie_titles.append(title.numpy())
排序推荐
从之前保存的路径加载排序模型:
ranking_path = "C:\data\python\space\MovieRecommenders\models\\ranking\\"
ranking = tf.saved_model.load(ranking_path)
将召回模型筛选出来的电影标题加上用户Id传入排序模型进行排序,排序模型同样会返回电影标题以及该电影的排序评分依据:
# 保存排序结果
test_ratings = {}
for movie_title in retrieval_movie_titles:
test_ratings[movie_title] = ranking({
"user_id": np.array([user_id]),
"movie_title": np.array([movie_title])
})
推荐结果
打印排序模型输出电影标题以及评分,可以从结果中选择评分最高的前10条来推荐给用户:
# 倒序打印推荐电影
print("Ratings:")
for title, score in sorted(test_ratings.items(), key=lambda x: x[1], reverse=True):
print(f"{title}: {score}")
结尾
当然实际的推荐场景可能更复杂,这里只是搭建一个简单的例子~















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









