







前言
基于 Tensorflow 2.12 搭建一个简单的智能商城商品推荐系统demo~
主要包含6个部分,首先是简单介绍系统架构,接着是训练数据收集、处理,然后是召回模型、排序模型的搭建以及训练、导出等,最后是部署模型提供REST API接口以及如何调用进行推荐。
Tensorflow是谷歌开源的机器学习框架,可以帮助我们轻松地构建和部署机器学习模型。这里记录学习使用Tensorflow来搭建一个简单的智能商城商品推荐系统。
相关版本:
- python 3.1.0
- pandas 2.0.3
- tensorflow 2.12.0
- tensorflow-recommenders 0.7.3
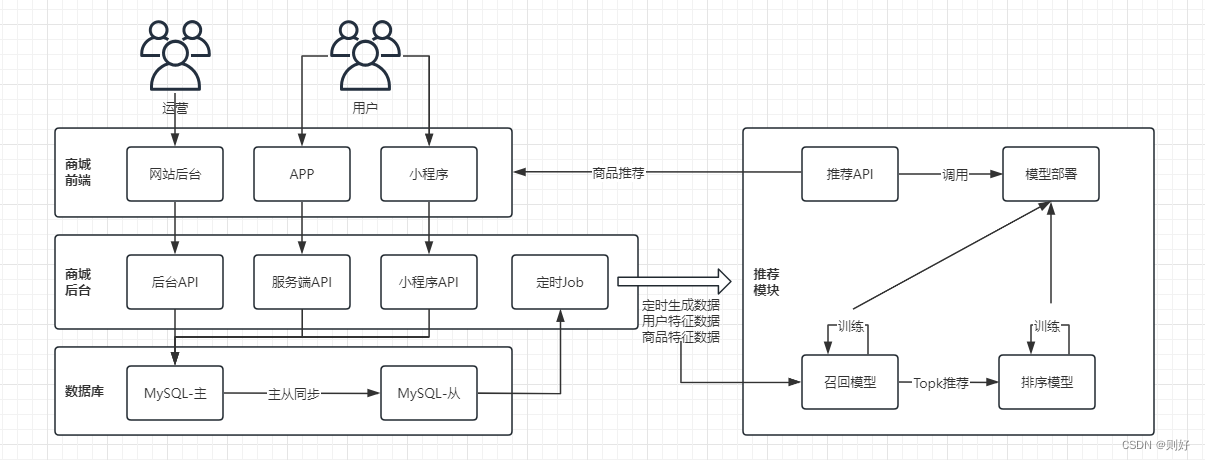
架构
通常一个商城系统主要包含前端、后台,前端包含网站、移动H5、APP、小程序、公众号等,后台主要包含相关的API服务以及存储层等。
首先运营通过后台来录入商品信息、进行上架,然后前端用户通过商城APP、小程序来浏览商品、搜索商品、进行下单购买、关注、收藏等。
一般系统中都会保留用户的这些操作数据,例如浏览数据、搜索数据、下单数据等,结合运营录入的商品数据,通过定时Job生成用户的特征数据、商品的特征数据,然后使用机器学习来找到用户喜欢的但又没有购买过的商品,进行简单的AI推荐。
这里简单的画了一个图:
数据
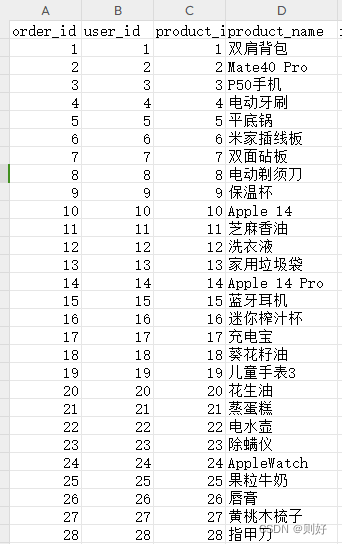
数据收集部分这里就不展开讲了,相信现在大部分电商系统都有保留用户的一些搜索数据、下单数据等,以及后台录入的商品数据,通过一个定时JOB,定时把数据查询出来导出为CSV文件即可,作为后续进行模型训练的数据集。
当然没有也没关系,可以写一个简单的Java方法、或者python方法随机生成数据,写到CSV文件中。
这里先从最简单的开始,只使用用户的下单数据以及商品数据来进行训练(主要特征为用户Id、商品Id)。
召回
主要是训练一个双塔召回模型,根据用户的历史下单数据以及商品数据,召回几百到数千条用户喜欢的商品(基于内容的推荐)。
召回模型搭建分为以下几部分:
1、数据处理
2、模型搭建
3、模型训练
4、模型评估
5、模型导出
import pprint
import pandas as pd
from typing import Dict, Text
import numpy as np
import tensorflow as tf
import tensorflow_recommenders as tfrs
# -*- coding:utf-8 -*-
# 使用pandas加载数据
order_df = pd.read_csv("C:\\data\\python\\data\\blog\\order.csv", encoding="gbk")
pprint.pprint(order_df.shape)
pprint.pprint(order_df.head(5))
# 处理数据类型(转为字符串)
order_df['user_id'] = order_df['user_id'].astype(str)
order_df['product_id'] = order_df['product_id'].astype(str)
# 将DataFrame(pandas)转换为Dataset(tensorflow)
order_df = tf.data.Dataset.from_tensor_slices(dict(order_df))
for x in order_df.take(1).as_numpy_iterator():
pprint.pprint(x)
# 准备嵌入向量的词汇表(用户的)
user_ds = order_df.map(lambda x: {
"user_id": x["user_id"],
"product_id": x["product_id"]
})
# 准备嵌入向量的词汇表(商品的)
product_ds = order_df.map(lambda x: x["product_id"])
# 随机数种子
tf.random.set_seed(42)
# 打乱数据
shuffled = user_ds.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
# 切分数据,分为训练数据以及验证数据
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
# 数据分片
user_ids = user_ds.batch(1_000_000).map(lambda x: x["user_id"])
product_ids = product_ds.batch(1_000)
# 获取唯一的用户Id列表以及商品列表
unique_user_ids = np.unique(np.concatenate(list(user_ids)))
pprint.pprint(unique_user_ids[:5])
unique_product_ids = np.unique(np.concatenate(list(product_ids)))
pprint.pprint(unique_product_ids[:5])
# 将用户特征映射到用户embedding中,查询塔
user_model = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32)
])
# 将商品特征映射到商品embedding中,候选条目塔
product_model = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=unique_product_ids, mask_token=None),
tf.keras.layers.Embedding(len</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









