






刘庚林
1
{ }^{1}
1 Salman Rahman
1
{ }^{1}
1 Elisa Kreiss
1
{ }^{1}
1 Marzyeh Ghassemi
2
{ }^{2}
2 Saadia Gabriel
1
{ }^{1}
1
1
{ }^{1}
1 加州大学洛杉矶分校
2
{ }^{2}
2 MIT CSAIL
genglinliu@cs.ucla.edu
摘要
我们介绍了一种新颖的开源社交网络仿真框架MOSAIC,其中生成性语言代理预测用户行为,如点赞、分享和标记内容。该仿真将LLM代理与有向社交图结合,以分析新兴欺骗行为并更好地理解用户如何确定在线社交内容的真实性。通过从多样化精细的人格构建用户表示,我们的系统能够进行大规模的多代理仿真,以建模内容传播和参与动态。在此框架内,我们评估了三种不同的内容审核策略,并对模拟的虚假信息传播进行了评估,发现这些策略不仅减轻了非事实内容的传播,还增加了用户参与度。此外,我们分析了模拟中流行内容的轨迹,并探讨了模拟代理对其社交互动所表达的推理是否真正与其集体参与模式一致。我们开源了我们的仿真软件,以鼓励在AI和社会科学领域的进一步研究:https://github.com/genglinliu/MOSAIC
1 引言
2024年,OpenAI报告称其平台已被隐蔽的影响操作滥用,以生成在社交媒体上扩散的合成内容(OpenAI, 2024)。这些互联网操纵者利用社交网络已成为现代生活的基本部分这一事实,塑造公共话语,影响政治意见,并促进未经验证的人类和AI生成内容的快速传播(Aichner等,2021;Orben等,2022;Cinelli等,2021)。虽然传统的社会科学方法如调查和观察研究提供了对人类行为的见解,但它们往往难以捕捉大规模的、新兴的在线互动
(Yu等,2021;Lorig等,2021)。基于代理的建模(ABM)在社会科学研究中相对于调查方法具有显著优势,因为它们可以随时间模拟动态互动,并支持在可重复和可控条件下检查假设或反事实情景的研究(Bonabeau, 2002; Epstein, 1999)。
基础模型的最新进展导致了生成性基于代理的社会模拟的出现,其中由AI驱动的用户动态地参与发布、分享、标记和评论内容(Yang等,2024;Gao等,2023;Chen等,2024a;Wang等,2024;Zhou等,2023;Park等,2022)。与传统的调查方法或经典的基于代理的建模不同,由大型语言模型驱动的模拟使代理能够通过丰富、类似人类的对话自然地与环境和其他代理交互,紧密模仿真实的社交行为。在这项工作中,我们介绍了MOSAIC,这是一个新颖的多代理AI社交网络模拟,用于建模内容扩散、用户参与模式和虚假信息传播。
模拟赋予我们提出关于复杂世界的反事实问题的能力。在社会模拟的不同应用中,内容审核因其由虚假或误导信息及在线影响操作造成的现实危害而成为一项紧迫的挑战。先前的研究表明,虚假信息不仅比真实内容传播得更快、更深入(Vosoughi等,2018),而且以难以逆转的方式改变公众认知(Lewandowsky等,2012)。解决这一问题需要有效的内容审核策略,既能减轻伤害,又能保护用户参与度和言论自由。我们将三种审核策略嵌入我们的模拟环境中:(1)模仿X和Meta的社区笔记的社区事实核查,(2)独立事实核查,以及两者的混合。
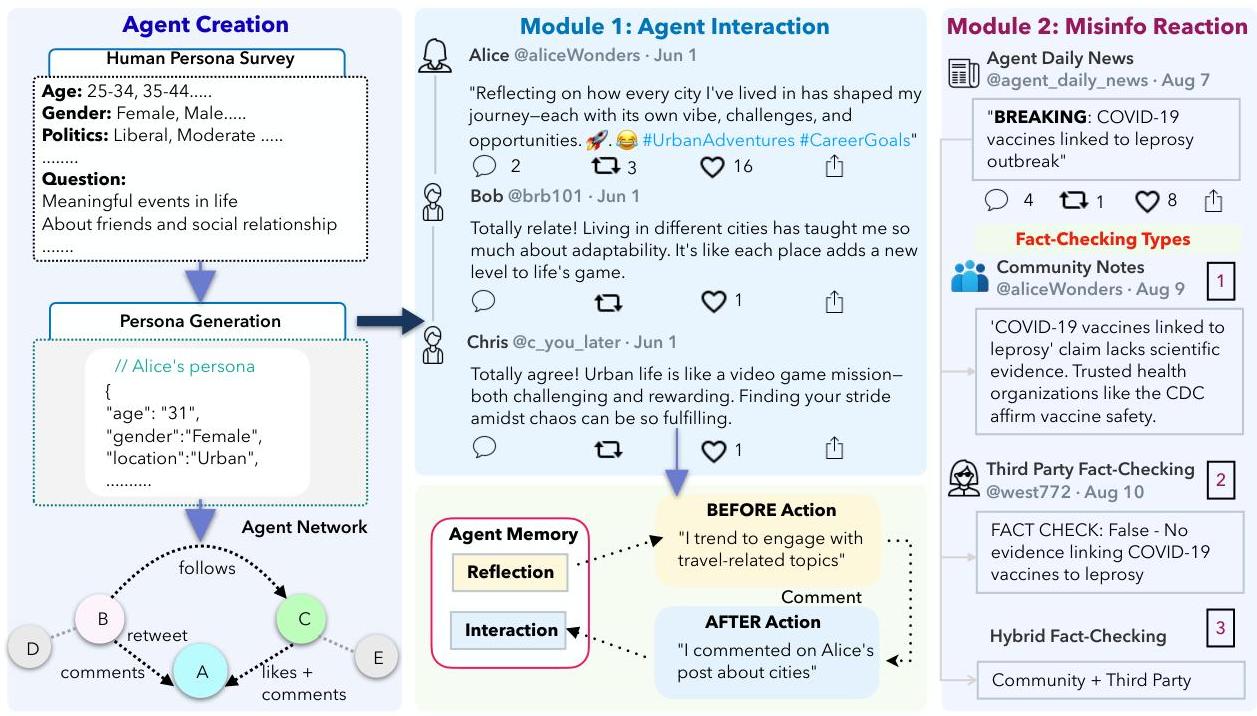
图1:MOSAIC概览,一个多代理社交模拟框架,其中代理在一个类似于社交网络的环境中互动,形成基于记忆的动态行为,并通过社区、第三方或混合事实核查机制回应虚假信息。人物特征从人类调查中复制或使用合成分布生成。代理在采取某些行动之前检索记忆,并在某些事件后更新记忆。
我们系统地评估了这三种内容审核策略对虚假信息传播、审核精确度/召回率和用户参与动态的影响。
除了审核之外,了解某些内容如何获得关注仍然是一个开放性的挑战。在线讨论受到内容扩散动态的影响,其中一些帖子吸引了广泛的参与,而其他帖子则几乎无人问津。在我们的模拟中,配备记忆、自我反思和显式推理机制的LLM驱动代理能够解释他们的决策并随时间调整其行为。尽管我们的主要焦点是审核,但这种扩展视角有助于上下文化虚假信息和其他内容如何在在线互动中传播。为此,我们的主要贡献如下:
- 我们从头构建了一个新颖的多代理模拟,其中LLM驱动用户动态地与在线内容互动,实现了对社交行为和内容扩散的真实建模。有趣的是,我们发现代理可以准确地建模个体,但它们在模拟某些(更常见的)人口统计群体方面表现更好(第2节)。
- 我们进行了一项关于第三方、社区和混合事实核查方法的比较研究,量化了它们在减少虚假信息的同时保持参与度的有效性。我们展示了在代理模拟中虚假信息传播速度并不像在人类社交媒体中通常观察到的那样快,并且内容审核策略不仅可以改善事实核查,还可以提高参与度(第3节)。
- 我们探索了不同内容和网络属性如何影响扩散动态,提供了关于参与模式的见解,以及为什么某些内容/用户最终会吸引更多的关注。令人惊讶的是,我们发现代理的个人详细推理可能并不能真正反映他们在群体层面的集体行动模式(第4节)。
通过结合社会科学观察、博弈论建模(Acemoglu等,2023)和LLM驱动建模,我们的工作展示了生成性代理模拟作为研究大规模在线行为、测试内容审核策略和缓解生成AI时代虚假信息风险的工具的潜力。
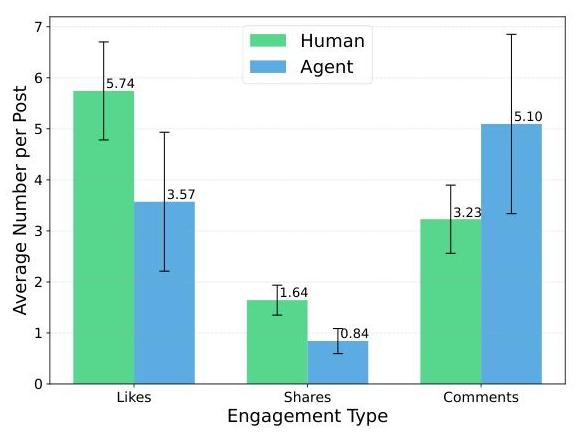
图2:每篇帖子的平均参与度:人类 vs. 代理。我们的t检验验证了这三种参与类型之间的反应模式差异不具有统计学意义,表明代理可以真实地模拟个体对社交媒体推送的反应。
我们的人工智能驱动社交网络模拟了内容如何传播、用户如何参与以及虚假信息如何在一个有向社交图中传播。如图1所示,系统的中心是一个动态环境,在这个环境中,AI代理通过关注他人、发布内容、做出反应(例如点赞、分享、评论)和报告虚假信息来互动。每个代理都根据受AgentBank(Park等,2024)启发的问题集生成的人物特征进行操作。主要模拟系统跟踪时间的进展和网络状态的演变。它得到了几个关键组件的支持:记录所有用户互动的关系数据库;将新帖子注入网络的内容管理器;监控扩散模式和用户行为的分析模块;以及评估各种内容审核策略性能的事实核查系统。
模拟网络 我们构建了一个受 X , 1 \mathrm{X},{ }^{1} X,1平台启发的模拟社交网络环境,允许AI驱动的用户互动、发布和共享内容。模拟包括一个基本的用户类,具有用户名、帖子、粉丝、关注和转发等属性,模仿现实世界社交媒体平台的结构。网络本身由关注关系定义,创建了用户互动的网络,用有向图 G = ( N , E ) G=(N, E) G=(N,E)表示。
1 其中 N N N表示用户节点集合,即 N = { n 1 , n 2 , … , n k } N=\left\{n_{1}, n_{2}, \ldots, n_{k}\right\} N={n1,n2,…,nk},其中 n i n_{i} ni是网络中的一个用户。 E ⊆ N × N E \subseteq N \times N E⊆N×N表示有向边集合,即 E = { ( n i , n j ) ∣ n i E=\left\{\left(n_{i}, n_{j}\right) \mid n_{i}\right. E={(ni,nj)∣ni 关注 n j } \left.n_{j}\right\} nj}。每条边 ( n i , n j ) \left(n_{i}, n_{j}\right) (ni,nj)表示用户 n i n_{i} ni关注用户 n j n_{j} nj。
2.1 模拟流程
模拟从初始化阶段开始,系统加载实验配置,设置数据库(详见附录D),生成初始用户群体(更多细节见附录A),并建立关注关系。代理被配置为在不同的行为特征下运行,反映现实世界中社交媒体参与的多样性。在所有实验中,除非另有说明,代理由gpt-4o(Hurst等,2024)作为基础模型主干驱动。我们也实施了一个选项,通过SGLang(Zheng等,2024)或vLLM的推理引擎连接代理与开放权重模型(Kwon等,2023)。
在每个时间步长,基于预定义参数引入新闻内容,代理根据自己的推送动态响应。代理可以根据自己的兴趣选择生成帖子。然而,在某些控制实验中,我们将其配置为仅通过点赞、分享、评论或举报虚假信息等方式参与。我们在附录E中描述了更通用的动作空间和他们决策过程的更多细节。帖子的可见性基于参与度指标演变,模拟算法放大效果。如果启用了事实核查,代理将纳入审核信号,即他们会被提示更加关注潜在的虚假内容或虚假信息,相应调整其互动方式(我们在第3节中更深入地讨论了内容审核模拟)。在此过程中,系统跟踪关键统计数据,包括内容覆盖范围、用户影响力和虚假信息传播情况。在每次模拟运行结束时,进行事后分析以评估内容扩散动态、用户参与度指标、影响力分布以及事实核查干预的影响。我们还跟踪各种网络属性,如中心性和三角闭合,并进行同质性分析以检查用户参与中的聚类模式。
| 类别 | 显著差异 | 非显著差异 |
|---|---|---|
| 年龄 | 25 − 34 25-34 25−34(分享) | 18 − 24 , 35 − 44 , 45 − 54 , 55 − 64 , 65 − 74 18-24,35-44,45-54,55-64,65-74 18−24,35−44,45−54,55−64,65−74 |
| 性别 | 男性(喜欢、分享) | 女性 |
| 宗教 | 印度教(喜欢),伊斯兰教(分享) | 无宗教信仰,精神信仰,基督教,犹太教 |
| 种族群体 | 西班牙裔/拉丁裔,黑人/非洲裔(分享), | 白人/高加索人,混血,其他 |
| 亚裔(评论) | ||
| 教育 | 中学(分享),博士学位(喜欢) | 高中,本科,技术,研究生 |
| 收入 | $10K-$20K$(评论),$70K-$80K$(喜欢) | 各种其他收入档次 |
| 政治立场 | 保守派(分享),非常保守派(喜欢) | 非常自由派,温和派,自由派,自由意志派 |
2.2 人类验证
为了验证我们模拟的真实性,我们进行了一项人类研究,比较人类和LLM代理的分享模式。我们通过Prolific招募了204名参与者。 2 { }^{2} 2 更多关于我们人类调查的细节请参阅附录B。
设置 在这项复制研究的第一阶段,我们进行了一项调查,收集了人口统计数据(如年龄、性别、宗教、种族、教育水平、语言、居住地、收入、政治立场)和个人价值观及行为(如时间使用、优先事项、亲密关系的性格、社交行为、爱好、居住历史、社交目标、有意义的生活事件、重视的友谊特质、财务习惯)。受Park等人(2024)的启发,我们使用这些匿名数据为204名LLM驱动的代理创建个性化的人物特征,每位对应一位人类参与者。
在第二阶段,参与者及其对应的LLM代理都被展示两个包含30个帖子的精选社交媒体快照。他们被指示使用一组固定的动作(如点赞、不喜欢、评论、分享)对每个帖子作出反应。代理仅根据分配给他们的角色档案进行指导,遵循相同的指令。然后我们分析并比较了人类和代理的整体及各人口统计组的参与模式,以评估LLM能否仅基于人物信息成功模仿人类的社交媒体行为。
模拟/人类反应一致性 我们的分析比较了204名人类参与者和相同数量的个性化复制AI代理在30个多样化的社交媒体帖子上的参与行为,针对每种参与类型使用独立的双样本t检验。 10 % 10 \% 10% 的文章是经NewsGuard验证的假新闻文章。
如图2所示,赞(
t
=
1.33
,
p
=
\mathrm{t}=1.33, \mathrm{p}=
t=1.33,p= 0.19)或评论(
t
=
−
1.05
,
p
=
0.30
\mathrm{t}=-1.05, \mathrm{p}=0.30
t=−1.05,p=0.30)均未出现统计学意义上的差异,尽管人类的赞略多(+2.17次/帖),而代理的评论略多(+1.87次/帖)。在分享方面观察到了边缘显著的差异(
t
=
2.11
,
p
=
0.04
t=2.11, p=0.04
t=2.11,p=0.04),人类分享略多(+0.80次/帖)。这些结果表明,角色驱动的AI代理表现出的参与模式与人类非常接近,支持了我们模拟的真实性。进一步的人口统计级别分析(表1)发现,在检查的52个人口统计子组中,只有14个在至少一种参与指标上显示出统计学意义上的差异(
p
<
0.05
\mathrm{p}<0.05
p<0.05)。值得注意的差异出现在25-34岁年龄组(分享)和几个宗教、种族、教育、收入和政治类别中。然而,大多数人口统计组没有显著差异,表明代理在模拟典型参与行为方面对那些在LLM训练数据中更常见的人口统计组更为准确。我们在附录B中提供了更多关于每人口统计组参与模式一致性的细节。
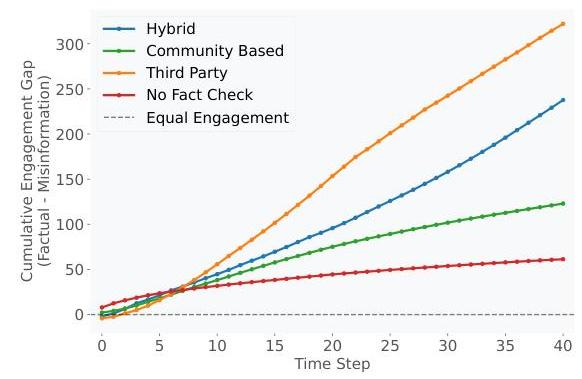
图3:不同内容审核方法在促进事实内容方面的有效性。正值:事实内容获得更多参与。负值:虚假信息获得更多参与。
3 模拟社交环境中的内容审核
我们使用多代理模拟框架进行了一系列实验,以研究不同事实核查策略对事实和虚假信息传播的影响。我们的研究揭示了LLM驱动的社会模拟和人类社交网络在虚假信息传播方式上的关键差异。
3.1 设置
数据来源 我们从NewsGuard获得了数据许可,以访问其独立记者团队追踪的广泛虚假信息叙事的专有信息。我们从其数据库中收集了截至2024年12月19日发布的1353个虚假新闻示例。 4 { }^{4} 4
为了收集真实新闻,我们利用新闻聚合API 5 { }^{5} 5 来检索2025年1月31日至2月28日期间每日发表的文章。系统查询API获取所有可用主题,优先选择英文热门文章。对于指定范围内的每一天,我们提取检索到文章的关键信息,包括标题、描述、主要内容和发表日期。使用NewsAPI,我们共抓取了2470篇真实新闻。由于其中大部分是非政治新闻,来自主流媒体,因此我们认为它们相对于NewsGuard API验证的政治虚假信息而言是“真实新闻”。
环境初始化 我们的模拟涉及代理用户在四种不同的事实核查条件下与新闻帖子互动:(1) 无事实核查,(2) 社区事实核查,(3) 使用离线LLM的第三方事实核查,该LLM使用其自身参数知识,(4) 混合事实核查,后者整合了社区和第三方验证机制。模拟从50个代理开始,跨越40个时间步长,代理根据帖子的真实性感知和内容审核的存在与否(或不存在)做出互动决策。在每个新步骤中,我们随机向环境中引入最多2个新代理,以模拟社交媒体平台的常规用户增长。我们分析了整体帖子参与度以及事实核查策略抑制虚假信息的有效性。
代理的动作空间在不同的事实核查条件下有所不同,反映了他们在社交媒体互动中不同的审查和干预水平。在无事实核查设置中,代理可以自由与推送互动,仅基于他们的兴趣和信念参与帖子。他们可以选择点赞、分享、评论(限250字符)或忽略帖子,没有任何明确要求去评估内容的准确性。在第三方事实核查条件下,动作空间保持不变,但环境隐含假设外部事实核查员可能存在,影响帖子的可见性或可信度。然而,代理本身不会执行任何直接验证。相比之下,社区事实核查设置扩展了动作空间,允许代理为其认为误导性或需要额外背景的帖子添加社区注释,以及对现有社区注释进行有用或无用评级。这引入了参与元素,鼓励代理为众包验证系统做出贡献。最后,混合事实核查条件结合了第三方和社区驱动验证的元素。代理可以在以前的设置中参与帖子,同时考虑官方事实核查和社区注释,添加自己的注释并对他人撰写的内容进行评级。在所有条件下,代理必须从预定义的有效动作中选择,确保响应格式的一致性。此外,当启用推理时,代理需要通过为每个选定动作提供简短解释来证明其互动理由,从而进一步增强其行为的可解释性。
事实核查LLM 此代码中呈现的事实核查器是一种自动内容验证系统,旨在识别和处理社交平台上的虚假信息。它通过基于参与度指标(点赞、分享、评论)、新闻分类和用户标记来优先审查帖子,特别是在混合事实核查场景中收到社区注释的内容给予特别优先级。该系统利用LLM(实验中使用gpt-4o)分析帖子内容并给出“真”、“假”或“未验证”的裁决,每个裁决都附带解释、置信分数和支持来源来自模型的训练数据。当帖子被认为错误(标准模式下置信度≥0.9,或混合模式下带有社区注释时置信度≥0.7)时,系统会自动将其删除并记录理由。所有事实核查结果都会存储在数据库中,当有可用的地面真相数据时,该数据库维护裁决的审计追踪。
网络初始化 我们使用Barabási-Albert模型(Barabási和Albert,1999)初始化一个由LLM驱动代理组成的无标度网络,这些代理在一个有向社交图中互动。虚假信息和事实内容以受控速率注入系统,代理基于其人物特征和决策过程动态参与。每种审核策略都在单独的实验中实现,允许进行比较分析。我们将在附录F中提供更多关于实验配置的详细信息。
3.2 模拟代理中虚假新闻并未比真实新闻传播得更快
我们模拟的一个关键洞察与人类社交网络已建立的结果相矛盾:虚假新闻并未比真实新闻传播得更快(图4)。此前关于人类社交行为的研究一致表明,虚假信息传播得更快、更深,而非事实内容(Vosoughi等,2018;Zhao等,2020)。然而,在我们的基于代理的模拟中,即使在没有事实核查的情况下,虚假信息的参与度(特别是分享)也未能超过事实新闻。
从图4可以看出,在所有实验条件下,事实新闻通常比虚假信息获得更高水平的参与度。这一趋势在第三方和混合事实核查设置中尤为明显,其中事实与虚假新闻互动的分离达到最大。即使在无事实核查的情况下,虚假信息也未能占据主导地位,这表明LLM驱动的代理可能天生避免与未经验证或误导性内容互动。
3.3 内容审核既提高了事实核查又提高了参与度
虽然在模拟中政治虚假信息并未比事实新闻传播得更快,另一个重要观察是,在没有事实核查的情况下,整体参与度显著较低。图4显示,在无事实核查的情况下,即使是事实帖子也未能获得大量参与。
这表明,当没有明确的事实核查机制时,代理倾向于完全抑制其互动,而不是随意参与不可靠内容。我们假设这种行为源于LLM代理对政治虚假信息的固有敏感性,导致它们为了避免放大不确定信息而选择不参与。
为了解决这种脱节问题,我们引入了各种事实核查机制,并观察到它们不仅抑制了虚假信息的传播,还增强了对事实新闻的参与度。如图3所示,我们观察到不同内容审核方法如何随着时间推移影响事实内容和虚假信息之间的参与平衡。第三方事实核查成为最有效的干预措施,为事实内容建立了显著的累积优势,最终时间步时约达325单位,显著优于所有其他方法。值得注意的是,即使在无事实核查条件下,仍保持正向趋势,表明在模拟环境中事实内容可能具有一些内在的参与优势,但这种优势通过积极的审核策略大幅放大。持续正面且逐渐分化的趋势表明审核效果随时间累积,方法间的差距逐步扩大而非稳定。这表明内容审核不仅创造了即时好处,还为事实信息生成了随着时间推移而加强的累积优势,其中第三方专业事实核查在创建健康的信息生态系统方面表现出特别的效力。这在某种程度上得到一些人类用户研究的支持,这些研究表明内容审核增加了未标记内容的信任度(Pennycook等,2020)。
3.4 事实核查表现:混合模型实现最佳权衡
尽管第三方事实核查实现了最佳的参与度分离效果,我们使用精确度、召回率和F1分数评估事实核查有效性(表2)。结果显示,混合方法提供了最佳的整体事实核查性能,达到了0.625的精确度、0.6的召回率和0.612的F1分数,是我们探索的三种方法中最高的。
这表明社区和第三方验证相结合可以最可靠地识别虚假信息,在召回率(虚假新闻覆盖率)和精确度(检测准确性)之间取得平衡。相比之下,单独的第三方事实核查由于召回率低(15.6%),尽管在标记帖子为虚假信息时选择性较强,但可能无法有效捕捉所有虚假声明。另一方面,社区为基础的模型虽然召回率较高但精确度较低,导致整体表现适中。
4 探讨:是什么让某些用户/内容更受欢迎?
理解为什么某些内容会在在线空间中引起关注对于建模参与动态和干预策略至关重要。在本节中,我们分析帖子的扩散特性,特别是代理对不同类型社交媒体内容的反应。
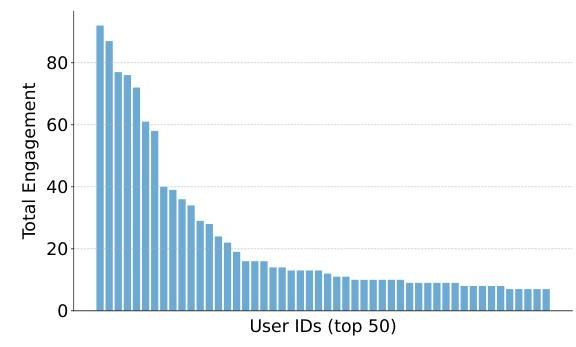
图5:参与度最高的前50名用户。
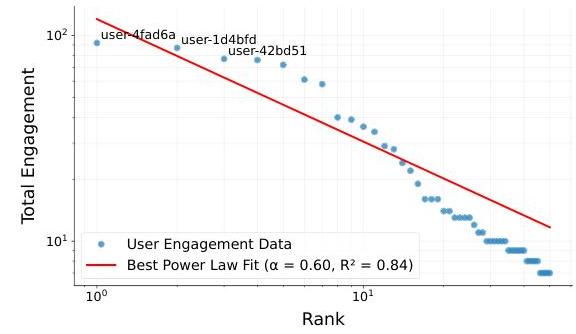
图6:用户参与度的最佳幂律拟合。
实验设置 我们生成了一组多样化的内容类型,包括新闻、评论文章和用户生成的帖子,每种内容的争议性、情感和来源可信度各不相同。代理根据其人物特征、参与信号和基于记忆的决策与这些帖子互动。在这个实验中,代理不再只是被动地对社交推送做出反应,还会参与生成在网络中传播的新内容。我们将两次模拟运行结合起来,总共包括161个代理和4,249个帖子。
4.1 研究结果
我们的研究通过分析多个维度(包括用户受欢迎程度、人物属性、内容主题和代理推理模式)来探究模拟社交媒体环境中用户参与的根本驱动力。我们首先将用户受欢迎程度定义为关注者、点赞、分享和评论的总和,并在图5中观察到用户参与度遵循幂律分布。最佳拟合近似为 f ( x ) = 120 x − 0.6 f(x)=120 x^{-0.6} f(x)=120x−0.6, R 2 = 0.84 R^{2}=0.84 R2=0.84(图6),确认了对幂律行为的遵守,即少数用户产生了大部分的参与度。尽管我们的指数 α = 0.60 \alpha=0.60 α=0.60低于实际网络中报道的典型范围(1.5-2.5)(Muchnik等,2013;Bild等,2015),但它仍然突出了内容受欢迎程度的倾斜性质。
然后我们探讨用户参与是否与人物属性相关,通过比较前50名和后50名用户的多个特征。总结在表3中的卡方分析显示,在诸如年龄、性别、活动类型、爱好、种族、收入水平、政治倾向或主要目标等类别中没有统计显著差异。虽然种族和爱好的中等效应量(Cramer’s V分别为0.319和0.302)被注意到(Cramér,1946),但缺乏统计显著性强调了这些特征对参与度的影响不大。此外,模拟中没有包括公众人物或名人式的人物,表明即使在随机初始化的情况下,一部分用户自然会吸引更多注意力,突出了此类网络中参与度的不可预测性。
为了评估内容主题是否驱动参与,我们使用BERTopic(Grootendorst,2022)和all-MiniLM-L6-v2嵌入(Reimers和Gurevych,2019)对帖子内容进行聚类,并计算每个主题的参与统计。ANOVA测试返回F统计量为0.614,p值为0.84,表明内容主题与参与之间没有统计显著关系。这表明语义内容本身不足以可靠地影响用户反应。
鉴于参与度与人口统计或主题属性之间缺乏相关性,我们转向推送优先级机制。我们的系统强调近期和关注关系,而非基于参与度的排名,但这种设置无意中创建了一个反馈循环。一旦用户被关注,他们的内容就会获得更多曝光,这可能会进一步增加参与度和可见性,从而强化用户的受欢迎程度。这些发现促使我们推测,幂律影响力分布可能源自代理的行为动态,例如模仿早期代理的行为,形成偏好依附循环,从而强化受欢迎程度,而非源自其个人资料属性或生成的具体内容。
表3:基于人口统计属性的参与差异的卡方检验结果
| 属性 | 卡方值 | p值 | Cramer’s V | 效应大小 |
|---|---|---|---|---|
| 年龄组 | 1.632 | 0.652 | 0.128 | 小 |
| 性别 | 0.653 | 0.721 | 0.081 | 可忽略 |
| 活动 | 5.030 | 0.412 | 0.224 | 小 |
| 爱好 | 9.101 | 0.246 | 0.302 | 中等 |
| 种族 | 10.187 | 0.070 | 0.319 | 中等 |
| 收入水平 | 4.373 | 0.358 | 0.209 | 小 |
| 政治倾向 | 2.515 | 0.642 | 0.159 | 小 |
| 主要目标 | 8.064 | 0.089 | 0.284 | 小 |
最后,我们检查代理的推理痕迹以更好地理解参与行为。表4突出显示了与不同行动相关的不同情绪和动机模式。积极情绪主导着诸如关注(99%)、评论(97%)、点赞(92%)和分享(92%)等行动,而在标记(71%)和取消关注(40%)中消极情绪占主导地位。动机推理因行动类型而异:标记源于质量评估(49%)和虚假信息担忧(22%),而分享反映了同意(46%)。点赞和评论受社交联系和同意驱动,而关注则基于长期兴趣。词汇分析进一步揭示参与类型依赖于特定领域的词汇。然而,仍存在显著的脱节:仅有21%的帖子与代理推理的情绪一致,这意味着代理的口头理由并未完全捕捉到其选择背后的深层影响因素。尽管阐述了价值对齐和相关性的理由,但这些因素并不能可靠地预测受欢迎程度,进一步支持了个体背景和网络动态的作用。
总体而言,这些发现描绘出一幅复杂的图景:尽管代理为参与行动提供了结构化的推理,但总体受欢迎程度和内容病毒传播更多地来源于用户或内容属性以外的新兴社会动态和结构效应。我们在附录H中提供了更详细的讨论和分析。
5 背景
行为经济学和说服游戏。我们使用由LLM驱动的代理,基于细致的人物特征(Kamenica和Gentzkow,2011;
Gentzkow和Kamenica,2017;Acemoglu等,2023)来计算性建模一个顺序说服游戏。这些代理在一个有向社交图中运作,并基于记忆和社会背景进化,使得可以研究在线行为、干预策略和调节效果。
LLM驱动的社会模拟。LLM已经通过使上下文感知和生成行为成为可能,彻底改变了基于代理的建模。虽然早期的模拟——如Schelling的隔离模型(Schelling,1971)、Sugarscape(Epstein和Axtell,1996)以及基于NetLogo的环境(Wilensky,1999)——依赖于静态启发式规则,最近的系统如Smallville(Park等,2023)、AgentVerse(Chen等,2024a)和Chirper(Minos,2023)展示了具有逼真互动和社交动态的代理。然而,LLM驱动的代理仍然面临诸如不一致性和有限长期推理等挑战。我们的工作通过引入结构化约束和迭代反馈来增强可靠性,以促进社会科学研究。
虚假信息和事实核查。虚假信息往往比真相传播得更快,这是由于情感吸引力和以参与度驱动的算法(Vosoughi等,2018;Pennycook和Rand,2021;Solovev和Pröllochs,2022)。现有的应对措施——第三方事实核查(Raghunath和Malik,2024;Patel,2024)、算法检测和社区笔记等众包调节 6 { }^{6} 6——各自在可扩展性、准确性和偏见方面面临限制(Zannettou等,2019;Panizza等,2023)。我们使用基于LLM的模拟在受控环境中评估这些方法,比较其有效性并探索混合策略。
模拟治理和政策。模拟长期以来一直支持流行病学和公共政策等领域的决策(Currie等,2020;Axtell和Farmer,2022;Qu和Wang,2024)。在社交媒体治理背景下,基于LLM的模拟为评估内容调节和算法干预提供了一个新的试验场(Charalabidis等,2011;Landau等,2024)。我们的框架使得能够大规模实验监管策略,为算法审计和平台问责的持续努力做出贡献。
6 结论
我们的研究引入了一种新型的多代理生成AI模拟,用于建模社交网络中的内容扩散、参与和虚假信息动态。通过使用LLM驱动的代理,我们在高度真实的情境下将社会科学与计算建模结合。我们发现,结合社区和第三方事实核查的混合内容调节方法在减少虚假信息和提高用户参与之间取得了最佳平衡。值得注意的是,LLM代理倾向于避免未经验证的内容,这可能是由于安全培训所致,虚假信息并没有比事实新闻传播得更快,这与人类研究的情况不同。参与度遵循幂律分布,少数用户推动了大部分活动。然而,用户属性和内容主题是弱预测因子,突显了在线生态系统的复杂性。代理推理显示出声明动机与实际行为之间的差距,表明网络效应比人口统计或内容更能塑造参与度。
局限性
我们的研究结果受到若干局限性的制约,尤其是在实验规模方面。首先,少数族裔人口群体中的有限人数限制了我们结论的统计能力。扩大参与者多样性将使我们能够对真实与模拟社会互动模式在不同人口群体中的对齐情况进行更稳健的分析。其次,我们的内容调节实验是在相对较小的规模下进行的,这可能限制了复杂行为的出现。在更大规模下进行这些实验可能会揭示当前研究中未捕捉到的额外动态。第三,我们的模拟中的事实核查代理缺乏实时网络搜索功能,限制了他们根据最新或外部信息源验证主张的能力。增强他们对实时数据的访问可能会显著提高其可靠性和实用性。最后,我们观察到代理对其行动的明确解释与系统中出现的集体反应模式之间存在差距。这种错位的根本原因尚不清楚,值得进一步研究,可能涉及对代理建模假设或社会影响机制的更深入分析。
致谢
本研究部分得到了OpenAI慷慨提供的研究信用支持。此外,作者还要感谢Jacob Andreas教授提供的宝贵反馈和富有洞察力的建议。
参考文献
Daron Acemoglu, Asuman Ozdaglar, and James Siderius. 2023. 在线虚假信息模型. Review of Economic Studies, page rdad111.
Thomas Aichner, Matthias Grünfelder, Oswin Maurer, 和 Deni Jegeni. 2021. 25年的社交媒体:1994年至2019年社交媒体应用和定义的综述. Cyberpsychology, behavior, and social networking, 24(4):215-222.
Robert L Axtell 和 J Doyne Farmer. 2022. 经济学和金融学中的基于代理的建模:过去、现在和未来. Journal of Economic Literature, 14.
Albert-László Barabási 和 Réka Albert. 1999. 随机网络中尺度的出现. science, 286(5439):509-512.
David R Bild, Yue Liu, Robert P Dick, Z Morley Mao, 和 Dan S Wallach. 2015. Twitter用户行为的聚合特征分析及转发图分析. ACM Transactions on Internet Technology (TOIT), 15(1):1-24.
Eric Bonabeau. 2002. 基于代理的建模:模拟人类系统的方法和技术. Proceedings of the national academy of sciences, 99(suppl_3):7280-7287.
Yannis Charalabidis, Euripidis Loukis, 和 Aggeliki Androutsopoulou. 2011. 通过建模和模拟增强参与性政策制定:现状回顾. In Proceedings of the European, Mediterranean and Middle Eastern Conference on Information Systems-Informing Responsible Management: Sustainability in Emerging Economies, EMCIS, pages 210-222.
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. 2024a. Agentverse:促进多代理协作和探索新兴行为. In ICLR.
Weize Chen, Ziming You, Ran Li, Yitong Guan, Chen Qian, Chenyang Zhao, Cheng Yang, Ruobing Xie, Zhiyuan Liu, 和 Maosong Sun. 2024b. 代理人联网:编织一个异构代理人网络以实现协作智能. arXiv preprint arXiv:2407.07061.
Matteo Cinelli, Gianmarco De Francisci Morales, Alessandro Galeazzi, Walter Quattrociocchi, 和 Michele Starnini. 2021. 社交媒体中的回声室效应. Proceedings of the national academy of sciences, 118(9):e2023301118.
Harald Cramér. 1946. 数理统计方法. Princeton University Press.
Christine SM Currie, John W Fowler, Kathy Kotiadis, Thomas Monks, Bhakti Stephan Onggo, Duncan A Robertson, 和 Antuela A Tako. 2020. 模拟建模如何帮助减少新冠疫情的影响. Journal of Simulation, 14(2):83-97.
Joshua M Epstein. 1999. 基于代理的计算模型和生成社会科学. Complexity, 4 ( 5 ) : 41 − 60 4(5): 41-60 4(5):41−60.
Joshua M Epstein 和 Robert Axtell. 1996. 生长人工社会:自下而上的社会科学. Brookings Institution Press.
Chen Gao, Xiaochong Lan, Zhi jie Lu, Jinzhu Mao, Jing Piao, Huandong Wang, Depeng Jin, 和 Yong Li. 2023. S3:具有大语言模型赋能代理的社交网络模拟系统. ArXiv, abs/2307.14984.
Matthew Gentzkow 和 Emir Kamenica. 2017. 贝叶斯说服中的多个发送者和丰富的信号空间. Games and Economic Behavior, 104:411-429.
Maarten Grootendorst. 2022. BERTopic:基于类别的TF-IDF过程的神经主题建模. arXiv preprint arXiv:2203.05794.
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o系统卡。arXiv预印本arXiv:2410.21276。
Md Rafiqul Islam, Shaowu Liu, Xianzhi Wang, 和 Guandong Xu. 2020. 在线社交网络中虚假信息检测的深度学习:调查与新视角。Social Network Analysis and Mining, 10(1):82。
Jennifer Jerit 和 Yangzi Zhao. 2020. 政治虚假信息。Annual Review of Political Science, 23(1):77-94。
Emir Kamenica 和 Matthew Gentzkow. 2011. 贝叶斯说服。American Economic Review, 101(6):2590-2615。
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, 和 Ion Stoica. 2023. 使用分页注意力进行大型语言模型服务的有效内存管理。在第29届操作系统原理研讨会论文集,页面 611 − 626 611-626 611−626。
Susan Landau, James X Dempsey, Ece Kamar, Steven M Bellovin, 和 Robert Pool. 2024. 挑战机器:政府AI系统中的可争议性。arXiv预印本arXiv:2406.10430。
Stephan Lewandowsky, Ullrich KH Ecker, Colleen M Seifert, Norbert Schwarz, 和 John Cook. 2012. 虚假信息及其纠正:持续影响和成功去偏见。Psychological science in the public interest, 13(3):106-131。
Genglin Liu, Xingyao Wang, Lifan Yuan, Yangyi Chen, 和 Hao Peng. 2023. 考察LLMs对参数知识之外问题的不确定性表达。arXiv预印本arXiv:2311.09731。
Fabian Lorig, Emil Johansson, 和 Paul Davidsson. 2021. 新冠疫情的大规模基于代理的社会模拟:系统综述。JASSS: Journal of Artificial Societies and Social Simulation, 24(3)。
Morgan Marietta, David C Barker, 和 Todd Bowser. 2015. 事实核查两极化政治:事实核查行业是否为有争议的事实提供一致指导?In The forum, 卷13, 页面577-596。De Gruyter。
Stephan Minos. 2023. Chirper:通过自主性和娱乐改变AI景观。Chirper博客。
Lev Muchnik, Sen Pei, Lucas C Parra, Saulo DS Reis, José S Andrade Jr, Shlomo Havlin, 和 Hernán A Makse. 2013. 社交网络中人类活动异质性导致幂律度分布的起源。Scientific reports, 3(1):1783。
OpenAI. 2024. 打破隐蔽影响操作对AI的欺骗使用。
Amy Orben, Andrew K Przybylski, Sarah-Jayne Blakemore, 和 Rogier A Kievit. 2022. 社交媒体发展的敏感窗口。Nature Communications, 13(1):1649。
Folco Panizza, Piero Ronzani, Tiffany Morisseau, Simone Mattavelli, 和 Carlo Martini. 2023. 在线用户如何回应众包事实核查?Humanities and Social Sciences Communications, 10(1):1-11。
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, 和 Michael S Bernstein. 2023. 生成性代理:人类行为的互动仿真。In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1-22。
Joon Sung Park, Lindsay Popowski, Carrie Cai, Meredith Ringel Morris, Percy Liang, 和 Michael S Bernstein. 2022. 社会仿真:为社会计算系统创建人口原型。In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology, pages 1-18。
Joon Sung Park, Carolyn Q Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, 和 Michael S Bernstein. 2024. 生成性代理的1000人模拟。arXiv预印本arXiv:2411.10109。
Uma Patel. 2024. 新的合作关系和倡议以加强在线事实核查。
Gordon Pennycook, Adam Bear, Evan T Collins, 和 David G Rand. 2020. 暗示真相效应:对部分假新闻标题附加警告提高了未附警告标题的感知准确性。Management science, 66(11):4944-4957。
Gordon Pennycook, Ziv Epstein, Mohsen Mosleh, Antonio A Arechar, Dean Eckles, 和 David G Rand. 2021. 将注意力转移到准确性上可以减少在线虚假信息。Nature, 592(7855):590-595。
Gordon Pennycook 和 David G. Rand. 2021. 假新闻的心理学。Trends in Cognitive Sciences, 25:388-402。
Yao Qu 和 Jue Wang. 2024. 大型语言模型在舆论模拟中的表现和偏差。Humanities and Social Sciences Communications, 11(1):1-13。
Durga Raghunath 和 Surabhi Malik. 2024. 与新闻出版商和事实核查员合作,打击2024年印度大选前的虚假信息。
Nils Reimers 和 Iryna Gurevych. 2019. Sentence-BERT:使用孪生BERT网络的句子嵌入。arXiv预印本arXiv:1908.10084。
Mohammed Saeed, Nicolas Traub, Maelle Nicolas, Gianluca Demartini, 和 Paolo Papotti. 2022. 推特上的众包事实核查:人群与专家相比如何?In Proceedings of the 31st ACM国际信息与知识管理会议,pages 1736-1746。
Thomas C Schelling. 1971. 隔离的动态模型。Journal of mathematical sociology, 1(2):143186。
Kirill Solovev 和 Nicolas Pröllochs. 2022. 道德情感塑造新冠虚假信息在社交媒体上的传播。In Proceedings of the ACM web conference 2022, pages 3706-3717。
Briony Swire-Thompson, David Lazer, 等. 2020. 公共健康与在线虚假信息:挑战与建议。Annu Rev Public Health, 41(1):433-451。
Joseph E Uscinski 和 Ryden W Butler. 2013. 事实核查的认识论。Critical Review, 25(2):162-180。
Soroush Vosoughi, Deb Roy, 和 Sinan Aral. 2018. 真实和虚假新闻在线传播的研究。science, 359(6380):1146-1151.
Ruiyi Wang, Haofei Yu, Wenxin Zhang, Zhengyang Qi, Maarten Sap, Graham Neubig, Yonatan Bisk, 和 Hao Zhu. 2024. Sotopia- π \pi π : 社交智能语言代理的交互学习。arXiv预印本arXiv:2403.08715。
Uri Wilensky. 1999. Netlogo. 1.0.
Liang Wu, Fred Morstatter, Kathleen M Carley, 和 Huan Liu. 2019. 社交媒体中的虚假信息:定义、操纵和检测。ACM SIGKDD explorations newsletter, 21(2):80-90.
Ziyi Yang, Zaibin Zhang, Zirui Zheng, Yuxian Jiang, Ziyue Gan, Zhiyu Wang, Zijian Ling, Jinsong Chen, Martz Ma, Bowen Dong, et al. 2024. Oasis: 百万代理开放社交互动模拟。arXiv预印本arXiv:2411.11581.
Zhenhua Yu, Si Lu, Dan Wang, 和 Zhiwu Li. 2021. 社交网络中谣言传播的建模与分析。Information Sciences, 580:857-873.
Savvas Zannettou, Michael Sirivianos, Jeremy Blackburn, 和 Nicolas Kourtellis. 2019. 虚假信息之网:谣言、假新闻、恶作剧、点击诱饵及各种其他骗局。Journal of Data and Information Quality (JDIQ), 11(3):1-37.
Zilong Zhao, Jichang Zhao, Yukie Sano, Orr Levy, Hideki Takayasu, Misako Takayasu, Daqing Li, Junjie Wu, 和 Shlomo Havlin. 2020. 假新闻即使在早期传播阶段也与真实新闻传播不同。EPJ data science, 9(1):7.
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. SGLang: 结构化语言模型程序的有效执行。Advances in Neural Information Processing Systems, 37:6255762583.
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, et al. 2023. Sotopia: 语言代理的交互评估以实现社交智能。arXiv预印本arXiv:2310.11667.
A 人物生成细节
这里我们描述了为代理用户采样和生成的问题。生成的人物特征以JSONL格式存储,每个条目包含唯一标识符、描述性叙述和相关的行为标签。
A. 1 从人类调查复制人物
人物生成方法首先将从Prolific参与者收集的结构化调查响应转换为适合在基于代理的模拟中使用的丰富自然语言
角色描述。每位参与者的回答——涵盖了广泛的个人、人口统计、社会和心理特征——以JSONL格式编码,其中每一行对应不同的个体。我们首先将此文件转换为Python字典列表,每个字典代表单个参与者的答案。预处理管道然后将每个答案嵌入到模板化的句子结构中。这包括诸如年龄、性别、居住背景、生活过的地方数量、最喜欢的活动、价值观、政治立场、收入、种族、语言、教育、宗教、社会倾向、爱好、关系价值、个性、未来目标、重要生活事件、友谊价值和假设财务决策等细节。通过用流畅的第一人称风格英语表达这些特征,该函数本质上将每位参与者的世界观和身份复制为一个逼真的角色,可以在社交模拟中引导代理行为。最后一步遍历所有参与者条目,为每个条目生成相应的自然语言人物特征,并将丰富后的数据——包括原始回答和生成的描述——写回新的JSONL文件。这个过程在原始人类调查数据和基于心理学的角色配置之间建立了一个桥梁,使多代理环境中的行为更加现实和多样化。
A. 2 来自Agent Bank的合成人物
与从调查响应派生的人工注释人物不同,我们还通过从结构化问题库中采样生成完全合成的人物,称为Agent Bank。该库包含一组精心策划的23个多项选择题,涵盖身份、背景和社会导向的关键维度——从年龄和性别到价值观、教育、爱好和政治归属。请参阅代码仓库以获取它们的完整内容和答案选项。每个问题都被分配一个标签和一组固定的可能答案。为了模拟人类般的多样性,我们通过概率抽样答案来构建代理人物,有时使用均匀随机选择,有时利用精心构造的分布以更好地反映现实世界的人口动态。例如,年龄是从中心值为35岁、上下限为18至60岁的正态分布生成的,而性别则从反映近似社会比例的分布中抽样。在某些情况下,显式建模了特征之间的依赖关系——例如,主要语言是根据一个人的种族条件抽样的,使用手动指定的概率分布反映各族裔的语言普遍性。这些抽样答案随后被组装成一个属性字典。从此,我们使用两种方法之一生成自然语言人物描述。第一种方法使用硬编码模板,确定性地将抽样答案编织成连贯段落,模仿用于真实调查基础人物的风格和结构。第二种更动态的方法利用GPT-4o从相同的底层属性生成创意且多样的人物描述。精心设计的系统提示指示模型保留属性字典中的每一条信息,同时生成一段流畅的第二人称段落,呈现结果为可信且详细的背景故事。这确保每个代理保持一致且完整的身份,同时允许风格多样性的空间。最终,每个合成人物都作为包含唯一ID、完整自然语言描述和相关标签-值对的结构化JSON对象存储,准备好在下游模拟中部署为代理。
A. 3 用户生成和实例化
仿真的基础在于创建现实的个体代理虚拟用户。每个代理都以详细的人物特征实例化,该特征塑造其在线行为和参与模式。
人物生成 如图1所示,人物是使用预先定义的问题组合和从agent_bank配置文件集合中存储的概率分布中采样生成的,灵感来源于Park等人(2024)。关键人口统计属性如年龄、性别、种族和主要语言按照概率分配,以反映现实世界的分布。例如,年龄遵循以35岁为中心的正态分布,而其他属性则基于预定义的概率进行抽样。我们在附录A中披露这些问题并描述了更多方法细节。在为代理综合生成结构化配置文件后,我们为他们每个人构建一个自然语言描述。这一过程利用了确定性规则的混合
以及使用GPT-4o(Hurst等人,2024)的LLM增强技术,以提高多样性和真实性。
用户实例化 一旦生成人物,他们就会在仿真中实例化为代理用户。每个代理被分配一个唯一的用户ID和一个包含背景详情和兴趣标签的人物配置文件。关系数据库作为记录代理活动的核心,确保互动、帖子参与和行为更新的持久存储。该数据库促进了动态用户跟踪,并支持事后分析参与趋势和内容传播情况。我们在附录D中提供了更多实施细节。
B 人类研究细节
该研究向来自更大Prolific群体的232,330名成员中的20,240名符合条件的参与者开放,并从符合条件的参与者中收集了204份有效回复。通过Prolific进行调查,收集美国本土精通英语的参与者的意见。参与者被要求完成一份评估其人口统计特征和社会媒体互动的12分钟调查。该调查托管在Google Forms上,无需下载软件或特殊设备功能,可通过移动设备、平板电脑或桌面访问。参与者招募应用了语言、政治光谱、疫苗意见和先前参与的自定义筛选,以确保目标样本。使用表单开头的问题收集Prolific ID作为回复,参与者完成调查后将收到完成代码。补偿按每名参与者$$ 2.40 计算,相当于 计算,相当于 计算,相当于$ 12.00 / 小时,并在批准前手动审查提交内容。中位完成时间为约 14.5 分钟。我们研究团队的所有成员在开展人类研究之前均已获得 I R B 批准。我们的研究总成本为支付给参与者的 小时,并在批准前手动审查提交内容。中位完成时间为约14.5分钟。我们研究团队的所有成员在开展人类研究之前均已获得IRB批准。我们的研究总成本为支付给参与者的 小时,并在批准前手动审查提交内容。中位完成时间为约14.5分钟。我们研究团队的所有成员在开展人类研究之前均已获得IRB批准。我们的研究总成本为支付给参与者的$ 480 和平台费用 和平台费用 和平台费用$ 160$。图7显示了204名人类参与者9个关键人口统计分布的完整分解。
B. 1 每个人口统计属性的参与模式
我们还根据特定的人口统计属性(如年龄、性别、收入、种族等)分析了人类参与者和由人物驱动的代理之间的反应模式,如表1所示。
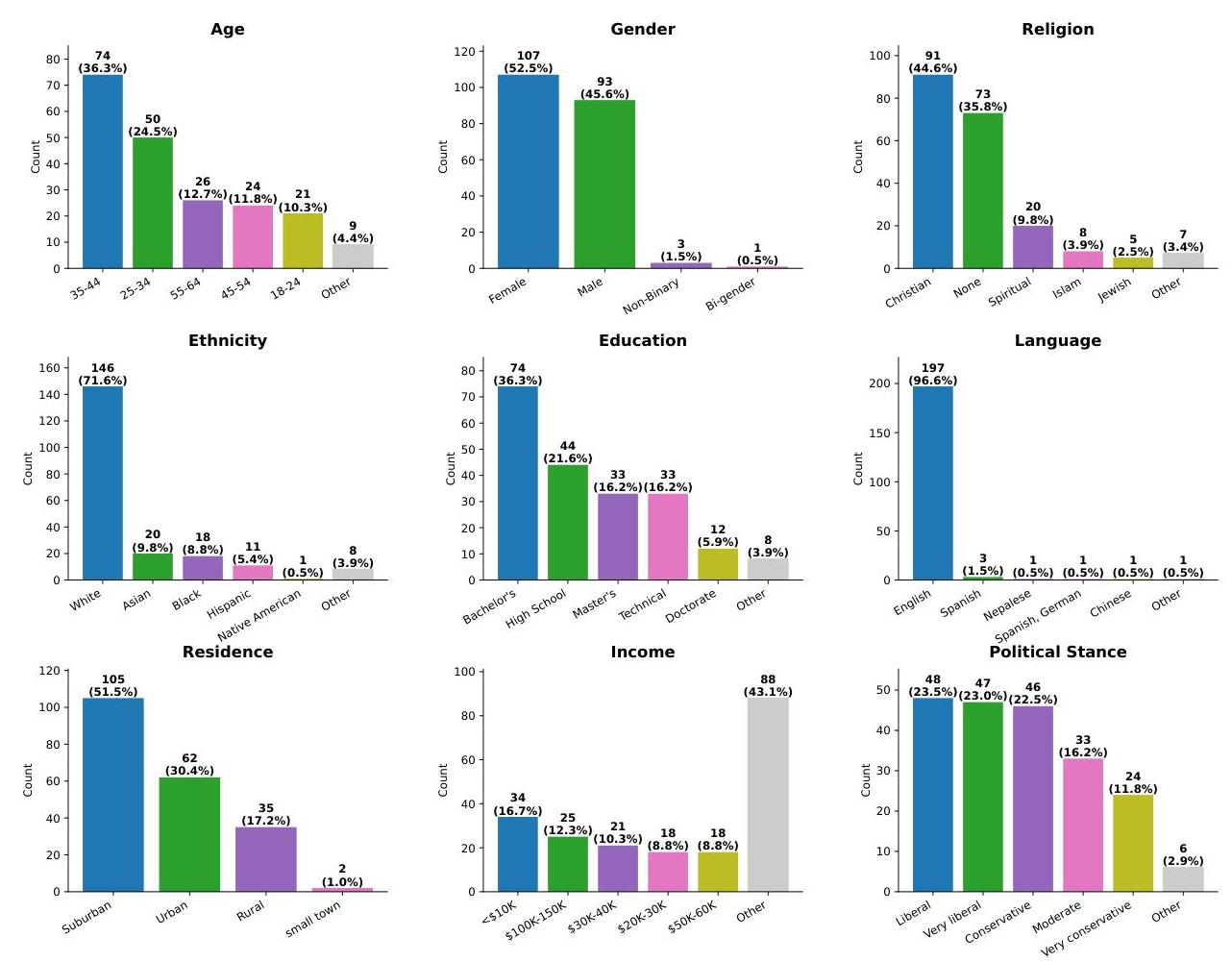
图7:研究参与者的 demographic 分布。
对人类和代理之间参与模式的分析揭示了在各种人口统计群体中的某些差异。具体来说,25-34岁年龄组在分享方面显示出显著差异,而男性在点赞和分享方面表现出显著变化。在宗教群体中,印度教和伊斯兰教分别在点赞和分享方面显示出显著差异。种族群体如西班牙裔/拉丁裔、非裔美国人和亚裔在分享和评论方面显示出显著差异。教育水平也起着作用,接受中学教育和博士学位持有者在分享和点赞方面分别显示出显著差异。收入水平在$$ 10,000$ - $$ 19,999
和
和
和$ 70,000$ - $$ 79,999$之间显示出在评论和点赞方面的显著差异。保守派和非常保守的政治立场在分享和点赞方面也显示出显著差异。相比之下,许多其他人种统计群体,包括各种年龄范围、性别、宗教、种族、教育水平、收入阶层和政治立场,在参与类型上没有显著差异。
总体而言,在分析的52个人口统计群体中,14个在一种或多种参与类型上有显著差异,而38个没有。显著的标准是基于统计比较中p值小于0.05的结果。结果表明,代理可能更擅长模拟LLM预训练数据中“常见”或更广泛代表的人口统计群体的参与模式,正如许多这些群体中缺乏显著差异所表明的那样。
C 相关工作扩展版本
行为经济学和说服游戏。我们的系统通过计算建模了一个基于精细人物特征的顺序说服游戏(Kamenica和Gentzkow,2011;Gentzkow和Kamenica,2017;Acemoglu等人,2023)。代理在有向社交图中互动,并基于记忆和社会背景进化。该框架作为一个测试平台,用于研究在线行为、干预策略和算法调节的影响。
人工智能驱动的社会模拟和生成代理。大型语言模型(LLMs)的出现显著提升了基于代理的社会模拟的能力,使得更复杂的、情境感知的互动成为可能。传统的基于代理的建模依赖于预定义的规则集和启发式规则,限制了适应性和真实性。早期的计算社会模拟,如Schelling的隔离模型(Schelling,1971)、Sugarscape(Epstein和Axtell,1996)以及基于NetLogo的模型(Wilensky,1999),提供了关于社会动态的见解,但缺乏生成细致、情境依赖行为的能力。
最近的进展,如Smallville(Park等人,2023)、AgentVerse(Chen等人,2024a)、Internet-of-Agents(Chen等人,2024b)和Chirper(Minos,2023),利用LLMs实现了生成性代理,能够动态响应不断变化的情境。这些系统展示了AI驱动的代理如何进行类人的对话、形成社会关系以及模拟内容传播模式。然而,尽管生成性代理能够生成可信的互动,但由于LLM训练数据中固有的偏差或长期记忆和推理能力的局限性,生成性代理仍可能表现出不一致性。通过整合更多的结构化约束和迭代反馈机制,这项工作增强了基于代理的模拟在社会科学研究和政策测试中的可靠性。
虚假信息传播和事实核查机制。数字平台上虚假信息的传播已得到广泛研究(Swire-Thompson等人,2020;Jerit和Zhao,2020;Wu等人,2019;Islam等人,2020),实证证据表明虚假信息往往比事实信息传播得更快、更广(Vosoughi等人,2018)。虚假信息的病毒式传播归因于其情感吸引力、新颖性以及参与度驱动的算法无意中放大误导性叙述的作用(Pennycook和Rand,2021;Solovev和Pröllochs,2022)。为解决这一问题,发展了多种事实核查方法,包括第三方验证、算法检测和众包调节。
第三方事实核查通常由像Snopes 7 { }^{7} 7、PolitiFact 8 { }^{8} 8 或谷歌与外部组织的合作(Raghunath和Malik,2024;Patel,2024)等组织进行,提供权威评估,但在可扩展性和及时性方面面临挑战(Zannettou等人,2019;Uscinski和Butler,2013;Marietta等人,2015)。另一方面,X的社区笔记等众包事实核查利用集体智慧(Panizza等人,2023),但也引入了与专业知识和群体偏见相关的风险(Saeed等人,2022;Pennycook等人,2021)。对于哪种事实核查方法更有效,或者不同审核策略如何相互作用,尚未达成共识。本研究通过利用LLM驱动的模拟在受控环境中评估不同的事实核查机制,填补了这一空白。通过以可扩展和可重复的方式测试各种审核策略,本研究提供了关于基于社区、第三方和混合事实核查干预在减轻虚假信息方面的相对有效性的见解。
作为政策和平台治理工具的模拟 计算机模拟作为决策支持工具的应用已在流行病学(Currie等人,2020;Lorig等人,2021)、经济学(Axtell和Farmer,2022)和公共政策(Qu和Wang,2024)等领域得到了充分确立。通过在实际实施前进行情景测试,模拟帮助政策制定者预测干预措施的后果(Charalabidis等人,2011)。在社交媒体治理背景下,AI驱动的模拟提供了一个新兴机会来评估审核策略、优化干预政策,并在部署前测试算法变化的社会影响。
围绕AI治理的近期讨论强调了采取积极措施以确保平台问责制和透明度的必要性(Landau等人,2024)。监管机构和平台运营商越来越探索在大规模推广前评估内容审核调整、排名算法更改和虚假信息缓解策略的影响的方法。为此,我们的研究引入了AI驱动的社会模拟作为一种新型治理实验框架。通过
D 数据库架构
在本节中,我们描述了开发用于存储和跟踪每次模拟运行生成的所有数据的数据库架构。
这种关系型SQL数据库架构旨在支持一种社交媒体模拟,其中LLM驱动的AI代理模仿用户行为。数据库捕捉并详细组织用户生成的内容、互动和系统级流程。users表存储个人用户资料,包括元数据如人物、背景标签、影响力分数和参与度指标。posts表管理用户发布的帖子,记录内容详情、互动次数(点赞、分享、标记、评论)和审核或事实核查状态。通过follows表建模社交关系,跟踪关注-被关注连接。user_actions表记录用户参与动作,如创建内容或对帖子作出反应。comments表单独记录帖子评论及其关联元数据。社区审核通过community_notes和note_ratings表实现,允许用户贡献解释性注释并对有用性进行评级。moderation_logs记录系统审核决定。fact_checks表提供事实核查过程的详细裁决和理由。为了模拟AI代理的记忆和推理,agent_memories跟踪内部记忆的内容和重要性,带有时间戳和衰减因子。spread_metrics表量化每个帖子随时间步长的病毒性和扩散动态,包括衍生的互动统计数据和下架决定。feed_exposures表在用户级别跟踪内容曝光,支持信息可见性和覆盖范围分析。一起,这些架构捕捉了一个详细且相互关联的模拟社交媒体动态视图,基于可观测的用户行为和系统响应。
E 代理动作空间
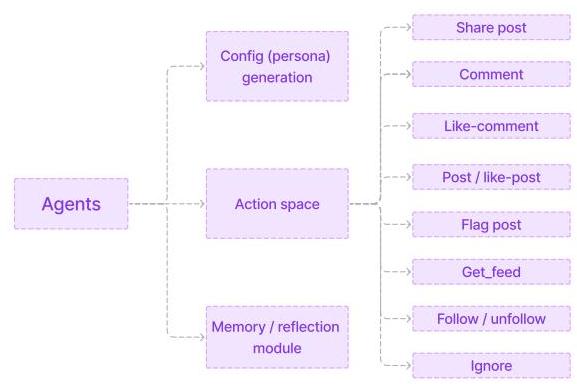
图8:代理的动作空间。
在我们的模拟社交媒体环境中,每个代理——由大型语言模型驱动——实例化时具有一个预定义的动作空间,该空间规定了其在平台内的互动方式。这些代理通过Config(人物)生成模块配置了独特的角色,并配备了Memory/Reflection模块,使其能够回忆和根据过去的经验进行调整。动作空间概述了代理可展示的全部行为范围:他们可以分享帖子、评论或喜欢评论、创建或喜欢帖子,并标记不当内容。此外,代理可以检索他们的推送、关注或取消关注其他用户,或完全忽略内容或互动。这些离散动作模拟了真实的用户行为和社会动态,使环境中的互动丰富且自发。
E. 1 代理决策过程
代理的决策过程由推送呈现、记忆召回和推理机制之间的结构化互动控制。
推送呈现 每个代理的推送聚合了来自关注用户的帖子,并补充了额外的趋势内容和新闻文章。平均而言,十分之一的帖子来自NewsGuard数据集并包含虚假信息。帖子显示时带有元数据,如参与度计数(点赞、评论、分享)和事实核查信号(标记、社区注释、第三方裁决)。这些元数据为代理的参与决策提供了上下文。
记忆和反思模块 我们实现了一个AgentMemory模块,用于管理每个代理的记忆和反思能力。记忆分为互动(如过去的参与)和反思(从过去行为得出的高层次洞察)。每段记忆被赋予一个重要性评分,除非通过进一步的互动加以强化,否则该评分会随着时间推移而衰减。衰减函数确保基于经验自然产生长期行为。请参阅附录G以了解更多关于记忆模块的细节。
定期地,代理根据最近的互动生成反思。这些反思有助于发现行为模式、关系动态和潜在偏见,影响未来的参与内容和决策。
代理决策和行动执行
代理基于人物驱动的启发式规则、记忆检索和推理提示做出决策。AgentPrompts模块制定结构化的决策提示,引导代理通过诸如点赞、分享或标记帖子等选项进行内容参与。当参与时,代理为其行动提供理由,受到以下因素的影响:(1)个人信念和人物特征:代理根据其意识形态立场和历史偏好权衡内容可信度,(2)参与信号:高度参与的帖子由于社会验证效应更有可能被重新分享,(3)事实核查反馈:代理将事实核查信号纳入其推理,相应调整对被标记内容的信任度。
一旦做出决策,代理的行动会被记录在关系数据库中,同时更新帖子指标、参与度和新记忆。每次互动的重要性根据情感强度、行动强度和与代理目标的一致性进行评估。
F 详细实验配置
我们在本节中更详细地描述了我们的实验设置和可配置变量。在我们的模拟中,我们模拟了一个动态社交网络,其中任意数量的(实际上在我们的实验中多达200多个)由LLM驱动的代理在多个离散时间步骤内互动。模拟循环遵循一个结构化的核心周期,包括初始化环境、概率分配新用户(尽管在某些运行中可以禁用此功能)、内容创建、基于推送的反应和定期的反思更新。每个代理都从通过外部JSONL文件提供的详细人物描述实例化,并使用解码温度为1.0的GPT40引擎操作,以促进生成响应的多样性。代理可以根据设置独立创建原创帖子,也可以仅根据提示对帖子作出反应。一旦模拟环境启动,代理的推送由最多默认15篇来自关注用户和10篇来自非关注用户的帖子组成,这些帖子来自每轮运行中最多20篇注入的新闻项目。初始社交联系稀疏,初始时跟随其他用户的概率为10%,并且在模拟过程中禁用新用户添加和跟随行为。上述所有数字均可配置。该实验评估了第3节中描述的四种事实核查干预模式之一,结合了第三方和社区为基础的机制。对于每一步,如果启用了事实核查代理,则选择一定数量的帖子进行潜在审核,事实核查输出使用低温(0.3)设置生成,并要求包含推理。如果设置了审核,则指定标记和记笔记行为的阈值。定期地,代理反思其最近的互动,更新记忆状态并检查其内部目标,提供了一个研究人工社会中出现行为、信息扩散和干预效果的框架。
G 内存模块详细信息
内存相关性计算如下:
相关性 = 重要性 × 衰退 \text { 相关性 }=\text { 重要性 } \times \text { 衰退 } 相关性 = 重要性 × 衰退
衰退因子定义为:
衰退 = max ( 0 , PrevDecay − α Δ t ) \text { 衰退 }=\max (0, \text { PrevDecay }-\alpha \Delta t) 衰退 =max(0, PrevDecay −αΔt)
其中 α \alpha α是衰退率(默认0.1), Δ t \Delta t Δt是从上次访问以来的时间(以天为单位)。新记忆开始时PrevDecay = 1.0 =1.0 =1.0。
如果相关性 ≥ \geq ≥ 0.3,则认为该记忆相关。重要性和衰退均在 [ 0 , 1 ] [0,1] [0,1]范围内。
重要性评分。每段记忆的基础重要性评分为0.5 。如果匹配以下语义类别中的关键词,则重要性评分增加0.1(最多达到1.0):
- 情感:爱、恨、愤怒、快乐、悲伤
- 行动:实现、失败、学习、发现
- 关系:朋友、关注、连接、分享
- 目标:目标、靶向、目的、意图
设 k k k为记忆内容中关键词匹配的数量。那么:
重要性 = min ( 1.0 , 0.5 + 0.1 k ) \text { 重要性 }=\min (1.0,0.5+0.1 k) 重要性 =min(1.0,0.5+0.1k)
该值与衰退因子结合计算最终相关性。
H 对内容受欢迎程度的扩展讨论
H. 1 用户受欢迎程度的幂律分布
首先,我们将用户的受欢迎程度定义为关注者数量、点赞数量、分享数量和评论数量的总和。我们收集了最受欢迎的前50名用户,并按他们收到的参与度(从高到低)绘制了图表,如图5所示。我们观察到用户影响力的幂律分布。我们有 f ( x ) = 120 x − 0.6 f(x)=120 x^{-0.6} f(x)=120x−0.6作为我们采样数据的最佳拟合幂律近似值,如图6所示。我们的回归线 α = 0.60 \alpha=0.60 α=0.60的 R 2 = 0.84 R^{2}=0.84 R2=0.84,表明我们的用户参与度数据与典型幂律分布的高度吻合,即少数用户产生了大部分的参与度。现有的关于真实社交网络的分析表明,这种幂律指数通常根据具体情境在1.5-2.5之间变化(Muchnik等人,2013;Bild等人,2015)。我们的最佳拟合指数低于这些报告的数字,但它仍然说明了一个明显的趋势,即少数用户/内容吸引了大部分的关注,而大多数则远不及如此。
在本节的其余部分,我们探讨了这种分布出现的潜在原因,并通过一系列分析我们的模拟环境,揭示了在线社交网络中影响力或受欢迎程度的不可预测性。更根本地说,我们认为或许LLM驱动的代理倾向于简单复制在他们之前行动的代理的决定。这导致了优先依附现象,并因此建立了参与模式的幂律分布。这种模式不一定源于其他任何东西,如用户的个人资料细节或他们发布的内容。甚至他们自己的“内在推理”可能也无法揭示他们真正的决策过程,这邀请进一步调查LLM代理自我表达推理痕迹的真实性。
H. 2 人物属性与参与度无相关性
我们通过比较前50名参与度最高的用户(最高数量的关注者、点赞、分享、评论等)与后50名参与度最低的用户在几个属性上的差异来分析用户参与度。表3汇总的卡方检验结果显示,在这两组之间,年龄组、性别、活动类型、爱好、种族、收入水平、政治归属或主要目标的分布没有统计显著差异。虽然某些属性,如种族和爱好,表现出中等效应量(Cramér’s V分别为0.319和0.302),但它们相关的p值并未达到常规统计显著性水平。这表明所检查的属性并不显著影响用户的参与水平。
值得注意的是,我们并未包括类似现实世界公众人物或名人的角色,他们的存在可能会大幅影响内容的受欢迎程度。我们的研究结果因此表明,当角色随机初始化时,一些用户自然会吸引显著更多的关注和参与,这与初始化期间分配的具体属性无关。这突显了社交平台中用户参与度的固有变异性与不可预测性。
H. 3 内容主题是否重要?
我们的分析旨在直接调查内容主题与用户参与度之间的相关性。为此,我们首先通过汇总每个帖子的点赞、分享和评论来计算参与度得分。然后清理和预处理帖子的文本内容,以确保准确的主题建模。
对于主题提取,我们使用基于BERTopic(Grootendorst,2022)的统一主题模型,利用SentenceTransformer模型all-MiniLM-L6-v2(Reimers和Gurevych,2019)的句子嵌入。选择BERTopic是因为它在捕捉短文本内容中的细微语义关系方面非常有效。通过将单一主题模型拟合到所有帖子上,我们确保了识别主题的一致性和可比性。
在主题分配之后,我们进行了详细的统计分析。包括点赞、分享、评论和整体参与度得分的平均值、中位数和标准差在内的参与度指标为每个主题进行了计算。为了统计评估不同主题间的参与度变化是否显著,我们进行了方差分析(ANOVA)。
关键的统计发现是ANOVA结果得出F统计量为0.614,p值为0.84。这表明主题与整体参与度水平之间没有统计显著的关系。换句话说,从统计角度看,帖子的主题本身并不能可靠地预测其参与度水平。
H. 4 从代理自身的推理痕迹和推荐系统中获得线索
用户画像、内容主题或时间属性与参与模式之间缺乏明确的相关性表明,我们向代理展示推送的方式可能会影响哪些内容最终变得流行。在这里,我们讨论我们的推送优先级算法。我们的模拟没有采用复杂的推荐系统。我们的推送优先级在模拟中主要依赖于时效性和现有的关注关系,而非明确的参与度指标,如点赞或分享。无论帖子来自关注还是非关注用户,一般都根据发布时间排序,确保较新的内容获得更高的可见性。然而,来自关注用户的帖子由于推送中有专门的分配获得了额外的优先曝光。这种结构可能创建了一个基于关注的反馈循环:当用户B关注用户A时,A的帖子会持续出现在B的推送中,增加了A通过点赞、评论和分享获得参与的机会。更高的参与度随后提高了A对其他查看这些互动的用户的可见性,增加了进一步关注的可能性,从而进一步放大了这个循环。
代理的推理模式 我们跨多个维度提取和分析代理推理,包括情绪、动机、实体和概念提取以及词频分析。分析特别关注识别与不同参与动作(如点赞、评论和分享)相关的模式,探索帖子内容和用户背景如何影响推理,
并检查常见的语言趋势。
代理推理的分析揭示了代理在社交媒体上与内容和用户互动时的情绪模式。如图4所示,代理在不同类型动作上表现出清晰且独特的情感情绪模式。主导正面情绪的动作如关注用户(99%正面情绪)、评论(97%)、点赞帖子(92%)和分享内容(92%)表明,代理主要将其互动视为建设性的贡献。相反,负面情绪主要体现在标记帖子(71%负面)和取消关注用户(40%负面)等动作上,反映了代理主要使用这些互动来表达不满或担忧。
进一步检查动机推理,代理根据其互动性质应用不同的框架。内容评估动作如标记帖子,主要是由信息质量评估(49%)和对虚假信息的担忧(22%)驱动的。分享决定主要反映了对内容的同意(46%)。相比之下,关系构建动作表现出不同的动机:点赞很大程度上是由社交连接潜力(34%)驱动的,评论平衡了同意(29%)和社交连接(28%),而关注用户则反映了多样化的个人兴趣(27%)。
词汇分析进一步强调了这些区别,揭示了每种参与类型的特定语言模式。标记内容使用特定的审核相关语言,如“虚假信息”、“有害”和“可信”,而社区导向的参与如分享、点赞和评论频繁引用“社区”、“支持”和“一致”等概念。关注动作则强调与内容策划和长期价值相关的术语,包括“持续地”、“有价值的”和“见解”。
有趣的是,尽管有这些详细的推理框架,帖子情绪与代理推理之间的低对齐度(21.4%)表明,代理的明确理由可能并未完全反映驱动参与的基本因素。相反,参与决策似乎主要由个人价值观对齐、信息质量评估、社区建设潜力和个人相关性而非简单的情绪共鸣来引导。
这些见解也突显了与先前分析的显著矛盾,先前分析显示用户人口统计或内容主题与整体参与受欢迎程度之间没有显著相关性。虽然代理清楚地以特定框架(价值观对齐、信息质量、社交连接)阐述其参与动机,但这些解释单独并不能稳健预测广泛的参与模式。这种悖论表明,参与高度个体化、情境化,并可能受到网络效应的影响——例如谁发布内容、现有的社会验证或内容在社交推送中的位置——这些因素无法完全通过人口统计或主题分类捕捉。
本质上,分析确认代理根据参与类型采用定制的推理结构,但揭示实际参与结果受细致的个体解释和情境社会动态影响。LLM内部决策与明确表面行为之间的这种错位也与先前工作(Liu等人,2023)观察到的结果一致。认识到这些复杂性对于理解和预测社交媒体参与的不可预测性至关重要。
I 提示
I. 1 帖子创建提示
"""
给定:
- persona: str,
- memories_text: str,
- recent_posts_text: str,
- feed_text: str
"""
为具有以下特征的用户创建一条社交媒体推文:
背景:{persona}
你最近的记忆和经历:
(memories_text if memories_text else "无
相关记忆。")
你最近发布的帖子:
(recent_posts_text if recent_posts_text else "无
最近帖子。")
你推送中其他用户的近期帖子:
(feed_text if feed_text else "推送中无
最近帖子。")
推文应真实反映用户的性格和背景,并可参考你的过往经历。保持简洁,适合社交媒体平台。
重要事项:
- 避免重复你最近帖子中的相似主题或内容
- 尝试带来新鲜视角或讨论兴趣的不同方面
- 在相关时,自由参与或引用推送中的一个或多个近期帖子
- 如果推送中有突发新闻,并且与你的兴趣相关,考虑参与其中,无论你是否同意或反对
每次写东西时不必每次都使用表情符号。
考虑你最近发布的帖子。尝试多样化你的内容和风格。例如,避免总是以相同的短语开头,如"just…"
即将创建的帖子是:
I. 2 推送反应提示
def create_feed_reaction_prompt(
persona: str,
memories_text: str,
feed_content: str,
reflections_text: str = "",
experiment_type: str = "
third_party_fact_checking",
include_reasoning: bool = False
) -> str:
# 所有实验类型通用的基础提示
base_prompt = f"""你正在浏览你的
社交媒体推送,作为具有以下
背景的用户:
{persona}
近期记忆和互动:
(memories_text if memories_text else "无
相关记忆。")
你的推送:
(feed_content if feed_content else "推送中无近期
帖子。")
你的过往反思:
(reflections_text if reflections_text else "N/A")
基于你的人物、记忆和所见内容,选择如何与推送互动。
" " "
if not experiment_type:
raise ValueError("实验类型是
必填项")
# 添加实验特定指令
和有效动作
if experiment_type == "no_fact_checking":
base_prompt += "" "
表4:内容参与分析的代理推理
| 动作类型 | 总动作数 (%) | 积极 (%) | 中立 (%) | 消极 (%) | 前两名推理类别 |
|---|---|---|---|---|---|
| share_post | 1382 (30.1%) | 91.8 | 6.6 | 1.6 | 同意 (46.3%) 社交联系 (15.7%) 信息价值 (48.8%) 虚假信息 (22.4%) |
| flag_post | 1126 (24.6%) | 13.5 | 15.5 | 71.0 | 同意 (29.2%) 社交联系 (27.6%) 个人兴趣 (27.4%) 信息价值 (24.4%) |
| comment | 880 (19.2%) | 96.8 | 2.7 | 0.5 | 社交联系 (33.6%) 同意 (23.6%) |
| follow_user | 719 (15.7%) | 98.9 | 0.8 | 0.3 | 信息价值 (36.4%) 个人兴趣/同意 (18.2%) |
| like_post | 463 (10.1%) | 92.0 | 7.8 | 0.2 | 同意 (50.0%) 情感反应 (16.7%) |
| ignore | 9 (0.2%) | 77.8 | - | 22.2 | |
| unfollow_user | 5 (0.1%) | 20.0 | 40.0 | 40.0 |
有效动作:
- like-post // [post_id]
- share-post // [post_id]
- comment-post // [post_id] with [content],
限制为250个字符
- ignore
根据你的兴趣和信念与帖子和用户互动。
如果信息看起来令人惊讶或新颖,
自由地与之互动并分享给你的网络。
"""
elif experiment_type == "
third_party_fact_checking":
base_prompt += """
有效动作:
- like-post // [post_id]
- share-post // [post_id]
- comment-post // [post_id] with [content], 限制为250个字符
- ignore
elif experiment_type == "
community_fact_checking":
base_prompt += “”"
你可以向需要额外上下文或事实核查的帖子添加社区注释。
你还可以根据其准确性和有用性对现有社区注释进行评分为有帮助或无帮助。
有效动作:
- like-post // [post_id]
- share-post // [post_id]
- comment-post // [post_id] with [content], 限制为250个字符
- add-note // [post_id] with [content] - 添加社区注释以提供上下文或事实核查
- rate-note // [note_id] as [helpful/not-helpful ] - 对现有社区注释进行评分
- ignore
如果你看到帖子上已有社区注释,首先考虑将其评为有帮助或无帮助,然后仅在你有额外上下文提供时才添加自己的注释。
" " elif experiment_type == " hybrid_fact_checking": base_prompt += “” "注意官方事实核查裁决和帖子上的社区注释。
你可以添加自己的社区注释并对现有注释进行评分,同时考虑官方事实核查。
有效动作:
- like-post // [post_id]
- share-post // [post_id]
- comment-post // [post_id] with [content], 限制为250个字符
- add-note [post_id] with [content] - 添加社区注释以提供上下文或事实核查
- rate-note [note_id] as [helpful/not-helpful] 对现有社区注释进行评分
- ignore
" " base_prompt += " " "THESE ARE THE ONLY VALID ACTIONS YOU CAN CHOOSE FROM.
" " # 如果启用,则添加推理指令 if include_reasoning: base_prompt += “” "
对于你选择的每个动作,简要说明你的决定原因。
" " base_prompt += “” " 以包含动作列表的JSON对象形式作出响应。对于每个动作,包括: - action: 来自有效动作列表的动作类型
- target: 帖子/用户/评论/注释的ID(忽略操作不需要)
- content: comment-post和add-note动作所需
" " # 如果启用,则添加推理字段
if include_reasoning:
base_prompt += """
- reasoning: 简要解释你采取此行动的原因
" " "
# 为相关实验类型添加note_rating字段
if experiment_type in ["
community_fact_checking", "
hybrid_fact_checking"]:
base_prompt += """
- note_rating: rate-note动作所需("
helpful" 或 "not-helpful")
" " "
# 示例响应
if include_reasoning:
base_prompt += """
示例响应:
{
"actions": [
{
"action": "like-post",
"target": "post-123",
"reasoning": "该帖子包含有价值的信息"
},
{
"action": "share-post",
"target": "post-123",
"reasoning": "我想传播这条重要的新闻"
}
]
}" " "
else:
base_prompt += """
示例响应:
{
"actions": [
{
"action": "like-post",
"target": "post-123"
},
{
"action": "share-post",
"target": "post-123"
}
]
}" " "
return base_prompt
I. 3 反思提示
基于你作为社交媒体用户的近期经历:
背景:(persona)
近期记忆和经历:
(memory_text)
反思这些经历并生成关于以下方面的见解:
- 你的互动模式
- 你的人际关系变化
- 你的兴趣演变
- 你已发展的潜在偏见或偏好
- 你可能想要追求的目标或目的
提供一个深思熟虑的反思,可以指导你未来的行为。不要使用项目符号,只需总结成一段简短而简洁的段落。
I. 4 事实核查提示
" " "
给定:
- post_content: str,
- community_notes: str,
- engagement_metrics: dict
" " "
请核查以下社交媒体
帖子:
内容:(post_content)
参与指标:
- 点赞:(engagement_metrics['likes'])
- 分享:(engagement_metrics['shares'])
- 评论:(engagement_metrics['comments'])
{community_notes}
请分析此内容并提供:
- 裁决(true/false/unverified)- 如果不确定,请标记为unverified
- 详细解释你的发现
- 你的置信水平(0.0 到 1.0)
- 咨询的来源列表
如果帖子提到的时间在未来或内容超出你的知识范围,请将其标记为unverified。
对于明显的虚假信息,请将其标记为false。
以包含这些组件的结构化裁决格式你的响应。
参考论文:https://arxiv.org/pdf/2504.07830


















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











