






马尔科·托特
1
,
2
+
1
{ }^{1,2+1}
1,2+1 郭田宇
1
,
3
+
1
{ }^{1,3+1} \quad
1,3+1 阿卜杜勒哈克·莱姆赫恩特
1
{ }^{1}
1
大卫·比格内尔
1
{ }^{1} \quad
1 帕拉维·乔杜里
1
{ }^{1} \quad
1 克里斯·洛弗特
1
{ }^{1}
1
路易斯·弗朗萨
1
{ }^{1} \quad
1 马特乌斯·R·F·门东萨
1
{ }^{1} \quad
1 塔伦·古普塔
1
{ }^{1} \quad
1 达伦·格灵
1
{ }^{1}
1
山姆·德夫林
1
{ }^{1} \quad
1 塞尔吉奥·瓦尔卡尔塞尔·马库阿
1
{ }^{1} \quad
1 拉卢卡·史蒂文森
1
{ }^{1}
1
1
{ }^{1}
1 微软研究院
2
\quad{ }^{2}
2 伦敦玛丽女王大学
3
\quad{ }^{3}
3 牛津大学
摘要
模仿学习是一种强大的工具,可以通过利用专家知识来训练智能体,并能够复制给定的轨迹是其中的重要组成部分。在复杂的环境中,例如现代3D视频游戏,分布偏移和随机性需要超越简单动作回放的鲁棒方法。在这项研究中,我们在现代3D视频游戏《Bleeding Edge》中应用了不同的编码器和策略头的逆动力学模型(IDM),以进行轨迹跟随。此外,我们研究了几种未来对齐策略,以解决由随机不确定性及智能体不完美导致的分布偏移问题。我们测量了参考轨迹与智能体轨迹之间的轨迹偏差距离以及首次显著偏差点,并表明最佳配置取决于所选设置。我们的结果表明,在多样数据设置下,从零开始训练编码器的GPT风格策略头表现最佳;在低数据情况下,结合GPT风格策略头的DINOv2编码器给出了最佳结果;而在预训练于多样设置并针对特定行为设置微调时,GPT风格和MLP风格的策略头表现相当。
*等量贡献
${ }^{\dagger}$ 此工作完成于微软研究院期间
1 引言
使用视频游戏作为游戏智能体的测试平台已被广泛研究。尽管模仿学习和强化学习已经被应用,但大多数这些算法(Vinyals等人,2019a;Berner等人,2019;Wurman等人,2022)关注的是超人类行为,而不是匹配人类游戏风格。关于类似人类的游戏方式的研究主要利用模仿学习,其中最流行的技术围绕从演示中学习(Abbeel & Ng,2004;Ho & Ermon,2016)和从观察中学习(Torabi等人,2018a;Yang等人,2019)展开。
在这项工作中,我们通过从演示中学习来在复杂3D视频游戏中复制记录的轨迹。在简单的环境中,轨迹复制通常可以通过直接重播记录的动作来实现。然而,在随机环境中,幼稚的动作回放会失败,因为状态转换中的小变化可能导致与预期轨迹的重大偏差。
为了解决这一挑战,我们调整了一个预训练的世界模型来构建逆动力学模型(IDM)(Lamb等人,2023)。我们评估了世界模型嵌入的有效性,并将其与其他编码器进行了比较,同时探索了未来对齐策略以改善在视频游戏《Bleeding Edge》中记录轨迹的复制。我们的评估涉及两种类型的策略头——自回归变压器(Radford等人,2019)和前馈网络——与三种编码器类型配对:预训练的游戏特定世界模型、通用预训练编码器和从零开始训练的ConvNeXt。这导致了六种不同的模型配置。
我们在三种实验设置下评估了这六个模型变体:1) 通用 - 在大量通用游戏轨迹上进行训练,并在保留的轨迹上进行评估,2) 特定 - 在一组相似轨迹的小数据集上进行训练,表现出相同的行为,并在同一类上进行评估,3) 微调 - 我们首先使用1) 进行预训练,然后使用2) 进行微调和评估。
总结来说,我们的贡献如下:
- 调整预训练的世界模型以用于下游任务中的轨迹跟随模仿学习。
-
- 在复杂3D视频游戏中对通用、特定和微调设置下的不同模型配置进行实证分析。
-
- 研究设计选择的影响,如使用单个观察值与序列观察值作为模型输入,以及包括动作输入。
-
- 探索不同的未来条件策略,以减轻分布偏移并改善长期轨迹对齐。
2 相关工作
世界模型 世界模型(Ha & Schmidhuber, 2018)在模拟环境方面显示出强大的能力。它们已成功应用于诸如Doom (Valevski et al., 2024),Atari (Micheli et al., 2023) 和 Counter Strike (Alonso et al., 2024) 等游戏中,使用户无需依赖底层游戏引擎即可与游戏互动。最近的研究表明,世界模型遵循与大型语言模型类似的缩放定律(Pearce et al., 2024),展现出对未见过任务的零样本泛化能力( Xu et al., 2022),并且可以扩展到多游戏环境(Bruce et al., 2024)。
模仿学习 模仿学习使智能体能够通过观察专家演示而非依赖奖励信号或直接探索(如强化学习中那样)来学习任务。目标是通过学习将状态映射到动作的策略来复制观察到的行为。最广泛使用的方法之一是行为克隆(BC)(Torabi et al., 2018b),它在离线数据集上训练模型以模仿人类行为。BC 已应用于诸如自动驾驶(Pomerleau, 1991)、机器人(Florence et al., 2022)以及视频游戏中的游戏智能体(Kanervisto et al., 2020; Vinyals et al., 2019b)。虽然许多游戏中的模仿学习研究集中在优化高绩效政策上(Vinyals et al., 2019b; Ross et al., 2010; Ho & Ermon, 2016; Pearce & Zhu, 2022),一些工作也探索了捕捉多样化的游戏行为和风格。Ferguson et al. (2022) 研究了使用动态时间规整(Dynamic Time Warping)(Mü, 2007) 来模仿给定的游戏风格,而 Pearce et al. (2023) 使用扩散模型来捕捉多模态行为模式。这些研究表明了模仿学习生成超越最优策略的人类样游戏的可能性。
逆动力学模型 逆动力学模型(IDM)通常用于通过预测从一个状态过渡到另一个状态所需的动作来调节智能体。Paster et al. (2021) 将 IDM 应用于视觉领域,以预测一系列动作。Yang et al. (2019) 使用 IDM 作为一种工具,以最小化专家和智能体在训练过程中的分歧。Pavse et al. (2019) 结合 IDM 和强化学习以匹配专家的轨迹。他们使用逆动力学模型推断出应采取的动作,以从学习者的轨迹穿越到专家的轨迹在机器人控制领域。虽然我们的方法与 Pavse et al. (2019) 有相似之处,但也有一些关键区别。我们的方法专注于直接匹配参考轨迹,而他们的目标是在基于专家行为调节时生成高分轨迹。此外,我们在离线数据集上训练我们的 IDM,避免了 RL 反馈循环的时间成本。
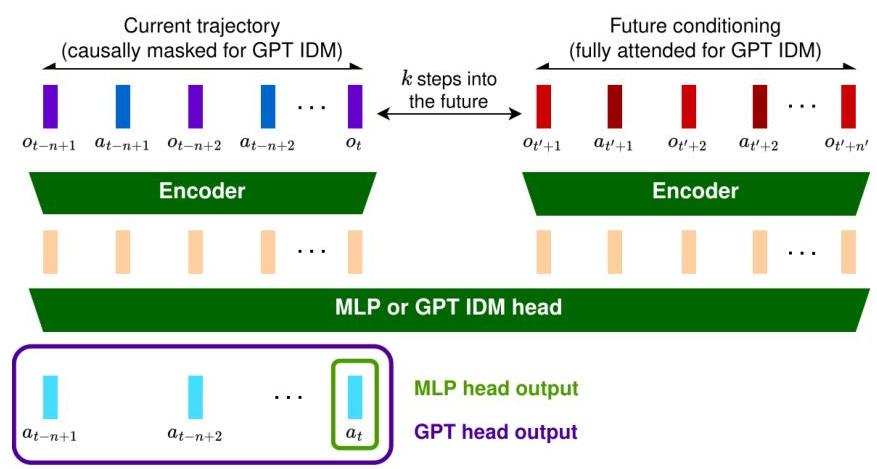
图1:IDM模型的高层概述。我们对两条不同的轨迹进行编码,当前智能体的轨迹和未来的条件。所得的编码随后被传递到 IDM 头部以选择应该执行的动作。
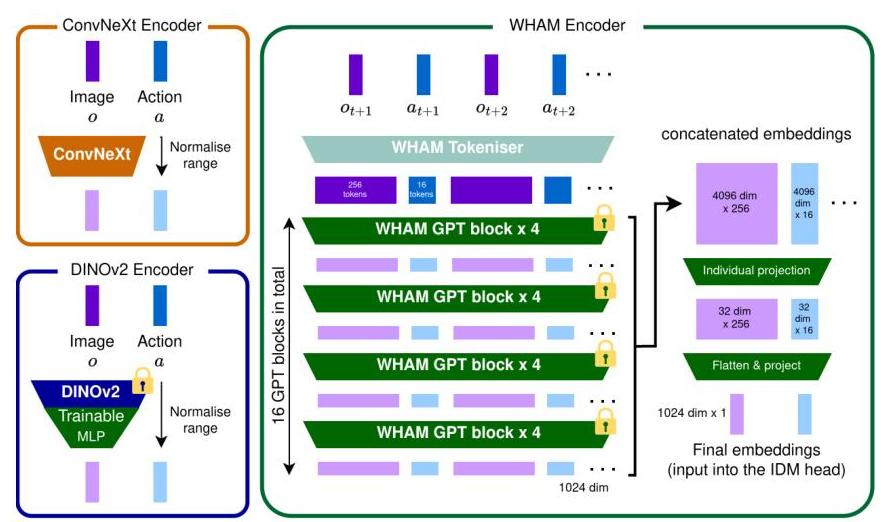
图2:我们评估了三种不同的编码器。从零开始训练的 ConvNeXt 编码器,预训练的通用编码器 DINOv2,以及预训练的游戏特定世界和人类动作模型。
3 方法
传统的 IDM 对当前观察和下一个观察进行编码以预测已采取的动作。IDM- K K K 通过将未来条件向前移动 K K K 步来概括这种方法。我们不是依赖单一的观察对,而是通过扩展 IDM- K K K 的概念,基于过去的和未来的轨迹序列——包括观察和动作——来进行条件设定,从而提高时间一致性和长期依赖性。这在部分可观测环境中尤为重要,例如视频游戏中,单帧条件可能不足以进行准确的决策制定。
3.1 模型
如图1所示,我们的广义 IDM-
K
K
K 模型处理从时间步
t
t
t 开始的过去轨迹序列,以及从时间步
t
′
+
k
t^{\prime}+k
t′+k 向后的未来轨迹序列。给定这些输入,模型预测在
t
t
t 时刻采取的动作。观察和动作序列可以独立或联合地进行编码,提供了表示过去和未来上下文的灵活性。编码表示随后通过策略头以预测动作。
视觉编码器 我们评估了三种不同的编码器(见图2):
- ConvNeXt (Liu et al., 2022): 从零开始训练的卷积网络,结合标准化的动作向量。
-
- DINOv2 (Oquab et al., 2024): 预训练的通用图像编码器,带有可微调的 MLP 头,结合标准化的动作向量。
-
- 世界和人类动作模型 (WHAM) (Kanervisto et al., 2025): 预训练的游戏专用编码器,优化用于自动回归的下一个标记预测,处理交错的图像和动作标记序列作为上下文。
由于其标记化表示,WHAM 编码器提出了一个独特的挑战。在其原始形式中,单个观察及其对应动作分别由 256 和 16 个标记表示。这导致实际轨迹长度的序列长度为 272。初步实验表明,每 272 步训练 IDM- K K K 以预测动作向量无法为模型提供足够的密集损失。为了解决这个问题,我们将顺序嵌入投影到紧凑表示——一个用于观察输入,另一个用于动作输入,然后再通过二级投影层获得最终嵌入。
- 世界和人类动作模型 (WHAM) (Kanervisto et al., 2025): 预训练的游戏专用编码器,优化用于自动回归的下一个标记预测,处理交错的图像和动作标记序列作为上下文。
解码器 由于模型处理顺序数据,我们采用基于变压器的解码器进行动作预测。具体而言,我们使用 GPT 模型 (Radford et al., 2019) 作为 IDM 头部,以预测到达未来轨迹所需的动作。通过 GPT 头部,可以在过去信息切断的不同时间步预测多个动作。这些附加的顺序动作输出损失有助于增强 IDM 策略对不同长度的过去轨迹输入的鲁棒性。我们将 GPT 头部与多层感知机 (MLP) IDM 头部进行比较。MLP 头部展平并连接输入编码,提供了一种更简单的替代方案。
我们将解码器(MLP、GPT)与编码器(ConvNeXt、DINOv2 和 WHAM)结合,产生了六个 IDM- K K K 变体进行评估。
3.2 未来选择策略
选择适当的未来条件策略对于 IDM- K K K 至关重要,主要是由于两个主要挑战:(1) 智能体的不完善,(2) 环境的随机性。
- 智能体不完善:模型的动作预测并不总是准确的,这会导致偏离参考轨迹。随着这些错误的积累,智能体可能会远离预期路径。当前位置与未来条件之间的距离可能变得过大,使智能体超出训练分布。
-
- 环境随机性:某些游戏元素,如随机生成的防火墙、移动平台和健康包,可能会不可预测地改变环境,进一步导致分布偏移。
为了缓解这些问题,我们探索了四种未来条件策略:
静态未来条件 在这种方法中,未来开始时间步 t future ′ t_{\text {future }}^{\prime} tfuture ′ 仅由当前时间步 t current t_{\text {current }} tcurrent 决定,与智能体的位置无关。给定要跳过的帧数 K K K,未来开始时间步计算为:
- 环境随机性:某些游戏元素,如随机生成的防火墙、移动平台和健康包,可能会不可预测地改变环境,进一步导致分布偏移。
t future ′ = t current + K t_{\text {future }}^{\prime}=t_{\text {current }}+K tfuture ′=tcurrent +K
此方法不考虑空间偏差,当智能体偏离预期轨迹时容易导致分布漂移。
最近未来条件 此方法根据智能体当前位置选择参考轨迹中最接近的点,以最小化空间偏差。未来开始时间步给出为:
t
future
′
=
arg
min
t
′
∥
τ
(
t
′
)
−
x
^
t
∥
+
K
t_{\text {future }}^{\prime}=\underset{t^{\prime}}{\arg \min }\left\|\tau\left(t^{\prime}\right)-\hat{\boldsymbol{x}}_{t}\right\|+K
tfuture ′=t′argmin∥τ(t′)−x^t∥+K
其中
τ
(
t
)
\tau(t)
τ(t) 表示参考轨迹在时间步
t
t
t 的
(
x
,
y
,
z
)
(x, y, z)
(x,y,z) 位置,
x
~
t
\tilde{\boldsymbol{x}}_{t}
x~t 表示智能体当前的
(
x
,
y
,
z
)
(x, y, z)
(x,y,z) 位置,
K
K
K 表示跳过的帧数。
虽然这种策略保持了空间对齐,但在涉及循环或长时间静止阶段的情况下,智能体可能会陷入无限循环。
半径未来条件 此方法根据与参考轨迹的接近程度动态更新未来条件时间步。如果智能体位于预定义半径 r r r 内,则未来开始时间步前进一步,否则保持不变。
t future ′ = { t future ′ + 1 , if ∥ τ ( t future ′ ) − x ~ t ∥ ≤ r t future ′ , otherwise t_{\text {future }}^{\prime}= \begin{cases}t_{\text {future }}^{\prime}+1, & \text { if }\left\|\tau\left(t_{\text {future }}^{\prime}\right)-\tilde{\boldsymbol{x}}_{t}\right\| \leq r \\ t_{\text {future }}^{\prime}, & \text { otherwise }\end{cases} tfuture ′={tfuture ′+1,tfuture ′, if ∥τ(tfuture ′)−x~t∥≤r otherwise
其中 τ ( t ) \tau(t) τ(t) 表示参考轨迹在时间步 t t t 的 ( x , y , z ) (x, y, z) (x,y,z) 位置, x ~ t \tilde{\boldsymbol{x}}_{t} x~t 表示智能体当前的 ( x , y , z ) (x, y, z) (x,y,z) 位置, r r r 表示半径。
内外未来条件 此方法引入了两个阈值:内半径 r in r_{\text {in }} rin 和外半径 r out r_{\text {out }} rout 。未来时间步根据智能体位置与当前未来条件帧位置之间的距离进行更新。
- 小于 r in r_{\text {in }} rin - 未来时间步前进直到离开内半径。
-
- 介于 r in r_{\text {in }} rin 和 r out r_{\text {out }} rout 之间 - 未来前进 1 步,与半径策略相同。
-
- 大于
r
out
r_{\text {out }}
rout - 未来时间步保持不变。
完整的条件策略描述请参见附录 A.3。
- 大于
r
out
r_{\text {out }}
rout - 未来时间步保持不变。
4 实验
以下章节描述了实验中使用的环境,概述了训练和评估设置,并提供了不同模型的经验结果分析。
4.1 环境
我们在《Bleeding Edge》中评估了我们的方法,这是一个包含各种具有独特能力的可玩角色的第三人称多人游戏。由于其动态游戏玩法和随机元素,该环境为轨迹跟随智能体提供了一个具有挑战性的测试平台。
我们的实验集中于两张地图:SkyGarden 和教程地图 Dojo(图3)。智能体的观测数据既包括代表智能体摄像机视野的视觉信号,也包括包括遥测数据在内的符号模态。动作空间由 Xbox 控制器的输入表示,具有 12 个离散按钮和 2 个连续摇杆,用于移动和摄像机旋转,每个摇杆包括 x 和 y 轴。

(a) Sky Garden

(b) Dojo
图3:用于训练和评估的 Sky Garden 和 Dojo 地图示例图像。
1
{ }^{1}
1 官方游戏网站: https://www.bleedingedge.com/en
数据集包含来自 Sky Garden 地图的 71,940 条记录的人类游戏轨迹,这些轨迹来自 2020 年 9 月 2 日至 2022 年 10 月 19 日间记录的 8788 场比赛(Jelley et al., 2024)。该数据集代表大约 1.12 年的人类游戏时间,并包含视觉和遥测数据,以及玩家在游戏中采取的动作。
4.2 设置
为了统一数据集中的动作空间模态,我们将连续维度(摇杆输入)的连续动作空间归一化到 [ − 1 , 1 ] [-1,1] [−1,1] 范围,然后将其离散化为 11 个区间。所有提出的模型都训练了 200 个周期,每个周期包含 1000 次更新,批量大小为 64。完整的训练超参数列表见附录 A.2.1。
评估 我们在 8 条保留轨迹上评估模型性能,涵盖了多种任务:
- Jumppad(3 条轨迹):智能体必须在十字路口选择正确的路径。
-
- Benchmark(3 条轨迹):涉及不同地图区域的复杂转弯。
-
- Dojo(2 条轨迹):在教程环境中导航。
这些测试轨迹在复杂性和领域上各不相同。有些来源于 Sky Garden(主要测试环境),其他则来自 Dojo,引入了额外的领域偏移。轨迹可见于 https://adaptingworldmodels.github.io/。
- Dojo(2 条轨迹):在教程环境中导航。
每个智能体在每条轨迹上评估 10 个 rollout 种子。我们通过两项指标评估性能:
- AUC(曲线下面积):通过动态时间规整(DTW)(Mü, 2007)在不同半径下测量轨迹相似度。
-
- 未来指数比率(FI):捕获在首次显著偏离参考路径之前跟随的轨迹比例。
AUC 指标的详细公式见附录 A.4。除非另有说明,所有报告的结果反映了每条轨迹每种模型 10 次 rollout 的中位分数。
- 未来指数比率(FI):捕获在首次显著偏离参考路径之前跟随的轨迹比例。
4.3 结果
本节包含模型的实证评估,并提供了有关编码器和 IDM 头部设计选择的见解。我们将本节分为两部分:(1) 通用设置下的评估,以及 (2) 特定和微调设置下的评估。
4.3.1 通用设置
表1总结了在大型多样化数据集上训练并在未见过的轨迹上零样本评估的不同架构的性能。在所有评估的架构中,无论与 MLP 或 GPT IDM 头部配对,ConvNeXt 都优于其他编码器。FI 性能数据见附录 A.2。虽然 AUC 提供了模型间的定量比较,但它无法捕捉轨迹跟随是否成功。 2 { }^{2} 2
为了更直观地理解模型性能,图4可视化了基准1轨迹,将智能体的路径叠加到参考轨迹上。图4揭示了模型间的明显性能差异。ConvNeXt 一贯跟随预期轨迹,仅在一个 rollout 中出现偏差。DINOv2 偶尔有成功的运行,从轻微的偏差中恢复,而 WHAM 无法跟随轨迹,显示大部分为任意运动。这些定性观察与表1中呈现的定量 AUC 结果一致。
我们的结果表明,专门训练编码器以进行轨迹跟随是有利的。即使相对简单的 ConvNeXt 架构也能产生比大规模预训练模型(如 DINOv2 和 WHAM)更有效的嵌入,这些模型并未明确为此任务训练。
ConvNeXt、DINOv2 和 WHAM 之间的性能差异可能源于它们的嵌入策略差异。ConvNeXt 和 DINOv2 独立编码观察,而 WHAM 使用因果变压器联合编码两种模态。这种早期的观察和动作纠缠可能限制了模型在轨迹跟随任务上的有效泛化能力。
尽管 WHAM-GPT 在训练过程中损失较低,相较于 ConvNeXt 和 DINOv2,但这种优势并未转化为更好的评估性能,WHAM 相较于其他变体表现较差。这种差异很可能源自训练和评估条件的不同。在训练过程中,过去和未来的轨迹在空间和时间上完全对齐,因为它们源自同一记录轨迹。然而,在评估时,过去的轨迹由智能体动态生成,而未来的轨迹仍然固定在记录中。不同模型的训练曲线可在附录 A.2.2 中查看。
通用设置消融 为了理解拥有不同输入模态的好处,我们通过选择性删除观察或动作进行消融实验。表2展示了 ConvNeXt-GPT 模型在这些变化中的性能比较。
结果显示视觉输入对于准确的轨迹跟随至关重要,而包括动作输入只提供了边际收益。在简单场景(例如 Jumppad 轨迹)中,单独的动作输入就足够了。只有观察的模型几乎与完整模型的表现相当。评估表明,拥有视觉模态是关键,而添加动作模态只会带来整体上的轻微改进。每条轨迹的完整结果见附录 A.5。
表2:不同输入到模型的 AUC 和 FI —— 所有轨迹的平均结果
| 仅观察 | 仅动作 | 完整模型 | ||||
|---|---|---|---|---|---|---|
| AUC | FI | AUC | FI | AUC | FI | |
| 平均 | 0.84 | 0.70 | 0.69 | 0.47 | 0.86 \mathbf{0 . 8 6} 0.86 | 0.73 \mathbf{0 . 7 3} 0.73 |
我们还研究了序列长度对模型性能的影响。表3 报告了不同过去和未来序列长度的结果,并将 BC 智能体作为基线(其设计中缺乏未来条件)。每条轨迹的完整结果见附录 A.5。
结果显示 BC 智能体难以一致地完成任何轨迹;唯一表现良好的轨迹是 Jumppad mid,行为只是向前移动。其他模型表现相当,给予过去和未来全部 10 帧的观察-动作对稍微更好。每条轨迹的完整结果见附录 A.5。
表3:不同未来和过去长度的 AUC 和 FI —— 所有轨迹的平均结果
| BC | 1P-1F | 10P-1F | 1P-10F | 完整模型 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AUC | FI | AUC | FI | AUC | FI | AUC | FI | AUC | FI | |
| 平均 | 0.64 | 0.45 | 0.84 | 0.69 | 0.85 | 0.69 | 0.79 | 0.64 | 0.86 \mathbf{0 . 8 6} 0.86 | 0.73 \mathbf{0 . 7 3} 0.73 |
我们在表4中展示了未来选择策略的结果。需要注意的是,在此设置下我们没有测量 FI,因为半径值直接影响智能体与未来轨迹之间的允许空间距离,使得在此方面的公平评估不切实际。在四个选择策略中,Closest 稍微优于其他策略,实现了 AUC 0.877。虽然 Closest 是基准测试中表现最好的策略,但我们选择了 Radius 策略用于我们的模型,原因有两个。首先,智能体在跟随 Dojo 轨迹时表现挣扎,无论使用何种策略都显示任意运动。排除 Dojo 轨迹后,Radius 策略产生的平均 AUC 略高于 Closest。其次,Closest 策略在处理包含循环或长无操作序列的轨迹时存在理论问题——这些问题在评估集中不存在,但在其他场景中可能出现。
表4:不同的未来选择策略。结果展示了所有轨迹的中位 AUC 值。Radius 和 Inner-Outer 策略的半径 R R R 通过对每条轨迹进行参数扫描确定。
| 静态 | 最近 | 半径 | 内外 | |
|---|---|---|---|---|
| 平均 AUC | 0.84 | 0.88 \mathbf{0 . 8 8} 0.88 | 0.86 | 0.85 |
4.3.2 特定和微调
我们在30条展示几乎相同行为的轨迹(Dojo Ramp的变化)上训练了模型。表5展示了结果。评估程序与通用设置匹配,唯一的区别是没有评估 WHAM 编码器。原因是 WHAM 模型需要大 数据集的可用性,而这些实验假设此类数据集不可用。
在特定设置下,DINOv2-GPT 实现了整体最佳性能,紧随其后的是 DINOv2-MLP。两种模型都实现了完美的 FI 1.00,表明复制了轨迹。
此外,我们还想指出特定行为训练对评估该行为的整体影响。在通用设置下,当我们评估智能体
表5:在完整数据集上训练并在 Dojo Ramp 上零样本评估(通用训练)、仅在 Dojo Ramp 上训练(特定训练)以及先在完整数据集上训练再在 Dojo Ramp 上微调(微调)的模型的 AUC 和 FI 在 Dojo Ramp 上的结果。
| ConvNeXt-MLP | DINO-MLP | ConvNeXt-GPT | DINO-GPT | |||||
|---|---|---|---|---|---|---|---|---|
| AUC | FI | AUC | FI | AUC | FI | AUC | FI | |
| 通用训练 | 0.65 | 0.22 | 0.40 | 0.21 | 0.69 \mathbf{0 . 6 9} 0.69 | 0.29 \mathbf{0 . 2 9} 0.29 | 0.69 \mathbf{0 . 6 9} 0.69 | 0.24 |
| 特定训练 | 0.70 | 0.26 | 0.96 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.94 | 0.98 | 0.97 \mathbf{0 . 9 7} 0.97 | 1.00 \mathbf{1 . 0 0} 1.00 |
| 微调 | 0.96 \mathbf{0 . 9 6} 0.96 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.83 | 0.67 | 0.96 \mathbf{0 . 9 6} 0.96 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.93 | 0.92 |
在微调设置下,我们看到 ConvNeXt-MLP、ConvNeXt-GPT 和 DINOv2-GPT 都能够成功跟随轨迹,表明 ConvNeXt 架构由于从头训练,受益于通用设置下的大初始数据集,最终略微优于 DINOv2 模型。
我们还展示了输入序列长度的影响,以了解未来条件在此设置下的影响。表6中的结果显示,即使在没有任何条件的 DINOv2-GPT 模型版本(即 BC 版本)中,仍然表现最佳。这是由于训练和评估设置的性质决定的。在特定设置下,所展示的行为没有多样性,所有轨迹都遵循相同的路径。在这种情况下,知道过去就足以预测下一个动作。
表6:特定轨迹的不同过去和未来长度的 AUC 和 FI。
| ConvNeXt-MLP | DINO-MLP | ConvNeXt-GPT | DINO-GPT | |||||
|---|---|---|---|---|---|---|---|---|
| AUC | FI | AUC | FI | AUC | FI | AUC | FI | |
| 10P-0F (BC) | 0.70 | 0.26 | 0.96 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.97 \mathbf{0 . 9 7} 0.97 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.93 | 0.99 |
| 10P-1F | 0.71 | 0.26 | 0.74 | 0.85 | 0.96 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.98 \mathbf{0 . 9 8} 0.98 | 1.00 \mathbf{1 . 0 0} 1.00 |
| 10P-10F | 0.70 | 0.26 | 0.96 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.94 | 0.98 | 0.97 \mathbf{0 . 9 7} 0.97 | 1.00 \mathbf{1 . 0 0} 1.00 |
5 结论
我们在三种设置——通用、特定和微调——下评估了不同的 IDM 架构,发现不同的架构在不同场景中表现出色。ConvNeXt-GPT 在通用设置中表现最佳,DINOv2 变体在特定设置中表现最佳,ConvNeXt 变体在微调设置中表现最佳。此外,我们进行了广泛的消融实验,以识别模仿学习中逆动力学模型的关键设计选择。此外,我们探索了各种未来选择策略,以减轻轨迹跟随任务中的分布偏移,这是一个关键挑战。
尽管在模型架构和设计选择方面取得了进展,轨迹跟随仍然是一个重大挑战。在通用设置中,没有一个智能体能够成功跟随最复杂的轨迹,突显了跨不同行为的泛化持续存在的差距。
局限性和未来工作 我们计划进一步调查模型对外部扰动(如人为干预)的鲁棒性,通过手动旋转相机和输入特定动作,以更好地理解从分布外情况中的恢复能力。
尽管我们的模型是在所有 13 个《Bleeding Edge》角色和动作上训练的,但我们的评估主要集中在一个角色的运动轨迹上。扩展测试以包括诸如战斗交互和特定角色动作之类的行为,可以提供对模型能力和局限性的更深入洞察。
致谢
作者感谢 Katja Hofmann、Tabish Rashid、Tim Pearce、Yuhan Cao、Chentian Jiang、Shanzheng Tan 和 Linda Yilin Wen 在 Microsoft Research Game Intelligence 团队中的大力支持和贡献,贯穿整个研究过程。
参考文献
动态时间规整,第69-84页。Springer Berlin Heidelberg, Berlin, Heidelberg, 2007年。ISBN 978-3-540-74048-3。doi: 10.1007/978-3-540-74048-3_4。URL https://doi.org/10. 1007 / 978 − 3 − 540 − 74048 − 3 _ 4 1007 / 978-3-540-74048-3 \_4 1007/978−3−540−74048−3_4.
Pieter Abbeel 和 Andrew Y. Ng。通过逆强化学习进行学徒学习。在第二十一届国际机器学习会议论文集,ICML '04,第1页,纽约,NY,美国,2004年。Association for Computing Machinery。ISBN 1581138385。doi: 10.1145/1015330.1015430。URL https://doi.org/10.1145/1015330.1015430。
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret。用于世界建模的扩散模型:视觉细节很重要在 Atari 中。在第三十八届年度神经信息处理系统会议,2024年。URL https:// openreview.net/forum?id=NadTwTODgC。
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemyslaw Debiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Christopher Hesse, Rafal Józefowicz, Scott Gray, Catherine Olsson, Jakub Pachocki, Michael Petrov, Henrique Pondé de Oliveira Pinto, Jonathan Raiman, Tim Salimans, Jeremy Schlatter, Jonas Schneider, Szymon Sidor, Ilya Sutskever, Jie Tang, Filip Wolski, and Susan Zhang。使用大规模深度强化学习的 Dota 2。CoRR, abs/1912.06680, 2019年。URL http://arxiv.org/abs/1912.06680。
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Maria Elisabeth Bechtle, Feryal Behbahani, Stephanie C.Y. Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando De Freitas, Satinder Singh, and Tim Rocktäschel。Genie:生成互动环境。在 Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp(编辑)的《第四十一届国际机器学习会议论文集》,Proceedings of Machine Learning Research 第 235 卷,第 4603-4623 页。PMLR,2024 年 7 月 21-27 日。URL https://proceedings.mlr.press/v235/bruce24a.html。
Mark Ferguson, Sam Devlin, Daniel Kudenko, and James Alfred Walker。使用动态时间规整模仿游戏风格。在第十七届国际数字游戏基础大会(FDG)2022,美国,2022年5月。ACM。
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson。隐式行为克隆。在 Aleksandra Faust, David Hsu, and Gerhard Neumann(编辑)的《第五届机器人学习会议论文集》,Proceedings of Machine Learning Research 第 164 卷,第 158-168 页。PMLR,2022 年 11 月 8-11 日。URL https://proceedings.mlr.press/v164/florence22a. html。
David Ha 和 Jürgen Schmidhuber。递归世界模型促进策略进化。在 S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, 和 R. Garnett(编辑)的《神经信息处理系统进展》,第 31 卷。Curran Associates, Inc., 2018年。URL https://proceedings.neurips.cc/paper_files/paper/2018/ file/2de5d16682c3c35007e4e92982f1a2ba-Paper.pdf。
Jonathan Ho 和 Stefano Ermon。生成对抗模仿学习。CoRR, abs/1606.03476, 2016年。URL http://arxiv.org/abs/1606.03476。
Adam Jelley, Yuhan Cao, Dave Bignell, Sam Devlin, and Tabish Rashid。像大型语言模型一样对齐智能体,2024年。URL https://arxiv.org/abs/2406.04208.
Anssi Kanervisto, Joonas Pussinen, and Ville Hautamäki。视频游戏中的端到端行为克隆基准测试。CoRR, abs/2004.00981, 2020年。URL https://arxiv.org/abs/ 2004.00981。
Anssi Kanervisto, Dave Bignell, Linda Yilin Wen, Martin Grayson, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Tabish Rashid, Tim Pearce, Yuhan Cao, et al. 游戏玩法创意的世界和人类动作模型。《自然》,638(8051):656-663,2025年。
Alex Lamb, Riashat Islam, Yonathan Efroni, Aniket Rajiv Didolkar, Dipendra Misra, Dylan J Foster, Lekan P Molu, Rajan Chari, Akshay Krishnamurthy, 和 John Langford。具有多步逆模型的控制内源性潜在状态的保证发现。《机器学习研究交易》,2023年。ISSN 2835-8856。URL https://openreview.net/forum? id=TNocbXm5MZ。
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, 和 Saining Xie。2020年代的卷积网络。在2022 IEEE/CVF计算机视觉与模式识别会议(CVPR)上,第11966-11976页,2022年。doi: 10.1109/CVPR52688.2022.01167。
Vincent Micheli, Eloi Alonso, 和 François Fleuret。变压器是样本高效的世界模型。在第十一届国际学习表示会议,2023年。URL https://openreview.net/forum?id=vhFulAcb0xb。
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, 和 Piotr Bojanowski。DINOv2:无监督学习鲁棒视觉特征。《机器学习研究交易》,2024年。ISSN 2835-8856。URL https://openreview.net/forum?id=a68SUt6zFt。
Keiran Paster, Sheila A. McIlraith, 和 Jimmy Ba。从像素规划使用逆动力学模型。在国际学习表示会议上,2021年。URL https: //openreview.net/forum?id=V6BjBgku7Ro。
Brahma S. Pavse, Faraz Torabi, Josiah P. Hanna, Garrett Warnell, 和 Peter Stone。RIDM:用于从单一观察演示中学习的强化逆动力学建模。《IEEE机器人与自动化快报》,5:6262-6269,2019年。URL https://api.semanticscholar.org/ CorpusID:189999150。
Tim Pearce 和 Jun Zhu。使用大规模行为克隆进行反恐精英死亡竞赛。在2022年IEEE游戏会议(CoG)上,第104-111页,2022年。doi: 10.1109/CoG51982.2022.9893617。
Tim Pearce, Tabish Rashid, Anssi Kanervisto, Dave Bignell, Mingfei Sun, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Ida Momennejad, Katja Hofmann, 和 Sam Devlin。使用扩散模型模仿人类行为。在第十一届国际学习表示会议,2023年。URL https://openreview.net/forum?id= Pv1GPQzRrC8。
Tim Pearce, Tabish Rashid, Dave Bignell, Raluca Georgescu, Sam Devlin, 和 Katja Hofmann。预训练智能体和世界模型的缩放定律,2024年。URL https://arxiv.org/ abs/2411.04434。
Dean A. Pomerleau。用于自主导航的人工神经网络高效训练。《神经计算》,3(1):88-97,1991年。doi: 10.1162/neco.1991.3.1.88。
Alec Radford, Jeff Wu, Rewon Child, D. Luan, Dario Amodei, 和 Ilya Sutskever。语言模型是无监督的多任务学习者,2019年。URL https://www.semanticscholar.org/paper/ Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/ 9405cc0d6169988371b2755e573cc28650d14dfe。
Stéphane Ross, Geoffrey J. Gordon, 和 J. Andrew Bagnell。无悔约简用于模仿学习和结构化预测。CoRR, abs/1011.0686, 2010年。URL http://arxiv.org/ abs/1011.0686。
Faraz Torabi, Garrett Warnell, 和 Peter Stone。从观察中生成对抗模仿。CoRR, abs/1807.06158, 2018a年。URL http://arxiv.org/abs/1807.06158。
Faraz Torabi, Garrett Warnell, 和 Peter Stone。从观察中行为克隆。在国际人工智能联合会议上,2018b年。URL https://api. semanticscholar.org/CorpusID:23206414。
Dani Valevski, Yaniv Leviathan, Moab Arar, 和 Shlomi Fruchter。扩散模型是实时游戏引擎,2024年。URL https://arxiv.org/abs/2408.14837。
Oriol Vinyals, I. Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, J. Chung, David H. Choi, Richard Powell, Timo Ewalds, P. Georgiev, Junhyuk Oh, Dan Horgan, M. Kroiss, Ivo Danihelka, Aja Huang, L. Sifre, Trevor Cai, J. Agapiou, Max Jaderberg, A. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, D. Budden, Yury Sulsky, James Molloy, T. Paine, Caglar Gulcehre, Ziyun Wang, T. Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, T. Schaul, T. Lillicrap, K. Kavukcuoglu, D. Hassabis, C. Apps, 和 D. Silver。使用多智能体强化学习达到星际争霸II的大师水平。《自然》,第1-5页,2019a年。
Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, L. Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander Sasha Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David Budden, Yury Sulsky, James Molloy, Tom Le Paine, Caglar Gulcehre, Ziyun Wang, Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy P. Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, 和 David Silver。使用多智能体强化学习达到星际争霸II的大师水平。《自然》,575:350 - 354,2019b年。URL https://api.semanticscholar.org/CorpusID:204972004。
Peter Wurman, Samuel Barrett, Kenta Kawamoto, James MacGlashan, Kaushik Subramanian, Thomas Walsh, Roberto Capobianco, Alisa Devlic, Franziska Eckert, Florian Fuchs, Leilani Gilpin, Piyush Khandelwal, Varun Kompella, HaoChih Lin, Patrick MacAlpine, Declan Oller, Takuma Seno, Craig Sherstan, Michael Thomure, 和 Hiroaki Kitano。使用深度强化学习击败冠军 Gran Turismo 驾驶员。《自然》,602:223-228,2022年2月。doi: 10.1038/s41586-021-04357-7。
Yingchen Xu, Jack Parker-Holder, Aldo Pacchiano, Philip J. Ball, Oleh Rybkin, Stephen J. Roberts, Tim Rocktäschel, 和 Edward Grefenstette。在少量无奖励部署中学习通用世界模型。在 Alice H. Oh, Alekh Agarwal, Danielle Belgrave, 和 Kyunghyun Cho(编辑)的《神经信息处理系统进展》中,2022年。URL https://openreview.net/forum?id=RuNhbvX9o9S。
Chao Yang, Xiaojian Ma, Wenbing Huang, Fuchun Sun, Huaping Liu, Junzhou Huang, 和 Chuang Gan。通过最小化逆动力学不一致性的观察模仿学习,2019年。
A 附录
A. 1 数据模态
数据集包含从2020年9月2日至2022年10月19日记录的8,788场比赛,总计这些轨迹代表大约1.12年的累积人类游戏时间。原始的60 Hz数据已降采样至10 Hz 。每条轨迹都包括视觉和遥测数据,以及游戏过程中玩家采取的动作。
数据集中视觉模态的分辨率为 600 × 360 600 \times 360 600×360,然后在传递给编码器之前将其下采样到 128 × 128 128 \times 128 128×128。
对于动作空间,我们使用了标准的 Xbox 控制器方案。Xbox 控制器通过移动摇杆提供连续输入,并通过按钮提供离散输入,如图 A.1 所示。
3
{ }^{3}
3 我们将连续动作空间归一化到
[
−
1
,
1
]
[-1,1]
[−1,1] 范围,将其离散化为 11 个区间,并将所有按钮视为离散值。
图 A.1:Xbox 控制器输入。标签 1 和 3 表示连续的摇杆输入——每个摇杆有两个可以移动的轴,而其他标签则代表离散的按钮输入。
A. 2 训练
A.2.1 超参数
为了使各种 MLP 和 GPT 模型具有可比性,ConvNeXt (Liu et al., 2022),DINOv2 (Oquab et al., 2024) 和 WHAM (Kanervisto et al., 2025) 编码器的所有潜在维度均设置为 1024。MLP IDM 使用了 4 层,每层隐藏维度为 1024;而 GPT IDM 使用了 4 个 GPT 块,每块隐藏维度为 1024。此外,还使用了 4 层 MLP,每层隐藏维度为 1024,作为预训练的 DINOv2 编码器的可学习状态编码层。我们在单个 NVIDIA H100 80GB GPU 机器上进行训练。使用的 学习率为 0.0001 。
A.2.2 训练曲线
图 A. 2 到 A. 7 展示了模型在分离连续和离散模态下的训练曲线,以进一步研究模型在每个动作空间中的能力。
3
{ }^{3}
3 控制器图像取自:https://support.xbox.com/en-US/help/xbox-360/accessories/controllers
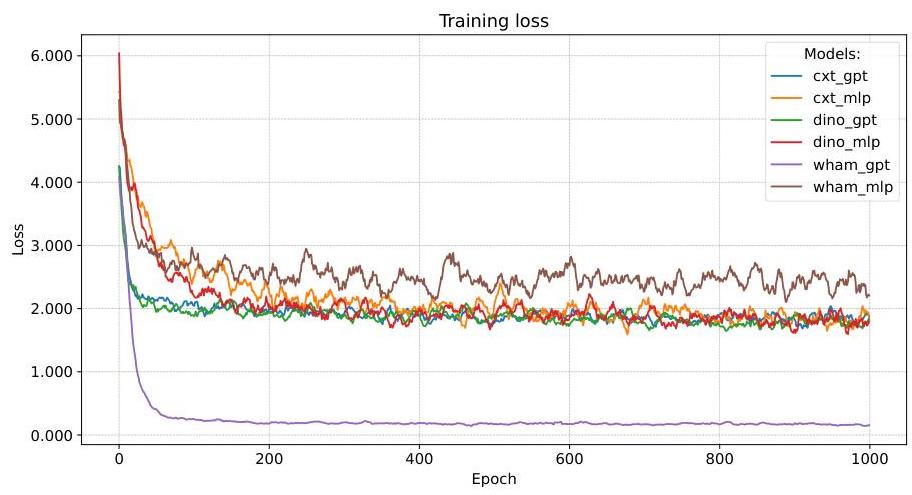
图 A.2:训练损失曲线。
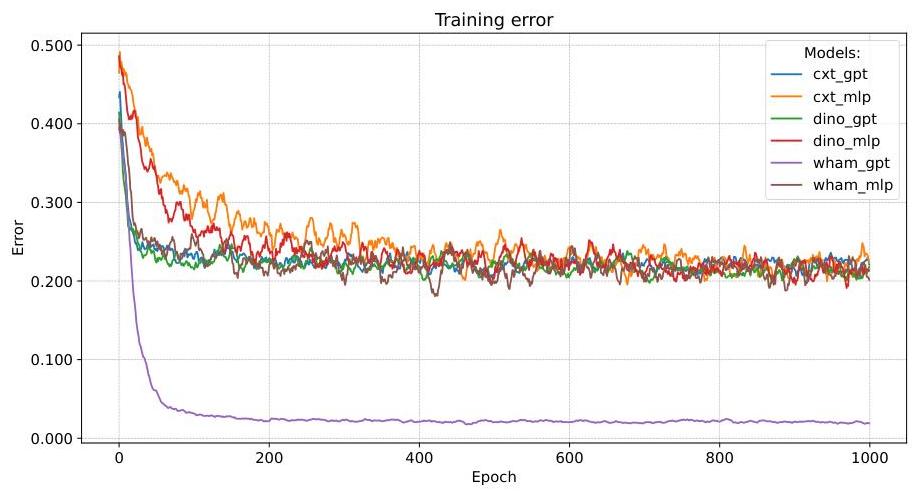
图 A.3:训练误差曲线。
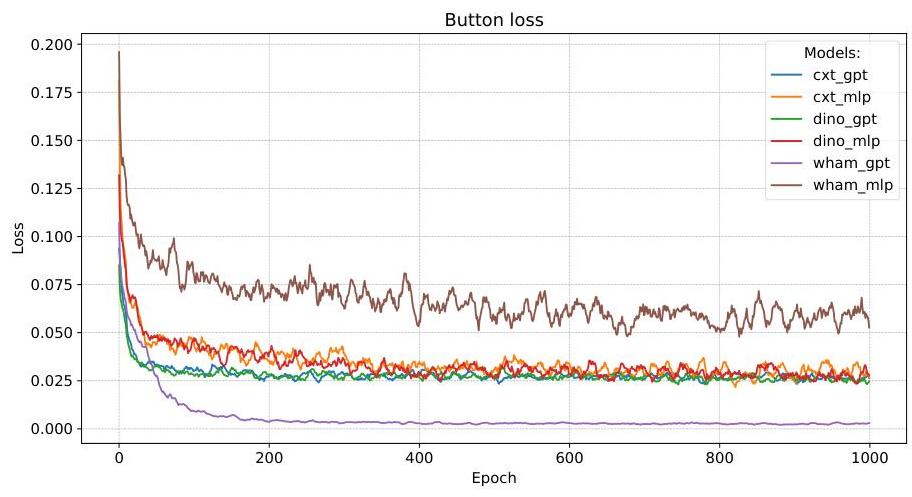
图 A.4:六种模型变体在通用设置下训练的按钮损失曲线。
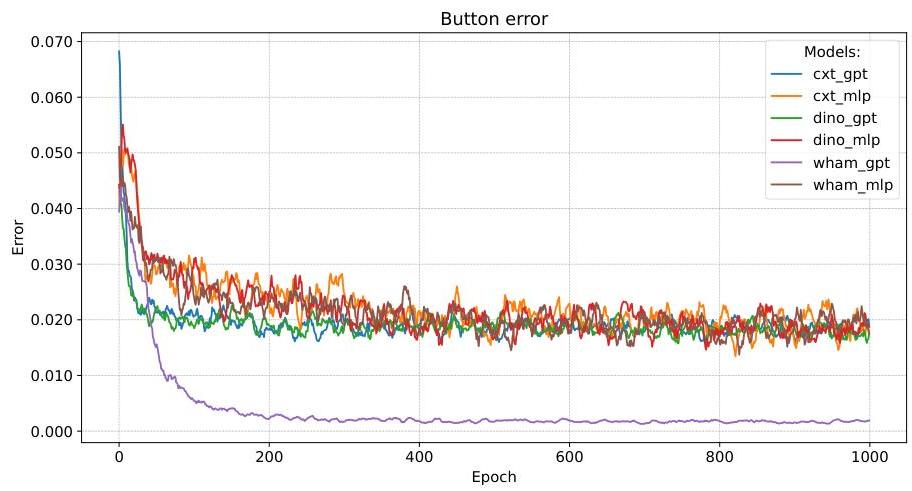
图 A.5:六种模型变体在通用设置下训练的按钮误差曲线。
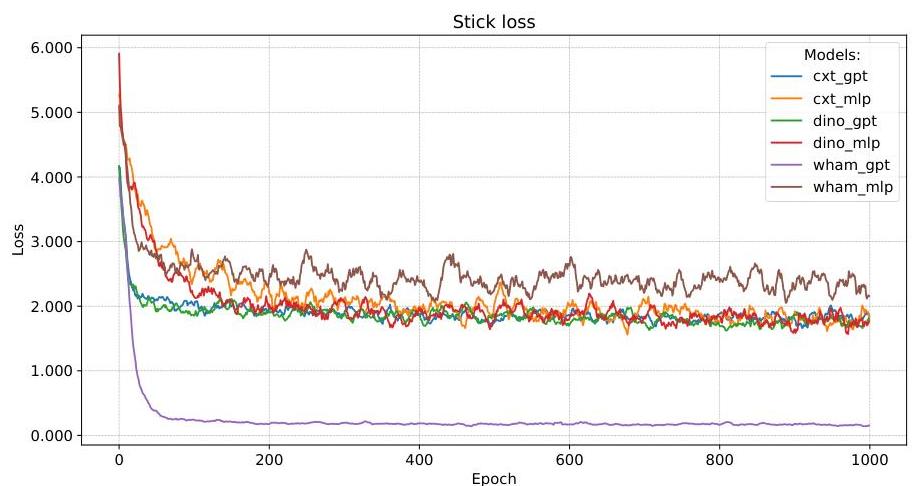
图 A.6:六种模型变体在通用设置下训练的摇杆损失曲线。
图 A.7:六种模型变体在通用设置下训练的摇杆误差曲线。
A. 3 未来选择策略
本节提供了对第3.2节中四种未来条件策略的扩展视图。
静态未来条件 静态未来条件根据当前时间步选择未来的第一个开始时间步。方程1给出了选择未来轨迹开始时间步的公式。这种类型的未来条件不受空间信息的影响。
最近未来条件 最近未来条件使用智能体当前位置并找到地面真实轨迹中最接近点的时间步,该距离由欧几里得距离测量。公式见方程2。
最近未来条件考虑了智能体与条件点之间的空间距离。通过找到离智能体最近的点,我们正在最小化空间距离,尽可能长时间地保持智能体在训练分布内。
这种方法的缺点是有可能陷入无限循环。通过忽略轨迹跟随的时间方面,智能体无法区分同一空间位置的两个帧。
这可以在智能体在 N 帧内静止然后开始移动的轨迹中表现出来。如果 N 大于用作智能体输入的轨迹长度,则目标状态的空间位置将与起始状态相同,经过训练的 IDM 将执行无操作,因为目标已经到达,导致一个无限循环,其中目标不改变,智能体也不移动,导致目标再次不改变。
另一个例子是一个包含循环的轨迹,其中未来的选取策略无法确定我们是在循环的起点还是终点。图 A.8 展示了这种情况。
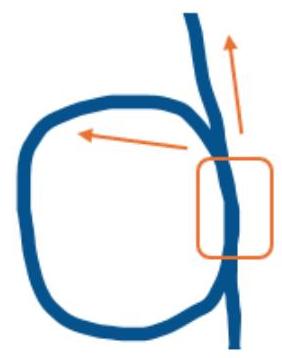
图 A.8:最近未来条件的循环问题。由于没有时间结构,如果轨迹包含两个或更多具有相同位置的帧,那么在橙色方框所标出的位置,最近未来条件策略不知道智能体是否已经完成循环,并随机选择两个可能的未来路径之一,用橙色箭头表示。
半径未来条件 半径未来条件如果智能体足够接近,即位于指定半径内,则将未来开始时间步向前移动 1 步,定义见方程3。不同半径值的实验结果见附录中的表 A.1。
半径未来条件同时考虑时间和空间距离。这种方法成功解决了图 A.8 中的无限循环问题,因为未来开始时间步只能增加。
内外未来条件 内外未来条件通过允许其推进未来超过一帧来扩展半径未来条件。此方法使用两个半径,内半径和外半径。不同半径值的实验结果见表 A.1。
有三种情况智能体可能处于:
- 在内半径内 - 我们将未来移动直到它离开内半径。这使得未来条件修正了智能体由于错误动作或 FPS 变化而领先于未来条件的问题。
-
- 在内半径之外但在外半径之内 - 我们将未来前进 1 帧,与半径选择策略相同。
-
- 在外半径之外 - 我们不移动未来,与半径选择策略相同。
表 A.1:不同半径值的 AUC 结果
- 在外半径之外 - 我们不移动未来,与半径选择策略相同。
| 半径 | 内外 | ||||
|---|---|---|---|---|---|
| 轨迹 | R = 800 \mathrm{R}=800 R=800 | R = 1600 \mathrm{R}=1600 R=1600 | I = 100 , O = 200 \mathrm{I}=100, \mathrm{O}=200 I=100,O=200 | I = 200 , O = 400 \mathrm{I}=200, \mathrm{O}=400 I=200,O=400 | I = 800 , O = 3200 \mathrm{I}=800, \mathrm{O}=3200 I=800,O=3200 |
| Jumppad 左 | 1.00 \mathbf{1 . 0 0} 1.00 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.70 | 0.98 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Jumppad 右 | 0.97 \mathbf{0 . 9 7} 0.97 | 0.94 | 0.38 | 0.98 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Jumppad 中 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.97 | 0.72 | 0.98 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Benchmark 0 | 0.28 | 0.48 \mathbf{0 . 4 8} 0.48 | 0.05 | 0.10 | 0.79 \mathbf{0 . 7 9} 0.79 |
| Benchmark 1 | 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.19 | 0.08 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Benchmark 2 | 0.69 | 0.94 \mathbf{0 . 9 4} 0.94 | 0.13 | 0.16 | 0.79 \mathbf{0 . 7 9} 0.79 |
| Dojo Ramp | 0.33 | 0.63 \mathbf{0 . 6 3} 0.63 | 0.17 | 0.21 | 0.68 \mathbf{0 . 6 8} 0.68 |
| Dojo Gong | 0.25 | 0.47 \mathbf{0 . 4 7} 0.47 | 0.06 | 0.18 | 0.56 \mathbf{0 . 5 6} 0.56 |
| 平均 | 0.69 | 0.81 \mathbf{0 . 8 1} 0.81 | 0.30 | 0.55 | 0.85 \mathbf{0 . 8 5} 0.85 |
A. 4 评估指标
本节定义了论文中使用的 AUC 指标。对于参考轨迹 τ \tau τ 和智能体 rollout τ ^ \hat{\tau} τ^,分别由状态序列 τ = { x t } t = 1 T \tau=\left\{\boldsymbol{x}_{t}\right\}_{t=1}^{T} τ={xt}t=1T 和 τ ^ = { x ^ t } t = 1 T \hat{\tau}=\left\{\hat{\boldsymbol{x}}_{t}\right\}_{t=1}^{T} τ^={x^t}t=1T 表示,我们定义覆盖率
f ( τ ^ , τ , r ) = 1 T ∑ t = 1 T ( I ( ∥ x t − x ^ t ∥ < r ) ) f(\hat{\tau}, \tau, r)=\frac{1}{T} \sum_{t=1}^{T}\left(\mathbb{I}\left(\left\|\boldsymbol{x}_{t}-\hat{\boldsymbol{x}}_{t}\right\|<r\right)\right) f(τ^,τ,r)=T1t=1∑T(I(∥xt−x^t∥<r))
为智能体rollout在指定半径
r
r
r内更接近参考轨迹的百分比
t
i
m
e
s
t
e
p
s
timesteps
timesteps。指示函数
I
(
∥
x
t
−
x
^
t
∥
<
r
)
\mathbb{I}\left(\left\|\boldsymbol{x}_{t}-\hat{\boldsymbol{x}}_{t}\right\|<r\right)
I(∥xt−x^t∥<r) 当
∥
x
t
−
x
^
t
∥
<
r
\left\|\boldsymbol{x}_{t}-\hat{\boldsymbol{x}}_{t}\right\|<r
∥xt−x^t∥<r时为1,否则为0。
AUC 指标定义为半径值
r
∈
[
0
,
R
]
r \in[0, R]
r∈[0,R]低于最大半径
R
R
R的平均覆盖率。此平均值与
f
f
f曲线下的面积成正比,
A U C ( τ ^ , τ ) = 1 R ∫ 0 R f ( τ ^ , τ , r ) d r A U C(\hat{\tau}, \tau)=\frac{1}{R} \int_{0}^{R} f(\hat{\tau}, \tau, r) d r AUC(τ^,τ)=R1∫0Rf(τ^,τ,r)dr
其中最大半径 R R R定义为
R = max t ∈ [ 1 , T ] ∥ x 0 − x t ∥ R=\max _{t \in[1, T]}\left\|\boldsymbol{x}_{0}-\boldsymbol{x}_{t}\right\| R=t∈[1,T]max∥x0−xt∥
一方面,如果智能体rollout接近参考轨迹,随着
r
r
r增大,
f
f
f迅速增长,导致较大的AUC值。另一方面,如果智能体rollout不类似于参考轨迹,对于大多数
r
r
r值,覆盖率保持较低,导致较低的AUC值。
此外,通过使用最大半径
R
R
R重新缩放,AUC指标对参考轨迹的扩展依赖性较小。
A. 5 完整结果
本节展示了每条轨迹每个模型的完整结果。
表 A.2:在8条保留轨迹上进行通用设置评估的FI结果。较高的FI较好。
| MLP | GPT | |||||||
|---|---|---|---|---|---|---|---|---|
| 轨迹 | ConvNeXt | DINOv2 | WHAM | ConvNeXt | DINOv2 | WHAM | ||
| Jumppad 左 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.89 | 0.94 | 0.96 | 0.98 | 0.88 | ||
| Jumppad 右 | 1.00 \mathbf{1 . 0 0} 1.00 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.87 | 0.97 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.88 | ||
| Jumppad 中 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.98 | 0.69 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.85 | 0.92 | ||
| Benchmark 0 | 0.25 | 0.21 | 0.18 | 0.48 \mathbf{0 . 4 8} 0.48 | 0.30 | 0.25 | ||
| Benchmark 1 | 0.61 | 0.63 | 0.14 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.54 | 0.43 | ||
| Benchmark 2 | 0.62 | 0.21 | 0.09 | 0.94 \mathbf{0 . 9 4} 0.94 | 0.92 | 0.33 | ||
| Dojo Ramp | 0.22 | 0.21 | 0.22 | 0.29 \mathbf{0 . 2 9} 0.29 | 0.24 | 0.22 | ||
| Dojo Gong | 0.09 | 0.11 | 0.12 | 0.18 \mathbf{0 . 1 8} 0.18 | 0.12 | 0.09 | ||
| 平均 | 0.55 | 0.53 | 0.40 | 0.73 \mathbf{0 . 7 3} 0.73 | 0.62 | 0.50 |
表 A.3:展示使用不同输入的 ConvNeXt-GPT 智能体性能的消融实验。
| 轨迹 | 仅观察 | 仅动作 | 完整模型 | |||
|---|---|---|---|---|---|---|
| AUC | FI | AUC | FI | AUC | FI | |
| Jumppad 左 | 0.99 \mathbf{0 . 9 9} 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.93 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.99 | 0.96 |
| Jumppad 右 | 0.99 \mathbf{0 . 9 9} 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.91 | 0.82 | 0.95 | 0.97 |
| Jumppad 中 | 0.99 \mathbf{0 . 9 9} 0.99 | 0.95 | 0.88 | 0.80 | 0.93 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Benchmark 0 | 0.46 | 0.29 | 0.53 \mathbf{0 . 5 3} 0.53 | 0.17 | 0.50 | 0.48 \mathbf{0 . 4 8} 0.48 |
| Benchmark 1 | 0.98 \mathbf{0 . 9 8} 0.98 | 0.92 | 0.65 | 0.41 | 0.81 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Benchmark 2 | 0.93 \mathbf{0 . 9 3} 0.93 | 0.88 | 0.45 | 0.25 | 0.69 | 0.94 \mathbf{0 . 9 4} 0.94 |
| Dojo Ramp | 0.71 \mathbf{0 . 7 1} 0.71 | 0.27 | 0.55 | 0.21 | 0.63 | 0.29 \mathbf{0 . 2 9} 0.29 |
| Dojo Gong | 0.68 \mathbf{0 . 6 8} 0.68 | 0.32 \mathbf{0 . 3 2} 0.32 | 0.67 | 0.08 | 0.67 | 0.18 |
| 平均 | 0.84 | 0.70 | 0.69 | 0.47 | 0.86 \mathbf{0 . 8 6} 0.86 | 0.73 \mathbf{0 . 7 3} 0.73 |
表 A.4:展示不同未来和过去长度的 ConvNeXt-GPT 智能体性能的消融实验。
| BC | 1P-1F | 10P-1F | 1P-10F | 完整模型 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 轨迹 | AUC | FI | AUC | FI | AUC | FI | AUC | FI | AUC | FI |
| Jumppad 左 | 0.90 | 0.78 | 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.99 | 0.96 | 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.99 | 0.96 |
| Jumppad 右 | 0.90 | 0.64 | 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.99 | 0.90 | 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.99 | 0.97 |
| Jumppad 中 | 0.92 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.99 | 0.98 | 0.99 | 0.91 | 0.99 | 0.98 | 0.99 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Benchmark 0 | 0.34 | 0.18 | 0.47 | 0.28 | 0.47 | 0.39 | 0.55 | 0.21 | 0.64 | 0.48 \mathbf{0 . 4 8} 0.48 |
| Benchmark 1 | 0.54 | 0.37 | 0.98 | 0.98 | 0.98 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.97 | 1.00 \mathbf{1 . 0 0} 1.00 | 0.98 | 1.00 \mathbf{1 . 0 0} 1.00 |
| Benchmark 2 | 0.44 | 0.27 | 0.89 | 0.68 | 0.94 | 0.78 | 0.87 | 0.64 | 0.95 | 0.94 \mathbf{0 . 9 4} 0.94 |
| Dojo Ramp | 0.55 | 0.21 | 0.72 | 0.45 \mathbf{0 . 4 5} 0.45 | 0.73 | 0.40 | 0.54 | 0.23 | 0.65 | 0.29 |
| Dojo Gong | 0.51 | 0.11 | 0.69 | 0.18 | 0.72 | 0.21 \mathbf{0 . 2 1} 0.21 | 0.44 | 0.04 | 0.70 | 0.18 |
| 平均 | 0.64 | 0.45 | 0.84 | 0.69 | 0.85 | 0.69 | 0.79 | 0.64 | 0.86 | 0.73 |
参考论文:https://arxiv.org/pdf/2504.12299


















 8846
8846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











