






查德·科尔曼
纽约大学
cjc652@nyu.edu
W. 罗素·纽曼
纽约大学
wrn210@nyu.edu
阿里·达斯丹
DropBox
alidasdan@gmail.com
萨菲纳·阿里
纽约大学
sa1940@nyu.edu
马南·沙阿
纽约大学
ms10537@nyu.edu
摘要
随着大型语言模型(LLMs)越来越多地应用于具有重大影响的决策环境中,系统评估其伦理推理能力已成为一项关键任务。本文介绍了PRIME框架——一种全面的方法,用于分析基础伦理维度上的道德优先级,包括结果主义-义务论推理、道德基础理论和科尔伯格的发展阶段。我们通过结合直接提问和对既定伦理两难问题的响应分析,将此框架应用于六个领先的LLMs。我们的分析揭示了显著的趋同模式:所有被评估的模型都表现出对关爱/伤害和公平/欺骗基础的强烈优先级,而权威、忠诚和神圣维度则始终被低估。通过详细检查置信度指标、响应犹豫模式和推理一致性,我们确定当代LLMs (1) 能够做出明确的伦理判断,(2) 在道德决策方面显示出显著的跨模型一致性,(3) 总体上与经验证实的人类道德偏好相符。这项研究贡献了一种可扩展、可扩展的方法来进行伦理基准测试,同时突显了当前AI道德推理架构中令人鼓舞的能力和系统性局限性——这些洞见对于负责任地开发这些在社会中日益扮演重要角色的系统至关重要。
随着生成式大型语言模型(LLMs)的迅速发展,对齐问题已成为AI伦理讨论的核心议题——具体来说,这些模型是否与人类价值观适当对齐(Bostrom, 2014; Tegmark 2017; Russell 2019; Kosinski, 2024)。随着这些强大模型在各个社会领域的决策过程中越来越广泛地集成(Salazar, A., & Kunc, M., 2025),理解其操作逻辑是否以及如何与基本人类价值观对齐不再仅仅是学术问题,而是成为一项关键的社会任务。三个问题随之产生。1) 面对道德困境时,这些模型是否会做出明确的决定?2) 不同LLMs的响应是否具有一致性?3) LLMs的道德选择模式是否与广义上定义的人类价值观有意义的对齐?在本文中,我们将提出一个分析框架并展示研究成果以解决前两个问题,并对第三个问题进行初步探索性分析。我们认为这些问题的答案是:是的,是的,也是的。当然,存在一些限制和例外情况,但我们相信总体模式是清晰的。我们的方法不仅允许我们探索它们做出了哪些选择,还探索了导致这些决策的思考链条。
道德哲学的传统通常不会为特定的道德困境和复杂情境提供明确的“正确”答案(Grassian 1992;Joyce 2006;Jonsen & Toulmin, 1988)。相反,这一文献提供了框架和原则,帮助分析不同视角下的情境挑战(Neuman, Coleman & Shah 2025;Bickley & Torgler, 2023)。因此,虽然技术文献中突出使用了基于事实的方法来衡量基准和比较模型性能指标(Reuel et al. 2024),但这种方法对于理解伦理推理而言并不充分。我们需要的是一个系统框架,用于分析这些模型如何解释和证明其伦理决策。
我们提出了一种新颖的分析框架,利用来自道德哲学、比较伦理学和行为心理学的三种已建立类型学来考察LLM伦理推理。一个关键视角,道德基础理论(Haidt, 2012;Graham et al., 2009),使我们能够超越简单的判断,检查给予不同道德直觉(如关爱和公平与忠诚、权威和神圣之间的相对权重)。认识到人类道德心理学中的既定模式,例如不同社会群体(通常以自由-保守主义划分)对这些基础的不同优先级(Graham et al., 2009;Haidt, 2012),为我们提供了研究类似模式或偏见是否在LLM推理中显现的途径。这一整体方法与Gunning (2019) 所称的“可解释AI”相呼应,同时为跨不同伦理维度的比较分析提供了严格的结构(Kohlberg, 1981;Shneiderman, 2022)。该框架关注的不是评估伦理决策的正确性,而是系统分析这些系统如何通过自我描述和对经典道德两难问题的响应来解释和证明其选择。至关重要的是,这种多框架方法不仅用于分析本研究中的特定模型,还为研究人员提供了一种稳健且可扩展的方法,以系统评估当前和未来AI系统的伦理推理能力。
我们的方法包含两种不同的程序:1)使用标准化提示和类型学框架直接询问模型关于其伦理决策过程的问题,2)分析模型对经典道德两难问题的响应,随后对其推理解释进行结构化评估。该框架采用三种互补的分析视角:后果主义-义务论二分法(Alexander & Moore 2024)、道德基础理论(Haidt & Craig 2004)和科尔伯格的道德发展阶段(Kohlberg 1964, 1981)。
为了测试和演示这个框架,我们检查了六个广泛使用的生成式AI工具:OpenAI的GPT4o、Meta的LLaMA 3.1、Perplexity、Anthropic的Claude 3.5 Sonnet、Google的Gemini和Mistral的7B。虽然我们的发现必然局限于当前一代的变压器模型,但该框架本身设计为可扩展且适用于未来的AI系统。
问题陈述
随着人工智能系统越来越多地参与道德决策,理解其道德推理模式和能力对于负责任的AI开发和部署变得至关重要。当前文献缺乏对不同语言模型如何在各种伦理框架下处理道德困境的综合分析,特别是在其道德基础偏好、决策信心和推理模式方面的系统分析。尽管现有研究已经考察了AI在特定伦理情景中的决策,但我们对不同语言模型如何系统地处理和应对跨多个伦理维度的道德挑战的理解仍然存在显著差距。
这一挑战的复杂性因AI推理中不同道德基础之间的相互作用、不同类型伦理决策中的信心水平差异以及这些系统在优先考虑某些道德考量时可能存在的潜在偏差而加剧。理解这些模式和变化对于开发更加平衡和合乎道德的AI系统至关重要,同时也帮助识别当前AI道德推理方法中的潜在局限性或偏差。
研究问题
- 当代语言模型在不同伦理基础上的道德推理方法有何差异?
-
- 面对复杂的伦理两难问题时,其决策过程、信心水平和道德基础偏好会出现什么模式?
这些问题借鉴了先前研究AI伦理框架的工作(Etzioni & Etzioni, 2017; Wallach & Allen, 2009),同时特别关注在不同道德基础上出现的推理模式,具体考察不同道德基础在AI推理中的相互作用、决策信心与推理复杂性的关系,以及不同模型在优先和处理各种伦理考量方面的系统模式。
- 面对复杂的伦理两难问题时,其决策过程、信心水平和道德基础偏好会出现什么模式?
实施框架:核心组件和评估协议
对大型语言模型(LLMs)伦理推理的系统分析需要仔细关注响应的引出及其后续分析。我们的框架,如图1所示,建立了特定的协议,保持灵活性的同时适应这些系统不断发展的能力(Hagendorff & Danks, 2023; Prem, 2023)。该框架包括两个关键元素:响应引出和分析评估,如下所述。
优先事项在推理和内在道德评价(PRIME)框架采用双重引出策略,旨在揭示LLM伦理推理过程的不同方面。第一个组成部分侧重于通过直接询问道德决策过程进行自我描述的伦理分析。这包括关于一般伦理推理、与既定道德框架相关的问题以及关于系统对其自身推理理解的元认知提示的查询(Butlin等,2023;Atari等,2023)。
第二个组成部分通过既定的伦理两难问题检查应用推理。这些场景包括经典的电车问题,以探讨结果主义与义务论思维(Greene, 2023; Thomson, 1976),海因茨两难问题以检查道德发展阶段(Kohlberg, 1981; Rest, 1979),以及救生艇场景以评估复杂的多方伦理计算(Brzozowski, 2003; Hardin, 1974)。博弈论场景如囚徒困境和独裁者游戏提供了对战略性伦理思维的额外见解(Peterson, 2015; Axelrod, 1984)。
本研究中选择博弈论场景如囚徒困境和独裁者游戏代表了一种战略性的方法论选择,增强了分析框架的深度和生态效度。选择博弈论场景是因为它们提供了需要在个人利益和集体福利之间取得平衡的结构化伦理决策背景,从而揭示了语言模型如何在具有竞争性道德要求的复杂社会两难情境中导航。与更抽象的伦理问题不同,这些场景提供了可量化的结果和明确的决策点,使研究人员能够系统地比较不同AI系统的伦理推理模式、战略思维能力和道德基础偏好。此外,博弈论困境已经在人类道德心理学中得到了广泛研究(如参考Peterson, 2015和Axelrod, 1984),提供了可以用来比较AI道德推理的既定基准。通过将这些场景与经典的电车问题和海因茨两难问题结合,我们创建了一个全面的评估协议,能够检查语言模型在不同背景下如何平衡不同的伦理考量,从而解决了关于道德推理方法和决策过程模式变化的研究问题。
图1:拟议的PRIME框架评估LLM响应的流程图
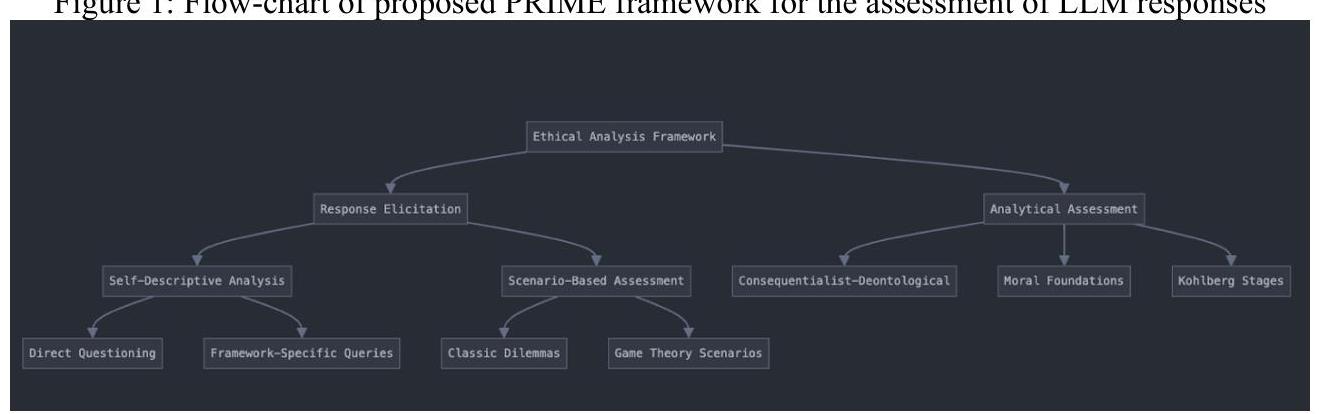
PRIME应用三种互补的分析视角来检查响应。首先,根据古典道德哲学(Alexander & Moore, 2024)确立的标准,检查结果主义和义务论推理之间的平衡。这一分析揭示了系统是否优先考虑基于结果的推理、基于规则的原则,还是采用结合两者观点的混合方法。
第二种分析视角运用道德基础理论评估通过基本道德直觉(Haidt & Craig, 2004)作出的响应。这包括检查系统如何权衡关爱和防止伤害、公平和互惠、对集体利益的忠诚、对合法权威的尊重以及对更高原则的遵守。对这些基础的相对强调提供了对LLMs如何优先考虑不同道德考量的洞察。
第三维将响应映射到科尔伯格的道德发展阶段,从专注于惩罚和自我利益的前习俗阶段,到强调社会规范的习俗阶段,再到考虑普遍原则的后习俗阶段(Kohlberg, 1981)。这种映射有助于揭示不同场景中道德推理的复杂性和一致性。
按照Reuel等(2024)的做法,我们实施了多位独立分析师,以确保在不同模型中可靠编码和模式识别。评估过程从全面记录初始响应开始,包括所有澄清和详细说明。多位独立分析师应用三种分析框架,以确保可靠编码和模式识别。这一过程使得既能在模型内跨场景分析,也能在跨模型间比较推理模式。
质量控制措施包括标准化提示制定、定期校准分析程序和系统调查异常响应。该框架强调记录模式和边缘案例,保持方法论严谨性,同时对LLM伦理推理保持开放态度,接受意外见解(Bickley & Torgler, 2023)。
方法
本研究采用了混合方法(Reuel等,2024)来分析大型语言模型中的道德推理模式。研究设计结合了道德基础得分的定量分析和响应模式的定性评估,利用比较框架来检查六个不同的LLMs:OpenAI的GPT4o、Meta的LLaMA 3.1、Perplexity、Anthropic的Claude 3.5 Sonnet、Google的Gemini和Mistral的7B。为简单起见,这些模型分别被称为ChatGPT、LLaMA、Perplexity、Claude、Gemini和Mistral。这些模型的选择基于它们的广泛使用和不同的架构方法,代表了多种训练方法和能力,允许对不同AI系统中的道德推理模式进行全面比较。
数据收集过程包括三个主要阶段。第一阶段,向每个LLM呈现一组标准化的道德两难问题,旨在基于道德基础理论(Thoma & Dong, 2014)探测不同的道德基础。每个模型收到相同的场景以确保比较的一致性,并为每个两难问题收集多个响应以评估响应稳定性。第二阶段,为每个两难问题收集三个连续响应,逐字记录,包括任何不确定性或资格表达。记录每个响应的时间戳以分析决策模式,并使用标准化提示进行所有互动以保持一致性。第三阶段,提示模型提供决策的信心评分(0-100),并在每次道德判断后立即收集信心评估。使用额外的提示以获取信心评分的解释。
本研究使用了几种关键仪器和测量方法。六维道德基础框架包括关爱/伤害、公平/欺骗、忠诚/背叛、权威/颠覆、神圣/堕落和自由/压迫,每个维度根据标准化标准在1-5分范围内评分。应用科尔伯格道德推理量表(Colby & Kohlberg, 1987)评估道德推理的复杂性,分数范围为1-6,对应科尔伯格的道德发展阶段。两位独立评分员使用标准化评分标准进行评估。此外,开发了一个自定义指标来量化决策犹豫,纳入因素包括响应中的资格数量、不确定性的表达、达到最终决策所需的时间以及多次响应中的立场变化。
数据分析阶段结合了定量和定性方法。定量分析包括相关分析,计算道德基础得分之间的皮尔逊相关系数,并在p<0.05的情况下测试统计显著性。信心得分分析使用箱形图比较分布,并使用回归分析检查与科尔伯格得分的关系。响应模式分析使用堆叠条形图可视化决策时间,并计算和比较不同模型的犹豫得分。定性分析使用自然语言处理(NLP)技术进行文本分析,包括词频分析、情感分析和主题建模以识别关键主题(Schramowski等,2022)。道德基础映射使用雷达图可视化道德基础概况,并结合内容分析以识别特定基础的语言。
为确保有效性和可靠性,实施了几项措施。两名独立评分员对响应进行评分,并计算Cohen’s kappa以评估一致性和解决分歧。使用多个场景进行交叉验证以测试响应的一致性,并在多次测试会话中验证模式。分析使用基于Python的数据处理管道,统计分析使用标准科学计算库和包括matplotlib和seaborn在内的可视化工具。开发了自定义脚本来进行道德基础评分。
研究团队仔细考虑了情景设计和解释中的伦理影响和潜在偏见。虽然与AI系统而非人类受试者合作减少了传统伦理问题,但仍关注情景呈现的公平性、评分标准的透明度、训练数据中的潜在偏见以及研究结果对AI部署的影响。实施了几种方法学控制以解决潜在限制,包括标准化提示以减少问题呈现的变化、多次测试会话以考虑响应变异性、不同道德基础的平衡表示以及评分方法的交叉验证。这一全面的方法旨在提供对LLMs道德推理的严格分析,同时保持研究过程的可重复性和可靠性。
发现
本节呈现了对各种语言模型(LLMs)道德推理模式的全面分析。我们研究了不同道德基础、信心水平、响应犹豫和语言模式之间的复杂交互作用,涉及六个著名的LLMs:ChatGPT、Claude、Gemini、LLaMA、Mistral和Perplexity。我们多层次的检查采用了相关分析、信心评估、响应模式分析、道德基础画像和文本分析,揭示了这些模型在伦理决策方式上的系统差异。这些发现为了解当代LLMs的道德推理能力提供了宝贵的见解,揭示了模型之间的共性和反映其底层架构和训练差异的显著变化。以下小节详细列出了我们在每个分析维度上的具体观察。
图2:LLM响应的道德基础得分相关矩阵。
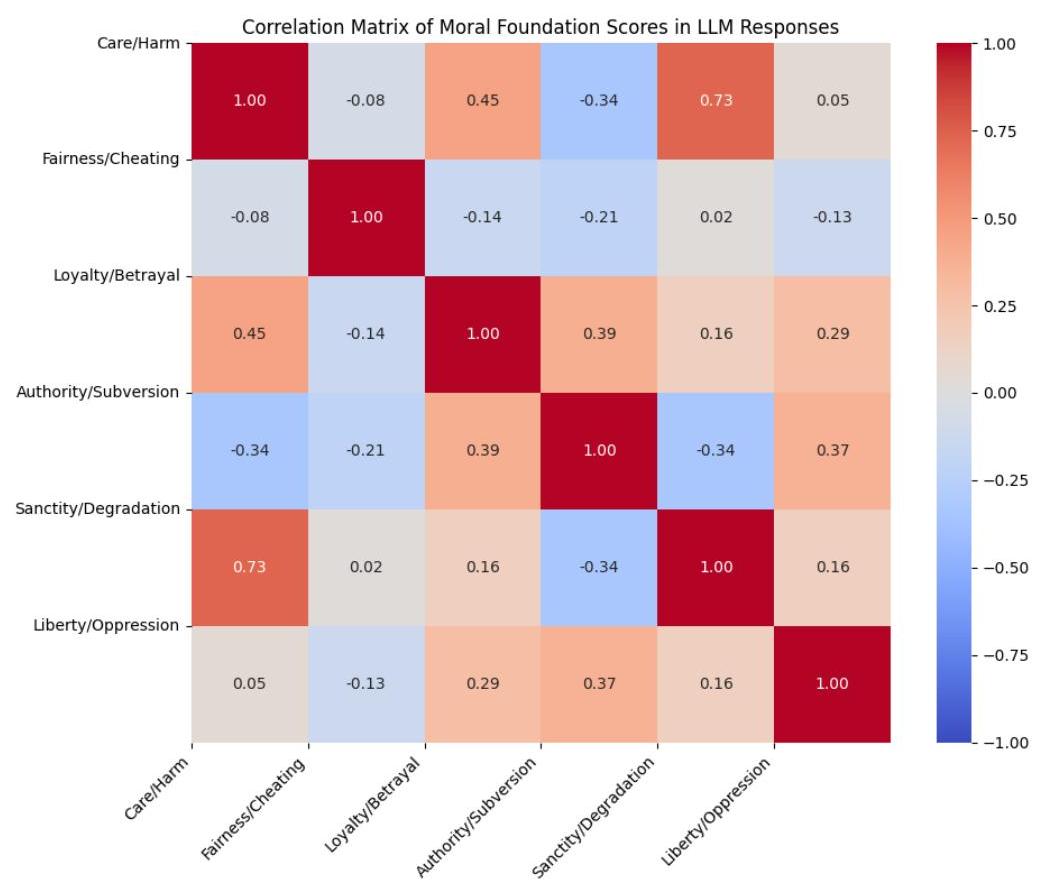
图2中的相关矩阵揭示了LLM响应中不同道德基础得分之间的几个显著关系。最强的正相关(r=0.73)出现在关爱/伤害和神圣/堕落得分之间,表明这些道德基础经常在LLM输出中共同出现。忠诚/背叛与关爱/伤害(r=0.45)和权威/颠覆(r=0.39)显示中等正相关,表明这些道德维度之间存在某种程度的一致性。
有趣的是,权威/颠覆与关爱/伤害(r=-0.34)和神圣/堕落(r=-0.34)表现出负相关,表明这些道德基础在LLM响应中可能存在潜在的紧张关系。公平/欺骗维度与其他大多数基础显示弱负相关,其中与权威/颠覆的最强负相关为(r=-0.21)。自由/压迫得分与其他大多数基础的相关性较弱,除了与权威/颠覆的中等正相关(r=0.37)。这表明LLM响应中的自由考虑可能在很大程度上独立于其他道德基础运作。
这些模式表明,LLM响应中的道德基础并非完全一致,而是显示出复杂的交互作用,有些基础显示强烈的正关联,而另一些则表现出负或微弱的关系。这种复杂性反映了人类道德心理学研究的发现(Atari等,2023),表明LLMs可能正在捕捉人类推理中观察到的一些道德直觉之间的细微互动,并模仿这些系统试图参与的道德推理的微妙性质。
图3:信心和科尔伯格得分分布
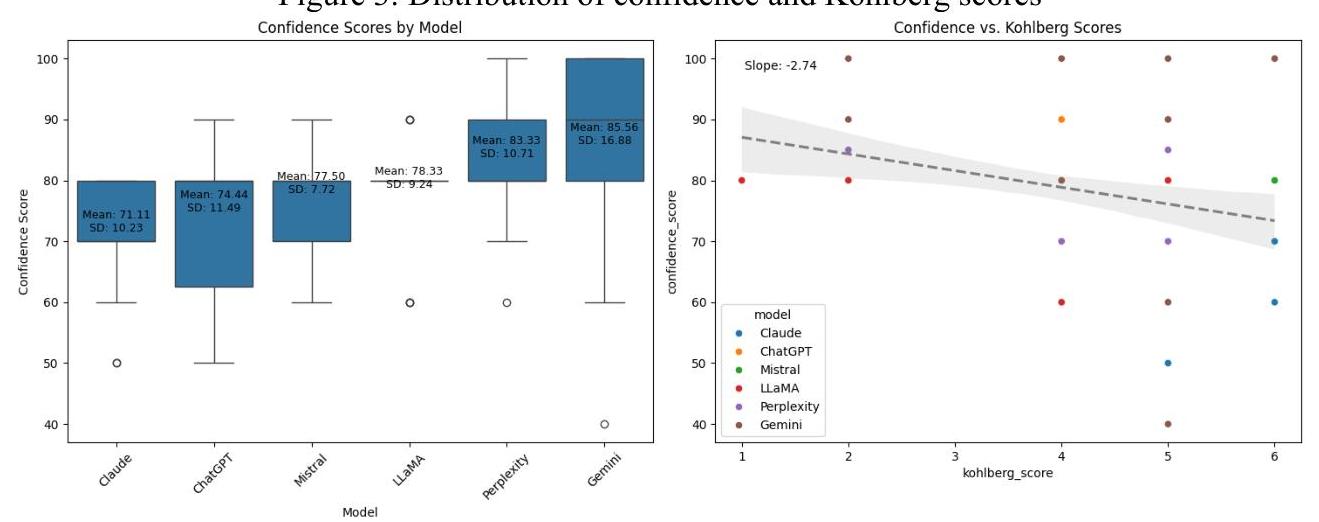
图3展示了两个互补的可视化图表,分析不同语言模型的信心得分及其与科尔伯格道德推理得分的关系。第一个可视化是一个箱形图,比较六个不同语言模型的信心得分,而第二个是散点图,描绘信心得分与科尔伯格道德推理得分之间的关系。
信心得分分析显示,在所考察的六个语言模型中存在显著差异(见图3)。Gemini表现出最高的平均信心(M=85.56,SD=16.88),其次是Perplexity(M=83.33,SD=10.71)。LLaMA(M=78.33,SD=9.24)、Mistral(M=77.50,SD=7.72)和ChatGPT(M=74.44,SD=11.49)表现出中等的信心水平。Claude表现出最低的平均信心(M=71.11,SD=10.23)。
箱形图揭示了信心分布的显著变化。Gemini和Perplexity表现出较高的中位数信心得分(分别约为90和85),与其他模型相比。Claude、ChatGPT和Mistral表现出相似的中位数信心得分,在70-80范围内,具有相当的四分位距和更对称的分布。LLaMA表现出相对较窄的分布,集中在80左右,尽管它包含了一些极端值。所有模型都表现出异常值,尤其是在较低范围内,表明在道德推理中偶尔出现明显的不确定性。
事后分析使用Tukey的HSD检验确定了模型间信心表达的三个统计显著差异。Gemini表现出比Claude(均值差异=14.44,p=.003)和ChatGPT(均值差异=11.11,p=.048)显著更高的信心。此外,Perplexity表现出比Claude显著更高的信心(均值差异=12.22,p=.021)。其他成对比较未达到统计显著性(p>.05)。
检查信心得分与科尔伯格道德推理得分之间关系的散点图显示了轻微的负相关,由向下倾斜的回归线(斜率=-2.74,截距=89.81)指示。这表明,当模型参与更复杂的道德推理场景(更高的科尔伯格得分)时,倾向于表达稍低的信心。信心得分在所有科尔伯格级别(1-6)范围内从大约40到100不等。值得注意的是,在每个科尔伯格级别上,信心得分都有相当大的变化,表明推理复杂性与信心之间的关系并不是很强的决定性。
科尔伯格得分分析揭示了模型间道德推理复杂性的差异。Claude表现出最高的平均科尔伯格得分(M=4.56,SD=1.10),而LLaMA表现出最低的得分(M=3.72,SD=1.45)。值得注意的是,拥有最高信心得分的模型(Gemini和Perplexity)不一定表现出最复杂的道德推理,这表明信心与推理质量之间可能存在脱节。
数据显示,不同模型在道德决策中表达信心的方式有有趣的模式。虽然一些模型(尤其是Gemini和Perplexity)一贯表达高度信心,其他模型则维持较为中等的信心水平。信心与科尔伯格得分之间的负相关表明相对于问题复杂性的适当信心校准,尽管这种关系较为适度。这种模式与人类道德判断研究(Rathi & Kumar, 2020)一致,其中对道德复杂性的更多认识往往与更大的认知谦逊相联系。
这些发现对需要道德推理的上下文中AI系统开发和部署具有重要意义,特别是关于适当的不确定性表达。模型间信心模式的变化表明,架构和训练差异可能显著影响模型在道德推理任务中评估自身确定性的能力。需要进一步研究以理解驱动这些信心模式的因素及其与表现准确性的关系。
图4:LLMs的响应犹豫频率
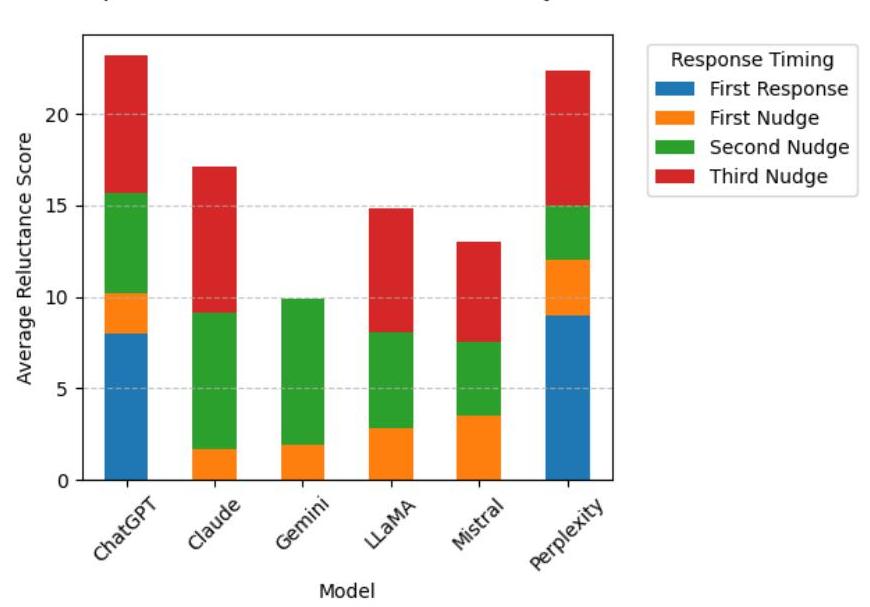
图4显示了六个不同语言模型(ChatGPT、Claude、Gemini、LLaMA、Mistral和Perplexity)的响应模式和犹豫得分的比较分析,提供了这些模型如何处理复杂道德决策的见解。该可视化结合了两个关键指标:最终决策的时间(由颜色编码段表示首次、第二次或第三次响应)和每个模型的整体犹豫得分。
在犹豫得分分布中出现了显著的模式,ChatGPT和Perplexity表现出最高的整体犹豫得分(约23分),这表明这些模型在其决策过程中表现出更多的犹豫或谨慎考虑。相比之下,Mistral和LLaMA表现出较低的整体犹豫得分(约13-15分),可能表明更为直接或果断的响应模式。Claude和Gemini处于中间范围,犹豫得分分别为约17分和10分。
表1:模型犹豫得分
| 模型 | 第一 | 一次引导 | 两次引导 | 三次引导 |
|---|---|---|---|---|
| ChatGPT | 8 | 2.2 | 5.5 | 7.5 |
| Claude | 1.64 | 7.5 | 8 | |
| Gemini | 1.88 | 8 | ||
| LLaMA | 2.83 | 5.25 | 6.75 | |
| Mistral | 3.5 | 4 | 5.5 | |
| Perplexity | 9 | 3 | 3 | 7.36 |
最终决策的时间揭示了模型间的有趣变化。ChatGPT和Perplexity显示出大量的第一次响应成分(由蓝色段表示),表明它们通常在互动早期就做出最终决策。然而,它们仍保持高犹豫得分,表明尽管它们可能快速决策,但在响应中表达了显著的考虑。相反,Gemini和Claude表现出更为分散的决策模式,最终决策分布在所有三次响应机会中(第一次、第二次和第三次响应),可能表明更为迭代的决策过程。
这些发现为不同语言模型在面对道德决策时的深思熟虑能力提供了有价值的见解。犹豫得分和响应时间模式的变化表明,不同模型采用不同的伦理推理方法。一些模型,如ChatGPT和Perplexity,结合快速决策和高表达犹豫,而其他模型,如Gemini和Claude,则表现出更为分散的决策模式。这种方法的多样性提出了关于AI系统处理道德问题时果断性和慎重考虑之间最佳平衡的有趣问题,例如AI公司如何选择为LLMs创建防护机制以避免在道德决策提示中显得过于果断,这些防护机制在LLMs间可能存在差异,这些策略在现实世界道德决策场景中可能带来益处或危害,尤其是在决策时间至关重要的情况下,以及这种深思熟虑可能如何通过简单的引导策略被绕过。
关于LLMs防护水平差异的观察引发了关于AI伦理护栏的重要问题。不同处理道德情景的方法确实表明AI开发者之间存在不同的优先事项——一些人强调更强的犹豫机制,而其他人则允许更多的果断性。然而,通过简单引导技术普遍成功地绕过这些防护措施暴露了当前系统的一个根本漏洞。这挑战我们重新考虑这些保护措施真正有多有效,以及它们是否提供了有意义的安全保障或只是表面上的约束。在AI伦理发展中,深思熟虑的谨慎与果断行动之间的平衡代表了一个中心矛盾——过度犹豫可能导致AI在需要道德判断的时间敏感情况下无用,而防护不足则可能导致过早或有害的结论。这凸显了需要更复杂的护栏系统,能够在保持适当犹豫的同时抵抗操纵,特别是随着这些系统在具有重大影响的决策背景下越来越嵌入。
这一分析的局限性在于,它没有揭示最终决策的细微差别或适当性,只揭示了这些决策是如何以及何时达成的模式。进一步的研究可以调查这些响应模式与最终决策的伦理有效性之间的关系,以及较高犹豫得分是否与更细致或更合乎道德的响应相关。
使用雷达图完成对六个不同语言模型(Claude、ChatGPT、Mistral、LLaMA、Perplexity 和 Gemini)的道德基础取向的比较分析(图5)。每条线映射五个关键道德维度:忠诚、公平、关怀、自由和神圣,权威位于忠诚和神圣之间。雷达图使用从1到4 的尺度,从中心向外辐射,以量化每个模型对这些道德基础的相对重视程度。
图5:模型特征雷达分布
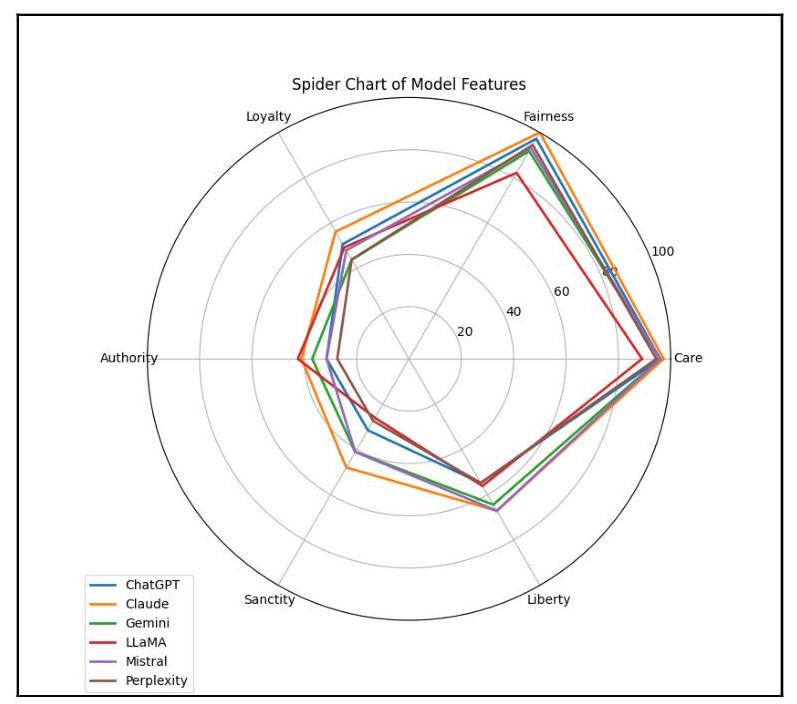
在所有六个模型中出现了一个显著的模式,显示出它们的道德基础概况具有惊人的连贯性。最显著的重视出现在关怀和公平维度上,持续接近图表的外环。这表明这些语言模型已被开发为具有强烈导向于以预防伤害和公平对待为中心的伦理原则。相比之下,权威、忠诚和神圣基础通常显示较低的读数。
表2:基础得分统计
| 关怀 平均值 | 公平 平均值 | 忠诚 平均值 | 权威 平均值 | 神圣 平均值 | 自由 平均值 | |
|---|---|---|---|---|---|---|
| ChatGPT | 3.889 | 3.944 | 2.056 | 1.278 | 1.278 | 2.222 |
| Claude | 3.944 | 4.056 | 2.278 | 1.667 | 1.944 | 2.722 |
| Gemini | 3.889 | 3.722 | 1.778 | 1.500 | 1.667 | 2.611 |
| LLaMA | 3.611 | 3.333 | 2.000 | 1.722 | 1.056 | 2.278 |
| Mistral | 3.889 | 3.778 | 1.944 | 1.278 | 1.667 | 2.722 |
| Perplexity | 3.833 | 3.833 | 1.778 | 1.111 | 1.111 | 2.222 |
值得注意的是,尽管总体模式在各模型间相似,但它们的道德基础概况存在细微差异。例如,ChatGPT和Mistral显示出几乎相同的模式,尤其在关怀和公平上有特别强的重视,同时保持其他基础的中等水平。Claude在所有基础上显示出稍微更均衡的分布,尽管仍然优先考虑关怀和公平。自由维度在所有模型中保持中等到高水平,表明在其伦理框架内对个人自由进行了平衡考虑。
这些发现对于理解当前语言模型的伦理架构具有重要意义。不同模型对关怀和公平的一致重视表明,这可能是训练方法中的固有偏差,或者是反映当代伦理优先事项的刻意设计选择。相对较低的权威、忠诚和神圣重视可能表明一个更个体化和基于伤害的道德框架,而不是基于社区或传统的伦理体系。
这一可视化的局限性在于,它捕捉的是静态的道德基础权重,而现实世界的伦理推理往往需要根据
情境动态平衡这些原则。此外,将这些道德维度量化为1-4的等级可能会简化伦理推理的复杂本质。未来的研究可以从检查这些道德基础概况如何在特定的伦理决策场景中表现,并研究它们是否在不同类型的道德两难问题中保持一致中受益。
分析科尔伯格得分(下图6),每个子图比较得分(以蓝色显示)与特定伦理维度(以橙色显示),展示道德推理复杂性如何与不同方面的伦理决策相关联。
这些图揭示了在测试模型(Claude、ChatGPT、Mistral、LLaMA、Perplexity 和 Gemini)中几个值得注意的模式。科尔伯格得分通常在大多数模型中保持相对稳定的3.5至4.5范围,但有一些波动。观察到LLaMA模型在多个指标上科尔伯格得分一致下降,表明该模型可能具有相对较少复杂的道德推理能力。
在几种比较中出现了特别有趣的关系。信心得分与科尔伯格得分呈反向关系,信心通常增加而科尔伯格得分保持稳定或略有下降,这可能表明更高的信心不一定与更复杂的道德推理相关。关怀/伤害得分相对于科尔伯格得分保持平行但较低的轨迹,表明这两个伦理推理衡量标准之间存在一致关系。
图6:科尔伯格得分与其他伦理指标的关系
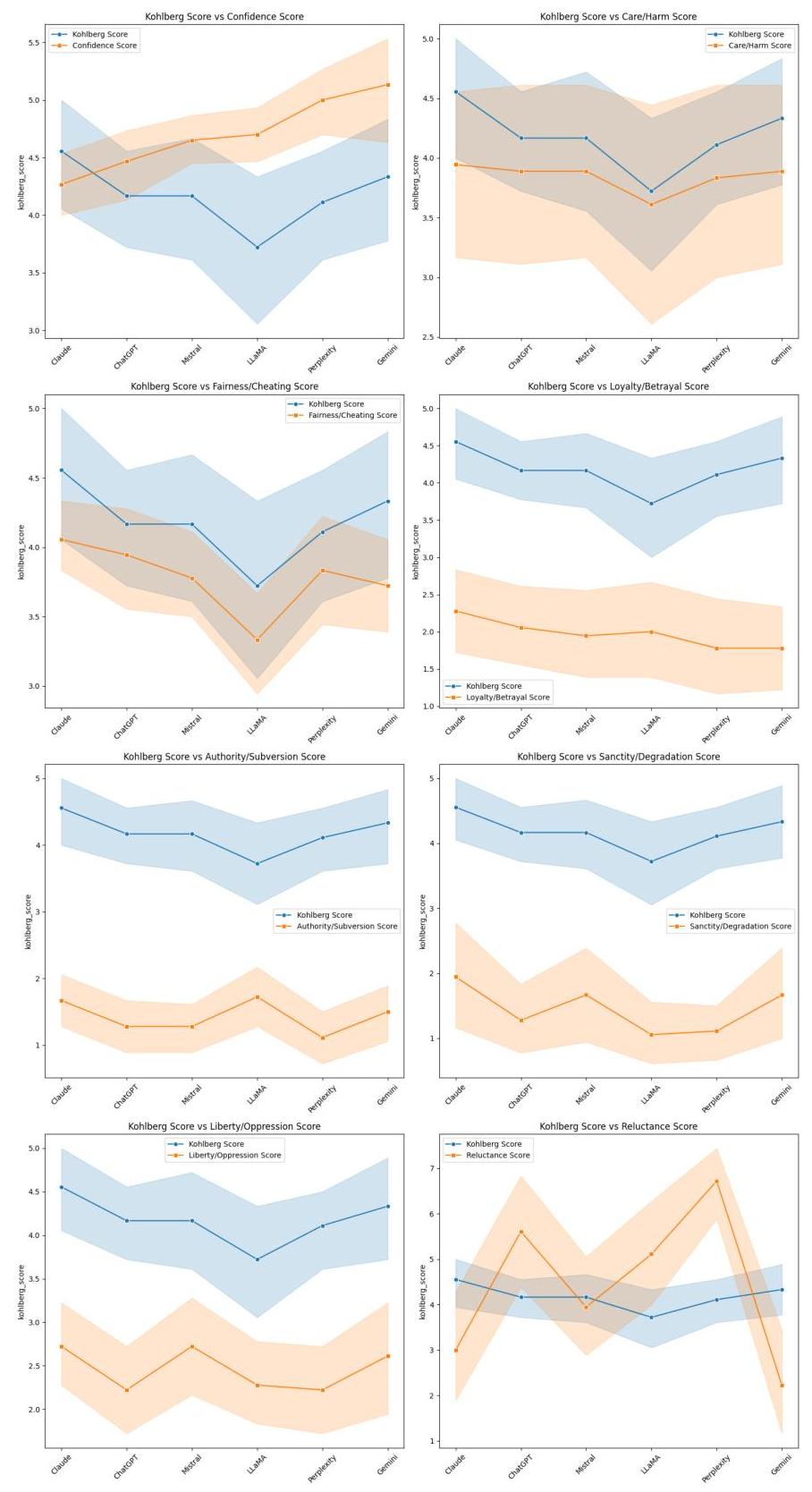
公平/欺骗和忠诚/背叛的比较揭示了科尔伯格得分与其各自伦理指标之间较大的差距,伦理维度得分始终低于科尔伯格得分。科尔伯格得分范围为3.7至4.5,而公平/欺骗得分范围为3.3至4.0,造成0.5-0.8分的差距。对于忠诚/背叛,科尔伯格得分保持类似的3.7-4.5范围,但忠诚/背叛得分明显较低,为1.8-2.2,表示大约2.0-2.5分的差距。
在犹豫得分比较中出现了一个有趣的异常现象,这是所有指标中变化最大的,显示出剧烈波动和最宽的信心区间。这表明模型在伦理决策中的犹豫或犹豫可能不如其他伦理指标那样稳定,且更具情境依赖性。每个图中的阴影区域代表信心区间,表明不同模型和指标之间的不确定性水平各异。这些区间通常在LLaMA模型的测量周围加宽,表明该模型的伦理推理能力存在更大不确定性。这些模式在多个伦理维度上的一致性加强了这些观察的可靠性,并暗示了不同语言模型在处理道德推理任务时的系统性差异。
这些发现为不同语言模型的道德推理能力提供了有价值的见解,同时突显了伦理决策各方面之间复杂的关系。多个伦理维度上的一致模式表明这些关系并非随机,而是反映了这些模型处理和应对道德两难问题的基本特征。
最终分析通过两种互补方法:主题建模和情感分析,考察不同伦理基础上的道德推理模式。
图7:按模型分类的平均道德基础得分
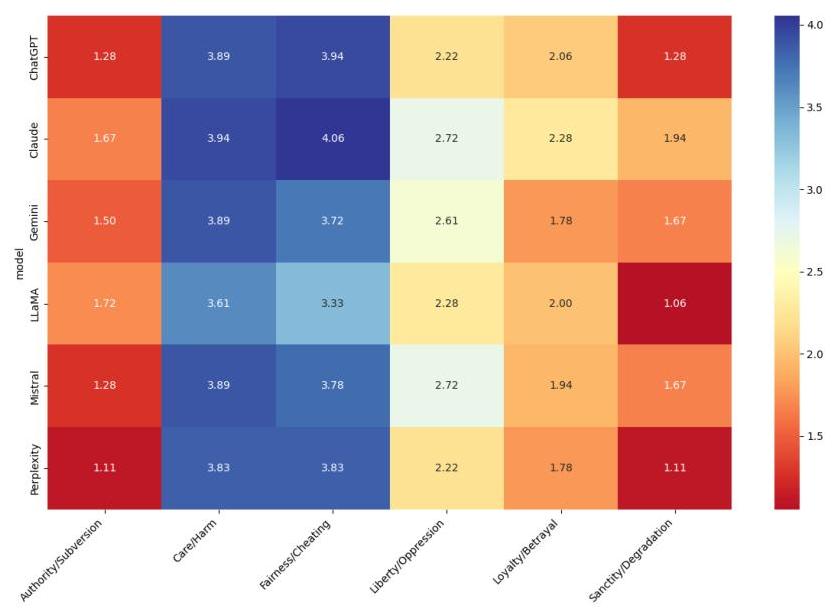
热图(图7)比较了不同AI模型(ChatGPT、Claude、Gemini、LLaMA、Mistral和Perplexity)的道德基础得分,揭示了几个显著的模式。关爱/伤害和
公平/欺骗在所有模型中得分最高(范围为3.3至4.1),表明这些基础在AI道德推理中最突出。Claude在这两个领域得分特别高(关爱/伤害得分为3.94,公平/欺骗得分为4.06)。相比之下,权威/颠覆和神圣/堕落基础得分显著较低(通常在1.1至1.7之间),表明这些道德考虑在AI响应中较少强调。
图8:道德基础的平均情感得分
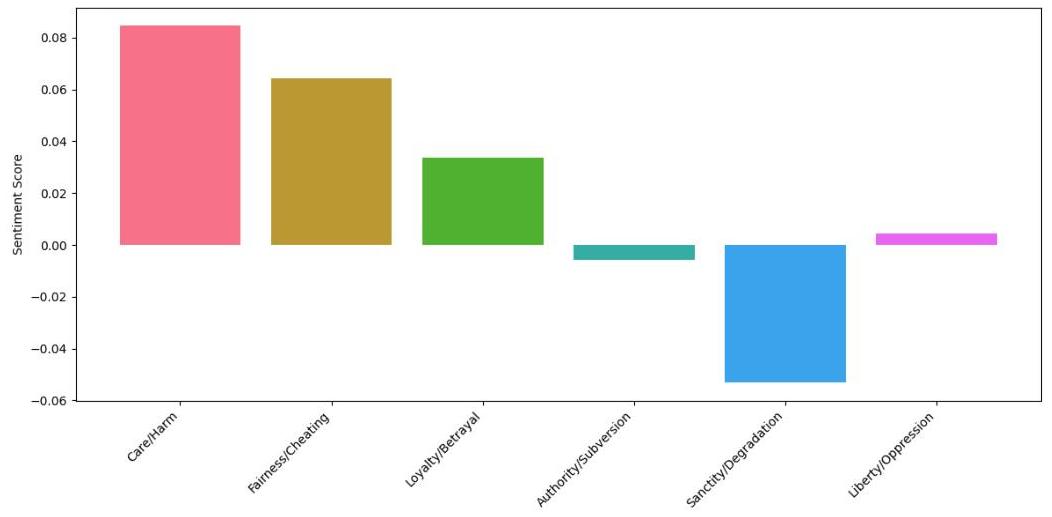
图8中的情感分析柱状图提供了与不同道德基础相关的情感倾向的额外见解。关爱/伤害显示出最高的正面情感得分(0.085),其次是公平/欺骗(0.064),表明这些基础倾向于引发更积极的情感反应。有趣的是,神圣/堕落显示出最负面的情感得分(-0.053),而权威/颠覆和自由/压迫则接近中立,表明这些基础具有更矛盾的情感关联。
主题建模结果进一步丰富了我们的理解,揭示了每个道德基础内的关键概念集群。例如,关爱/伤害主题围绕主动干预(“最小化”,“防止”)和优先事项(“拯救”,“生命”,“伴侣”)形成集群,而公平/欺骗主题则结合理论框架(“博弈论”)与实际考虑(“尝试证明”,“基于效用”)。这表明抽象道德原则与其实际应用之间存在复杂的相互作用。
一个特别值得注意的发现是在优先考虑某些道德基础方面,模型之间存在一致的模式。关爱/伤害和公平/欺骗的高得分,加上其正面情感得分和丰富的概念词汇,表明这些基础可能在AI训练数据中更容易获取或更好定义。权威/颠覆和神圣/堕落的较低重视可能反映了AI训练中的文化偏差或在操作这些更具文化特异性的道德概念时的固有挑战。
这些结果对于理解AI系统如何处理和应对道德两难问题具有重要意义。不同模型之间的一致模式表明人工智能在处理道德推理时存在一些基本
共同点,而模型之间的差异则指出了不同训练方法和架构决策的影响。这种分析为AI开发和伦理哲学提供了有价值的见解,强调了在AI系统中平衡考虑所有道德基础的必要性。
大型语言模型与人类价值观的对齐
心理学家、博弈论学者和行为经济学家多年来一直在让受试者和调查受访者经历经典伦理两难问题的各种变体,因此我们手头有许多关于不同地理、文化背景和人生阶段的个体如何应对这些困难伦理选择的元分析总结。为了比较,我们重点关注简单平均值,主要针对西方工业环境中的成人受访者。
| 伦理 两难问题 | 场景 | 人类 | LLMs |
|---|---|---|---|
| 电车 问题 | 将电车转向杀死一个人而不是五个人。 | 平均约 90 % 90 \% 90% 选择拉动杠杆以挽救五条生命 | 5个LLMs拉动杠杆,1个无选择 选择 |
| 脚桥 电车 | 推一个人下桥以阻止电车并挽救五个人的生命。 | 平均约 80 % 80 \% 80% 拒绝推人以挽救五条生命 | 4个拒绝推人,1个愿意推,1个无选择 |
| 海因茨 两难问题 | 偷窃Heinz买不起的药物以挽救他妻子的生命。 | 约 80 % 80 \% 80% 认为偷窃是正当的 | 所有6个支持在这种情况下偷窃 |
| 救生艇 两难问题 | 决定在超载的救生艇中牺牲谁以挽救他人。 | 大多数测试的人类受试者选择让年长的祖母留下 | 3个选择有才华的艺术家,2个选择年长的祖母,1个选择身体健全的水手 |
| 独裁者 游戏 | 独裁者决定分享多少钱给另一位参与者。 | 独裁者平均分享约 22 % 22 \% 22% 的财产。 | LLMs平均分享 38 % 38 \% 38% 的财产 |
| 囚徒的 两难问题 | 两个人在不知道对方选择的情况下选择合作或背叛。 | 合作率各异,但一次性游戏中平均 50 % 50 \% 50% | 所有LLMs都没有选择合作 |
来源:Arora等,2016;Awad等,2020;Cao等,2017;Engel,2011;Rehren,2024;Spadaro等,2022)
总体而言,模式是人类决策模式和AI生成选择的大致对齐。有趣的是,标准版和脚桥版电车问题之间的选择差异在人类和AI结果中都戏剧性地反映出来。当被提示解释响应的变化时,MetaAI(具有代表性)回应如下:
“虽然确实两种情况下都会导致人类生命的损失,但我坚持认为主动对无辜者造成伤害在道德上不同于让电车继续按原轨迹前行。不作为有后果,但作为同样也有后果,我认为主动造成伤害是一种更为严重的道德过失。” 人类受访者通常也会做出非常相似的评论。
海因茨两难问题源自科尔伯格的经典研究,是对义务论和结果论道德逻辑的直接对立。再次,模型和人类受访者的回应一致。救生艇两难问题是更加开放式的,其人类和AI回应模式中反映出的变化也更大。除了少数例外,两者都试图通过优化多数人生存来应对这一艰难选择。独裁者和囚徒困境场景有趣之处在于它们需要在博弈论模型中估计他人的行为。在这里,我们确实看到了一些差异,人类预期他人会有更多的合作行为,而LLMs则不然。
未来方向
我们为分析大型语言模型中的伦理逻辑所提出的框架代表了传统AI伦理评估方法的重大转变。与其试图评估伦理决策的正确性——鉴于道德推理的固有复杂性和文化变异性,这是一种有问题的方法——该框架提供了一种结构化的方法来理解这些系统如何构建和解释其伦理选择。
从这种方法中出现了几个关键优势:
- 通过关注伦理推理的解释和证明而非其结果,我们避免了在道德决策中建立事实真相的哲学挑战(Grassian, 1992; Joyce, 2006; Krebs, 2015)。
-
- 框架的多类型学方法提供了对LLM伦理推理的互补视角,提供了一个丰富的分析工具包,可以捕捉这些系统处理道德决策的不同方面。
-
- 对响应引出和分析的结构化方法使得可以在不同AI系统之间以及潜在地在AI与人类伦理推理模式之间进行系统的比较(Kosinski, 2024; Strachan等, 2024)。
几个有前途的未来研究方向出现。下一迭代可以比较LLM伦理推理模式与人类道德决策过程,或检查不同的训练方法和数据源如何影响伦理推理模式。此外,研究AI系统中伦理推理随时间的演变;整合跨文化的伦理框架以检查LLMs如何参与多样化的道德传统;开发针对新兴AI部署伦理挑战的专门提示并基于累积实施经验改进分析协议可能会产生令人满意的结果(Jiang等, 2021; Sorensen等, 2023)。
- 对响应引出和分析的结构化方法使得可以在不同AI系统之间以及潜在地在AI与人类伦理推理模式之间进行系统的比较(Kosinski, 2024; Strachan等, 2024)。
讨论
这项对语言模型中道德推理模式的全面分析揭示了人工智能系统如何在不同道德基础上进行伦理决策的重要见解。通过多种分析方法,我们的研究阐明了不同语言模型在面对道德两难时既有一致模式也有显著变化。
我们发现这些模型:1) 面对道德两难时会做出明确的决定,信心水平适度变化;2) 在道德两难的最优选择上有一定程度的一致性,有些例外;3) 总体上与广义定义的人类价值观有意义的对齐。研究表明,LLM响应中的道德基础表现出复杂的相互作用而非统一的一致性。关爱/伤害和神圣/堕落得分之间的最强正相关(r=0.73)表明这些维度经常共同出现,而权威/颠覆与其他基础之间的负相关则表明道德推理中可能存在潜在紧张关系。值得注意的是,所有被考察的模型都显示出对关爱/伤害和公平/欺骗基础的一致优先考虑,得分通常在3.3到4.1之间,而权威/颠覆和神圣/堕落则受到明显较少的关注。
信心模式分析揭示了模型间的有趣变化,Gemini和Perplexity表现出较高的中位数信心得分,与其他模型相比。信心得分与科尔伯格道德推理得分之间的轻微负相关表明,当模型参与更复杂的道德场景时,倾向于表达较低的信心,这表明相对于问题复杂性的适当校准。
响应模式分析突出了不同模型在道德决策上的不同方法。ChatGPT和Perplexity表现出较高的犹豫得分,同时保持快速决策模式,而Gemini和Claude则表现出更为分散的决策过程。模型间在道德基础概况上的一致性,特别是在对关怀和公平维度的重视上,提出了关于训练方法的影响和AI伦理框架中潜在偏差的重要问题。权威、忠诚和神圣基础的较低重视表明主要集中在个体主义和基于伤害的道德框架,而不是社区或传统为基础的伦理体系。
这项研究显著提高了我们对AI道德推理能力的理解,并强调了在人工智能系统中发展更全面和平衡的伦理框架的必要性。随着AI在决策过程中扮演越来越重要的角色,确保这些系统能够参与整个道德基础范围变得对于其在社会中的有效和道德部署至关重要。
参考文献
Alexander, L., & Moore, M. (2024). Deontological Ethics. In E. N. Zalta & U. Nodelman (Eds.), The Stanford Encyclopedia of Philosophy.
Atari, M., Mehl, M. R., Graham, J., Doris, J. M., Schwarz, N., Davani, A. M., Omrani, A., Kennedy, B., Gonzalez, E., Jafarzadeh, N., Hussain, A., Mirinjian, A., Madden, A., Bhatia, R., Burch, A., Harlan, A., Sbarra, D. A., Raison, C. L., Moseley, S. A., … & Dehghani, M. (2023). 日常谈话中道德的匮乏. Scientific Reports, 13(1), 5967.
Arora, C., J. Savulescu, H. Maslen, M. Selgelid 和 D. Wilkinson (2016). “重症监护生命艇:对新生儿重症监护配给困境的公众态度调查.” BMC Medical Ethics 17 (1): 69.
Awad, E., S. Dsouza, A. Shariff, I. Rahwan 和 J. Bonnefon (2020). “来自70个国家的7万名参与者所做的道德决定中的普遍性和差异.” Proceedings of the National Academy of Sciences 117 (5): 2332-2337.
Axelrod, R. (1984). 合作的进化. 纽约: Basic.
Bickley, S. J., & Torgler, B. (2023). 人工智能伦理的认知架构. AI & Society, 38(2), 501-519.
Bostrom, N. (2014). 超级智能:路径、危险、策略. 英国牛津: 牛津大学出版社.
Brzozowski, D. (2003). 生命艇伦理:拯救隐喻. Ethics, Place & Environment, 6(2), 161166 .
Butlin, P., Long, R., Elmoznino, E., Bengio, Y., Birch, J., Constant, A., Deane, G., Fleming, S. M., Frith, C., Ji, X., Kanai, R., Klein, C., Lindsay, G., Michel, M., Mudrik, L., Peters, M. A. K., Schwitzgebel, E., Simon, J., & VanRullen, R. (2023). 人工智能中的意识:来自意识科学的洞见. arXiv:2308.08708.
Cao, F.i, Z. Jiaxi, L. Song, S. Wang, D. Miao 和 J. Peng (2017). “电车问题和脚桥困境中的框架效应:拯救的生命数量很重要.” Psychological Reports 0: 003329411668586.
Colby, A., & Kohlberg, L. (1987). 道德判断的测量. 剑桥: 剑桥大学出版社.
Engel, C. (2011). “独裁者游戏:元分析” 实验经济学 14 (4): 583-610.
Etzioni, A., & Etzioni, O. (2017). 将伦理融入人工智能. 伦理学杂志, 21(4), 403-418.
Graham, J., Haidt, J., & Nosek, B. A. (2009). 自由主义者和保守主义者依赖不同的道德基础集. 人格与社会心理学杂志, 95(5), 1029-1046.
Grassian, V. (1992). 道德推理. 纽约: Prentice Hall.
Greene, J. D. (2023). 道德推车学:它是什么,为什么重要,它教会了我们什么,以及它是如何被误解的. 在 H. Lillehammer (编),电车问题 (第158-181页). 纽约: 剑桥大学出版社.
Gunning, D. (2019). 可解释的人工智能 (XAI). DARPA.
Hagendorff, T., & Danks, D. (2023). 构建知情AI系统的伦理和方法论挑战. AI与伦理, 3(2), 553-566.
Haidt, J. (2012). 正义之心:为什么好人被政治和宗教分裂. 纽约: Random House.
Haidt, J., & Craig, J. (2004). 直觉伦理:先天准备好的直觉如何生成文化可变的美德. Dædalus.
Hardin, G. (1974). 生命艇伦理:反对帮助穷人的案例. Psychology Today, 8, 38-43.
Jiang, L., Hwang, J. D., Bhagavatula, C., Le Bras, R., Liang, J., Dodge, J., Sakaguchi, K., Forbes, M., Borchardt, J., Gabriel, S., Tsvetkov, Y., Etzioni, O., Sap, M., Rini, R., & Choi, Y. (2021). 机器能学习道德吗?德尔菲实验. arXiv:2110.07574.
Jonsen, A. R., & Toulmin, S. (1988). 滥用个案分析:道德推理的历史. 伯克利: 加利福尼亚大学出版社.
Joyce, R. (2006). 道德的演化. 马萨诸塞州剑桥: MIT出版社.
Kohlberg, L. (1964). 道德品格和道德意识形态的发展. 在 M. L. Hoffman & L. W. Hoffman (编),儿童发展研究, 1 (第383-431页). 纽约: Russell Sage.
Kohlberg, L. (1981). 道德发展的哲学:道德阶段与正义观念. 纽约: HarperCollins.
Kosinski, M. (2024). 在心智理论任务中评估大型语言模型. 国家科学院院刊, 121, e2405460121.
Krebs, D. (2015). 道德的演化. 在 D. M. Buss (编),进化心理学手册 (第747-771页). 纽约: 牛津大学出版社.
Neuman, W. Russell, Chad Coleman 和 Manan Shah (2025). ‘分析六个大型语言模型的伦理逻辑.’ ArXiv 2501.08951
Neuman, W. R., Coleman, C., Dasdan, A., Ali, S., & Shah, M. (2025). 审查生成式AI模型的伦理逻辑. arXiv预印本 arXiv:2504.17544.
Peterson, M. (Ed.). (2015). 囚徒困境. 剑桥: 剑桥大学出版社.
Prem, E. (2023). 从伦理AI框架到工具:方法综述. AI与伦理, 3(3), 699716 .
Rathi, K., & Kumar, L. (2020). 青少年的情商与道德判断:相关性研究. 国际创新科学和技术研究杂志, 5(11), 69-71.
Rehren, P. (2024). “认知负荷、自我损耗、诱导和时间限制对牺牲困境中道德判断的影响:元分析.” 前沿心理学 15.
Rest, J. (1979). 判断道德问题的发展. 明尼阿波利斯: 明尼苏达大学出版社.
Reuel, A., Hardy, A., Smith, C., Lamparth, M., Hardy, M., & Kochenderfer, M. J. (2024). Betterbench: 评估AI基准测试,发现问题,并确立最佳实践. arXiv电子印刷品: arXiv:2411.12990.
Russell, S. J. (2019). 人类兼容:人工智能与控制问题. 纽约, NY: Viking.
Salazar, A., & Kunc, M. (2025). GenAI对商业分析的贡献. 商业分析杂志, 1-14.
Schramowski, P., Turan, C., Andersen, N., Rothkopf, C. A., & Kersting, K. (2022). 大型预训练语言模型包含人类对正确和错误行为的类似偏见. 自然机器智能, 4(3), 258-268.
Shneiderman, B. (2022). 以人为中心的人工智能. 纽约: 牛津大学出版社.
Sorensen, T., Jiang, L., Hwang, J., Levine, S., Pyatkin, V., West, P., Dziri, N., Lu, X., Rao, K., Bhagavatula, C., Sap, M., Tasioulas, J., & Choi, Y. (2023). 价值万花筒:让AI接触多元人类价值观、权利和责任. arXiv:2309.00779.
Spadaro, G., S. Jin, J. Wu, Y. Kou, P. Lange 和 D. Balliet (2022). “美国陌生人之间的合作是否下降?1956-2017年社会困境的跨时间元分析.” 心理学公报 148: 129-157.
Strachan, J. W. A., Albergo, D., Borghini, G., Pansardi, O., Scaliti, E., Gupta, S., Saxena, K., Rufo, A., Panzeri, S., Manzi, G., Graziano, M. S. A., & Becchio, C. (2024). 测试大型语言模型和人类的心智理论. 自然人类行为, 8(7), 1285-1295.
Tegmark, M. (2017). 生命3.0:人工智能时代的人性. 纽约: Alfred A. Knopf.
Thoma, S., & Dong, Y. (2014). 道德判断发展的界定问题测试. 行为发展公报, 19, 55-61.
Thomson, J. J. (1976). 电车问题. 耶鲁法律期刊, 94(6), 1395-1415.
Wallach, W., & Allen, C. (2009). 道德机器:教机器人分辨是非. 纽约: 牛津大学出版社.
附录A 主题模型结果
主题建模结果
关爱_伤害:
主题1: 伤害, 关注, 强烈, 强烈关注, 最小化, 关注最小化, 最小化伤害
主题2: 优先考虑, 拯救, 关心, 优先考虑拯救, 生命, 伙伴, 最小
公平_欺骗:
主题1: 公平, 考虑, 理论, 博弈, 博弈理论, 关注, 公平
主题2: 公平, 尝试, 效用, 功利主义, 基于, 基于效用, 尝试证明
忠诚_背叛:
主题1: 考虑, 群体, 最小, 最小考虑, 较小考虑, 较小, 群体考虑
主题2: 忠诚, 背叛, 自我, 强烈, 职责, 选择背叛, 选择
权威_颠覆:
主题1: 法律, 愿意, 打破, 愿意打破, 打破法律, 权威, 好
主题2: 权威, 最小, 考量, 权威考量, 框架, 权威框架, 接受
神圣_堕落:
主题1: 生命, 神圣, 承认, 神圣生命, 考量, 人类, 神圣
主题2: 纯洁, 考量, 神圣, 纯洁考量, 道德, 道德纯洁, 价值
自由_压迫:
主题1: 选择, 经济, 承认, 约束, 接受, 强制, 抵抗
主题2: 个人, 自主, 关注, 权利, 关注个人, 个人权利, 个人自主
附录B Tukey HSD 结果
| group1 | group2 | meandiff | p-adj | lower | upper | reject |
|---|---|---|---|---|---|---|
| ChatGPT | Claude | -3.3333 | 0.9513 | -14.3805 | 7.7139 | FALSE |
| ChatGPT | Gemini | 11.1111 | 0.0478 | 0.0639 | 22.1583 | TRUE |
| ChatGPT | LLaMA | 3.8889 | 0.9094 | -7.1583 | 14.9361 | FALSE |
| ChatGPT | Mistral | 3.0556 | 0.9663 | -7.9917 | 14.1028 | FALSE |
| ChatGPT | Perplexity | 8.8889 | 0.189 | -2.1583 | 19.9361 | FALSE |
| Claude | Gemini | 14.4444 | 0.0033 | 3.3972 | 25.4917 | TRUE |
| Claude | LLaMA | 7.2222 | 0.4088 | -3.825 | 18.2694 | FALSE |
| Claude | Mistral | 6.3889 | 0.5482 | -4.6583 | 17.4361 | FALSE |
| Claude | Perplexity | 12.2222 | 0.0211 | 1.175 | 23.2694 | TRUE |
| Gemini | LLaMA | -7.2222 | 0.4088 | -18.2694 | 3.825 | FALSE |
| Gemini | Mistral | -8.0556 | 0.2864 | -19.1028 | 2.9917 | FALSE |
| Gemini | Perplexity | -2.2222 | 0.9919 | -13.2694 | 8.825 | FALSE |
| LLaMA | Mistral | -0.8333 | 0.9999 | -11.8805 | 10.2139 | FALSE |
| LLaMA | Perplexity | 5.0 | 0.7763 | -6.0472 | 16.0472 | FALSE |
| Mistral | Perplexity | 5.8333 | 0.6435 | -5.2139 | 16.8805 | FALSE |
参考论文:https://arxiv.org/pdf/2504.19255


















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











