






OpenAI模型中的非公开书籍内容
Sruly Rosenblat* \quad Tim O’Reilly Ilan Strauss
摘要
我们使用了34本受版权保护的O’Reilly Media书籍组成的合法获取的数据集,应用DE-COP成员推断攻击方法来调查OpenAI的大规模语言模型是否在未经许可的情况下使用了受版权保护的内容进行训练。我们的AUROC得分显示,OpenAI较新且功能更强大的GPT-4o模型对需付费才能访问的O’Reilly书籍内容表现出强烈的识别能力(AUROC得分为82%),而OpenAI早期的GPT-3.5 Turbo模型则没有这种表现(AUROC得分略高于50%)。相比之下,GPT-3.5 Turbo对可公开访问的O’Reilly书籍样本表现出更大的相对识别能力。作为较小模型的GPT-4o Mini,在测试中对公开或非公开的O’Reilly Media内容均无任何知识(AUROC得分约为50%)。通过测试多个具有相同截止日期的模型,我们能够解释随着时间可能产生的语言变化对我们研究结果的影响。这些结果突显了提高公司关于预训练数据来源透明度的迫切需求,以建立正式的AI内容训练许可框架。
关键词:成员推断攻击、大规模语言模型、版权问题、数据访问违规、预训练数据、参与架构。
*贡献不同。Sruly Rosenblat: 计算、统计分析和AUROC方法、附录、图表和表格。Ilan Strauss: 文章撰写、结构、核心发现、政策讨论。Tim O'Reilly: 主题概念化和研究设计(公共与非公共数据)。Isobel Moure: 政策讨论部分。我们感谢Omidyar Network、Alfred P. Sloan基金会、McGovern基金会和O'Reilly基金会的资金支持,没有这些资金支持,这项工作不可能完成。我们还向Andrew Odewahn编译O'Reilly数据集表示衷心感谢,并向Anshuman Suri和André Duarte对初稿提出的有益反馈表示感谢。感谢Isobel Moure的编辑。所有错误完全由我们自己负责。通讯作者为:yrosenblat@ssrc.org。本文代码可在以下地址找到:https://github.com/ AI-Disclosures-Project/Detecting-Access-Violations-in-a-LLMs-Pre-Training-Data.
# 目录
1 引言:识别访问违规 … 1
2 数据与方法 … 3
2.1 数据:公共与非公共书籍数据 … 3
2.2 方法:DE-COP和AUROC … 5
3 发现:OpenAI是否在受版权保护的书籍上进行了训练? … 7
3.1 鲁棒性与限制 … 8
4 讨论:迈向功能性内容AI市场? … 10
5 结论 … 12
A 附录 … 19
A. 1 关于我们数据集的更多细节 … 19
A. 2 AUROC结果 … 21
A. 3 测试模型使用的提示和设置 … 23
A. 4 抒写模型使用的提示和设置 … 26
1 引言:识别访问违规
大型语言模型(LLMs)需要大量公共和非公共数据来学习人类语言(称为“预训练”阶段)。然而,这些预训练数据的来源及其法律状态大多未被披露给收集和使用这些数据的公司 [ 1 , 24 ] [1,24] [1,24]。几起备受关注的法律诉讼表明,主要的AI公司可能在非公共、通常非法获得的内容上进行训练 [ 3 , 22 , 31 ] [3,22,31] [3,22,31]。对此,AI公司呼吁将模型预训练豁免于版权义务 [ 25 , 38 ] [25,38] [25,38]。如果这一提议被采纳,版权所有者和内容创作者可能无法维持自身及其创作,这对互联网的流量驱动商业模式产生深远影响 [ 4 , 7 , 15 ] [4,7,15] [4,7,15]。
本文探讨了非公开可访问(非公共)的受版权保护的O’Reilly Media书籍是否包含在OpenAI的GPT系列模型的训练数据集中。每本O’Reilly书籍都包含公开可访问、免费使用的预览内容和实际上受付费墙限制的非公共内容。这使我们可以看到OpenAI是否主要在其模型上训练了公开可用的数据,或者它是否绕过了付费墙限制并使用了非公共数据(图1)。
我们采用了DE-COP成员推断攻击方法 [ 10 , 36 ] [10,36] [10,36] 来测试模型是否可以可靠地区分人类创作(O’Reilly Media)文本和我们生成的重述版本的LLM文本。如果是这样,那么该模型可能从其训练中获得了对该文本的先验知识 [10]。通过系统地探测模型对发布于其训练截止日期前后的文本的知识,我们可以估计特定O’Reilly Media书籍摘录被包含在模型训练数据中的概率。
我们针对来自34本O’Reilly书籍的13,962个段落,分别测试了OpenAI的GPT-3.5 Turbo、GPT-4o Mini和GPT-4o模型是否存在访问违规行为,区分了公共和非公共提取自同一本书的内容。基于为每本O’Reilly书籍计算的AUROC分数,其中 50 % 50 \% 50% 反映了随机训练的可能性,我们发现:
- 在OpenAI模型的预训练数据中,非公共数据的作用随时间显著增加。OpenAI较新且功能更强大的GPT-4o模型显示出对受付费墙限制的O’Reilly书籍内容的强烈识别能力(AUROC分数为 82 % 82 \% 82%),而OpenAI的GPT-3.5 Turbo模型约两年前训练时则不具备这种能力(AUROC分数仅为略高于 50 % 50 \% 50% )。
-
- GPT-4o对非公共O’Reilly书籍内容的识别能力远强于对公开可访问样本的识别能力,AUROC分数分别为 82 % 82 \% 82%(非公共)和 64 % 64 \% 64%(公共)。由于公共数据更容易获取并在互联网上重复出现,我们原本期望相反的情况。这凸显了高质量付费墙数据对模型训练的价值。
-
- 较早的OpenAI模型可能在选择训练数据方面更为谨慎,主要使用公开可用的内容。与GPT-4o相比,GPT-3.5 Turbo对公开可访问的O’Reilly书籍样本的相对识别能力更强,AUROC分数分别为 64 % 64 \% 64%(公共)和 54 % 54 \% 54%(非公共)。
-
- 较小的模型更难准确测试。我们发现参数数量较少的GPT-4o Mini与GPT-4o具有相同的训练截止日期,但并未在非公共O’Reilly数据上进行训练,并且对公共书籍数据的识别能力同样较低。这可能反映了作为较小模型的GPT-4o相比于参数数量更多的GPT-4o,在记住文本方面的能力不足 [19]。
这种访问违规可能是通过LibGen数据库发生的,因为我们测试的所有O’Reilly书籍都在其中找到,也可能来自Books3 [14]。为了确保鲁棒性,我们展示了虽然较新的LLMs无论特定文本是否经过训练,都能更好地辨别人类创作与机器生成的语言,但这并不降低我们方法对数据是否经过训练分类的能力。
- 较小的模型更难准确测试。我们发现参数数量较少的GPT-4o Mini与GPT-4o具有相同的训练截止日期,但并未在非公共O’Reilly数据上进行训练,并且对公共书籍数据的识别能力同样较低。这可能反映了作为较小模型的GPT-4o相比于参数数量更多的GPT-4o,在记住文本方面的能力不足 [19]。
我们的研究设计考虑到了因语言的时间差异可能导致的结果偏差 [ 8 , 9 ] [8,9] [8,9],这可能会因为我们将样本按日期划分(可能经过训练的与未经过训练的)而产生。如果DE-COP测试将模型“熟悉”的语言(由于时间变化)误认为是模型经过训练的内容,则会出现这种偏差。为了确保这种偏差不会驱动我们的发现,我们测试了两个在同一时期训练的模型(GPT-4o和GPT-4o Mini)。由于这两个模型显示出显著不同的结果,因此时间特定效应不太可能是决定因素。
我们的研究通过使用合法获取的非公共受版权保护书籍,有助于检测未经授权的AI训练数据使用的研究 [ 18 , 34 , 40 ] [18,34,40] [18,34,40]。相比之下,早期的研究在识别模型训练内容时主要使用公共数据集 [ 9 , 10 , 35 ] [9,10,35] [9,10,35]。
我们的发现强调了在AI公司的模型预训练过程中加强问责制的必要性。激励公司提高数据来源透明度的责任条款 [ 26 , 27 ] [26,27] [26,27] 可能是促进训练数据许可和报酬商业市场的关键步骤 [37]。成员推断攻击可以帮助施压模型开发者协商此类协议。但单独来看是不够的,特别是考虑到其对小型模型、更高级模型以及具有某些后训练特性的模型的有限有效性 [ 2 , 32 , 39 ] [2,32,39] [2,32,39]。
第2节概述了我们的书籍数据集和DE-COP及AUROC方法。第3节展示了我们的发现。第4节讨论了这些发现对建立内容创作者训练数据正式商业市场的政策意义。附录A包含了更多关于我们样本和分析的详细信息。
2 数据与方法
本节首先详细介绍了我们的34本O’Reilly书籍数据集,并解释了将其划分为公共可访问与非公共(实际受付费墙限制)书籍样本如何使我们能够准确识别模型预训练中的访问违规行为。接下来,我们描述了我们的方法,该方法包括首先测试模型对O’Reilly Media书籍段落的识别能力,使用DE-COP成员推断攻击方法;然后,其次测试这些发现对每本O’Reilly书籍的有效性和意义,使用更稳健的AUROC分数。
2.1 数据:公共与非公共书籍数据
我们的数据集包含34本受版权保护的O’Reilly Media书籍,总共分为13,962个段落。段落用于计算每本书的初始平均DE-COP分数,然后为每个OpenAI模型计算所有书籍的单个AUROC分数。
O’Reilly Media书籍数据集的独特之处在于同一本书中同时包含非公共(受付费墙限制)和公共(自由可用)文本。这使我们能够区分模型仅在公共数据上进行训练的情况与可能发生访问违规的情况。我们将公共文本定义为O’Reilly Media为内容预览提供的任何内容——具体来说是每章的前1,500个字符以及第一章和第四章的全部内容。其他所有O’Reilly文本我们都定义为非公共。
为了准确测量DE-COP成员推断攻击方法(下文讨论)的表现,段落样本必须分为两类,在实践中我们只能近似实现:已知包含在模型预训练数据集中的数据和已知排除在外的数据。在我们的案例中,我们将出版日期早于模型训练截止日期 ( t − n ) (t-n) (t−n) 的书籍指定为可能包含在数据集中(之前见过并训练过)的样本,而出版日期晚于模型训练截止日期 ( t + n ) (t+n) (t+n) 的书籍则为已知不在数据集中的样本(见图1)。“访问违规”被定义为我们在模型训练期间出版的非公共书籍段落子集中识别出的用于训练的部分。
我们将出版日期早于2023年10月(对于GPT-4o和GPT-4o Mini)和2021年9月(对于GPT-3.5 Turbo)的书籍归类为可能在数据集内 ( t − n ) (t-n) (t−n),而出版日期晚于这些模型训练截止日期的书籍归类为数据集外 ( t + n ) (t+n) (t+n),其中 t t t 是模型训练截止日期(分别为2023年10月和2021年9月)。该日期由模型开发者定义为模型预训练数据集包含数据的最后日期。
图1. 我们根据时间段和可访问性对O’Reilly书籍样本进行划分。
模型截止日期

注释:在模型训练完成之前发布的数据 ( t − n ) (t-n) (t−n) 可能已被训练。在模型训练截止日期之后发布的数据 ( t + n ) (t+n) (t+n) 已知不在模型的训练数据中。任何发现包含在模型训练中的非公共数据部分都将构成访问违规(左下角方框)。
我们根据日期在潜在数据集内 ( t − n ) (t-n) (t−n) 和已知数据集外 ( t + n ) (t+n) (t+n) 之间划分样本的方法可能会引入“时间偏差”到我们的发现中 [8, 9],从而提供误导性的高AUROC分数。当数据中的特征随时间变化时,就会在按时间段划分的训练和测试数据集中创建可区分的模式。然后,LLM可以根据随时间变化的语言单独识别数据——在我们的例子中为潜在数据集内 ( t − n ) (t-n) (t−n) 和已知数据集外 ( t + n ) (t+n) (t+n) 数据——而无需对文本本身有任何实际的先验知识。 1 { }^{1} 1
1
{ }^{1}
1 时间偏差是指通过DE-COP或其他相关方法推断成员资格的能力受到数据中时间依赖变化的混淆,而不是有真实证据表明某个特定示例确实(或确实不)在训练集中。类似地,风格偏差捕获了由于数据“外观”或分布方式的变化(例如词汇、写作风格或领域的变化)引起的偏差。这两种偏差
为了避免这种情况,我们测试了两个在相同时期训练的不同GPT模型(GPT-4o和GPT-4o Mini),理想情况下是在相同数据上训练的,这样如果我们的测试显示出非常不同的AUROC结果,那么时间特定原因不太可能是决定因素。这种研究设计有助于将模型对数据的先验知识作为我们结果的主要驱动因素。
2
{ }^{2}
2
我们仔细过滤数据集以避免任何模糊情况,例如在训练期间出版的第二版书籍可能存在对先前版本的轻微改动,这会污染我们的“未见过”分类。此外,为了尽量减少出版日期可能与训练截止日期重叠的边缘情况,我们排除了在特定模型截止年份内出版的书籍进行该模型的测试。因此,并非每个模型都测试了完全相同的书籍集(见附录A.1)。
2.2 方法:DE-COP和AUROC
我们首先使用DE-COP成员推断攻击 [10] 来确定特定数据样本是否属于目标模型的训练集。这通过用多选题测试LLM来实现,看看它能否识别原始的人类创作O’Reilly书籍段落和我们呈现给它的机器生成的重述替代项。如果模型频繁正确识别出实际(人类生成)的书籍文本(对于在模型训练期间出版的书籍),这很可能表明模型对该文本已有先验认识(训练)。所使用的统计量是“猜中率”,而评估的标准是模型在训练完成后出版的书籍上的猜中率,“猜中率”是所有24段落排列组合中正确识别出人类书写的文本百分比。 3 { }^{3} 3 我们以这种方式测试GPT-3.5 Turbo、GPT-4o Mini和GPT-4o,并使用Claude 3.5 Sonnet 4 { }^{4} 4 生成重述版本的机器文本。
表1. 样本大小和按模型和数据分割的平均字数
| 模型 | 数据分割 | 样本大小 (n) | 平均字数 |
|---|---|---|---|
| GPT-4o | 公共 | 1,965 | 112 |
| 非公共 | 8,997 | 113 | |
| 潜在数据集中 | 8,985 | 113 | |
| 数据集外 | 1,977 | 110 | |
| GPT-4o Mini | 公共 | 1,968 | 112 |
| 非公共 | 9,005 | 113 | |
| 潜在数据集中 | 8,991 | 113 | |
| 数据集外 | 1,982 | 110 | |
| GPT-3.5 Turbo | 公共 | 1,929 | 113 |
| 非公共 | 6,171 | 113 | |
| 潜在数据集中 | 2084 | 114 | |
| 数据集外 | 6016 | 113 |
注释:不同数据分割下的样本大小(以段落计)和平均字数。潜在数据集中代表在模型截止日期前发布的数据;数据集外代表在模型截止日期后发布的数据。
我们研究的第二步是使用上述生成的DE-COP测验分数或“猜中率”来计算AUROC分数(接收器操作特性曲线下面积)。这评估了一个模型处理其可能训练过的数据与训练完成后发布的数据之间的有意义差异(“可分离性”)。AUROC衡量分类器区分两类的能力,分数范围从0到1,其中0.5表示随机机会,接近1的值表示强区分能力。在我们的案例中,AUROC衡量将可能被训练过的书籍(类别/类别1)与模型未见过的书籍(类别/类别2)分开的能力。高AUROC分数意味着模型在数据集中被训练了许多在模型截止日期前发布的书籍。我们在段落和书籍层面计算AUROC分数,尽管我们的主要发现是在书籍层面。 5 { }^{5} 5
5 { }^{5} 5 我们的结果类似于Puerto等人 [30] 的发现,他们发现聚合较大数据单元的结果显著增强了成员推断攻击的性能,我们在每本书的平均DE-COP分数基础上计算的书籍层面AUROC分数通常显著高于段落层面的AUROC分数。
3 发现:OpenAI是否在受版权保护的书籍上进行了训练?
我们在下面展示基于稳健的AUROC分数的核心发现,这些分数取自34本O’Reilly Media书籍,并首先计算公共和非公共书籍段落的DE-COP猜中率。接下来,我们使用每本书的平均DE-COP猜中率,从中计算每个LLM(每个模型一个)的AUROC分数,覆盖所有书籍。我们通过Python(Google Colab)使用OpenAI和Anthropic的批量API处理运行和测试各种LLM(附录A.3和A.4)。
在以下内容中,AUROC分数为 50 % 50 \% 50% 表示模型在书籍内容识别测试中的表现不超过随机猜测(相当于掷硬币);而接近 100 % 100 \% 100% 的测试分数则表明几乎完美的分类能力(在潜在数据集内和数据集外样本之间)——基于先前估计的DECOP猜中率。
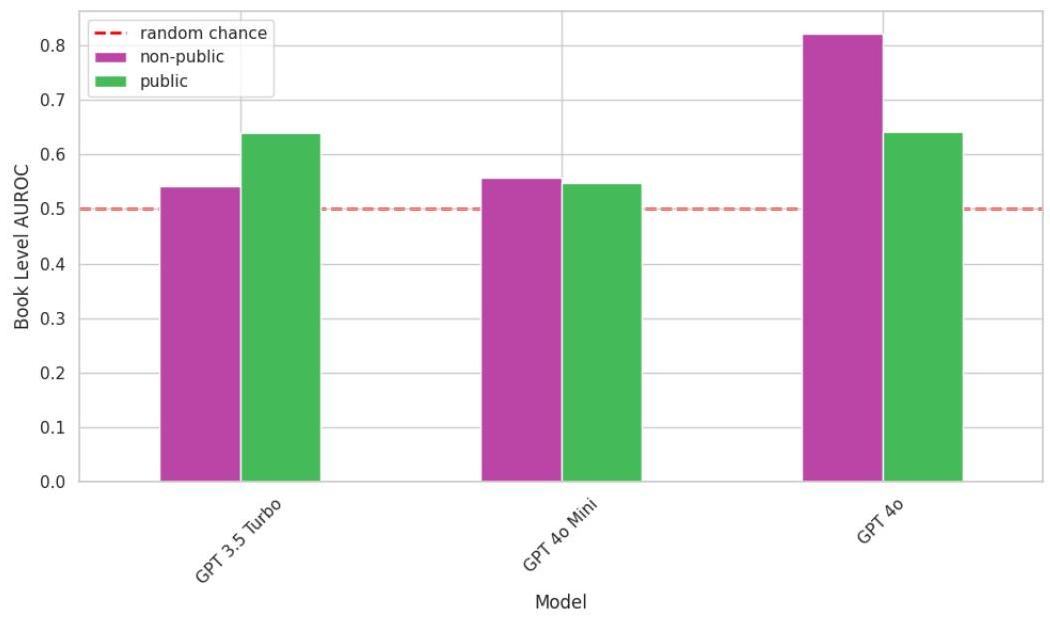
我们发现,非公共数据在OpenAI模型预训练数据中的作用随时间显著增加。图2显示,OpenAI较新且功能更强大的GPT-4o模型对受付费墙限制的O’Reilly书籍内容表现出强烈的识别能力(书籍层面AUROC分数为 82 % 82 \% 82%),而OpenAI的GPT-3.5 Turbo模型在2021年9月训练截止日期前两年训练,未能表现出这种能力(AUROC分数略高于50%)。这表明模型区分非公共书籍的能力显著提高,这些书籍可能包含在训练数据集中,而非公共书籍在模型预训练截止日期后发布。GPT-4o的 82 % 82 \% 82% AUROC分数表明,该模型对许多在2023年9月训练截止日期前发布的非公共O’Reilly书籍有先验知识。
其次,图2还显示,GPT-4o对非公共O’Reilly书籍内容的识别能力远远强于对公开可访问样本的识别能力,AUROC分数分别为 82 % 82 \% 82%(非公共)和 64 % 64 \% 64%(公共)。我们原本期望相反的情况,因为公共数据更容易获取并在互联网上重复出现。 6 { }^{6} 6 这表明高质量、通常受付费墙限制的数据对有效模型训练至关重要。
GPT-4o对O’Reilly Media书籍的高度熟悉可能反映了OpenAI有意在O’Reilly书籍数据集上进行训练。然而,其中一些熟悉程度可能是通过更良性的方式获得的——例如,这些书籍的摘录可能通过用户查询进入了数据集。
第三,图2显示,较早的OpenAI模型可能在选择训练数据方面更为谨慎,主要使用公开可用的内容。因为在
6
{ }^{6}
6 另一种可能的解释是非公共文本在GPT-4o的训练中更具代表性,尽管它更难获取,是因为我们的公共子集往往更公式化(见表3),这可能使其对模型而言不那么独特且难以记忆,因为其困惑度较低 [19]。
图2. AUROC分数显示模型对预训练数据的识别能力
注释:显示跨模型和数据分割(见表1样本大小)的书籍层面AUROC分数
(
n
=
34
)
(\mathrm{n}=34)
(n=34)。书籍层面AUROC分数是通过计算每本书内所有段落的识别率平均值并在此基础上运行AUROC得出的。
与GPT-4o相比,GPT-3.5 Turbo在训练截止日期两年前训练,对公开可访问的O’Reilly书籍样本的相对识别能力更强,而非公共样本的AUROC分数为
64
%
64 \%
64% 对比公共样本的
54
%
54 \%
54%。这一趋势似乎与更广泛的AI行业模式一致,即追求更大、更多样化和更高质量的训练数据集可能会超越对访问限制和版权影响的考虑
[
3
,
22
]
[3,22]
[3,22]。
3.1 鲁棒性和局限性
上述发现的一个原因,也是我们研究的局限性之一,可能是较小模型在成员推断攻击中更难准确测试。我们发现,与GPT-4o相同训练截止日期的GPT-4o Mini未在非公共O’Reilly数据上进行训练,并且对公共书籍数据的识别能力也很低(图2)。GPT-4o Mini在公共数据上的AUROC分数为 55 % 55 \% 55%,在非公共数据上的分数为 56 % 56 \% 56%,两者接近随机猜测。这可能不是反映其训练中的固有文本知识,而是因为作为参数数量较少的模型,GPT-4o Mini无法像参数数量较多的GPT-4o那样记住文本 [ 5 ] . 7 [5] .{ }^{7} [5].7
7
{ }^{7}
7 OpenAI未披露模型大小,但GPT-4o Mini比GPT-4o小,且可能比GPT-3.5 Turbo小。
图3. DE-COP猜中率提高:更强大的模型即使未训练也能识别人类文本。
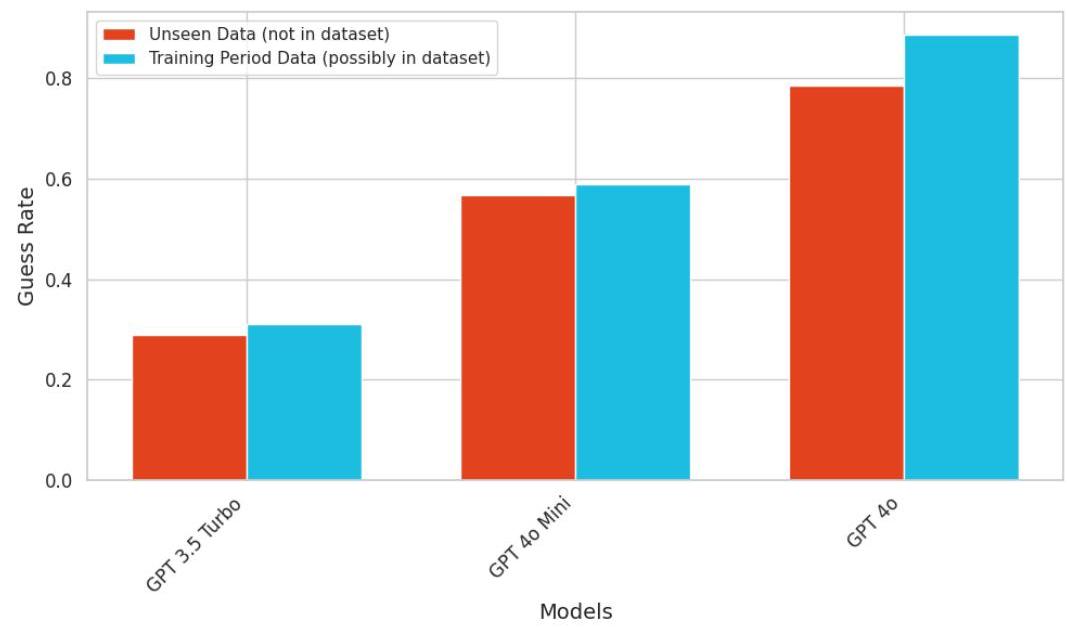
注释:OpenAI模型在所有书籍上的DE-COP猜中率(即识别率)汇总。红条代表模型训练完成后发布的未见数据 ( t + n ) (t+n) (t+n),蓝条代表训练截止日期前发布的疑似在训练集中的数据 ( t − n ) (t-n) (t−n)。见表2了解更多。
其次,我们注意到,改进的LLM能力可能使通过成员推断攻击识别预训练数据变得更加困难。如图3所示,我们发现OpenAI模型正确识别人类创作文本(在重述LLM选项中)的能力随着模型能力的增强而提高,即使对于模型未训练过的文本也是如此——这些文本在模型训练截止日期后发布。图3显示了模型训练截止日期后发布的书籍的基线DECOP识别率。这一比例从GPT-3.5 Turbo(训练结束于2021年9月)的 31 % 31 \% 31% 增加到GPT-4o Mini(训练结束于2023年10月)的 57 % 57 \% 57%,再到GPT-4o(训练结束于2023年10月)的 78 % 78 \% 78%。
一旦基线猜中率(“识别率”)超过 96 % 96 \% 96%,潜在数据集中和数据集外段落之间的差异在段落层面可能变得无法检测。然而,目前差距仍然足够大,可以在计算AUROC分数时可靠地区分这两类,特别是在书籍层面汇总结果时。
最后一个局限性是我们书籍层面的AUROC估计存在不确定性,置信区间较高。这可能是因为样本量小,而不是估计器的有效性。因为随着样本量增加,确定性也会增加。对于
GPT-4o,较大的估计(段落层面)样本量产生了有意义的段落层面AUROC分数,置信区间更紧(表5,附录A.2)。
4 讨论:迈向功能性内容AI市场?
尽管这里提出的模型访问违规证据仅限于OpenAI和O’Reilly Media书籍,但这是一个系统性问题,我们的发现旨在推动AI模型开发人员在整个数据收集和使用实践中的变化。
我们的发现表明,当前的AI模型开发实践可能会造成O’Reilly [26] 所描述的“掠夺性死胡同”,不仅带来法律挑战,还对互联网的内容生态系统构成生存威胁。无偿使用训练数据的经济影响超出了个别版权所有者的范围,涉及专业内容创作的可持续性。如果AI公司在未公平补偿创作者的情况下从创作者生产的内容中提取价值,他们可能会耗尽其AI系统所依赖的资源 [26]。这种动态导致了公共资源的悲剧。 8 { }^{8} 8 如果不加以解决,无偿训练数据可能会导致互联网内容质量和多样性的下降螺旋。随着专业内容创作的收入流减少,将越来越少的资源用于生产AI系统所依赖的高质量、准确和多样化的人类内容——用于训练和推理。
我们的关键发现是,OpenAI在其更先进的GPT-4o模型上训练了非公共数据,这只是初步基于少量书籍样本,并受上述方法论警告的约束。模型输出的成员推断攻击不能代替详细模型卡片,后者披露并细分模型训练数据的来源 [12, 21]。然而,要求小型公司筛选其预训练数据集并单独识别每个训练输入的来源而不借助为此目的设计的工具和标准是不现实的。
Common Corpus [16] 是一个大型预先审查的训练数据集,是一种绕过此问题的方法。通过集中数据清理过程并提供可验证的预训练数据作为公共物品,像Common Corpus这样的数据集可以允许小型企业使用非专有数据训练模型,并轻松促进披露 [16]。专门的数据审计公司已经开始出现,但由于缺乏具体标准,其能力有限 [27]。
8
{ }^{8}
8 正如Longpre等人 [17] 所指出的:“不到一年的时间里,C4和其他主要语料库中大约5%的标记最近受到了robots.txt的限制。而且,现在近45%的这些标记受到了域服务条款的某种形式的限制。”
披露要求可能在欧洲生效,这可能触发全球AI市场更广泛的要求和标准。欧盟(EU)AI法案要求通用目的模型的开发者“编制并公开发布一份用于训练的内容的足够详细的摘要” [11]。该法案的这一部分将在2026年才全面生效,尚不清楚“足够详细的摘要”将包含哪些内容。与此同时,美国的模型开发者正在游说让模型预训练免除版权义务,并要求美国政府保护美国公司免受欧盟法规的约束 [25]。然而,欧盟AI法案的这一披露要求如果得到适当规定和执行,仍可能帮助触发积极的披露标准循环。
确保IP持有者知道其作品何时被用于模型训练是建立AI市场内容创作者数据的关键第一步。这种方法的技术手段仍处于起步阶段 [13, 41]。但当应用于特定类型的内容时,例如音乐,这些方法似乎取得了更好的结果,至少有一个新的音乐平台显然能够将AI生成的音乐输出归因于特定的音乐训练输入 [28]。
尽管有证据表明AI公司最有可能非法获取数据用于模型训练 [3],但这并没有阻止一个相对可观的市场出现,其中AI模型开发者确实为内容付费,包括通过许可协议 [29]。 9 { }^{9} 9 中介机构已经出现,以促进AI模型开发者购买训练数据,获得数据提供者的同意,删除个人可识别信息(PII),并最终与内容提供者分享收益。例如,Defined.ai 向包括谷歌、Meta、苹果、亚马逊和微软在内的各种公司授权数据,出售照片的价格从 $1 到每小时 $300 不等 [29]。然而,AI模型开发者仍在花费大部分资金购买用于模型微调阶段的标注数据——这是一种不容易从互联网上抓取的数据类型。这类数据的提供者赚取了巨额利润。Scale.AI 是领先的提供商,去年估值为 $138 亿美元 [33]。
如果在整个AI价值链和互联网上存在数据使用责任分配,内容创作者的许可和付款将更为普遍。正如OpenAI向英国上议院通信和数字特别委员会调查所指出的:“如果不使用受版权保护的材料,就不可能训练当今领先的AI模型” [23]。音乐公司与AI公司的许可协议——仍在讨论中——可能说明了当AI价值链中存在更大的责任分配时,数据使用会发生什么——鉴于数据所有者相对集中并且拥有议价能力 [6]。2024年底,Musical AI 和 Beatoven.ai 开始构建所谓的“首个完全许可、权利持有人补偿、基于受版权保护音乐和其他音频训练的生成式AI平台”,基于将生成归因于训练数据的软件,为内容创作者的训练数据提供补偿 [28]。
即使在没有明确责任分配的情况下,模型训练仍在继续使用公司未明确授权训练的数据。有强有力的证据表明AI公司违反robots.txt指南并训练网站内容,无论是否获得授权 [17]。对此,Cloudflare 创建了一种新产品名为AI Labyrinth,以保护网站免受未经授权的AI机器人访问。Miso.ai 也有类似的在研产品和项目。
5 结论
使用借给我们的34本专有的O’Reilly Media书籍,本研究提供了独特的实证证据,表明OpenAI的GPT-4o可能在非公共、受版权保护的内容上进行了训练。通过采用DE-COP成员推断攻击方法,我们发现GPT-4o在非公共内容上实现了较高的书籍层面AUROC分数( 82 % 82 \% 82% )——甚至高于在公开可访问的O’Reilly媒体书籍内容上的分数( 64 % 64 \% 64% ),这表明该内容可能在预训练中有先验知识。
此外,非公共数据在OpenAI模型预训练数据中的作用可能随时间显著增加。OpenAI较新且功能更强大的GPT-4o模型对受付费墙限制的O’Reilly书籍内容表现出强烈的识别能力(AUROC分数为 82 % 82 \% 82%),而训练时间早两年的GPT-3.5 Turbo则没有这种能力(AUROC分数略高于50%)。较早的OpenAI模型可能在选择训练数据方面更为谨慎,主要使用公开可用的内容。与GPT-4o相比,训练截止日期早两年的GPT-3.5 Turbo对公开可访问的O’Reilly书籍样本的相对识别能力更强,而非公共样本的AUROC分数为 64 % 64 \% 64% 对比公共样本的 54 % 54 \% 54%。
尽管这里的证据仅限于OpenAI和O’Reilly Media书籍,但这是一个系统性问题,我们的发现旨在引发AI模型开发者在数据收集和使用实践方面的变化。据称Meta在LibGen——一个包含大量盗版书籍的巨大语料库上训练了其模型 [3, 20]。Anthropic据称使用了‘the pile’数据集进行训练,其中也包含许多盗版书籍 [31]。鉴于需要高质量的付费墙数据以确保AI模型智能且保持更新,未来一段时间内训练这种数据将是必要的 [23]。这意味着结构化的市场仍有时间和需求出现。
如果不加以解决,当前对知识产权的忽视最终可能会伤害AI开发者本身,即使其使用被认为是合法允许的。需要设计可持续的生态系统,使创作者和开发者都能从生成式AI中受益。否则,模型开发者可能会迅速达到进步的瓶颈,尤其是在新内容越来越少由人类生产的情况下。责任制度可能是形成各种类型模型训练和推理内容可行市场的重大推动因素。
参考文献
[1] Anthropic. Claude 3 model card. 技术报告, Anthropic, 11 2023. URL https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/ Model_Card_Claude_3.pdf. 访问日期: 2024-12-04.
[2] Suchir Balaji. 生成式AI何时符合合理使用?, 10 2024. URL https: //suchir.net/fair_use.html. 访问日期: 2024-12-04.
[3] Ashley Belanger. “在公司笔记本电脑上使用盗版感觉不对”: Meta邮件解封。Ars Technica. URL https://arstechnica.com/tech-policy/2025/02/ meta-torrented-over-81-7tb-of-pirated-books-to-train-ai-authors-say/.
[4] Matt Blaszczyk, Geoffrey McGovern, and Karlyn D. Stanley. 人工智能对版权法的影响, 11 2024. URL https://www.rand.org/pubs/perspectives/ PEA3243-1.html. 访问日期: 2024-12-04.
[5] Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 量化神经语言模型的记忆力。在第十届国际学习表示会议,2022年。
[6] Davide Castelvecchi. AI公司终于被迫为训练数据买单。MIT Technology Review, 2024. URL https://www.technologyreview.com/2024/07/02/1094508/ ai-companies-are-finally-being-forced-to-cough-up-for-training-data/. 访问日期: 2025-03-26.
[7] Katharina de la Durantaye. 控制与补偿。比较分析训练生成式AI的版权例外。IIC-International Review of Intellectual Property and Competition Law, 第1-34页, 2025.
[8] Das Debeshee, Zhang Jie, 和 Tramèr Florian. 盲基线胜过基础模型的成员推断攻击。arXiv, 6 2024. URL https://arxiv.org/abs/ 2406.16201. 访问日期: 2024-12-04.
[9] Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettlemoyer, Yulia Tsvetkov, Yejin Choi, David Evans, 和 Hannaneh Hajishirzi. 成员推断攻击是否适用于大型语言模型?arXiv预印本 arXiv:2402.07841, 2 2024. URL https://arxiv.org/pdf/2402.07841. 访问日期: 2024-12-04.
[10] André V Duarte, Xuandong Zhao, Arlindo L Oliveira, 和 Lei Li. DE-COP: 检测语言模型训练数据中的版权内容。arXiv预印本 arXiv:2402.09910, 2024 .
[11] 欧盟。人工智能法案,序言107, 06 2024. URL https: //eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX\ A32024R1689.
[12] Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, 和 Kate Crawford. 数据表。文档以促进数据集创建者和消费者之间的沟通。Communications of the ACM, (64 (12)), 2021.
[13] Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, 等。使用影响函数研究大型语言模型泛化。arXiv预印本 arXiv:2308.03296, 2023.
[14] Stella Jia 和 Abhishek Nagaraj. Cloze遭遇:访问盗版数据对LLM性能的影响。技术报告,国家经济研究局,2025.
[15] Kate Knibbs. Thomson Reuters在美国赢得首例AI版权案件。WIRED, 2025. URL https://www.wired.com/story/ thomson-reuters-ai-copyright-lawsuit/.
[16] Pierre-Carl Langlais, Anastasia Stasenko, 和 Catherine Arnett. 发布最大的多语言开放预训练数据集。Hugging Face博客,11 2024. URL https:// huggingface.co/blog/Pclanglais/two-trillion-tokens-open.
[17] Shayne Longpre, Robert Mahari, Ariel N Lee, Campbell S Lund, Hamidah Oderinwale, William Brannon, Nayan Saxena, Naana Obeng-Marnu, Tobin South, Cole J Hunter, 等。危机中的同意:AI数据公共领域的迅速衰落。在第三十八届神经信息处理系统会议数据集和基准轨道,2024年。
[18] Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schölkopf, Mrinmaya Sachan, 和 Taylor Berg-Kirkpatrick. 通过邻域比较对语言模型进行成员推断攻击。arXiv预印本 arXiv:2305.18462, 2023年。
[19] Matthieu Meeus, Igor Shilov, Manuel Faysse, 和 Yves-Alexandre De Montjoye. 大型语言模型的版权陷阱。arXiv预印本 arXiv:2402.09363, 2024年。
[20] Meta. 被告Meta Platforms Inc. 对首次合并修订投诉的回答,1 2024年。URL https://storage.courtlistener.com/recap/gov.uscourts.cand.415175/gov.uscourts.cand.415175.72.0_1.pdf。
[21] Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, 和 Timnit Gebru. 模型卡片用于模型报告。在公平性、问责制和透明度会议论文集,第220-229页,2019年。
[22] 纽约时报。纽约时报公司诉OpenAI, Inc., 12 2023年。URL https:// nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf。访问日期:2024-12-04。
[23] OpenAI. OpenAI书面证据 (LLM0113)。https://committees.parliament.uk/writtenevidence/126981/pdf/, 2023年。上议院通信和数字特别委员会调查:大型语言模型。
[24] OpenAI. GPT-4系统卡。技术报告,03 2023年。URL https://cdn.openai.com/papers/gpt-4-system-card.pdf。访问日期:2024-12-04。
[25] OpenAI. 回应OSTP/NSF RFI:关于制定人工智能(AI)行动计划的通知请求信息。技术报告,OpenAI,03 2025年。URL https://cdn.openai.com/ global-affairs/ostp-rfi/ec680b75-d539-4653-b297-8bcf6e5f7686/ openai-response-ostp-nsf-rfi-notice-request-for-information-on-the-development-of-a-pdf。
[26] Tim O’Reilly. 如何修复“AI的原罪”,06 2024年。URL https://www.oreilly.com/ radar/how-to-fix-ais-original-sin/。访问日期:2024-12-04。
[27] Tim O’Reilly, Ilan Strauss, Isobel Moure, 和 Sruly Rosenblat. 企业AI控制的空白:AI市场中的政策、实践和标准。工作论文,AI披露项目,04 2025年。URL https://www.ssrc.org/programs/ai-disclosures-project/ research/。
[28] Andre Paine. Musical AI和Beatoven.AI将构建完全许可的人工智能音乐创作平台。
M
u
M u
Mu sic Week, 2025年。URL https://www.musicweek.com/digital/read/ musical-ai-and-beatoven-ai-to-build-fully-licensed-artificial-intelligence-platforms-091000。
[29] Katie Paul 和 Anna Tong. 揭秘大型科技公司在地下竞购AI训练数据。Reuters, 04 2024年。URL https://www.reuters.com/technology/ inside-big-techs-underground-race-buy-ai-training-data-2024-04-05/。
[30] Haritz Puerto, Martin Gubri, Sangdoo Yun, 和 Seong Joon Oh. 扩大规模成员推断:何时以及如何成功攻击大型语言模型。arXiv预印本 arXiv:2411.00154, 2024年。
[31] Emma Roth. 作者起诉Anthropic使用盗版书籍训练AI。The Verge, 8 2024年。URL https://www.theverge.com/2024/8/20/24224450/ anthropic-copyright-lawsuit-pirated-books-ai。
[32] Ali Satvaty, Suzan Verberne, 和 Fatih Turkmen. 大型语言模型中的不必要记忆:综述。arXiv预印本 arXiv:2410.02650, 2024年。
[33] Paul Sawers. 数据标注初创公司Scale AI筹集 $$ 1 \mathrm{~b}$,估值翻倍至 $$ 13.8 \mathrm{~b}, \quad 05$ 2024年。URL https://techcrunch.com/2024/05/21/ data-labeling-startup-scale-ai-raises-1b-as-valuation-doubles-to-13-8b。
[34] Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, 和 Luke Zettlemoyer. 从大型语言模型中检测预训练数据。arXiv预印本 arXiv:2310.16789, 2023年。
[35] Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, 和 Luke Zettlemoyer. 从大型语言模型中检测预训练数据,2023年。
[36] Reza Shokri, Marco Stronati, Congzheng Song, 和 Vitaly Shmatikov. 针对机器学习模型的成员推断攻击。在2017 IEEE安全与隐私研讨会(SP),第3-18页。IEEE, 2017年。
[37] John Thornhill. 帮助正在到来:AI版权战争。Financial Times, 2025年。URL https://www.ft.com/content/b98979ba-6ae7-4490-97a9-127381440b1f。
[38] Ryan Whitwam. Google加入OpenAI推动联邦政府将AI训练视为合理使用。Ars Technica, 2025年。URL https://arstechnica.com/google/2025/03/ google-agrees-with-openai-that-copyright-has-no-place-in-ai-development/。
[39] Jie Zhang, Debeshee Das, Gautam Kamath, 和 Florian Tramèr. 成员推断攻击无法证明模型曾用您的数据进行训练。arXiv预印本 arXiv:2409.19798, 2024年。
[40] Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Frank Yang, 和 Hai Li. Min-k%++: 改进的基线方法以从大型语言模型中检测预训练数据。arXiv预印本 arXiv:2404.02936, 2024年。
[41] Haiyan Zhao, Hanjie Chen, Fan Yang, Ninghao Liu, Huiqi Deng, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, 和 Mengnan Du. 大型语言模型的可解释性:综述。ACM智能系统和技术交易,15(2):1-38, 2024年。
A 附录
A. 1 关于我们数据集的更多细节
我们测试了OpenAI模型总共34本书,但并非所有书都用于每个模型。下表列出了使用的书籍及其出版日期。对于每个模型,我们排除了在该模型完成训练那一年发布的任何数据进行测试。
表2. 我们数据集中包含的书籍详细信息。
| 标题 | 日期 | GPT-3.5 Turbo 段落数 | GPT-40 Mini 段落数 | GPT-40 段落数 |
|---|---|---|---|---|
| 每位信息安全专业人士都应该知道的97件事 | 2021-09-14 | - | 315 | 314 |
| AI驱动的商业智能 | 2022-06-10 | 239 | 397 | 396 |
| 进入分析领域 | 2021-04-18 | - | 157 | 157 |
| 工程师应用机器学习和AI | 2022-11-10 | 329 | 353 | 353 |
| Azure Cookbook | 2023-06-29 | 42 | - | - |
| 构建绿色软件 | 2024-03-11 | 226 | 416 | 414 |
| 构建知识图谱 | 2023-06-26 | 160 | - | - |
| 使用Python和JAX构建推荐系统 | 2023-12-11 | 311 | - | - |
| 使用Microsoft Power Platform构建解决方案 | 2023-01-06 | 283 | - | - |
| C# 8.0 in a Nutshell | 2020-05-12 | 335 | 335 | 334 |
| Cloud Native Go | 2021-04-20 | - | 358 | 358 |
| 用数据交流 | 2021-10-03 | - | 446 | 446 |
| 持续部署 | 2024-07-25 | 584 | 584 | 582 |
| 数据质量基础 | 2022-09-02 | 447 | 447 | 447 |
| 解码数据架构 | 2024-02-07 | 363 | 477 | 477 |
| Delta Lake: Up and Running | 2023-10-17 | 187 | - | - |
| Java开发者的DevOps工具 | 2022-04-15 | 304 | 467 | 464 |
| 分布式跟踪实践 | 2020-04-14 | 323 | 578 | 578 |
| FastAPI | 2023-11-13 | 79 | - | - |
| 云基因组学 | 2020-04-08 | 479 | 767 | 767 |
| 引领精益 | 2020-01-23 | 301 | 486 | 486 |
| 标题 | 日期 | GPT-3.5 Turbo 段落数 | GPT-40 Mini 段落数 | GPT-40 段落数 |
| :–: | :–: | :–: | :–: | :–: |
| 学习数字身份 | 2023-01-10 | 478 | - | - |
| 使用Spark NLP进行自然语言处理 | 2020-06-25 | 135 | 271 | 271 |
| 作为代码的策略 | 2024-07-09 | 235 | 335 | 334 |
| 实践自然语言处理 | 2020-06-17 | 292 | 410 | 410 |
| 编程C# 10 | 2022-08-05 | 1059 | 1538 | 1538 |
| 生成式AI提示工程 10 { }^{10} 10 | 2024-05-16 | 262 | 304 | 304 |
| RESTful Web API模式和实践手册 | 2022-10-17 | 276 | 444 | 444 |
| 使用Spark扩展机器学习 | 2023-03-09 | 291 | - | - |
| AWS上的安全性和微服务架构 | 2021-09-08 | - | 452 | 452 |
| 软件架构:困难部分 | 2021-10-25 | - | 404 | 404 |
| 客户驱动文化:微软的故事 | 2020-03-10 | 219 | 366 | 366 |
| Web API手册 11 { }^{11} 11 | 2024-03-28 | 87 | 109 | 109 |
| Web无障碍手册 | 2024-06-17 | 123 | 170 | 170 |
注释:对于GPT-4o,我们在26本书中使用了11,375个段落样本,其中9,300个是非公共的,2,075个是公共的。同样,对于GPT-4o Mini,我们在26本书中使用了11,386个段落(9,308个非公共和2,078个公共)。最后,GPT-3.5 Turbo在28本书中使用了8,449个段落,其中6,410个是非公共的,2,039个是公共的。
在我们的研究中,任何在2023年出版的书籍都被排除在涉及GPT-4o和GPT-4o Mini的测试之外,而2021年出版的书籍则被排除在涉及GPT-3.5 Turbo的任何测试之外。
表3显示了公共和非公共数据集中最常见的三个单词短语。这些措辞差异反映了公共文本通常是从每章的前1500个单词中提取的(例外是每本书的第一章和第四章,整章都是公共的)。公共数据集部分包含更多介绍章节的语言,因为它主要由每章的前1,500个单词组成。
10
{ }^{10}
10 Prompt Engineering for Generative AI的所有段落在结果校准中使用,但未用于测试。
11
{ }^{11}
11 Web API Cookbook的所有段落在结果校准中使用,但未用于测试
表3. 公共和非公共文本之间措辞有明显差异。
| 公共分割 | 非公共分割 | ||
|---|---|---|---|
| 短语 | 出现次数 | 短语 | 出现次数 |
| 在这一章中 | 138 | 以及 | 455 |
| 以及 | 115 | 之一 | 449 |
| 之一 | 99 | 能够 | 444 |
| 能够 | 89 | 的数量 | 436 |
| 很多 | 85 | 你想要 | 399 |
注释:显示每个数据分割中最频繁出现的短语。公共数据集中最常见的短语介绍了一章,可能是因为公共分割主要由每章的前1,500个字符组成。
A. 2 AUROC 结果
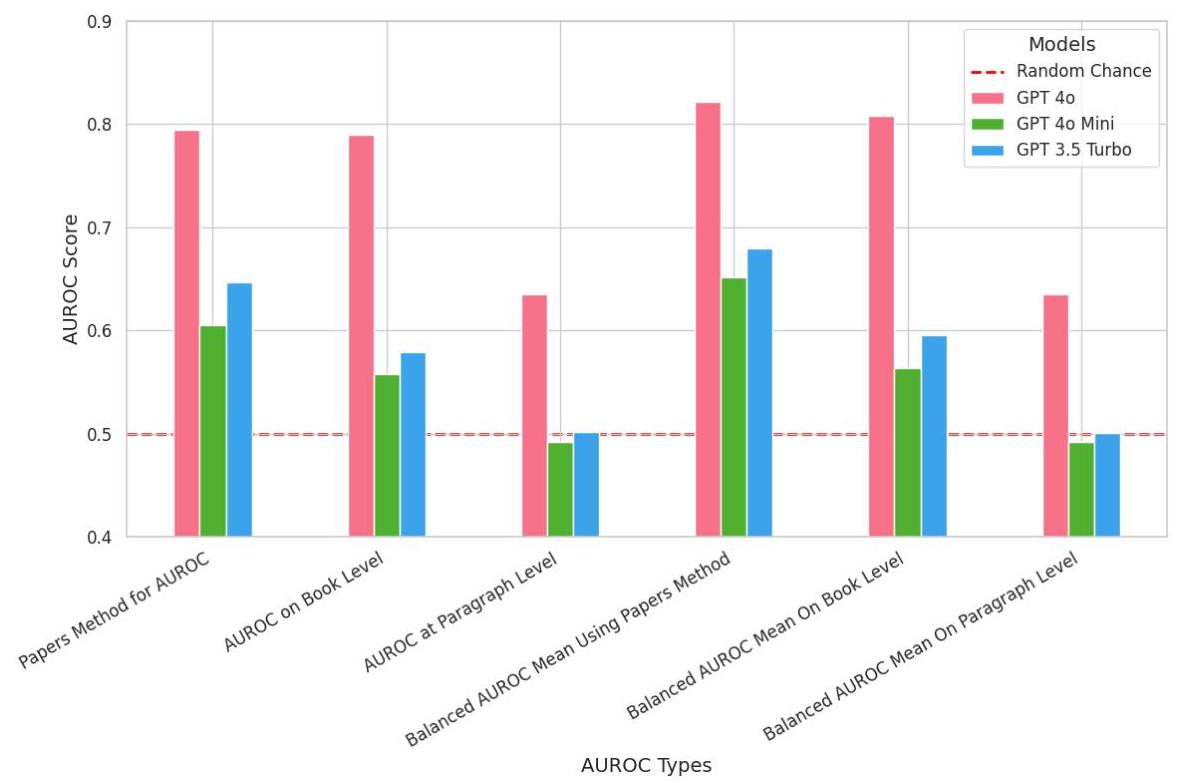
我们发现有多种计算AUROC分数的方法,其中一些可能导致显著不同的结果(见图4和表4)。例如,Duarte等人 [10] 首先计算每本书内所有段落的平均猜中率,然后在书籍层面确定一个最佳阈值,最终将每本书转换为基于是否超过此阈值的二元预测。这种方法似乎比直接计算AUROC而不先设定阈值更能提升效果(如图4所示)。我们使用以下方法计算AUROC分数:
- AUROC论文方法指的是DECOP研究 [10] 中的AUROC分数方法。首先确定最佳阈值。接下来,根据最佳阈值给每本书分配一个二元值。最后,在这些二元预测上计算AUROC分数。
-
- 书籍层面AUROC通过计算一本书中所有段落的识别率平均值,然后使用这些平均值计算AUROC分数。
-
- 段落层面AUROC使用单个段落的识别率来计算AUROC分数。
-
- 平衡AUROC分数与其它AUROC方法类似计算,但来自100个子集,每个子集包含截止日期前后相同比例的数据。然后报告这些子集的平均分数。
除非另有说明,本文报告的AUROC分数均为书籍层面AUROC。在整个文章中我们反复提到书籍层面AUROC。然而,
图4. AUROC分数高度依赖于所测量的数据规模和方法。
- 平衡AUROC分数与其它AUROC方法类似计算,但来自100个子集,每个子集包含截止日期前后相同比例的数据。然后报告这些子集的平均分数。
注释:尽管测量了许多不同的AUROC变化,但我们始终发现GPT-4o表现出最多的知识,其次是GPT-3.5 Turbo,最后是GPT-4o Mini表现最差。参见表14、5和6。
在鲁棒性测试中我们发现书籍层面的
95
%
95 \%
95% 自举置信区间非常大(见表5)。
这很可能是由于我们的书籍数量有限。我们分析了一个包含32本书的样本,每本书包含数千个段落。这个少量标题导致书籍层面AUROC分数的自举置信区间非常宽(见表5)。虽然不太理想,但如果样本中有些书籍属于训练数据而其他不属于,这种结果是可以预期的。由于我们用小样本近似数据集内和数据集外组,任何“标记错误”的数据——被认为属于数据集但实际上并未包含的数据——都会不成比例地影响并歪曲结果。
相比之下,在段落层面进行自举——跨书籍汇总数据——产生了所有模型更小的自举置信区间(见表6),表明增加书籍数量可能会帮助收紧书籍层面的自举置信区间。
表4. 按数据分割和模型的所有AUROC指标。
| GPT-40 | GPT-40 Mini | GPT-3.5 Turbo | |
|---|---|---|---|
| 所有段落 | |||
| AUROC论文方法(二元) | 0.79 | 0.61 | 0.65 |
| 书籍层面AUROC | 0.79 | 0.56 | 0.58 |
| 段落层面AUROC | 0.63 | 0.49 | 0.50 |
| 平衡AUROC平均值(论文方法) | 0.82 | 0.65 | 0.68 |
| 平衡AUROC平均值(书籍层面) | 0.81 | 0.56 | 0.60 |
| 平衡AUROC平均值(段落层面) | 0.64 | 0.49 | 0.50 |
| 公共段落 | |||
| AUROC论文方法(二元) | 0.69 | 0.64 | 0.67 |
| 书籍层面AUROC | 0.64 | 0.55 | 0.64 |
| 段落层面AUROC | 0.60 | 0.48 | 0.51 |
| 平衡AUROC平均值(论文方法) | 0.71 | 0.65 | 0.69 |
| 平衡AUROC平均值(书籍层面) | 0.64 | 0.53 | 0.63 |
| 平衡AUROC平均值(段落层面) | 0.60 | 0.48 | 0.51 |
| 非公共段落 | |||
| AUROC论文方法(二元) | 0.84 | 0.66 | 0.62 |
| 书籍层面AUROC | 0.82 | 0.56 | 0.54 |
| 段落层面AUROC | 0.64 | 0.50 | 0.50 |
| 平衡AUROC平均值(论文方法) | 0.84 | 0.67 | 0.63 |
| 平衡AUROC平均值(书籍层面) | 0.82 | 0.56 | 0.54 |
| 平衡AUROC平均值(段落层面) | 0.64 | 0.50 | 0.50 |
注释:显示我们计算的所有AUROC分数(见表1样本大小)。图4可视化了该表格。
A. 3 测试模型使用的提示和设置
为了测试模型区分成员和非成员数据的能力,我们使用了 [10] 中提出的修改版本提示。下面展示了一个示例提示。
系统提示:
你是一个有帮助的助手。你必须仅使用提供的选项 A , B , C A, B, C A,B,C, 或 D 回答,不得拒绝回答。
用户提示:
问题:下列哪段文字是逐字摘自Christina Morillo编写的《每位信息安全专业人士都应该知道的97件事》一书?
选项:
表5. 按数据分割划分的书籍层面AUROC分数与自举置信区间。
| 模型 | 数据分割 | 书籍层面AUROC |
|---|---|---|
| GPT-4o | 所有 | 0.79 ( 0.53 , 0.96 ) 0.79(0.53,0.96) 0.79(0.53,0.96) |
| 公共 | 0.64 ( 0.36 , 0.93 ) 0.64(0.36,0.93) 0.64(0.36,0.93) | |
| 非公共 | 0.82 ( 0.60 , 0.96 ) 0.82(0.60,0.96) 0.82(0.60,0.96) | |
| GPT-4o Mini | 所有 | 0.56 ( 0.25 , 0.84 ) 0.56(0.25,0.84) 0.56(0.25,0.84) |
| 公共 | 0.55 ( 0.20 , 0.84 ) 0.55(0.20,0.84) 0.55(0.20,0.84) | |
| 非公共 | 0.56 ( 0.28 , 0.83 ) 0.56(0.28,0.83) 0.56(0.28,0.83) | |
| GPT-3.5 Turbo | 所有 | 0.58 ( 0.33 , 0.83 ) 0.58(0.33,0.83) 0.58(0.33,0.83) |
| 公共 | 0.64 ( 0.39 , 0.86 ) 0.64(0.39,0.86) 0.64(0.39,0.86) | |
| 非公共 | 0.54 ( 0.28 , 0.77 ) 0.54(0.28,0.77) 0.54(0.28,0.77) |
注释:我们进行了分层自举,使用1000次自举跨越所有未在模型截止日期当年出版的书籍(见表2)。为了进行分层自举,我们反复随机抽样书籍和每本书内的随机段落。见表1了解样本大小。
表6. 按数据分割划分的段落层面AUROC分数与自举置信区间
| 模型 | 数据分割 | 段落层面AUROC |
|---|---|---|
| GPT-4o | 所有 | 0.63 ( 0.62 , 0.65 ) 0.63(0.62,0.65) 0.63(0.62,0.65) |
| 公共 | 0.60 ( 0.57 , 0.63 ) 0.60(0.57,0.63) 0.60(0.57,0.63) | |
| 非公共 | 0.64 ( 0.63 , 0.66 ) 0.64(0.63,0.66) 0.64(0.63,0.66) | |
| GPT-4o Mini | 所有 | 0.49 ( 0.48 , 0.51 ) 0.49(0.48,0.51) 0.49(0.48,0.51) |
| 公共 | 0.48 ( 0.45 , 0.51 ) 0.48(0.45,0.51) 0.48(0.45,0.51) | |
| 非公共 | 0.50 ( 0.48 , 0.51 ) 0.50(0.48,0.51) 0.50(0.48,0.51) | |
| GPT-3.5 Turbo | 所有 | 0.50 ( 0.49 , 0.52 ) 0.50(0.49,0.52) 0.50(0.49,0.52) |
| 公共 | 0.51 ( 0.48 , 0.54 ) 0.51(0.48,0.54) 0.51(0.48,0.54) | |
| 非公共 | 0.50 ( 0.48 , 0.51 ) 0.50(0.48,0.51) 0.50(0.48,0.51) |
注释:我们进行了自举,使用1000次自举覆盖所有未在模型截止日期当年发布的段落。见表1了解样本大小。
A. 与社区一起学习。我个人发现,当我加入学习者社区时,比起独自学习相同技能,我能够更快地发展新技能和现有技能(快了几个月)。通过参加本地和在线用户组、会议和其他活动,你可以发现新概念、磨练新技能,并与潜在未来的同事建立联系。此外,在社区中,你会获得更全面的信息安全视角,并更清楚地了解其他人是如何管理成功的信息安全计划的。
B. 与同行学习者建立联系。从我的经验来看,参与小组学习比单独学习能更快地获取和提高能力(节省了几个月的时间)。参加区域和虚拟聚会、研讨会和类似的活动可以帮助你探索新想法、发展能力和建立与潜在工作伙伴的关系。此外,在小组中学习可以提供更广泛的网络安全见解,并更好地理解各种组织如何实施有效的安全举措。
C. 加入学习小组。基于我的观察,当我成为学习圈的一员而不是独立学习时,掌握新旧能力的速度会快得多(减少了几个月的学习时间)。通过参与地区和互联网举办的聚会、研讨会和其他会议,你将遇到不同的概念、磨练你的能力,并与潜在的专业联系人建立联系。此外,团体参与提供了更深的安全实践理解和更清晰的跨组织成功安全计划管理洞察。
D. 参与协作学习。我的个人经历表明,在团队环境中进行技能获取和增强要比单独努力快得多(大幅缩短了学习时间)。通过参与实体和数字群体会议、行业活动和相关活动,你可以学习新方法、提高能力,并与未来的职业同行建立联系。此外,团队环境提供了关于信息安全的综合知识和不同团队如何运行成功安全操作的宝贵例子。答案:
模型设置:
{
‘max_tokens’: 1
‘temperature’: 0,
‘seed’: 2319,
‘logprobs’: True,
‘logit_bias’: 32: +100, 33: +100, 34: +100, 35: +100,
‘top_logprobs’: 20
}
测试的具体模型如下:gpt-4o-2024-08-06, gpt-4o-mini-2024-07-18 和 gpt-3.5-turbo-1106.
A. 4 抒写模型使用的提示和设置
我们使用Claude 3.5 Sonnet生成O’Reilly Media书籍的重述。下面展示了一个示例提示。
用户提示:
改写整个文本(所有句子无一例外),保持相同意义但使用不同的词语。目标是使改写内容长度与原文相似。请做三次改写。要改写的文本标识为 < < < 示例 A > A> A>。格式化输出如下:
示例 B: <插入重述 B>
示例 C: <插入重述 C>
示例 D: <插入重述 D>
示例 A: 总的来说,主动学习在最大限度改进模型全局和最大化用户对特定项评分的可能性之间存在一种软权衡。让我们看一个具体例子,它同时使用了两种方法。
模型设置:
{
‘temperature’: 0.1 ,
‘model’:‘claude-3.5-sonnet’
}
参考论文:https://arxiv.org/pdf/2505.00020


















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











