






Robert E. Wray
[
0000
−
1111
−
2222
−
3333
]
{ }^{[0000-1111-2222-3333]}
[0000−1111−2222−3333],James R. Kirk 和 John E. Laird
综合认知中心,IQMRI,美国密歇根州安娜堡市,邮编 28105
{robert.wray, james.kirk, john.laird}@cic.iqmri.org
http://integratedcognition.ai
摘要
人工智能(AI)和通用人工智能(AGI)的一个目标是识别并理解实现通用智能所需的特定机制和表示形式。通常,这项工作以研究架构的形式呈现,许多认知架构已在AI/AGI领域中被探索。然而,不同的研究团队甚至不同的研究传统在某种程度上独立地识别出了相似的共同过程和表示模式或认知设计模式,这些模式体现在现有的架构中。今天,利用大型语言模型(LLMs)的AI系统提供了一种相对较新的机制和表示组合,可用于探索通用智能的可能性。在本文中,我们总结了几种在各种前转换器AI架构中出现的反复认知设计模式。然后,我们探讨了这些模式如何体现在使用LLMs的系统中,特别是对于推理和互动(“代理”)用例。通过检查和应用这些反复出现的模式,我们还可以预测当今LLM系统中的差距或不足,并确定未来基于LLMs和其他生成基础模型的通用智能研究可能涉及的主题。
关键词:代理 ⋅ \cdot ⋅ 认知架构 ⋅ \cdot ⋅ 大型语言模型
1 引言
认知架构封装并代表了对通用、系统化智能架构的理论和承诺。已提出了并开发了一百多种不同的认知架构,它们源自许多不同(且往往相当差异化的)知识传统 [15]。值得注意的是,随着架构因研究成果而演变,尽管它们来自非常不同的来源,但在高级功能架构的认知方面 [18] 以及许多低级算法 [13] 和表示承诺 [5,6] 方面,出现了显著的收敛甚至共识。从这种收敛中可以得出一个初步但充满希望的推论,即作为领域,我们开始了解实现人工通用智能(AGI)所需的组件(或至少重要的组件)。
与认知架构相对较长的历史相比,大型语言和多模态模型(LLMs
1
)
\left.{ }^{1}\right)
1) 在过去五年内作为一项重大新技术出现,吸引了大量研究兴趣、投资甚至公众关注。这种关注源于这些模型的广度和深度及其适用于许多不同用例和应用的能力。虽然有时有人声称LLMs单独可能具备实现AGI的潜力 [3],但一个新的快速成长的研究领域旨在将LLMs作为一种(重要)组件,整合到更广泛的组件和工具集合中,从而构成一个通用AI系统
[
14
,
63
,
24
]
[14,63,24]
[14,63,24]。
在本文中,我们专注于主要由LLM组件组成的系统架构(而非LLM与规划器 [14]、约束求解器 [22]、传统认知架构 [17] 等的更混合集成)。此类代理型LLM系统通常为特定任务或领域开发,例如软件开发 [8] 或网络内容发布 [36]。然而,研究人员和开发者也在尝试识别和开发足够通用的代理框架,以应用于任何任务 [62,37, 55]。此外,代理型LLM系统通常通过专门记忆进行增强,这些记忆在认知架构中也很常见(例如情景记忆)。总之,寻找通用代理型LLM系统的目标和与认知架构研究有显著重叠。
在代理型LLM社区中,已经有一些高层次的建议,试图从认知架构 [40] 和代理架构及多代理系统 [41] 中汲取经验教训。在本文中,从认知和代理架构研究人员的角度出发,我们简要概述了在不同架构中反复出现的常见机制和表示形式的概念。然后,我们回顾了一些这些认知设计模式,并探讨其对代理型LLM系统的潜在相关性。我们的示例包括目前在代理型LLMs中正在探索的模式,以及相对较少探索但似乎适合研究关注的模式。我们认为,这种跨不同领域的细致、比较和整合分析不仅可以加速代理型LLMs的未来研究,还可以拓宽针对识别通用智能架构的研究范围。
2 认知设计模式
在软件工程中,设计模式是对特定设计问题解决方案的描述或模板。设计模式通常以抽象方式(而非代码)指定,并且灵活到足以适应/定制于特定情况。认知设计模式代表类似概念。认知设计模式指代在代理和/或认知架构中经常出现的某些功能/过程或表示/记忆。也就是说,就像软件设计模式一样,认知设计模式在抽象层面上总结了智能系统功能需求的常见(或至少反复出现的)解决方案。表1列出了一些认知设计模式的例子,这些例子来源于不同研究人员过去的比较分析 [13, 18, 15, 38]。为了说明,我们包括了ACT-R [1] 和Soar [16] 认知架构以及信念-欲望-意图(BDI)家族代理架构 [53] 的示例。我们引入认知设计模式以支持此类分析的组织和统一。
重要的是,认知设计模式像软件设计模式一样是抽象的。它们不仅抽象了实现细节,甚至具体算法。如表中所示的例子,不同的算法和表示承诺用于在个别架构中实现认知设计模式。图1展示了一个例子。许多架构使用三阶段过程来控制断言和撤回单个记忆项(而不是更常见的存储/擦除两阶段过程)。
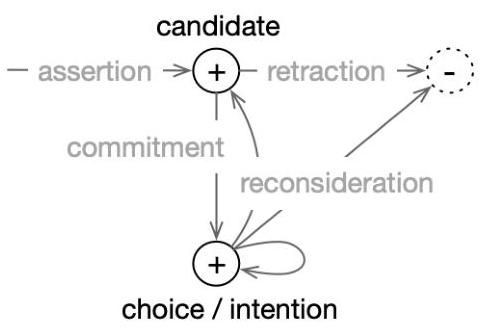
图1. 三阶段承诺认知设计模式的插图。
过程。相反,代理生成某些记忆槽位的候选对象。然后它使用选择或承诺过程 [53] 在候选人中做出选择,然后再做最终选择或意图。
任何承诺都可以在承诺决策后进行评估或重新考虑 [35]。重新考虑可能导致移除/撤回、降级(先前选择降级为候选人),或重新确认(继续当前选择)。BDI架构和Soar(以及其他一些认知架构)在其主要审议单元中表现出这种三阶段过程。然而,审议的表示焦点(BDI中的计划,Soar中的操作符)是不同的,具体的断言、承诺和重新考虑算法也是如此 [54, 35, 13]。
熟悉的算法可能会被专门化(在范围和/或实现上)以在架构中实现认知功能。例如,Soar使用基于理由的真理维护系统(JTMS)9] 作为一种功能类型记忆元素的重新考虑过程。JTMS实现专门针对其在Soar中的集成。认知设计模式作为比较和分析单位是有用的,因为抽象到仅仅识别功能性角色(重新考虑)使分析远离实现细节(Soar的定制JTMS),从而使架构承诺中的共同点和对比更加明显和清晰。如果我们仅仅断言Soar使用JTMS,而BDI架构在不同类型的记忆实例上使用某些决策理论计算,很容易错过这两种过程的功能角色——重新考虑(更广泛地说,信念修订和上下文/记忆管理)——在这两种架构中是可比的。
3 认知设计模式与代理型LLM系统
认知设计模式在许多现有系统中出现并重复,这些系统致力于实现通用智能。我们现在考虑这些认知设计模式是否适合于理解和评估代理型LLM研究的进程。我们考虑以下三个问题:
- 在现有的代理型LLM系统中有哪些认知设计模式?如果认知设计模式代表了通用智能的重要功能目录,我们应该在针对通用智能的代理型LLM系统中观察到它们。一些认知设计模式非常明显。我们将详细讨论两个最近的例子。
-
- 哪些认知设计模式看似适合代理型LLMs,但尚未成为代理型LLM主流的一部分?我们展示了两个尚未深入研究但看似与当前代理型LLM系统状态相关的例子。
-
- 代理型LLMs的独特属性是否暗示了通用智能的新认知设计模式?我们调查代理型LLMs的计算和行为特征是否暗示了新的认知设计模式。
以下小节考虑了每个问题,从代理型LLM和认知及代理架构的研究中举例说明。我们确定具体示例以说明(并希望提供洞察力)。对这些问题进行全面调查超出了会议论文的范围,鉴于这些主题的加速探索,也有些不切实际。
表2. 最近代理型LLM研究中明显的认知设计模式。
- 代理型LLMs的独特属性是否暗示了通用智能的新认知设计模式?我们调查代理型LLMs的计算和行为特征是否暗示了新的认知设计模式。
| 认知设计模式 | 代理型LLM系统 |
|---|---|
| 观察-决定-行动 | ReAct [62], Reflexion [37] |
| 分层 | Voyager [46], ADaPT [33], DeAR [60], |
| 分解 | 思维树 [61], 思维图 [2] |
| 知识编译 | 自然语言: ExpeL [64], Reflexion [37] |
| 结构化表示: Voyager [46], LLMRG [51], | |
| 认知代理框架 [66] | |
| 上下文记忆 | MemGPT [30], LONGMEM [49] |
| 非历史知识/记忆 | A-MEM [59], WISE [47], MemoryBank [65] |
| 历史知识/记忆 | 生成式代理 [31], MemoryBank [65] |
| 过程知识/记忆 | ProgPROMPT [39], Voyager [46], 自进化GPT [11] |
3.1 现有系统中的认知设计模式
表1中的许多认知设计模式都是众所周知的,并且在代理型LLM研究中越来越明显。表2列出了最近研究中的例子。 2 { }^{2} 2 我们重点介绍两个具体示例。
ReAct中的观察-决定-行动 一般来说,当用户提示引导模型明确表达其推理时,LLM性能会提高,正如现在普遍使用的思维链(CoT)提示方法 [52] 所示。ReAct [62] 是最早的也是最具影响力的代理型LLM方法之一,它基于CoT区分了内部和外部问题解决步骤。如图2(左)所示,ReAct最初提示LLM对问题进行自然语言(NL)陈述(思考)后再采取任何行动。引导LLM将其推理和行动步骤分开,导致多个领域中LLM响应显著改善 [62]。ReAct现在是代理型LLM系统的基础方法,并已被纳入代理型软件开发工具中,例如LangGraph [21]。
ReAct复制了部分常见的观察-决定-行动模式。图2(右)展示了观察-决定-行动如何在BDI架构中频繁实现:新输入触发一个分析/推理过程,该过程受代理当前信念和欲望的影响。更新后的信念和欲望背景然后通知决策或承诺过程(包括前面讨论的重新考虑)。由此产生的意图随后导致代理行动。其他架构的基本决策过程,如Soar和ACT-R,也可以映射到这个抽象的观察-决定-行动模式。
ReAct与此模式有显著重叠,但缺乏明确的承诺步骤。因此,这种将ReAct映射到熟悉设计模式的做法引发了一个直接的经验问题:在ReAct中引入承诺概念是否会导致比单独使用ReAct更好的整体推理结果?我们认为,将代理型LLM解决方案映射到认知设计模式的一个优势是识别出类似的具体问题。
生成式代理中的情景记忆 代理型LLM研究人员越来越多地探索各种长期记忆(LTMs) [56]。例子包括通用LTMs [65] 和专用于程序(或技能) [46, 11]、历史/事件 [31,32,65] 或事实(语义记忆) [59, 48] 的LTMs。通常,长期记忆赋予代理型LLM系统更多能力来控制其生成步骤所使用的上下文,使其能够在较长时间内对动态环境作出自适应反应 [ 11 , 57 ] [11,57] [11,57]。
一个早期且具有影响力的例子是在代理型LLM系统中使用长期记忆的是生成式代理 [31]。在这个专注于人类行为模拟的研究系统中,LLM代理代表生活在小村庄中的人。不同的代理通过自然语言相互交互,并执行各种个人和集体任务,例如上班或上学、竞选公职、计划聚会等。生成式代理实现了一个长期记忆,该记忆连接了特定近期经历(观察)的历史和过去经验的抽象、综合摘要(反思)。反思捕捉了经验的核心(“Klaus整天在实验室工作”)和见解(“Klaus对实验室工作的奉献表明他对研究充满热情。”)。
这些过去经验的记忆随后影响了该代理的后续行为。代理检索观察和反思的组合进入记忆流,这提供了代理规划和行动的上下文。检索使用最近性、代理判断的重要性(在记忆编码时)以及代理主观的相关性从长期记忆中检索项目到记忆流。
表3. 情景记忆的特点及与生成式代理的比较。
| 特征 | 是否在[31]中? | 注释 |
|---|---|---|
| 学习过程 | ||
| 自动 | 半自动 | 定期过程用于评估记忆并保存子集。 |
| 自传体 | 是 | 记忆以第三人称记录,但代理理解记忆与自身有关。 |
| 自我意识 | ? | 不清楚代理如何区分当前理解和过去经验的记忆。 |
| 情景分割 | 否 | 观察跨度和反思提示基于预定义的静态周期(例如,每100次观察触发一次反思)。 |
| 可变长度 | 是 | 反思可以涵盖代理经验的不同长度。 |
| 检索过程 | ||
| 提示驱动 | 部分 | 当前代理情境中的对象用作检索提示 |
| 自发性? | 是 | 检索实现为定期自动化过程 |
| 故意性? | 否 | 代理无法故意尝试构建提示或检索记忆 |
| 编码特异性 | 部分 | 相关性(三个检索标准之一)使用语义相似性,而非编码特异性。 |
生成式代理的开发者没有将其长期记忆描述为情景记忆。然而,这篇论文常被引用 3 { }^{3} 3 为使用LLMs的情景记忆示例。情景记忆是自传性的,是对发生在我身上的事情的记忆。人类情景记忆的具体特征已被充分理解 [44] 并在认知架构中进行了研究和实现 [28]。
将任何情景记忆实现与情景记忆认知设计模式的一般特征进行比较,可以潜在地识别出能力、局限性和进一步探索的机会。表3列出了情景记忆计算实现的具体要求,改编自Nuxoll和Laird [28]。表格还指出生成式代理满足哪些情景记忆特征(以及哪些未满足)。
为进一步突出表中的一个例子,大多数情景记忆概念假设编码特异性原则 [45],该原则(大致)表示情景记忆编码事件的上下文。当检索提示匹配编码上下文时,检索某些过去的事件更有可能:多年未居住的房子可能会唤起关于那所房子的记忆。具体上下文(例如,平面图)被编码在记忆中。再次出现在家中会产生感知提示,这些提示与过去记忆中的编码提示相匹配,从而导致检索。
生成式代理的记忆编码对象,提供一定的特异性,但观察和反思的编码并非完全上下文化。检索反而使用相关性,这依赖于语义相似性,而非
3
{ }^{3}
3 根据Semantic Scholar统计,总引用量超过1,500次。
而是线索特异性。表格对其他相似点和差异也进行了评论。对于ReAct而言,这种分析指出了具体的研究问题,例如探索代理行为是否会改变,如果代理能够故意尝试构建明确的检索线索,或者反思质量是否会随着更敏感的反思触发条件而改变。
3.2 适合探索和利用的模式
在本节中,我们简要讨论两种尚未在代理型LLM主流中采用的认知设计模式:重新考虑和知识编译。详细说明后,这两种模式似乎对当前代理型LLM的缺点作出了回应,因此代表了研究机会。
代理型LLM中的承诺与重新考虑 聊天导向的LLM倾向于抵制其标记生成轨迹的重大重定向。此外,仅依靠LLM产生非单调推理步骤的结果显示了较为混合的结果 [23]。在代理型LLM中,已经开发了各种方法,通常类似于短期记忆,以限制或管理每次LLM查询呈现的上下文 [30],类似于操作系统中的分页。这种方法间接支持了通过忘记/删除过去上下文来重定向。
如前所述,重新考虑是封装了评估先前承诺(如目标或计划)是否应根据代理当前情况继续的认知设计模式。当重新考虑导致承诺变化时,代理推理方向会发生非单调变化。除了总体反思策略(将在下面讨论),在代理型LLM中使用重新考虑意图或承诺可以让代理定期评估其目标的持续可行性和可取性。这一研究方向将增强最近使用代理型LLM进行规划和计划分解的努力,这些努力与承诺过程有一些相似之处 [33, 60]。正如传统代理所做的那样,当代理型LLM做出明确、显式的承诺时,它们还需要决定何时/是否放弃这些承诺。
知识编译 多步推理(更一般地,问题搜索 [19])即使在理论上也可能计算昂贵,甚至是NP完全问题 [4]。知识编译将(可能是多次)推理步骤的结果缓存到更紧凑的表示中,本质上通过在未来的类似情况下立即使用缓存步骤来摊销昂贵推理的成本。已经开发了许多知识编译算法,包括STRIPS中的宏操作学习 [10] 和各种形式的基于解释的学习 [26]。知识编译是ACT-R(生产编译 [42])和Soar(块化 [20])的核心学习算法。
忽略质量和可靠性问题,代理型LLM参与的潜在昂贵问题搜索(即,个体查询-响应步骤)
需要比单独的LLM更多的运行时计算。例如,我们之前审查了ReAct如何将内部和外部问题解决步骤划分为单独的查询-响应交互,从而(至少)加倍查询-响应交互的数量。此外,最近出现了大型推理模型(LRMs),如OpenAI o1和DeepSeek R1,在这些模型中,细粒度、多步推理类似于思维链,在令牌生成中得到强化 [58, 29, 7]。这些新推理模型的运行时推理计算需求显著高于基于聊天的模型。LRMs面临的一个开放挑战是减少其运行时推理成本 [58]。
鉴于这些趋势,知识编译设计模式显然与代理型LLM和LRMs直接相关。将LLM推理编译成另一种形式供后续使用已成为一个活跃的研究领域,作为程序合成的一种特殊情况。例如,Voyager [46] 使用LLM推理构建Minecraft制作配方(作为可执行JavaScript),LLMRG [51] 构建结构化图以总结推荐系统中的用户历史和偏好,Zhu和Reid [66] 描述了从LLM推理生成Soar生产规则。
虽然这些例子说明了将推理编译成另一种形式的价值,但直接在线缓存LLM的自然语言响应尚未成为广泛研究的领域。Voyager生成了其生成功能(技能)的NL摘要。Reflexion [37] 是一个旨在通过LLM介导的反思改进其问题解决策略的系统,它将其反思缓存在内存中以供后续试验使用。这种缓存支持任务内转移,但几乎没有任务间转移。ExpeL [64] 从领域内的初始探索性问题解决痕迹中发展NL见解。ExpeL的见解功能最接近(在我们发现的范围内)知识编译设计模式。然而,见解生成需要一个明确的训练阶段,与ACT-R和Soar中在线使用知识编译解决问题形成鲜明对比。
最后,知识编译假定代理将在未来遇到类似的情况,因此保存潜在昂贵、多步推理的结果是值得的。只要内存大小和检索成本相对较低 [25],这种假设就是合理的。缓解这种效用问题强烈影响了认知架构中知识编译的实现 [25, 43]。随着知识编译在代理型LLM系统中变得越来越普遍,我们可以预期效用问题将出现,并且需要专门的技术和算法来实现知识编译在LLM系统中的常规使用。
3.3 新兴认知设计模式
大多数认知架构规定了固定的、预定义的控制流程。相比之下,LLM计算混合了内容和控制。鉴于这一差异,我们可以预期,通过整合和组合LLM模块以实现代理AI,很可能会出现新型处理模式。
作为一个例子,一种新兴的新型模式是逐步反思。逐步反思旨在提高LLM响应的整体可靠性。最简单的版本提示语言模型评估之前的响应。自我一致性 [50] 是该模式的更复杂实例,它为单个提示生成多个LLM响应。然后,通过反思步骤,它识别出现频率最高(或一致)的响应,并选择其作为原始查询的“最终”答案。
虽然逐步反思在功能上类似于重新考虑和信念修订 [12],但其具体特征是独特的。例如,反思步骤本身可能与初始响应一样不可靠,因此在最坏的情况下可能是递归且无界的。它与自我反思 [34] 对比鲜明,其中外部过程提供反馈,表明先前响应(通常是问题的答案)是错误的。在逐步反思中,LLM被要求在没有外部/神谕反馈的情况下评估正确性和充分性。
最后,逐步反思不同于更熟悉的元认知反思,例如Soar的回顾 [27] 或Reflexion [37],这是对之前概述的ReAct的扩展。在元认知反思中,代理反思许多问题解决步骤,包括与环境的交互,以获得额外的知识(如概括或校正)。总之,逐步反思似乎是通过独特方式整合和组合其他模式的新型模式,这种需求推动了对LLM驱动推理的持续和精细(逐步)评估。
4 结论
我们提出了认知设计模式作为一种强大的分析工具,用于组织和理解代理型LLM系统的爆炸性研究。认知设计模式封装了在研究和开发代理/认知架构过程中反复出现的高级过程、表示和记忆描述,这些研究和开发受到AGI目标的激励。通过使用这些模式分析代理型LLM系统,我们识别出现有方法的潜在局限性,并预测特定扩展/细化方法(受认知设计模式指导)将减轻这些局限性。
长期来看,我们将认知设计模式视为补充其他方法的一种手段,这些方法试图对通用智能方法的共性进行编码,例如认知共同模型 [18]。认知设计模式代表了一种功能驱动的方法,用于组织认知功能,无论这些模式是否代表或与人类认知相关。我们预计,这样的方法可以代表一种新兴的比较认知架构学科。跨架构范式的分析、理解和建立进展一直是AGI更快发展的障碍。我们认为,分析、比较和整合方法作为一种伴随现有架构实现研究的补充,具有加速探索和实现通用人工智能代理的潜力。
参考文献
- Anderson, J.R., Bothell, D., Byrne, M.D., Douglass, S., Lebiere, C., Qin, Y.: An integrated theory of the mind. Psychological review 111(4), 1036 (2004)
-
- Besta, M., Blach, N., Kubicek, A., Gerstenberger, R., Podstawski, M., Gianinazzi, L., Gajda, J., Lehmann, T., Niewiadomski, H., Nyczyk, P., Hoefler, T.: Graph of Thoughts: Solving Elaborate Problems with Large Language Models. In: Proc. of 38th Annual AAAI Conference on Artificial Intelligence. AAAI Press, Vancouver (Feb 2024)
-
- Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y.T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M.T., Zhang, Y.: Sparks of Artificial General Intelligence: Early experiments with GPT-4 (Apr 2023), http://arxiv.org/abs/2303.12712, arXiv:2303.12712 [cs]
-
- Bylander, T.: Complexity results for planning. In: Proceedings of the 12th international joint conference on Artificial intelligence - Volume 1. pp. 274-279. IJCAI’91, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (Aug 1991)
-
- Cohen, M.A., Ritter, F.E., Haynes, S.R.: Herbal: A high-level language and development environment for developing cognitive models in Soar. In: 14th Conference on Behavior Representation in Modeling and Simulation 2005. pp. 231-236. Simulation Interoperability Standards Organization (Dec 2005)
-
- Crossman, J., Wray, R.E., Jones, R.M., Lebiere, C.: A High Level Symbolic Representation for Behavior Modeling. In: Gluck, K. (ed.) Proceedings of 2004 Behavior Representation in Modeling and Simulation Conference. Arlington, VA (2004)
-
- DeepSeek-AI: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Jan 2025), http://arxiv.org/abs/2501.12948, arXiv:2501.12948 [cs]
-
- Dong, Y., Jiang, X., Jin, Z., Li, G.: Self-Collaboration Code Generation via ChatGPT. ACM Trans. Softw. Eng. Methodol. 33(7), 189:1-189:38 (Sep 2024)
-
- Doyle, J.: A truth maintenance system. Artificial Intelligence 12, 231-272 (1979)
10.10. Fikes, R.E., Hart, P.E., Nilsson, N.J.: Learning and executing generalized robot plans. Artificial Intelligence 3, 251-288 (Jan 1972)
- Doyle, J.: A truth maintenance system. Artificial Intelligence 12, 231-272 (1979)
- Gao, J., Ding, X., Cui, Y., Zhao, J., Wang, H., Liu, T., Qin, B.: Self-Evolving GPT: A Lifelong Autonomous Experiential Learner. In: Proc. of ACL 2024 (2024)
-
- Gärdenfors, P.: Knowledge in Flux. MIT Press, Cambridge, MA (1988)
-
- Jones, R., Wray, R.E.: Comparative Analysis of Frameworks for KnowledgeIntensive Intelligent Agents. AI Magazine 27(2), 57-70 (2006)
-
- Kambhampati, S., Valmeekam, K., Guan, L., Verma, M., Stechly, K., Bhambri, S., Saldyt, L.P., Murthy, A.B.: Position: LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks. In: PMLR Vol 235: 41st International Conf. on Machine Learning. vol. 235, pp. 22895-22907. Vienna (2024)
-
- Kotseruba, I., Tsotsos, J.K.: 40 years of cognitive architectures: Core cognitive abilities and practical applications. Artificial Intelligence Review 53(1), 17-94 (2020)
-
- Laird, J.E.: The Soar Cognitive Architecture. MIT Press, Cambridge, MA (2012)
-
- Laird, J.E., Lebiere, C., Reitter, D., Rosenbloom, P.S., Stocco, A. (eds.): Proc. of 2023 AAAI Fall Symposia: Integration of Cognitive Architectures and Generative Models. AAAI Fall Symposium Series, AAAI Press, Washington, DC. (2023)
-
- Laird, J.E., Lebiere, C., Rosenbloom, P.S.: A Standard Model of the Mind: Toward a Common Computational Framework across Artificial Intelligence, Cognitive Science, Neuroscience, and Robotics. AI Magazine 38(4), 13-26 (2017)
-
- Laird, J.E., Newell, A.: A universal weak method. In: Rosenbloom, P.S., Laird, J.E., Newell, A. (eds.) The Soar Papers: Research on Integrated Intelligence, vol. 1, pp. 245-292. MIT Press, Cambridge, MA (1983)
-
- Laird, J.E., Rosenbloom, P.S., Newell, A.: Chunking in Soar: The anatomy of a general learning mechanism. Machine Learning 1(1), 11-46 (1986)
-
- LangChain: LangGraph (2025), https://langchain-ai.github.io/langgraph/
-
- Lawless, C., Schoeffer, J., Le, L., Rowan, K., Sen, S., St. Hill, C., Suh, J., Sarrafzadeh, B.: “I Want It That Way”: Enabling Interactive Decision Support Using Large Language Models and Constraint Programming. ACM Trans. Interact. Intell. Syst. 14(3), 22:1-22:33 (Sep 2024)
-
- Leidinger, A., Van Rooij, R., Shutova, E.: Are LLMs classical or nonmonotonic reasoners? Lessons from generics. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). pp. 558-573. Association for Computational Linguistics, Bangkok, Thailand (Aug 2024)
-
- Luo, J., Zhang, W., Yuan, Y., Zhao, Y., Yang, J., Gu, Y., Wu, B., Chen, B., Qiao, Z., Long, Q., Tu, R., Luo, X., Ju, W., Xiao, Z., Wang, Y., Xiao, M., Liu, C., Yuan, J., Zhang, S., Jin, Y., Zhang, F., Wu, X., Zhao, H., Tao, D., Yu, P.S., Zhang, M.: Large Language Model Agent: A Survey on Methodology, Applications and Challenges (Mar 2025), http://arxiv.org/abs/2503.21460, arXiv:2503.21460 [cs]
-
- Minton, S.: Quantitative results concerning the utility of explanation-based learning. Artificial Intelligence 42(2), 363-391 (Mar 1990)
-
- Mitchell, T.M., Keller, R.M., Kedar-Cabelli, S.V.: Explanation-based learning: A unifying view. Machine Learning 1(1), 47-80 (1986)
-
- Mohan, S., Laird, J.E.: Learning Goal-Oriented Hierarchical Tasks from Situated Interactive Instruction. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 28, pp. 387-394. AAAI Press (2014)
-
- Nuxoll, A.M., Laird, J.E.: Enhancing intelligent agents with episodic memory. Cognitive Systems Research 17-18, 34-48 (Jul 2012)
-
- OpenAI: OpenAI o1 System Card (Dec 2024), http://arxiv.org/abs/2412.16720, arXiv:2412.16720 [cs]
-
- Packer, C., Wooders, S., Lin, K., Fang, V., Patil, S.G., Stoica, I., Gonzalez, J.E.: MemGPT: Towards LLMs as Operating Systems (Feb 2024), http://arxiv.org/abs/2310.08560, arXiv:2310.08560 [cs]
-
- Park, J.S., O’Brien, J.C., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative Agents: Interactive Simulacra of Human Behavior. In: Proceedings of 2023 ACM Symposium on User Interface Software and Technology (UIST). pp. 1-22. Association for Computing Machinery, San Francisco (Apr 2023)
-
- Pink, M., Wu, Q., Vo, V.A., Turek, J., Mu, J., Huth, A., Toneva, M.: Position: Episodic Memory is the Missing Piece for Long-Term LLM Agents (Feb 2025), http://arxiv.org/abs/2502.06975, arXiv:2502.06975 [cs]
-
- Prasad, A., Koller, A., Hartmann, M., Clark, P., Sabharwal, A., Bansal, M., Khot, T.: ADaPT: As-Needed Decomposition and Planning with Language Models. In: Duh, K., Gomez, H., Bethard, S. (eds.) Findings of the Association for Computational Linguistics: NAACL 2024. pp. 4226-4252. Association for Computational Linguistics, Mexico City, Mexico (Jun 2024)
-
- Renze, M., Guven, E.: Self-Reflection in LLM Agents: Effects on Problem-Solving Performance. In: 2024 2nd International Conference on Foundation and Large Language Models (FLLM). pp. 476-483. Dubai (Nov 2024)
-
- Schut, M., Wooldridge, M., Parsons, S.: The theory and practice of intention reconsideration. Journal of Experimental & Theoretical Artificial Intelligence 16(4), 261-293 (Oct 2004)
-
- Shao, Y., Jiang, Y., Kanell, T.A., Xu, P., Khattab, O., Lam, M.S.: Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models. In: Proc. of 2024 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6252-6278. ACL, Mexico City (2024)
-
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Language Agents with Verbal Reinforcement Learning. In: 37th Conference on Neural Information Processing Systems (Mar 2023)
-
- Silva, L.d., Meneguzzi, F., Logan, B.: BDI Agent Architectures: A Survey. In: Twenty-Ninth International Joint Conference on Artificial Intelligence. vol. 5, pp. 4914-4921. Yokohama/Virtual (Jul 2020)
-
- Singh, I., Blukis, V., Mousavian, A., Goyal, A., Xu, D., Tremblay, J., Fox, D., Thomason, J., Garg, A.: ProgPrompt: program generation for situated robot task planning using large language models. Autonomous Robots (Aug 2023)
-
- Sumers, T.R., Yao, S., Narasimhan, K., Griffiths, T.L.: Cognitive Architectures for Language Agents. Transactions on Machine Learning Research 2835-8856 (2023)
-
- Sypherd, C., Belle, V.: Practical Considerations for Agentic LLM Systems (Dec 2024), http://arxiv.org/abs/2412.04093, arXiv:2412.04093 [cs]
-
- Taatgen, N.A., Lee, F.J.: Production compilation: A simple mechanism to model complex skill acquisition. Human Factors: The Journal of the Human Factors and Ergonomics Society 45(1), 61-76 (2003)
-
- Tambe, M., Newell, A., Rosenbloom, P.S.: The problem of expensive chunks and its solution by restricting expressiveness. Machine Learning 5, 299-348 (1990)
-
- Tulving, E.: Elements of Episodic Memory. Oxford University Press (1983)
-
- Tulving, E., Thomson, D.M.: Encoding specificity and retrieval processes in episodic memory. Psychological Review 80(5), 352-373 (1973)
-
- Wang, G., Xie, Y., Jiang, Y., Mandlekar, A., Xiao, C., Zhu, Y., Fan, L., Anandkumar, A.: Voyager: An Open-Ended Embodied Agent with Large Language Models. Transactions on Machine Learning Research (2024)
-
- Wang, P., Li, Z., Zhang, N., Xu, Z., Yao, Y., Jiang, Y., Xie, P., Huang, F., Chen, H.: WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models. In: Advances in Neural Information Processing Systems. vol. 37, pp. 53764-53797. Vancouver (Dec 2024)
-
- Wang, R., Jansen, P., Côté, M.A., Ammanabrolu, P.: ScienceWorld: Is your Agent Smarter than a 5th Grader? In: EMNLP 2022. arXiv (Nov 2022)
-
- Wang, W., Dong, L., Cheng, H., Liu, X., Yan, X., Gao, J., Wei, F.: Augmenting language models with long-term memory. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. pp. 74530-74543. NIPS '23, Curran Associates Inc., Red Hook, NY, USA (Dec 2023)
-
- Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-Consistency Improves Chain of Thought Reasoning in Language Models. In: ICLR 2023. arXiv (Mar 2023)
-
- Wang, Y., Chu, Z., Ouyang, X., Wang, S., Hao, H., Shen, Y., Gu, J., Xue, S., Zhang, J., Cui, Q., Li, L., Zhou, J., Li, S.: LLMRG: Improving Recommendations through Large Language Model Reasoning Graphs. Proceedings of the AAAI Conference on Artificial Intelligence 38(17), 19189-19196 (Mar 2024)
-
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q.V., Zhou, D.: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In: NeurIPS 2022. vol. 35, pp. 24824-24837 (2022)
-
- Wooldridge, M.J.: Reasoning about Rational Agents. MIT Press, Cambridge, MA (2000)
-
- Wray, R.E., Laird, J.E.: An architectural approach to consistency in hierarchical execution. Journal of Artificial Intelligence Research 19, 355-398 (2003)
-
- Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E.E., Jiang, L., Zhang, X., Zhang, S., Awadallah, A., White, R.W., Burger, D., Wang, C.: AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. In: Proceedings of the Conference on Language Modeling 2024. Philadelphia (Aug 2024)
-
- Wu, Y., Liang, S., Zhang, C., Wang, Y., Zhang, Y., Guo, H., Tang, R., Liu, Y.: From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs (Apr 2025), http://arxiv.org/abs/2504.15965, arXiv:2504.15965 [cs]
-
- Wu, Y., Hu, Z.: LLMs Are Not Good Strategists, Yet Memory-Enhanced Agency Boosts Reasoning. In: ICLR 2025 Workshops: Reasoning and Planning for LLMs. Singapore (Mar 2025)
-
- Xu, F., Hao, Q., Zong, Z., Wang, J., Zhang, Y., Wang, J., Lan, X., Gong, J., Ouyang, T., Meng, F., Shao, C., Yan, Y., Yang, Q., Song, Y., Ren, S., Hu, X., Li, Y., Feng, J., Gao, C., Li, Y.: Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models (Jan 2025), http://arxiv.org/abs/2501.09686, arXiv:2501.09686 [cs]
-
- Xu, W., Liang, Z., Mei, K., Gao, H., Tan, J., Zhang, Y.: A-MEM: Agentic Memory for LLM Agents (Feb 2025), http://arxiv.org/abs/2502.12110, arXiv:2502.12110 [cs]
-
- Xue, S., Huang, Z., Liu, J., Lin, X., Ning, Y., Jin, B., Li, X., Liu, Q.: Decompose, Analyze and Rethink: Solving Intricate Problems with Human-like Reasoning Cycle. In: Advances in Neural Information Processing Systems. vol. 37, pp. 357-385 (Dec 2024)
-
- Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T.L., Cao, Y., Narasimhan, K.: Tree of Thoughts: Deliberate Problem Solving with Large Language Models (May 2023), http://arxiv.org/abs/2305.10601, arXiv:2305.10601 [cs]
-
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: ReAct: Synergizing Reasoning and Acting in Language Models. In: The Eleventh International Conference on Learning Representations, ICLR 2023. Kigali, Rwanda (2023)
-
- Zaharia, M., Khattab, O., Chen, L., Davis, J.Q., Miller, H., Potts, C., Zou, J., Carbin, M., Frankle, J., Rao, N., Ghodsi, A.: The Shift from Models to Compound AI Systems (Feb 2024), http://bair.berkeley.edu/blog/2024/02/18/compound-aisystems/
-
- Zhao, A., Huang, D., Xu, Q., Lin, M., Liu, Y.J., Huang, G.: ExpeL: LLM Agents Are Experiential Learners. Proceedings of the AAAI Conference on Artificial Intelligence 38(17), 19632-19642 (Mar 2024)
-
- Zhong, W., Guo, L., Gao, Q., Ye, H., Wang, Y.: MemoryBank: Enhancing Large Language Models with Long-Term Memory. Proceedings of the AAAI Conference on Artificial Intelligence 38(17), 19724-19731 (Mar 2024)
-
- Zhu, F., Simmons, R.: Bootstrapping Cognitive Agents with a Large Language Model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 655-663. AAAI Press, Vancouver (Mar 2024)
参考论文:https://arxiv.org/pdf/2505.07087
- Zhu, F., Simmons, R.: Bootstrapping Cognitive Agents with a Large Language Model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 655-663. AAAI Press, Vancouver (Mar 2024)


















 3340
3340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











