







Classification
分类是机器学习中另外一类非常重要的类别,如:

对邮件分类,如有用的邮件和垃圾邮件;在线购物的用户是否存在欺诈行为;病人是否有肿瘤。所有在现实的世界有很多的分类,或者说是选择。
分类又分为二分类和多分类的问题。

在图中是一个二分类的问题。其中 0 表示负类 , 一般表示缺少某些东西,例如在肿瘤分类中表示病人没有肿瘤。
1 表示正类 , 在肿瘤分类中表示病人有肿瘤。
在二分类中只有两种选择,还可以在每个有限集合中选择其中一种,就是多分类问题。
在linear regression 中拟合函数不能很好的用于分类问题,原因是在遇到一个有偏差的数据集时,它不能很好的对数据样本进行分类。

如图当没有最右边的样本时,线性回归拟合的是粉色的线,如果添加右边的样本,回归曲线变成了蓝色的线。
可以看到遇到有偏差的数据集合时,线性回归不能很好对数据进行分类。
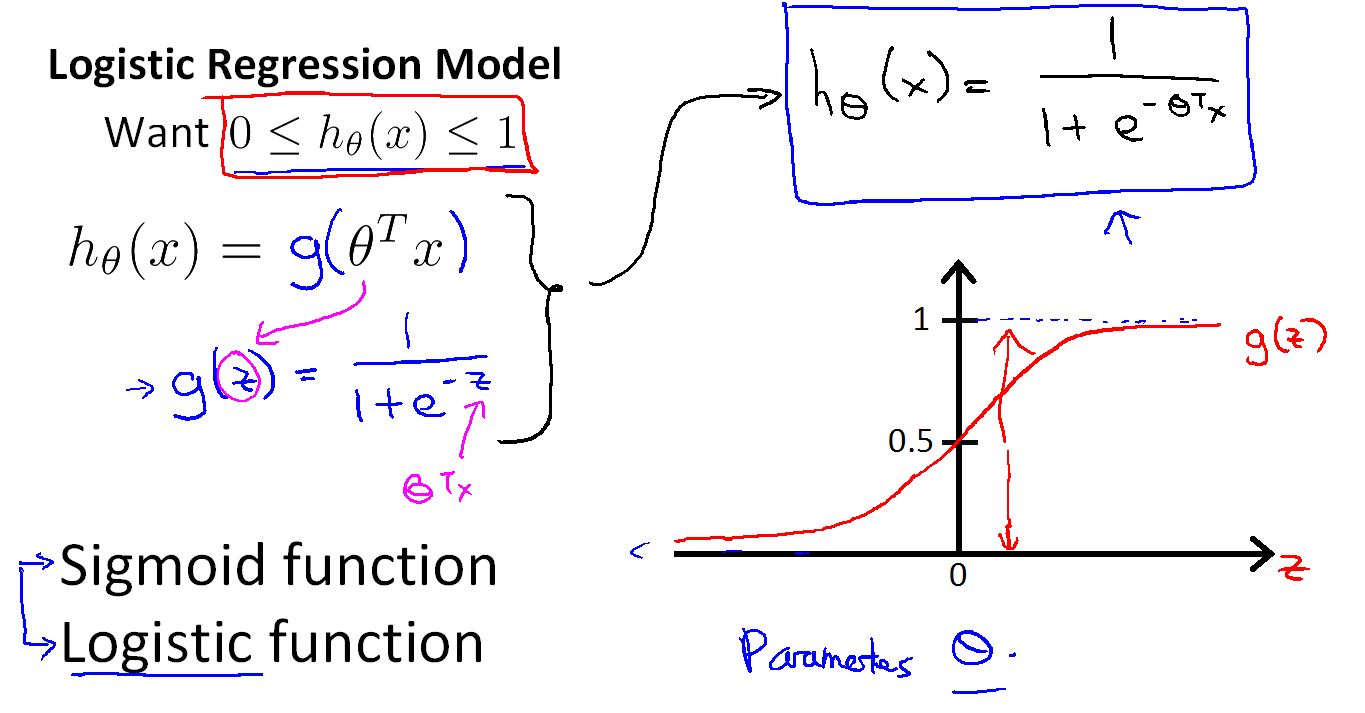
在分类中希望输出在0 - 1 之间。这里用一个Sigmoid function。
logistic 中假设函数的含义

h(x) 输出值表示在新样本 x 对 y=1(正类)的概率的估计值。
在例子中 h(x) = 0.7 表示特征为x的病人得肿瘤(y = 1)的概率是 0.7 (一般的表示,也可以反过来)。
Decision boundary(决策边界)
决策边界不是数据集的特性,而是函数的一个特性,一个函数会把空间分成两部分,分别是 h(x) > 0 的部分和h(x) < 0 的部分。
Logistic Regresion 就是找出这些参数 Theta 确定这个决策边界。
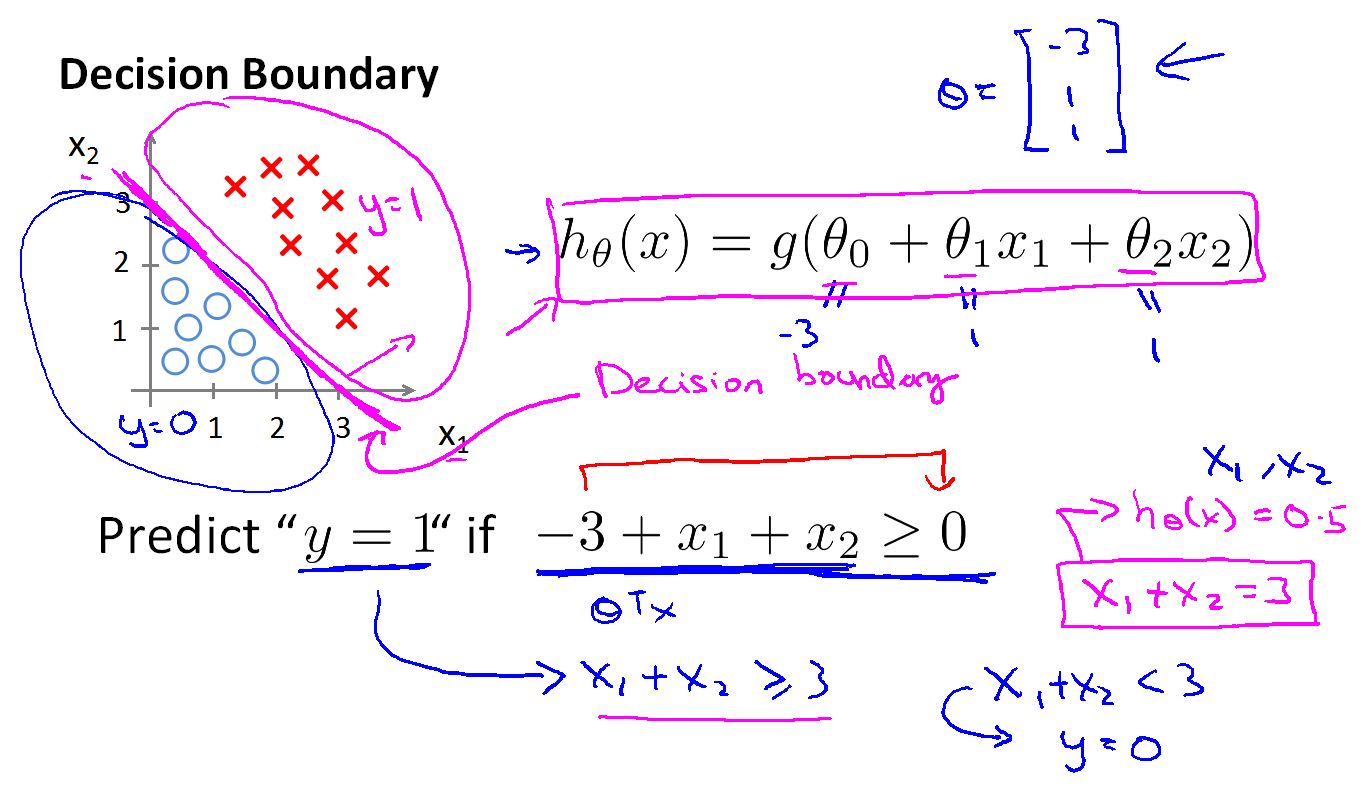
可以说在机器学习中,数据集决定theta ,theta决定决策边界。
Cost Function
在逻辑回归中拟合曲线:
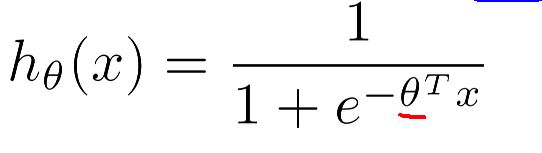
代价函数是

当y=1时,如果h(x)预测的也是1 那么代价函数 Cost = 0
但是如果 h(x) 预测的有错误,那Cost > 0
如果h(x) 预测为 0 ,那Cost 会接近无穷。
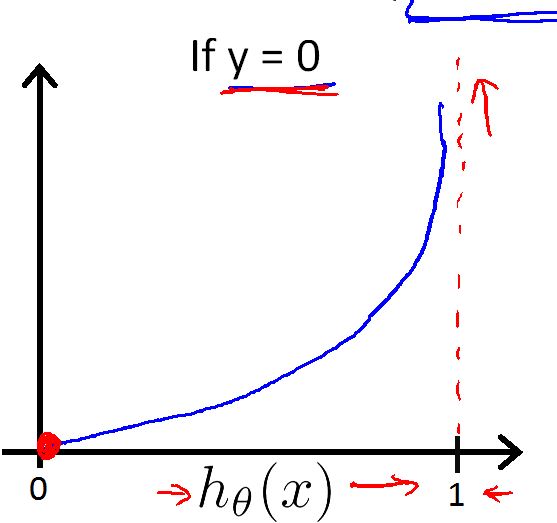
这是在y=0 时 Cost 的函数。
Simplified cost function and gradient descent
为了计算方便把Cost 函数合并成一个
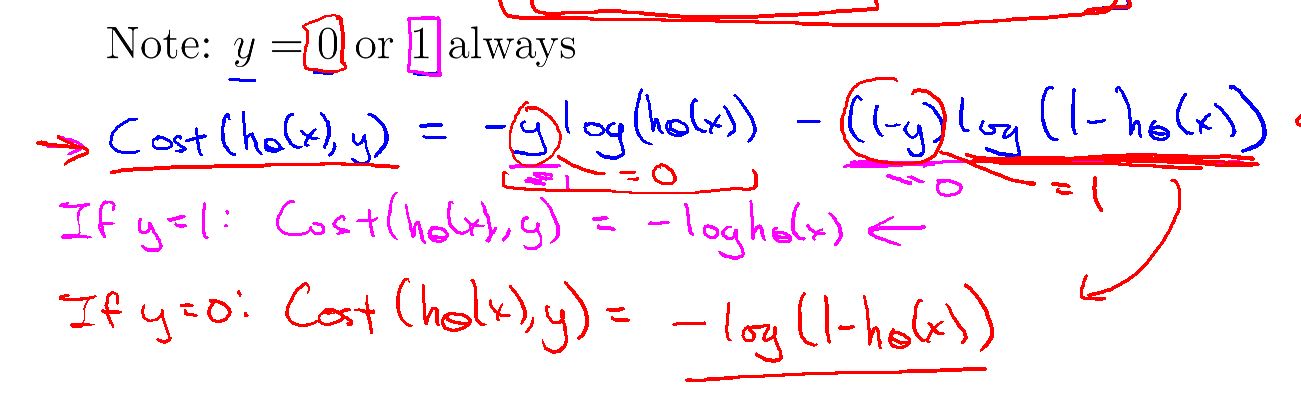
J(θ) 写成
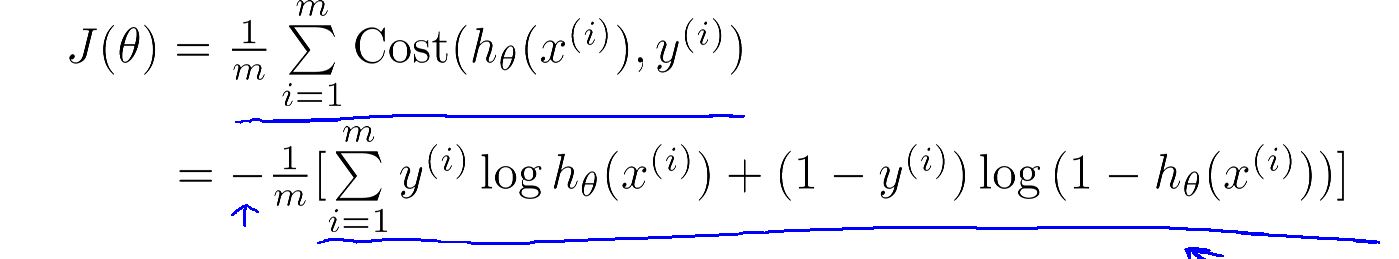
要等到 parameters θ只有最小化 J(θ) 就好。
在这里用梯度下降


梯度下降和linear regression 中的很像,但有区别,把h(x)替换成
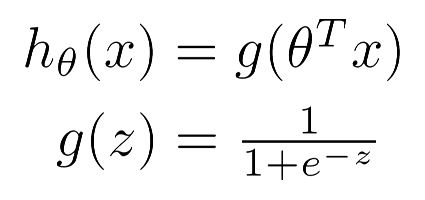
在计算函数的参数时,除了梯度下降外的其他方法

Multi-class classification
多分类问题
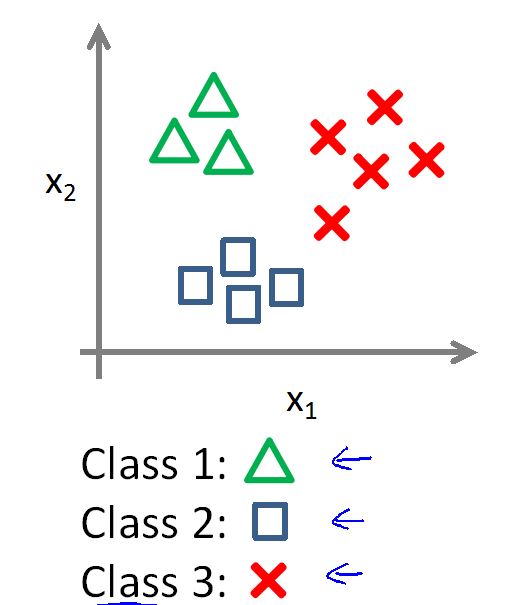
如上是一个三分类问题。
多分类问题有两种解决办法:
一种是 One VS All
就是把其一个类别当成二分类中一类,其他的类别当成二分类中另一个类别。
然后训练出多个不同的分类器。当有一个新的样本时,把它输入到所有的分类器中然后选择的估计值最大的一个。
但是,这种方法有一个缺点,就是,用一个类别对其他的所有的类别,在每次训练分类器时都用一个有偏差的训练集,有时也会面对在Linear regression 遇到偏差训练集时面对的问题。
另一种是 One VS One
就是把训练集中一种类别当成是二分类中的一个类别,选另一个类别当成二分类中的另一种类别。循环进行,训练多个分类器,当遇到新样本时,输入所有的分类器,然后让这些分类器进行投票,得票最多的类别,就是样本的类别。
这种方法可以克服 一对多 面对的问题,但这种方法训练的分类器要比第一种多,当遇到大样本集时,训练时间会是一个问题。















 4122
4122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









