







Logistic regression 的不足
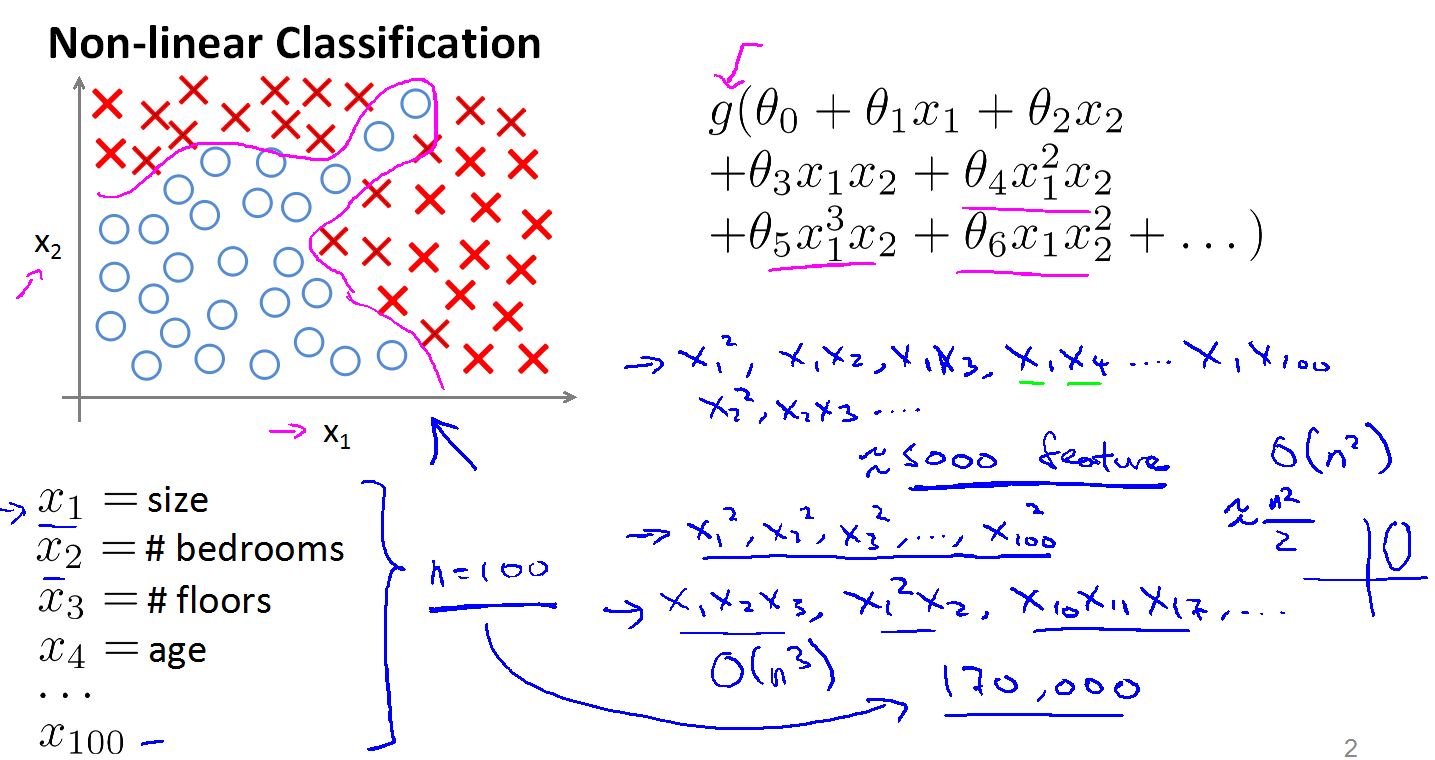
Logistic regression 进行分类时,如果数据是线性可分的数据集
Logistic会工作的很好。但是当我们遇到如图所示的数据集时,无法用线性分类器将其分开。我们可以使用高次分类器,问题来了。假设我们的数据集的每个样本有N = 100 个特征,那么二次特征就有大于5000个,三次特征就有大约17000个,如果用这么多的特征去训练分类器,无论是训练的时间还是物理硬件都会是个挑战,这里我们假设N=100。
在计算机视觉中,单个样本的特征可能就有数万个甚至数十万个,如果还用Logistic 来拟合高次曲线对样本进行分类是很不现实的。

如上图我们要让计算机来识别这张图片是不是汽车,首先我们要提取图片的特征,然后输入一个学习模型,学习一个分类器。这张图片在我们人类看来是张二维的图像,计算机并不这么认为,在它看来图片就是一大堆的数字组成的数组(其中,每个数字表示一个像素的强度值)。例如我们把车门的把手放大会看到一个数组矩阵。
即使我们只是从每张图提取一个50x50 像素的小图片作为特征,每个像素假设只保存了灰度值(0 ~ 255之间)那么你个小图片的特征数为 2500 。如果计算二次特征大约有300万,用这么大的特征去拟合曲线,显然是不现实的。如果用彩色图片那么特征空间要比现在大更多。
Neural NetWorks
神经网络是人们想用计算机模拟大脑的工作方式,为解决不同机器学习问题提供统一的方法而设计。神经网络的主要缺点就是计算量比较大,但对于现在的计算机,这已经不是问题,相比与Logistic 高次拟合带来的超大特征集,神经网络可以用一次特征通过构造多层网络最后得出一个非线性分类器。

神经网络的逻辑单元(我们可以把它看成是大脑的一个神经元)。其中X0表示偏置神经元,设计神经网络结构时,可以画,也可以不画(要看它是否有用)。
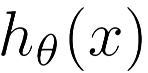
也就是说,一个逻辑单元是一个有个S型函数或逻辑函数作为激励函数的人工神经元。
神经网络示意图:
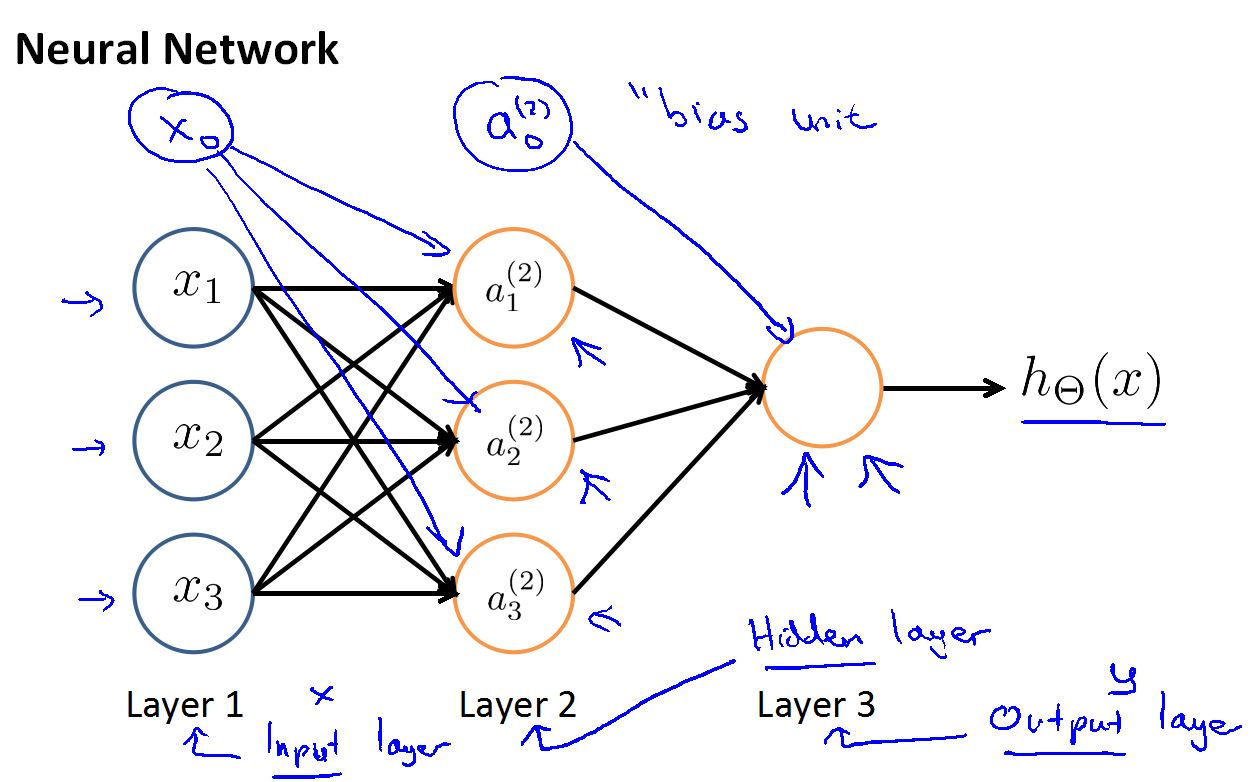
这是一个简单的神经网络,用它来说明一下神经网络的基本结构。
首先是特征输入层是Input Layer 这里也叫Layer1
输出最后结果的层是Output Layer 这里也叫Layer3
中间的层是Hidder Layer(隐藏层) 这里是Layer2
其中,Input Layer 和 Output Layer 只有一层,分别是第一层和最后一层,Hidder Layer 可以有很多层。
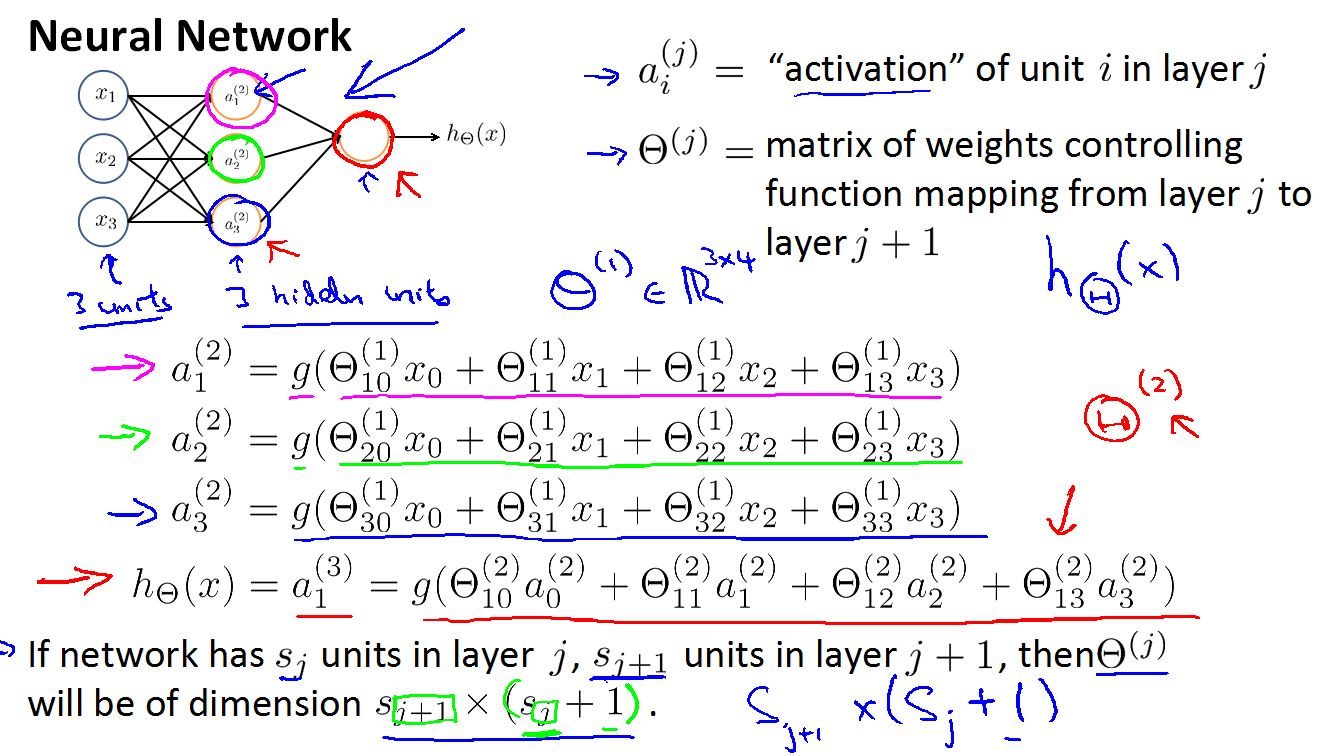
在神经网络中我们用
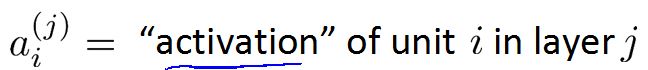
表示在第j层的第i个神经元/激励单元。
例如: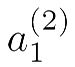
表示第二层的第一个激励(即隐藏层的第一个激励)
激励是由一个具体的神经元输出的值。
括号里的2表示,第二层的意思。下标1表示,第一个激励的意思。
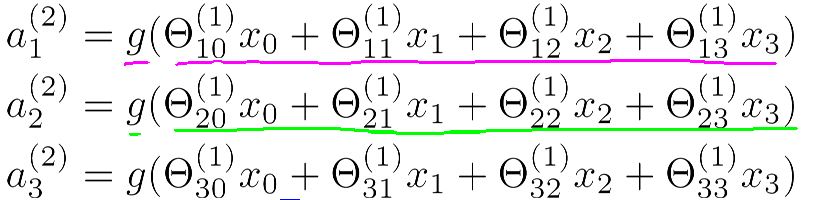
隐藏层的值等于S激励函数作用于输入的线性组合上的结果。

表示一个权重矩阵,控制从第j层到第j+1层的映射。
假设s(j)个单元在j层,s(j+1) 个单元在j+1 层,权重矩阵的维度是s(j+1) x ( s(j) + 1 ) .
在上列中我们有三个输入单元和三个隐藏单元。
而且从第一层到第二层的控制矩阵Θ(1)的维度是3X4 ,这是因为第一层含有x0特征。
Vectorized
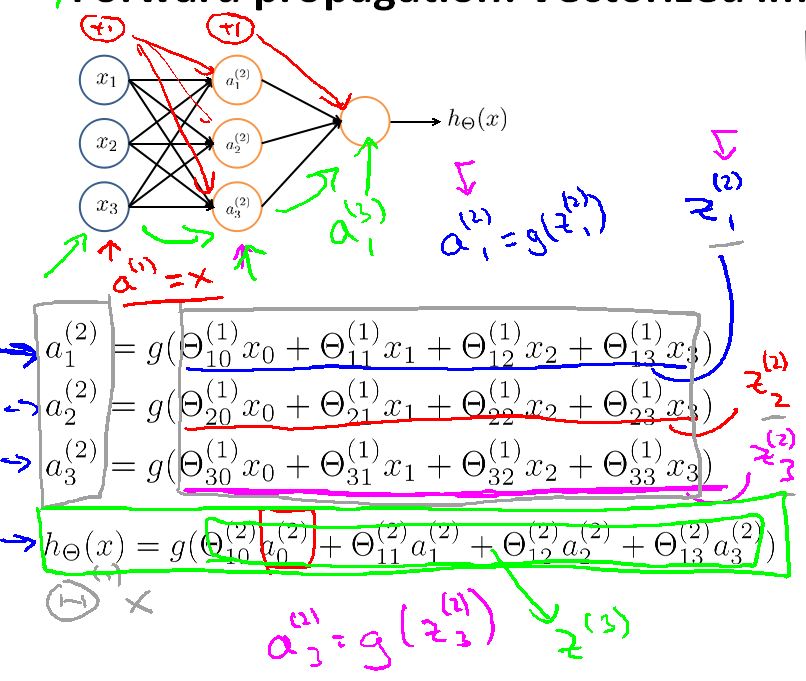
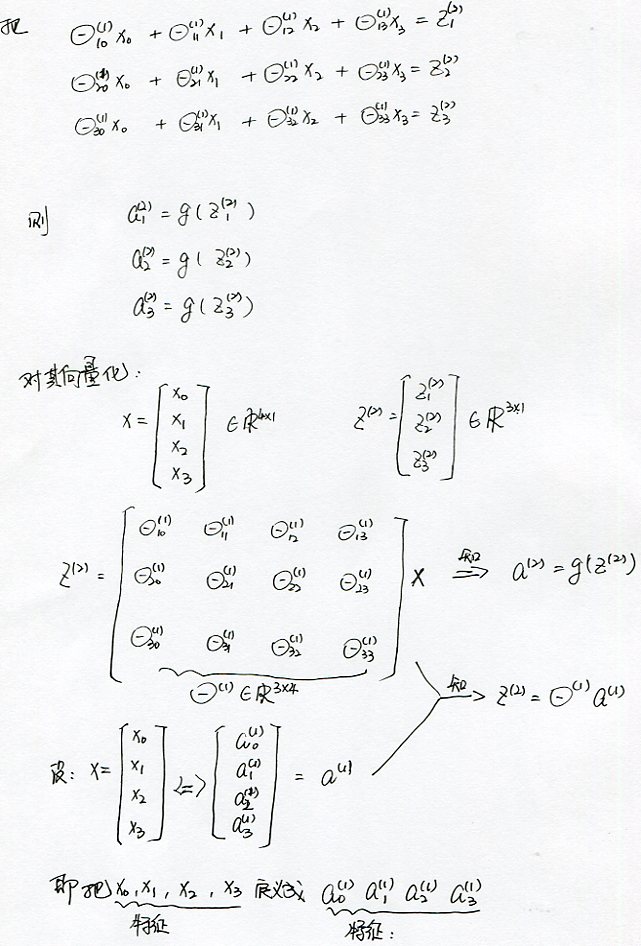
然后得到向量化的运算方法

由于网络的计算是从输入层一直到输出层这样一层一层的计算,所有也叫前向传播网络(forward propagation)
Neural Networks 实现非线性分类的例子
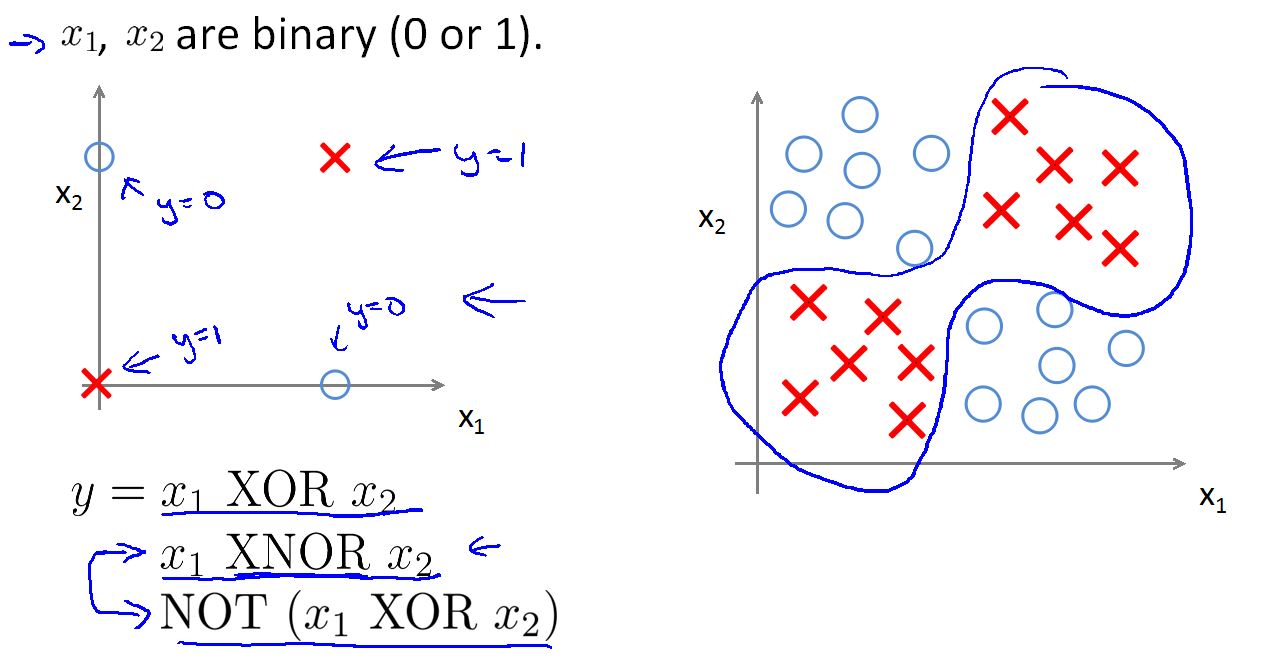
如上是一个非线性的数据集。无法用一个线性分类器完美的将数据分开。观测数据我们发现两个特征接近为叉叉,两个特征差异大为圈圈。
为了完美的将数据集分开这里我们用多个线性分类器组合和一个非线性分类器。
首先是AND分类器模型:
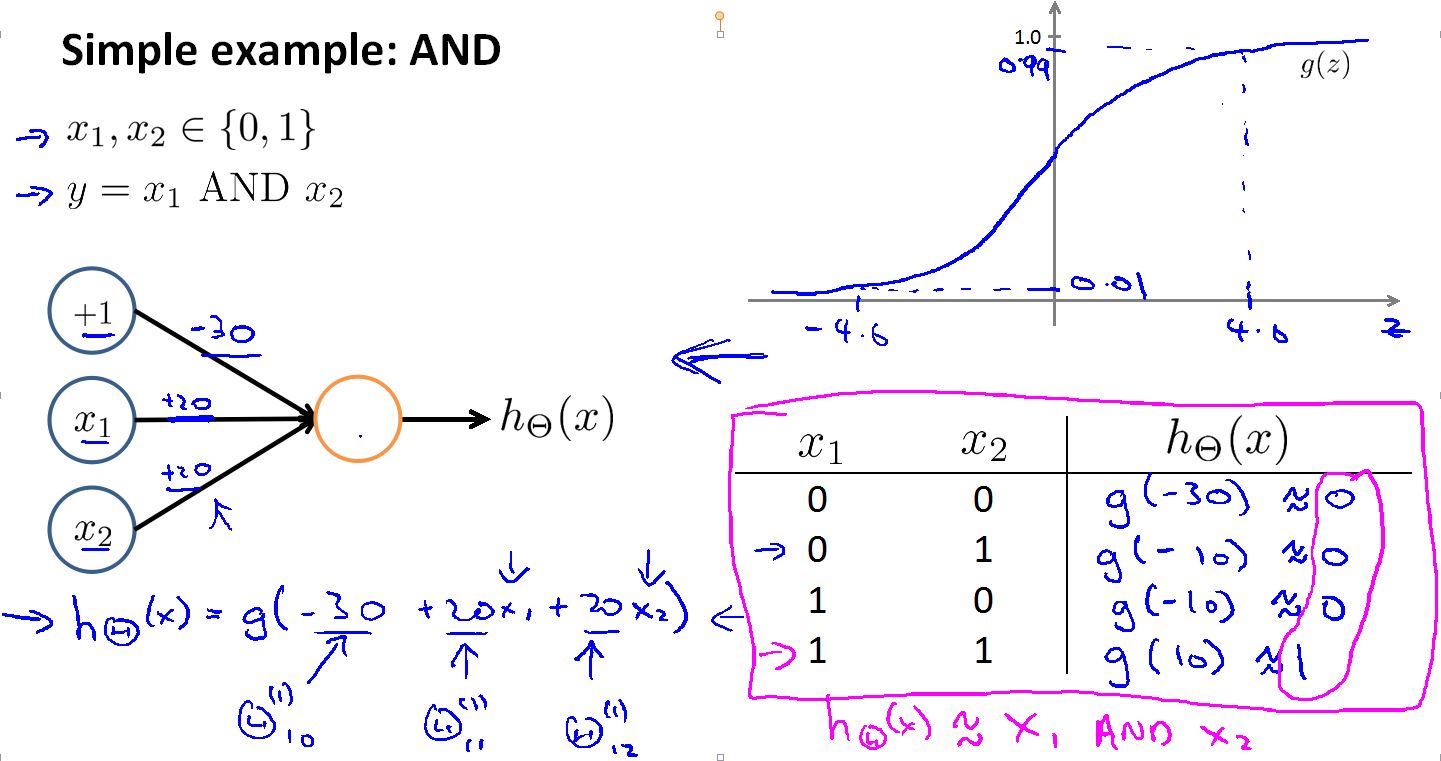
我们可以看到训练出的h(x) 只有在X1 X2都是1 时才输出1.
接下来是OR分类器模型:

然后是求反分类器模型:
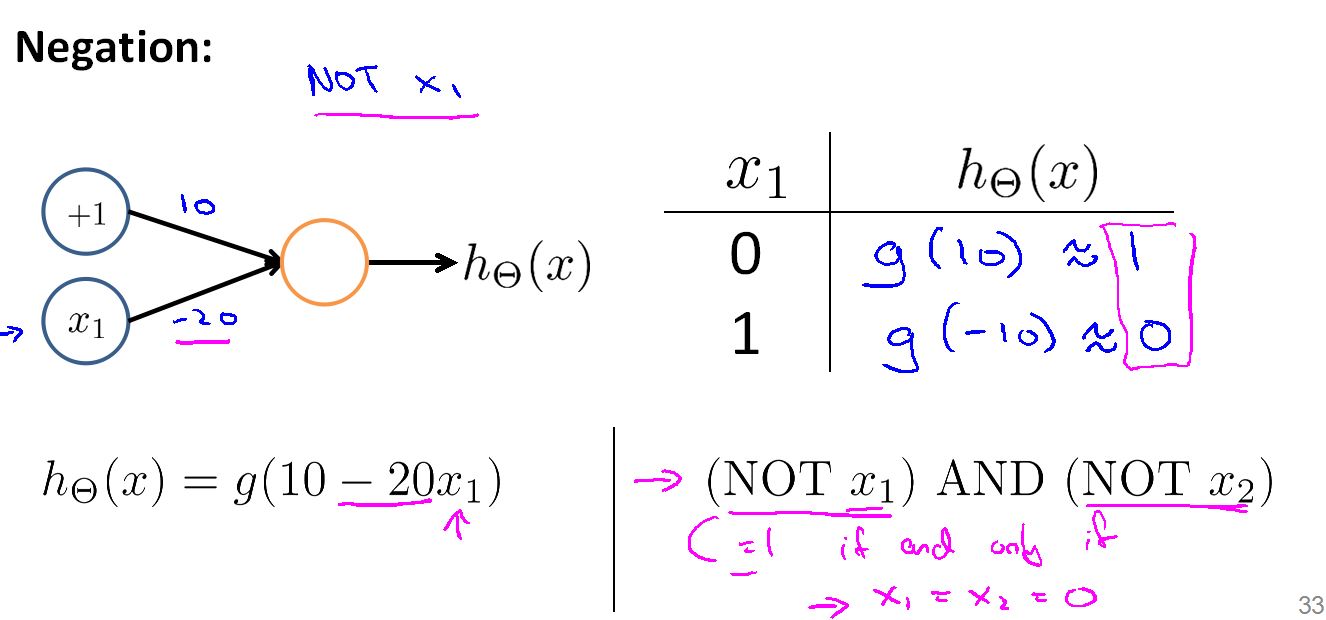
构建最终的分类模型:
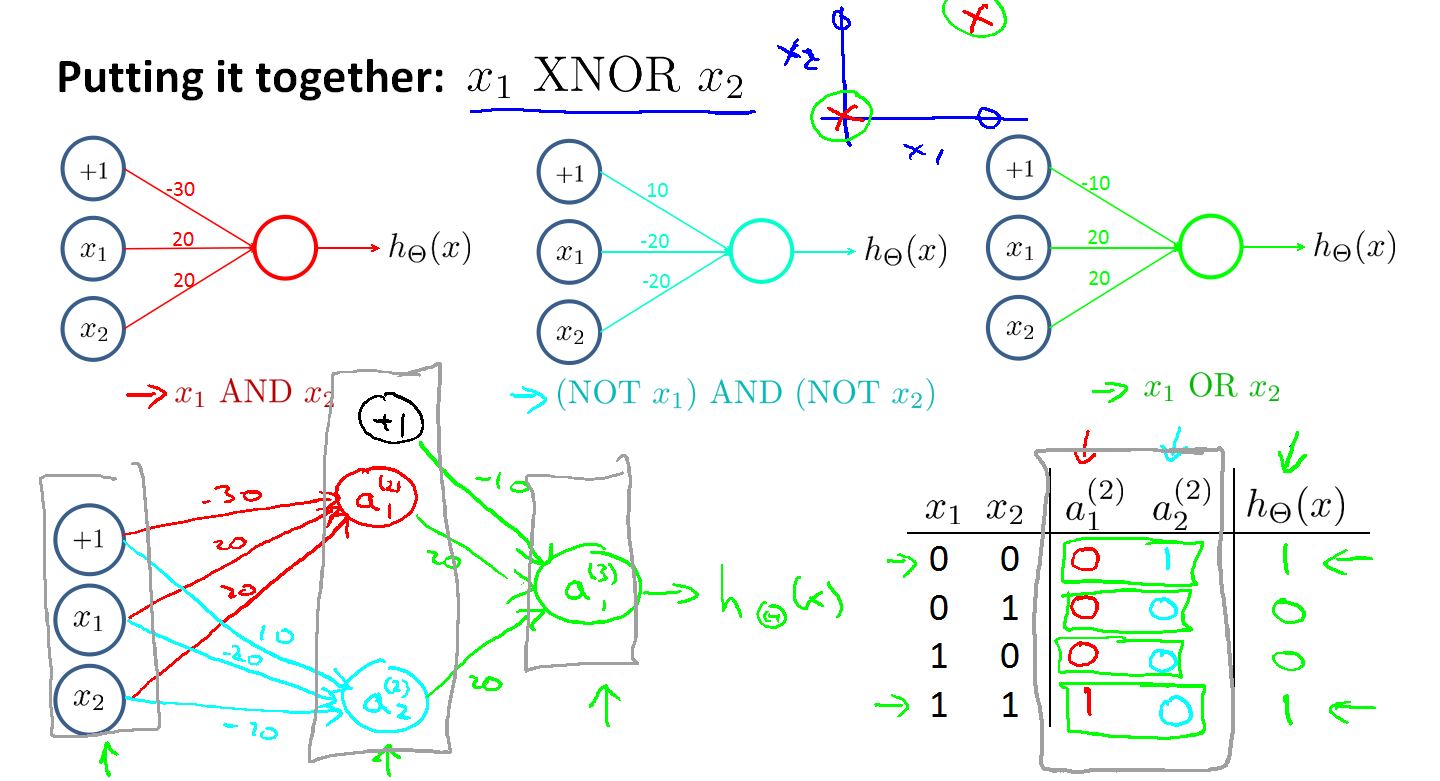
红色是AND分类器,浅蓝色是(NOT x1)AND(NOT x2)分类器,绿色是OR分类器。
右下角的表格可以看到x1 x2 一样时,输出为1 。不同时 , 输出为0.
透过例子,直觉告诉我们在隐藏层运用一些特殊的处理函数可以得到一个更强大的输出函数。我们可以看到如果单看每一层网络都是线性的,组合起来输出是非线性的。
关于构建多分类的神经网络
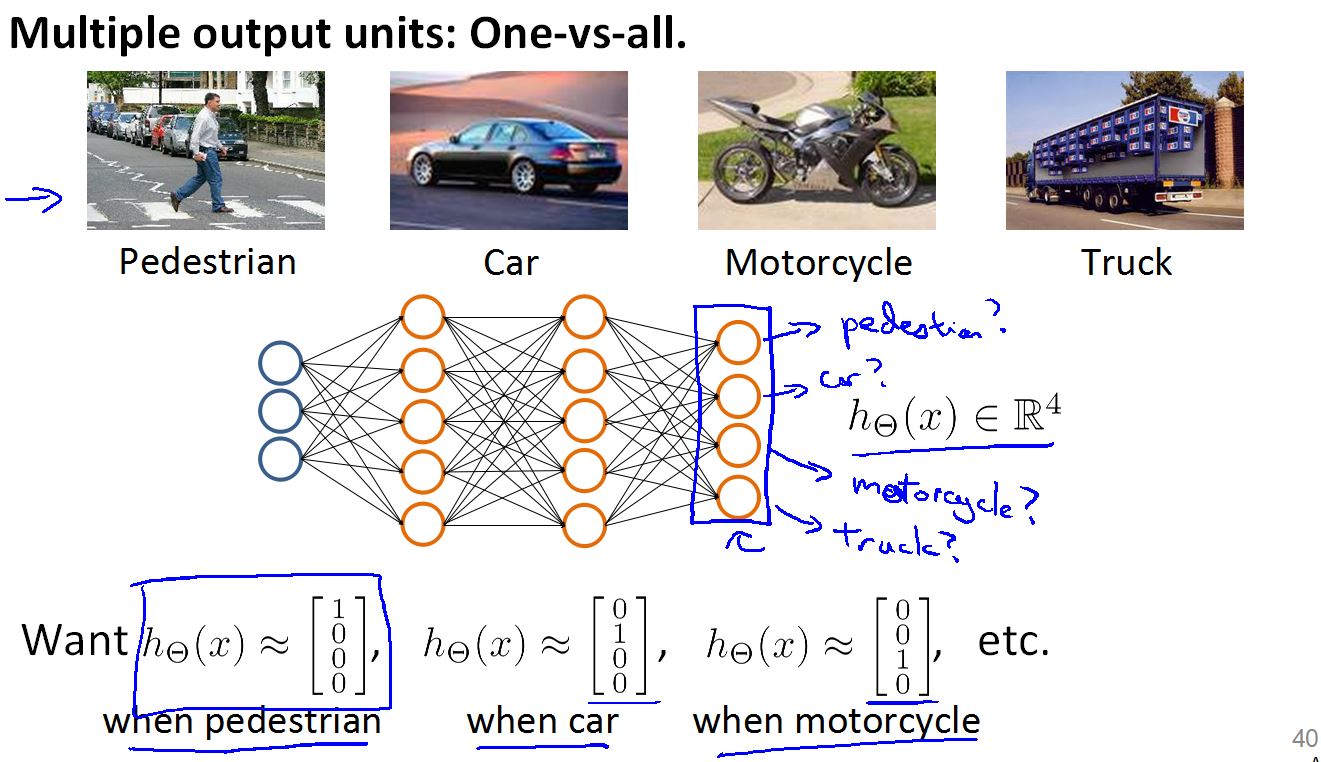
在这里我们队多个不同的类别进行分类,和Logistic 不同的是,我们不必构建多个分类模型,只要一个神经网络然后将输出变成多个输出单元就可以得到一个多分类模型(输出单元的个数等于要分类的类别数量)。
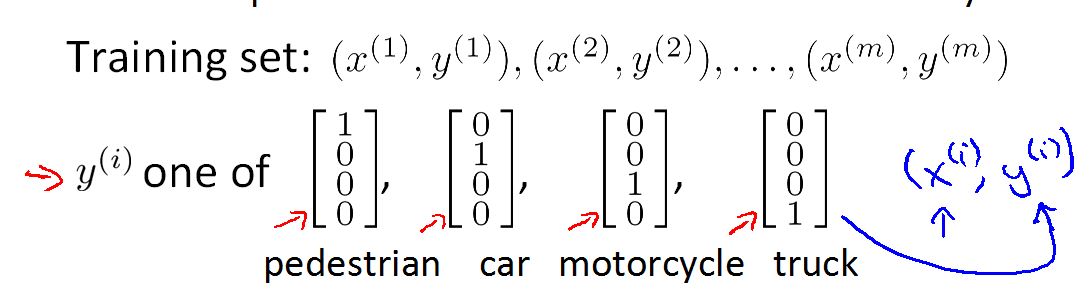
但是样本集的输出Y(i)要做一些改变,这是在四个类别的情况。如图
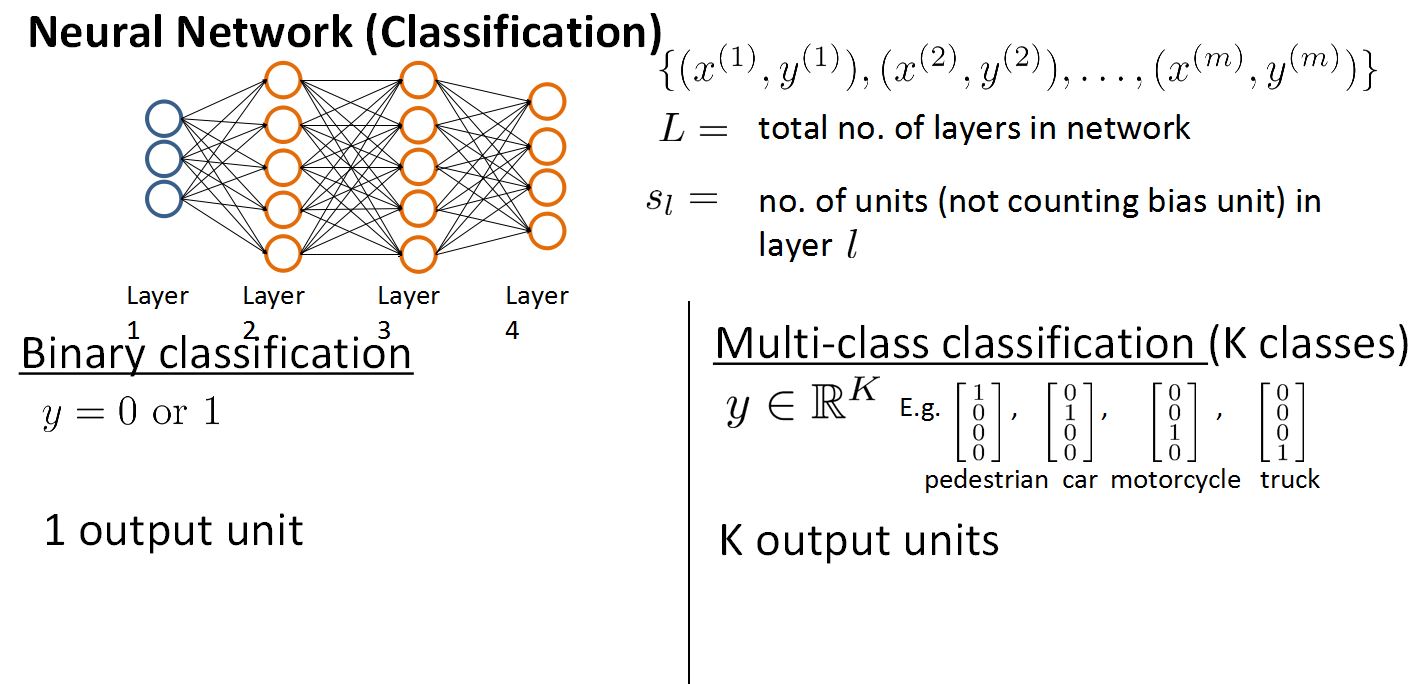
Cost Function
目标是在给定数据集,为神经网络拟合参数的学习算法。
其中:
L 表示网络的总层数
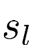
说以二元分类中SL = 1(表示输出单元个数为1)
在多元分类中SL = k (输出单位的个数为k个)
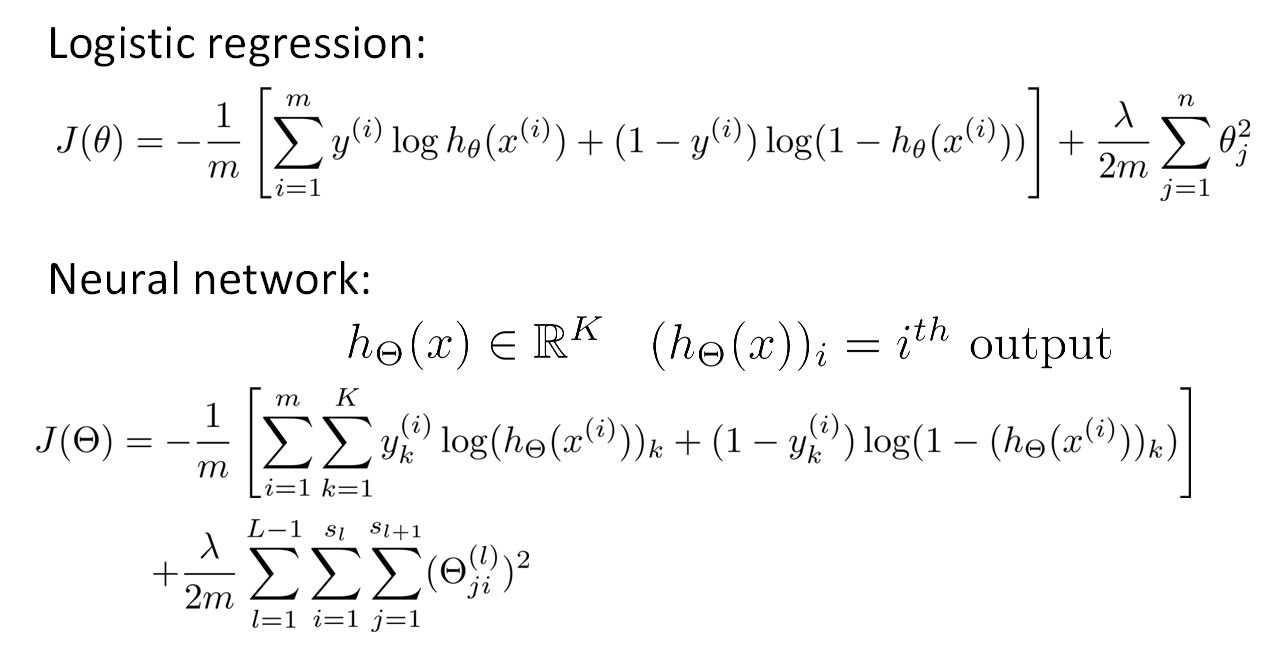
对比Logistic的代价函数给出神经网络的代价函数,可以看出,神经网络的代价函数是Logistic的代价函数的扩展。
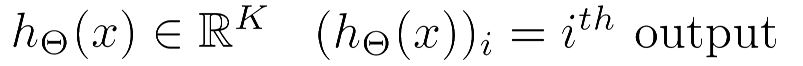
可以知道K 是输出单元的个数, (h(x))i 表示第i个输出。
对神经网络的代价函数的参数说明:
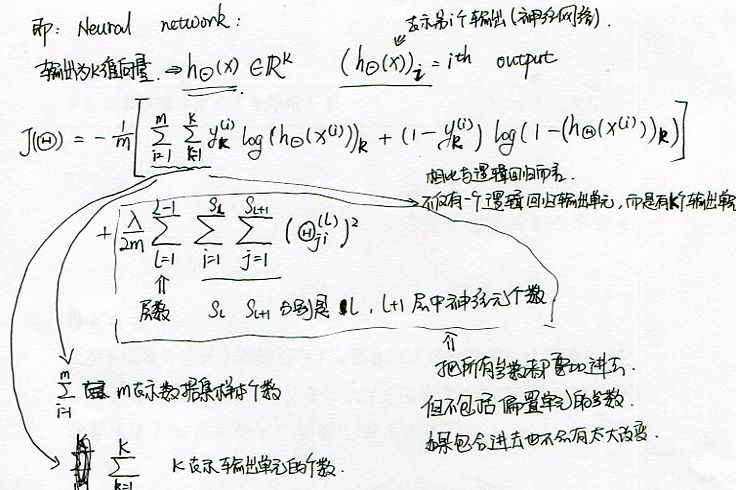
正规化时一定要把除偏置单元以外的所有参数都要考虑进去,对于偏置单元的参数来说,是否正规化对神经网络没有太大的影响。
Backpropagation algorithm
有了代价函数:
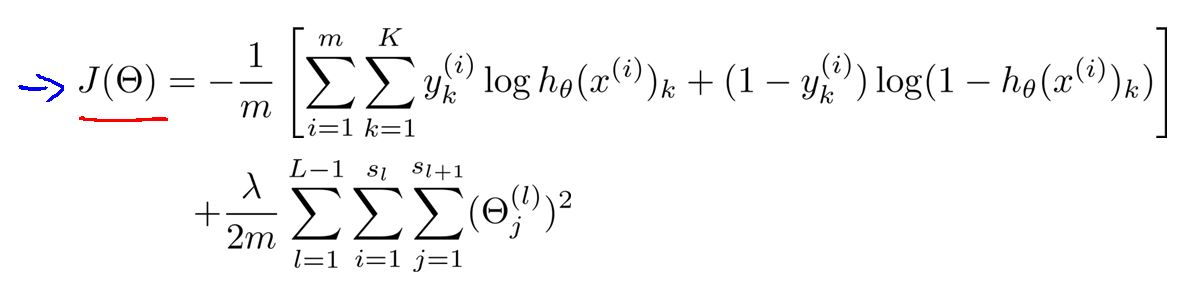
可以看出,去掉正规化部分,其余部分相当于,K个独立的逻辑回归J(θ)进行求和。
然后就是和Logistic 一样的步骤。
对代价函数最小化
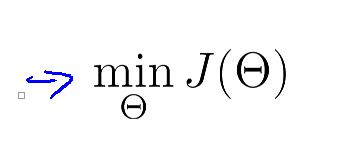
求出神经网络的权重。
J(Θ)是对K个输出单元进行求和。
而求权重的方法就是梯度下降,在神经网络里我们用反向传播网络来求梯度下降的方向。
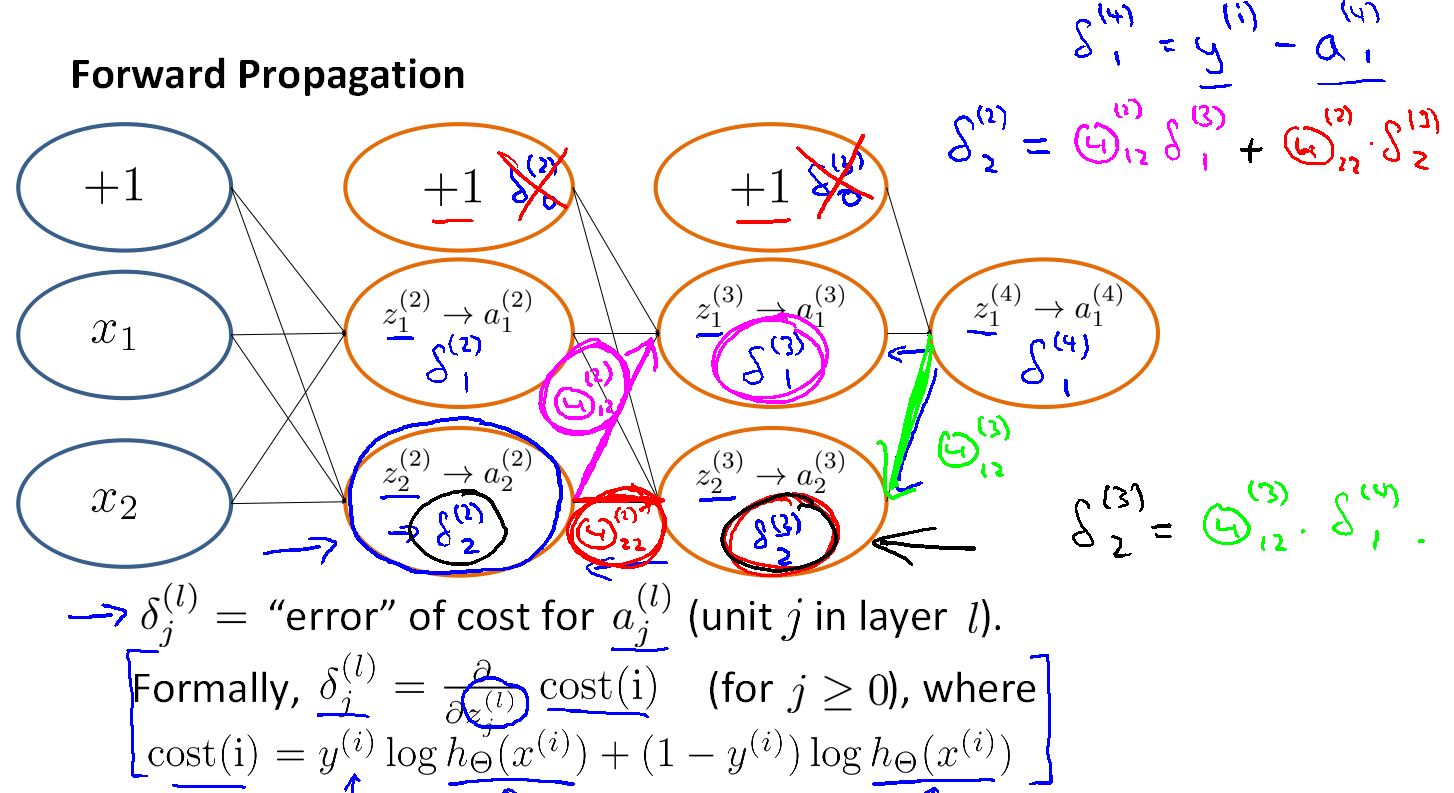
反向传播算法(在一个样本时):
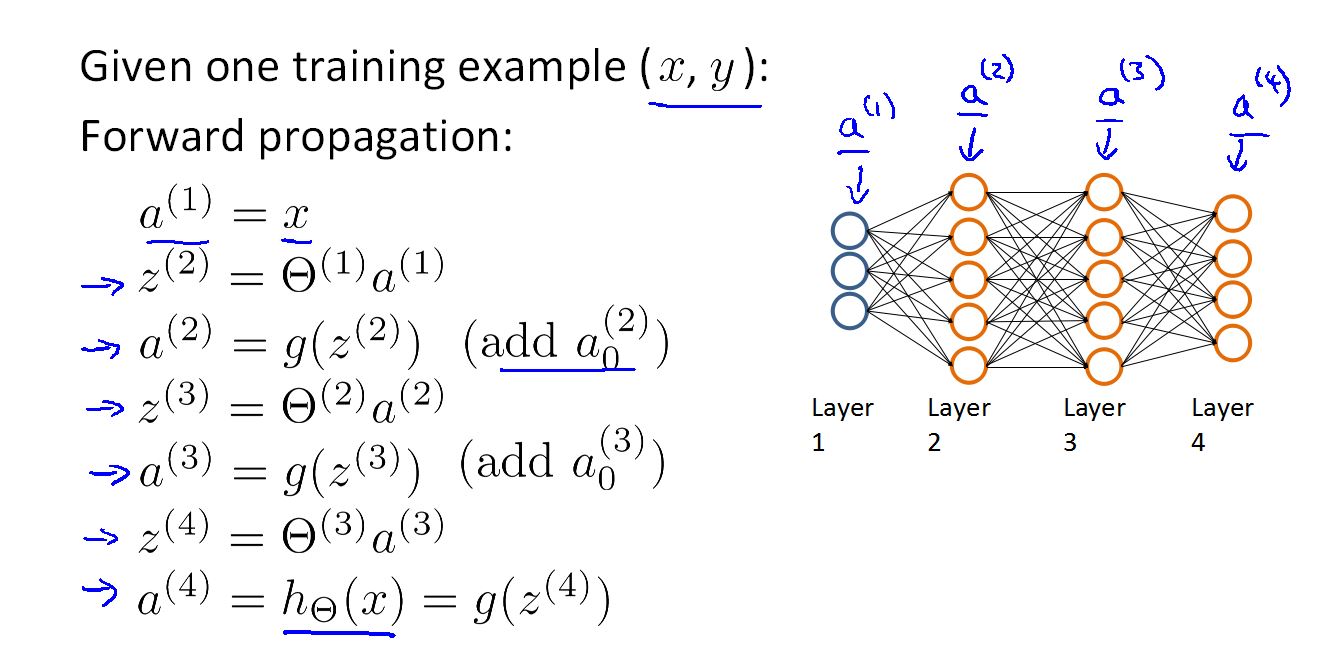
这里有一个四层的神经网络,而且给出了向量化的前向传播网络算法。
在用反向传播网络来求最小的代价函数时,首先要用前向网络求出我们预测的结果。

表示L层的j单元的误差(捕捉L层j神经节点的激励值的误差)
先求最后一层的误差(在这里就是第四层误差)
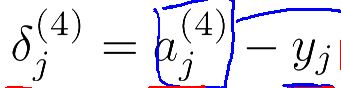
在等好右边的第一个式子表示由前向网络计算出的值(输出单元激励值),第二个式子表示该样本的真正的类别值。
对上边的式子进行向量化:
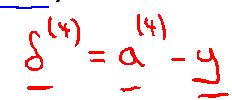
有了最后一层(第四层)的误差然后反向计算第三层,第二层的误差,第一层没有误差。
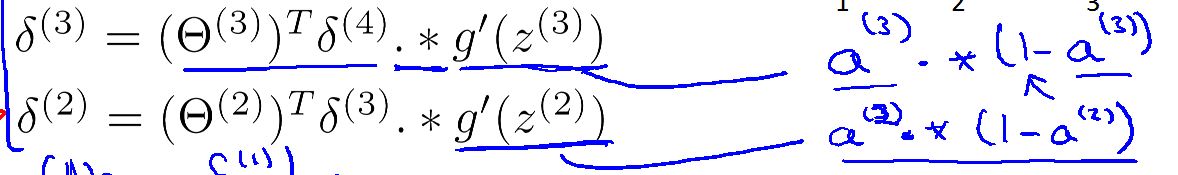
其中 .* 是元素乘法运算。
所有对网络中的第L层i行j列的参数求导为:
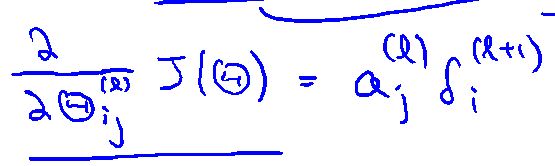
用反向传播网络求下降方向:

在上面的求下降方向的算法中,我们用了所有的样本。
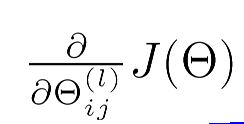
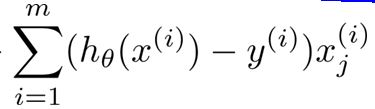
然后对每个样本进行循环。
首先将一个样本的所有特征输入到前向传播网络,求出样本的 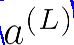
用求出的项,计算最后一层的误差 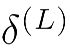
然后用反向传播网络,计算网络各个层的激励误差。
计算方法:
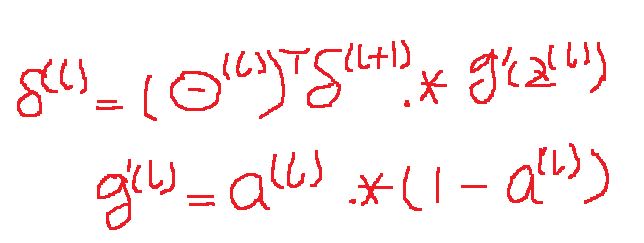
用这些误差来更新,个个激励的 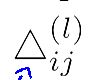
这一步可以向量化:

循环完毕后:求各个参数梯度下降的方向。
Neural Networks 都干了什么
首先创建一个神经网络框架:
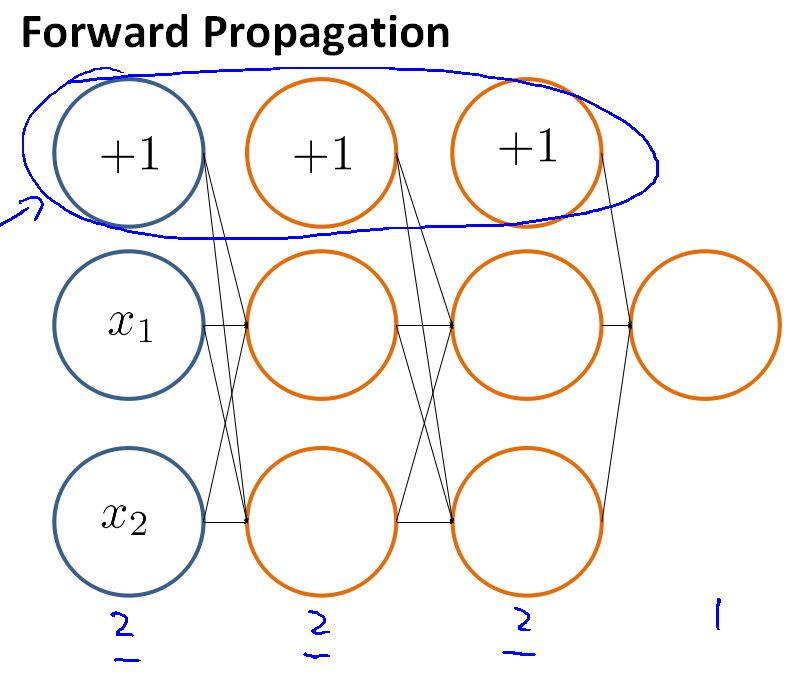
在这个神经网络的框架中,是一个四层网络。
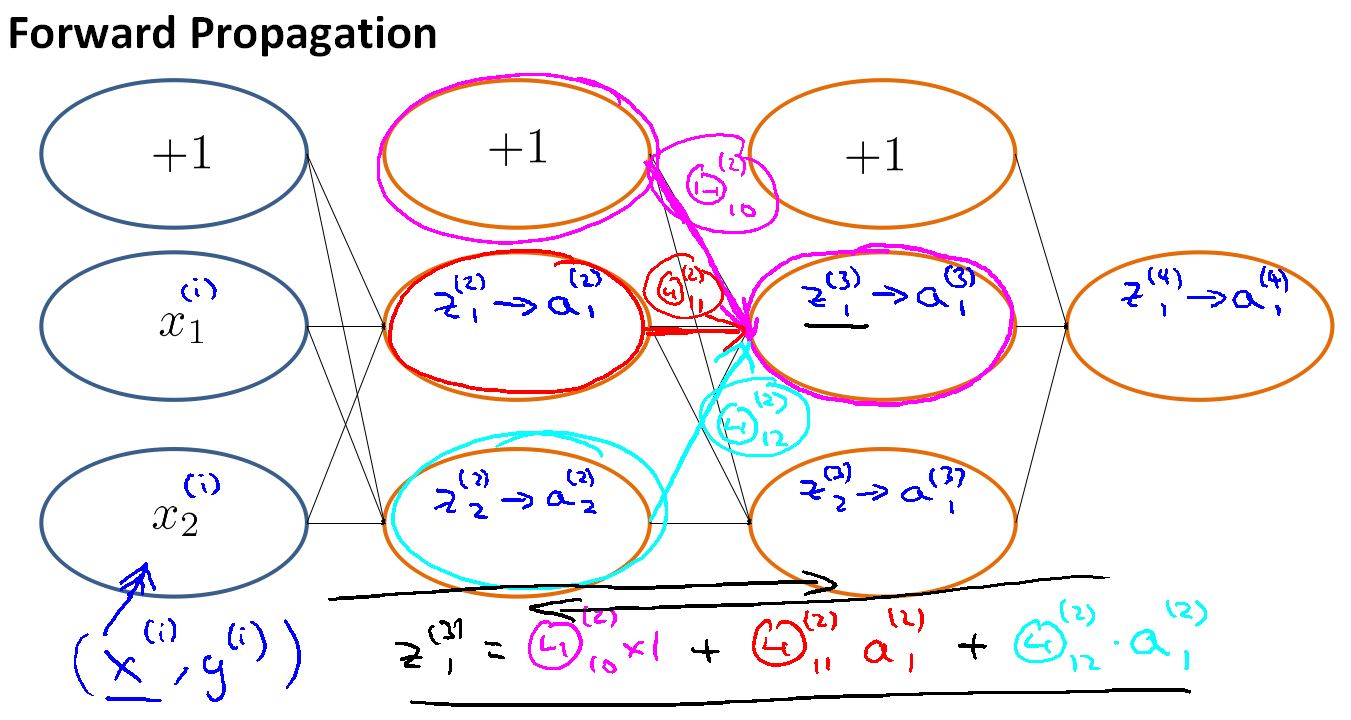
前向传播网络就是从输入层,用不同的权重,来计算第二层的激励,让后把第二层激励看成是输入,由不同权重计算第三层的激励,这样一直下去直到输出层。
反向输出网络干了什么?
简化说明:这里只有一个输出
代价函数是 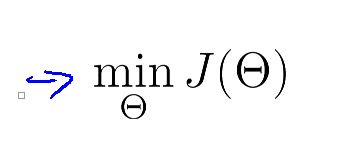
同时也不考虑正规化项。
于是样本 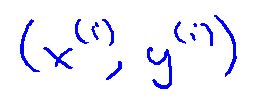
每次要付出的代价是:
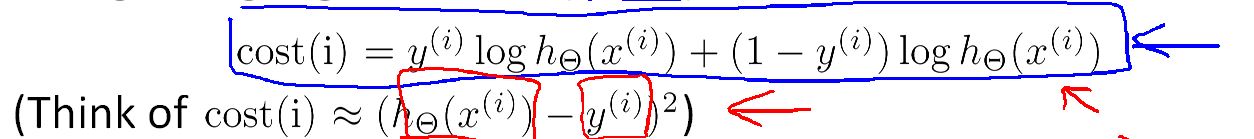
当然在这里我们也可以用平方代价来计算。
反向网络其实就是把误差当成输入特征,然后把网络反过来,把前向网络的输入到输出,把前向网络的输出当成输入,进行计算,求出网络中每个激励的误差。
Neural Networks的实现

图的上方是Logistic 的实现代码,但是在神经网络中参数(权重)不在是一个向量,而是一个个矩阵theta1 , theta2 , theta3 。
在这里创建一个四层的神经网络:
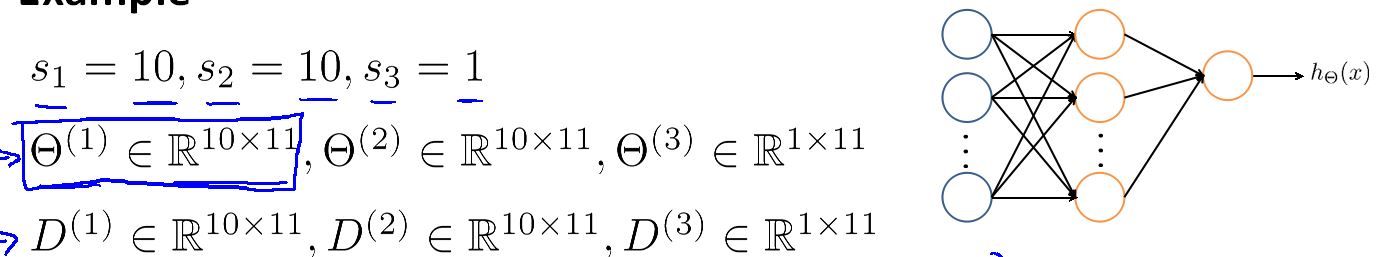
它说明如上,这里神经网络的框架图有错误,只有四层网络才会有三个参数矩阵,三层网络只有两个参数矩阵。

用上面两条命令,可以将矩阵变成向量。

用上面的命令,可以将向量变成矩阵。

有了上面的两步,可以用处理Logistic的方法,处理神经网络的参数。方法如上。
Neural Network 的实现细节:Gradient checking
坏消息:在实现反向传播神经网络时,会遇到一些细小的错误(Θ对δ(误差)的改变是很敏感的),在神经网络中应用梯度下降或其他方法计算参数矩阵和代价函数J时,有时看起来代码运行正常,而且计算得到的代价函数J可能也是减小的,但是最后得到的神经网络的泛华能力却很低,这些错误很可能不易发现。
Gradient checking:是用于在实现神经网络初对代码进行正确性检查,以保证最后结果的正确性。
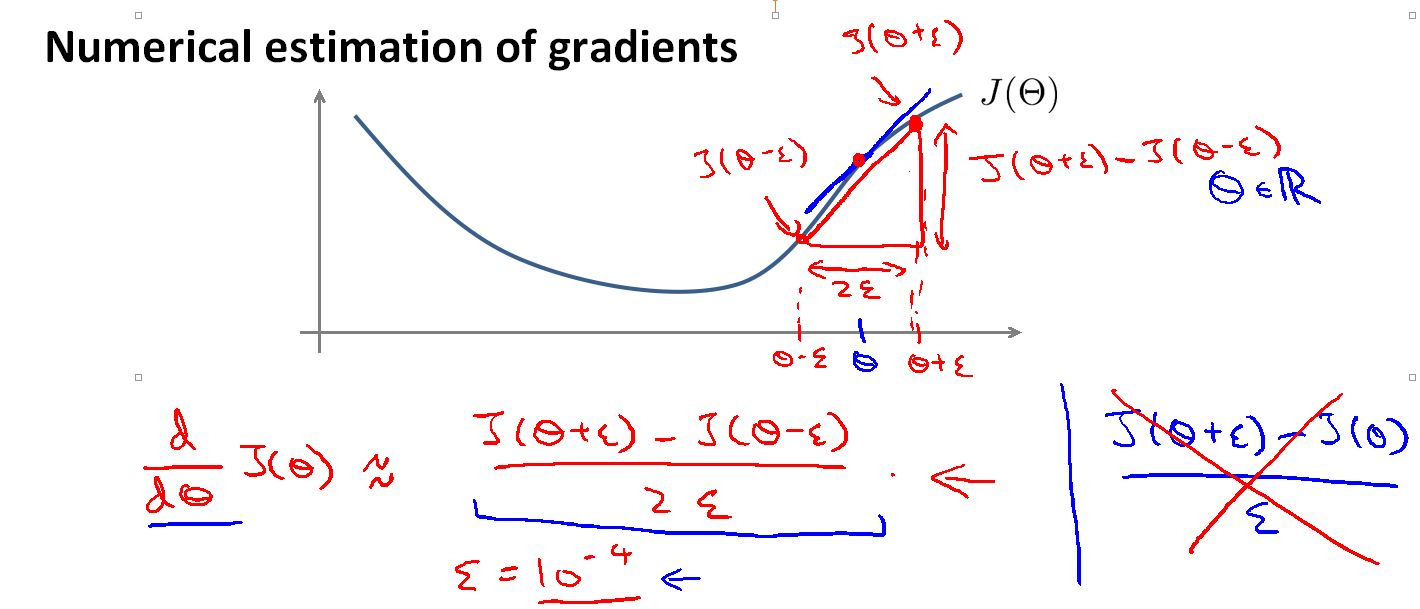
如图,在曲线上任意一点(theta1)求导,我们可以得到曲线在这点处的斜率,同时,在theta1的两边取两个值分别是(theta1+epsilon)和(theta+epsilon) 其中epsilon 是一个很小的值。把曲线上对应的两点用线连接起来,连接线的斜率应该和theta1的斜率很接近

代码表示

推广到高维代码是:

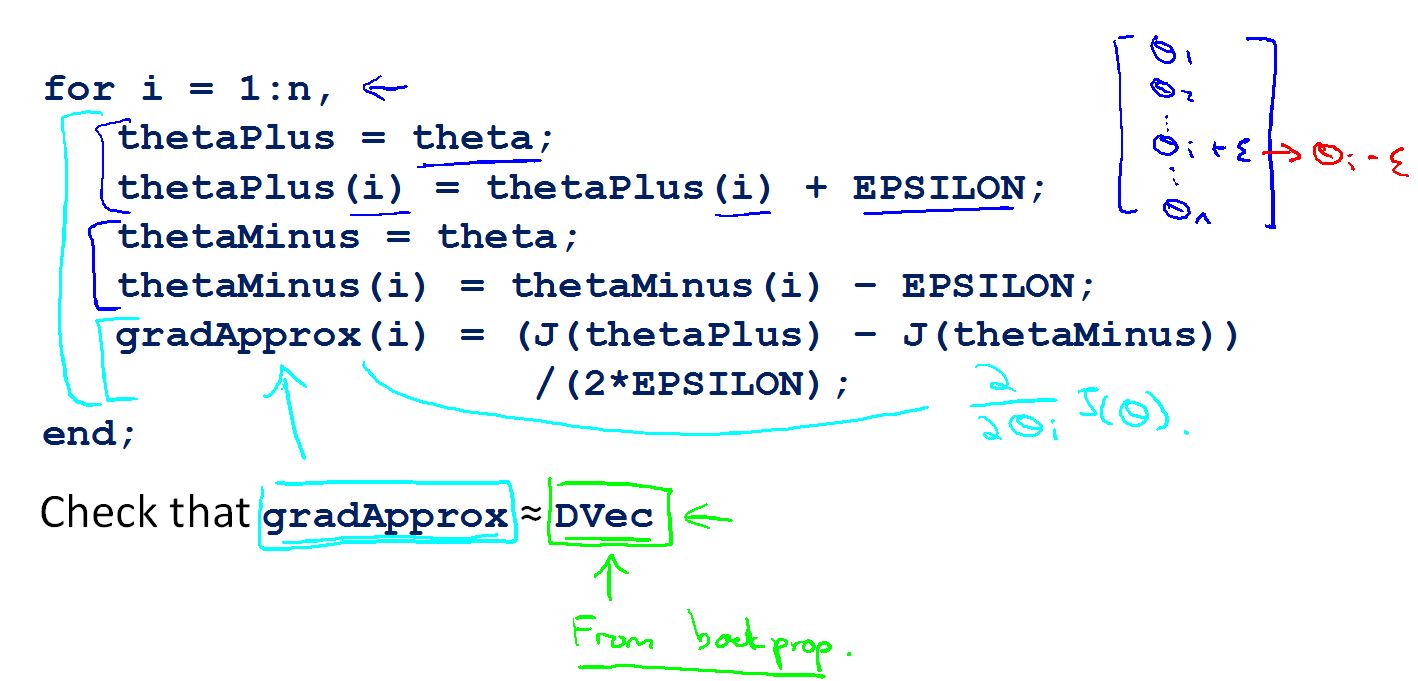
在神经网络中用for循环计算出估计每个参数的斜率,然后用反向传播网络得到每个参数的梯度值。若两者接近,说明反向传播网络是正确的。

Gradient checking 的步骤:
1.利用反向传播网络计算各个参数的DVec(梯度值)
2.用上面的方法计算参数的估计梯度值 gradApprox
3.确定DVec 和 gradApprox 结果相似
4.如相似,关闭Gradient checking ,用反向网络求解参数值;不相似,修改反向网络的代码。
这里必须关闭Gradient checking ,他是一个运行非常慢的求导数估计值的方法,而反向网络效率要高很多,如果每次都精心梯度检测,会非常的耗时。
Neural Network 的实现细节:Random initialization(随机初始化参数)

无论是Linear 还是 Logistic 在初始化参数时可以将参数初始化成一样的值,但在神经网络中不可以这样做。
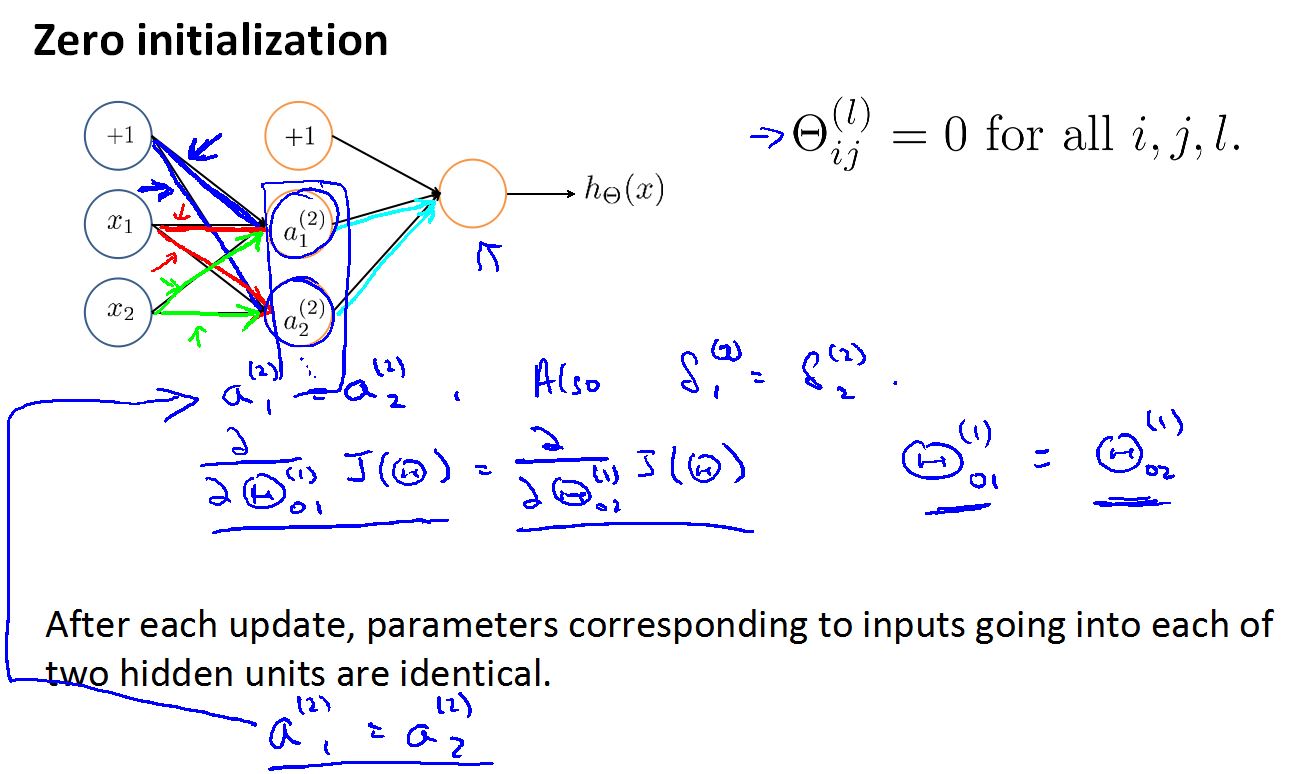
假设将神经网络的参数都初始化成零,用蓝,红,绿表示从第一层到第二层的路径,如果参数都初始为零,则第二层的所有的激励值都是一样的,这样一直计算到最后。然后应用反向神经网络计算出错各个参数的误差也是相同的,各个参数的导数也相同,跟新后的参数也相同,然后在用前向神经网络进行下一次的跟新,但参数还是相同的,这样一直下去,没有任何的变化,不可能完成网络的学习。
以蓝色的路径为例:
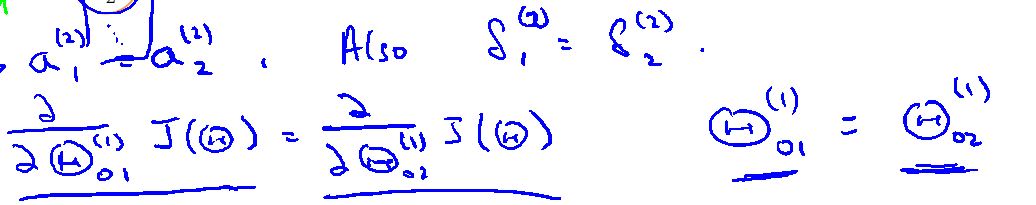
所有在学习神经网络时有一个重要的步骤,就是随机初始化所有的参数

对参数的初始化一般值在[-ε , +ε]之间,ε很小接近零的数.
总结
设计神经网络:
首先要搭建神经网络的框架,设计神经元之间的连接方式。
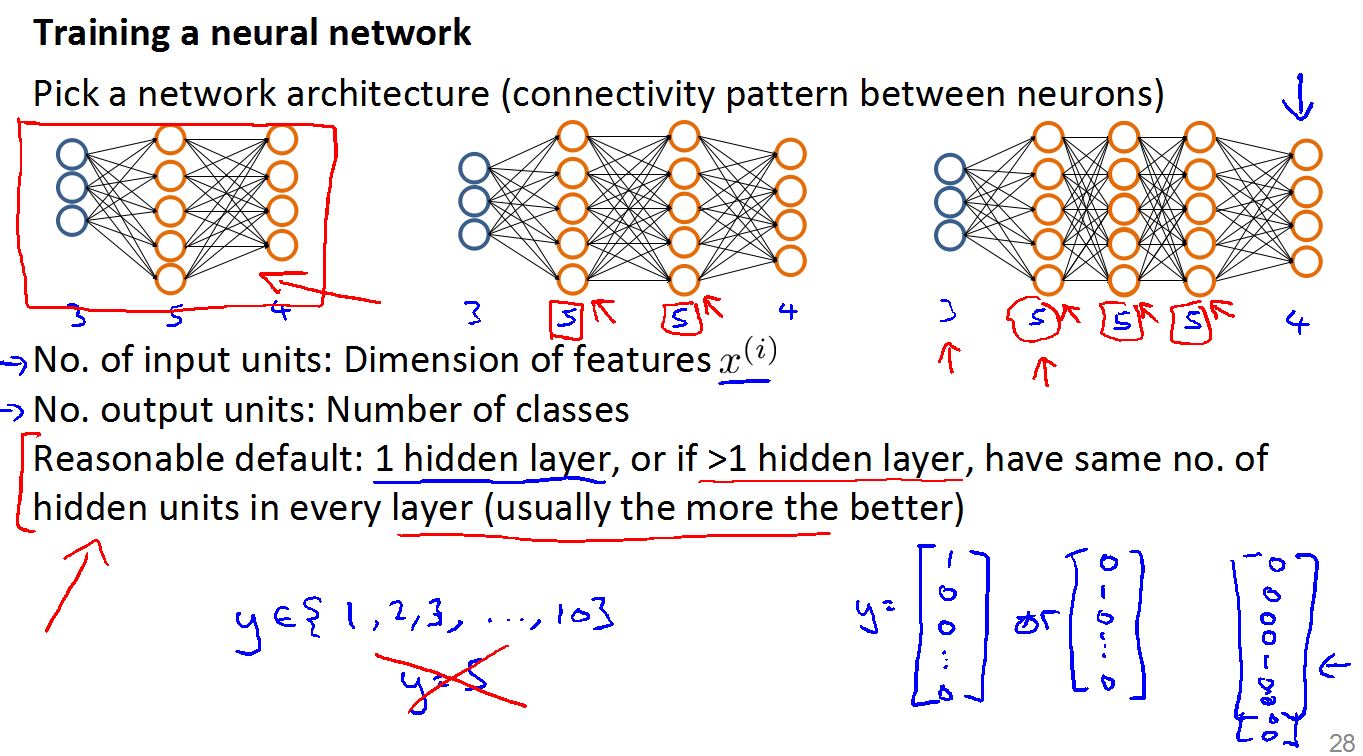
1.输入特征的个数决定输入单元的个数
2.输出类别的个数决定输出单元的个数
3.决定隐藏层的个数(一般一个隐藏层就可以很好的完成工作),和每层隐藏单元的个数(隐藏单元的个数一般要大于输出单元个数),当然隐藏层和隐藏单元的个数越多越好,计算量会上升。
接着是训练的过程。


1.随机初始化参数值
2.应用前向传播网络计算说有x(i)的预测值
3.设计代价函数
4.用反向传播网络计算梯度
5.应用梯度检测,检查代码的正确性。验证完正确后,关闭梯度检测。
6.运行程序,计算神经网络的最优参数(这里要说明一点J(Θ)不是一个严格的凸函数,所以,在求解最优参数时,它可能会停在局部最小值,而不是全局最小值,但即使是局部最小值,神经网络工作仍然表现很好)















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









