







spark Example GOGOGO!
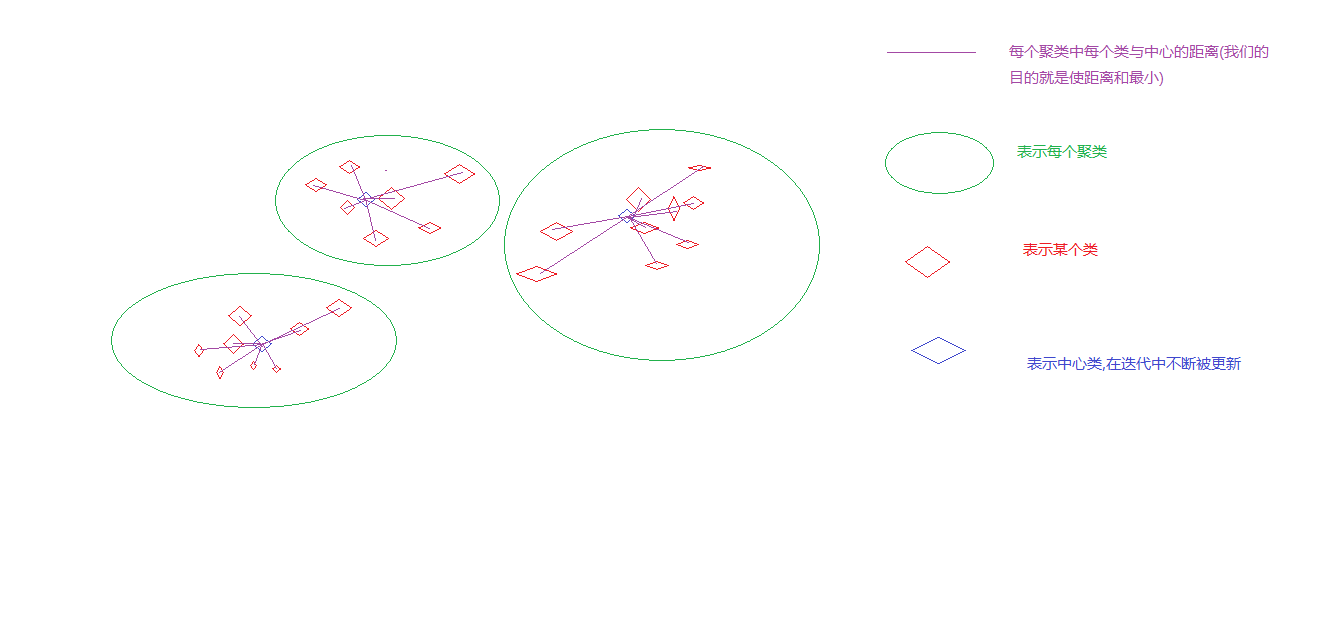
kmean算法的聚类算是好理解的
依旧画图好理解
from __future__ import print_function
import sys
import numpy as np
from pyspark import SparkContext
def closestPoint(p, centers):
bestIndex = 0
closest = float("+inf")
for i in range(len(centers)):
tempDist = np.sum((p-centers[i]) ** 2)
# 找出p最靠近那个点
if tempDist < closest:
closest = tempDist
bestIndex = i
return bestIndex
if __name__ == '__main__':
if len(sys.argv) != 4:
print("Usage: kmeans <file> <k> <convergeDist>", file=sys.stderr)
exit(-1)
print(
"""WARN: This is a naive implementation of KMeans Clustering and is given as an example!
Please refer to examples/src/main/python/mllib/kmeans.py for an example on how to use MLlib's
KMeans implementation.""", file=sys.stderr)
sc = SparkContext(appName="PythonKMean")
lines = sc.textFile(sys.argv[1])
# 分割数据
data = lines.map(lambda line: np.array([float(x) for x in line.split(' ')])).cache()
K = int(sys.argv[2])
# 平均距离
convergeDist = float(sys.argv[3])
# 该函数是将数据加载到内存中的,所以使用时必须注意,数据量不能太大
# False 表示num不大于原本数据
# 初始化 K 个默认 的点(最后不断的迭代,至最小距离)
kPoints = data.takeSample(False, K, 1)
tempDist = 1.0
while tempDist > convergeDist:
closest = data.map(
lambda p: (closestPoint(p, kPoints), (p, 1)))
# 把每一个K的集合的距离相加 (sum,num)
pointStats = closest.reduceByKey(
lambda p1_c1,p2_c2:(p1_c1[0] + p2_c2[0],p1_c1[1] + p2_c2[1]))
newPoints = pointStats.map(
# st[0] => K
# st[1][0]距离和
# st[1][0] / st[1][1] 平均距离
lambda st: (st[0], st[1][0] / st[1][1])).collect()
tempDist = sum(np.sum((kPoints[iK] - p) ** 2) for (iK, p) in newPoints)
# 保存聚类点
for (iK,p) in newPoints:
kPoints[iK] = p
print("Final centers:" + str(kPoints))
sc.stop()















 4709
4709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









