






本文将详细介绍FPGA芯片。
微信搜索关注《Java学研大本营》

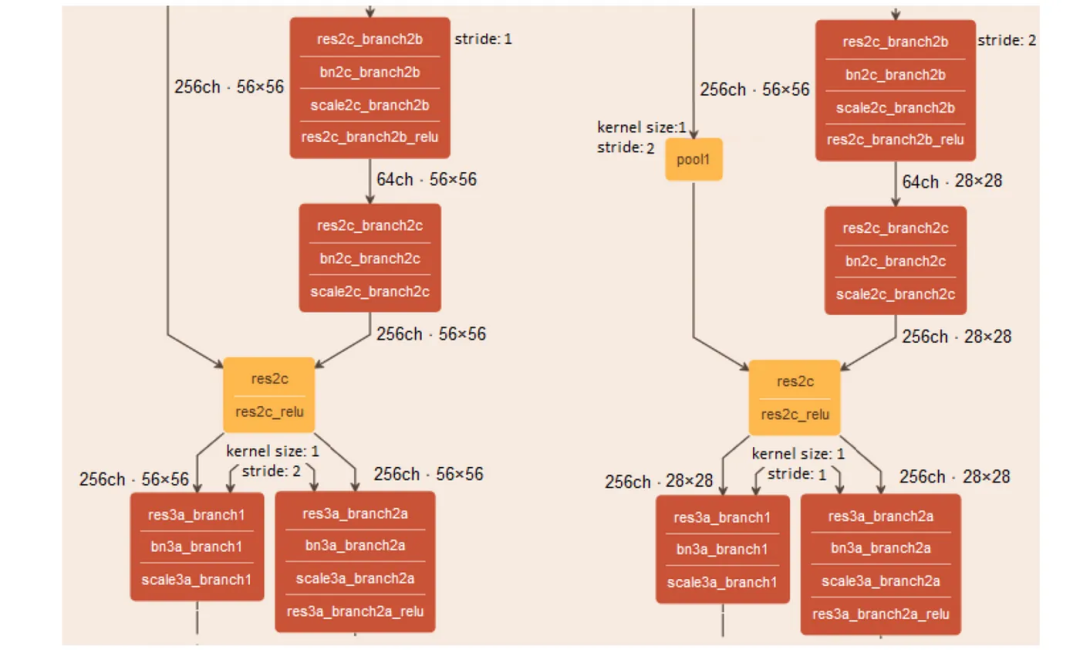
9 ResNet中的步幅优化(高级主题-可选)
这里的主要思想是将大于1的步幅从后面的卷积层(内核大小=1)移动到上面的卷积层。此外,还为跳过连接添加了一个池化层。
其他优化包括节点合并、水平融合和删除未使用的层(dropout)。TensorRT是Nvidia在GPU上使用的部署工具。对于那些对这个优化主题感兴趣的人,它记录了一个更大的计算图优化列表。
10 中间表示量化
如果开发人员要求,可以进一步对权重进行量化,以使用低精度算术,如INT8。这减少了内存带宽需求并加快了操作速度。
11 英特尔FPGA深度学习加速(DLA)套件
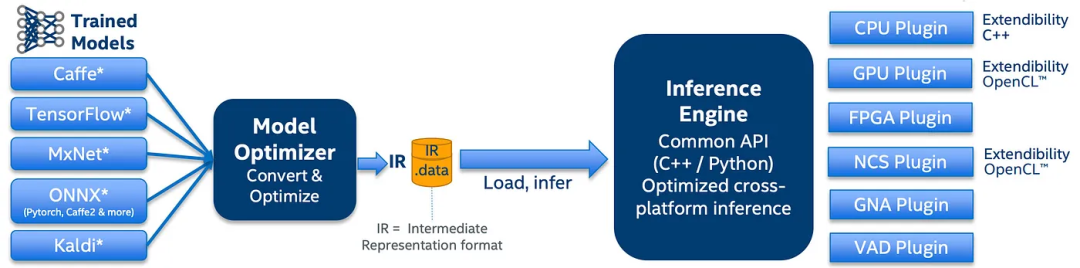
深度学习部署工具包(DLDT)中的推理引擎为开发人员提供了一个高级的设备无关API来编程推理。这是一些示例代码。
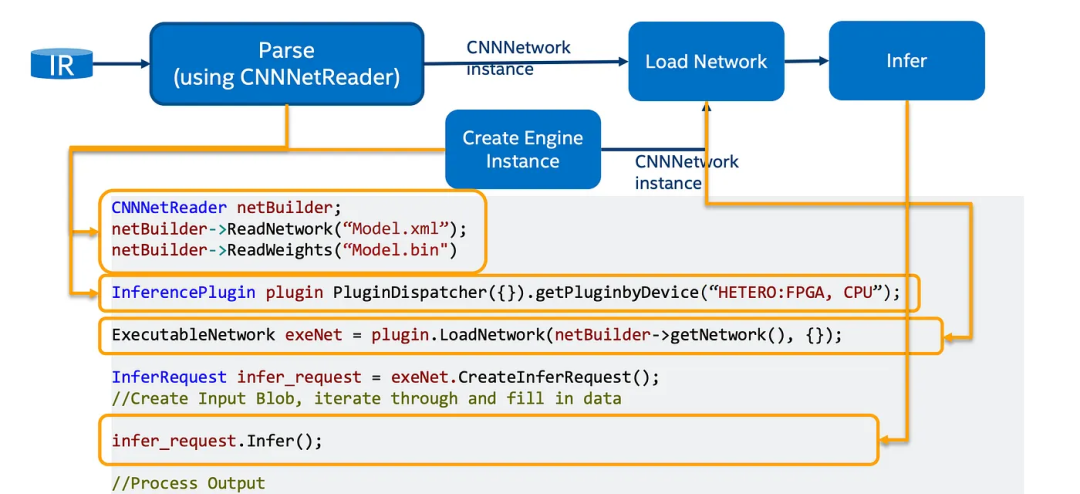
推理引擎加载用户提供的IR并调用相应的插件来处理特定设备的推理。

对于FPGA,它调用了DLA(深度学习加速)运行时引擎。

它驱动加速器中DL模型的执行。
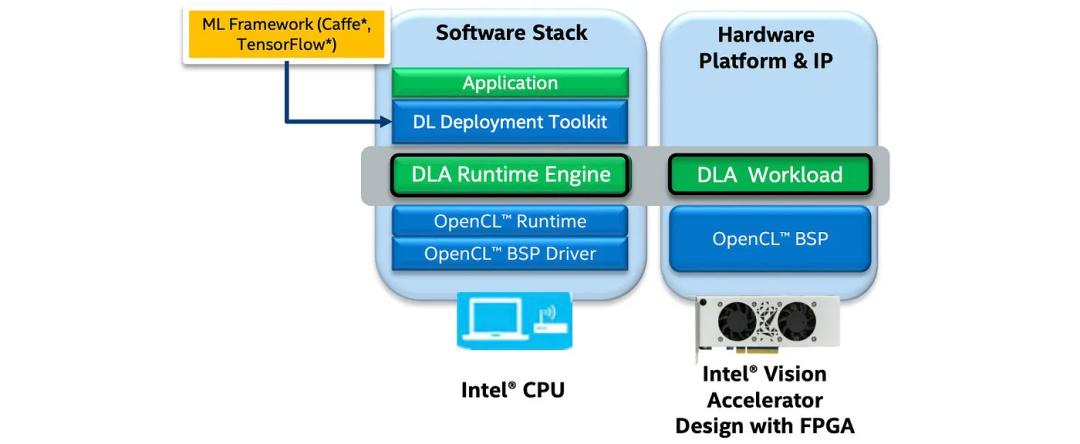
部署DNN模型是一个软件过程。FPGA已经预先编程了一个为DLA运行DL模型而设计的比特流。不需要FPGA编译。
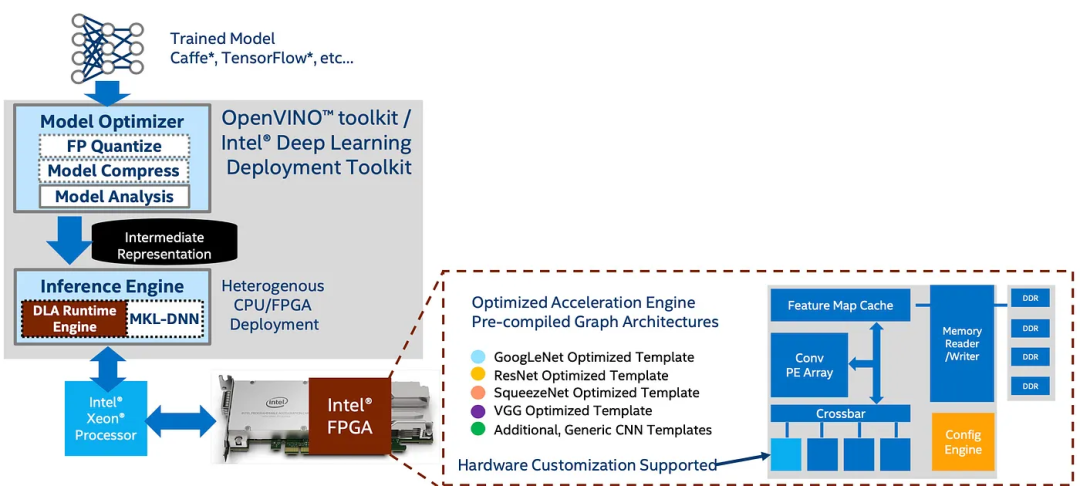
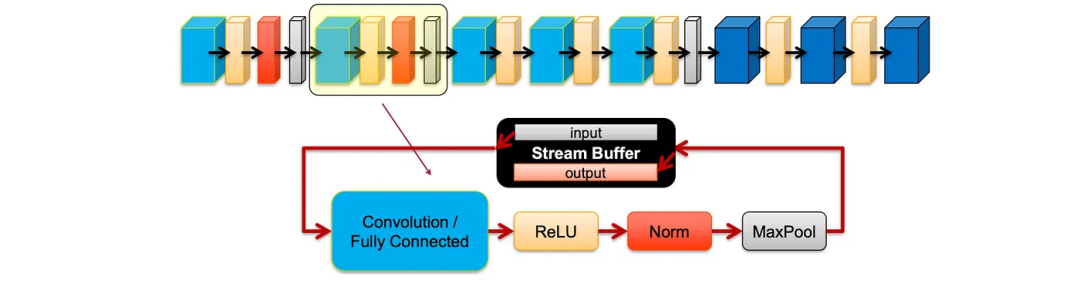
这里是DLA Runtime用于运行DL模型的DLA架构。该架构包含卷积PE(处理元素)阵列、用于存储特征图和 DL 中常用的层(组件)的缓存。
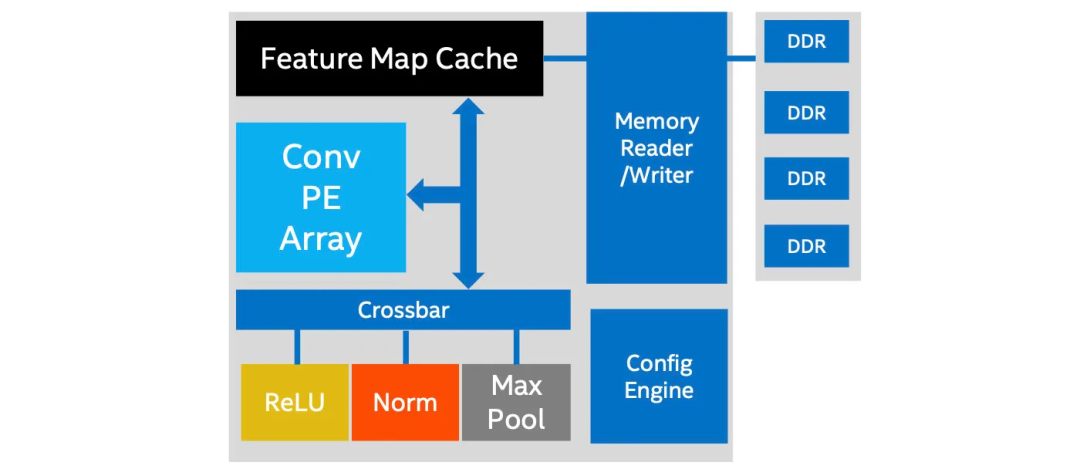
让我们将DNN模型映射到这个加速引擎架构中。许多DL模型,如AlexNet,包含高度相似的层序列组,例如卷积层后跟ReLU、归一化和最大池化。
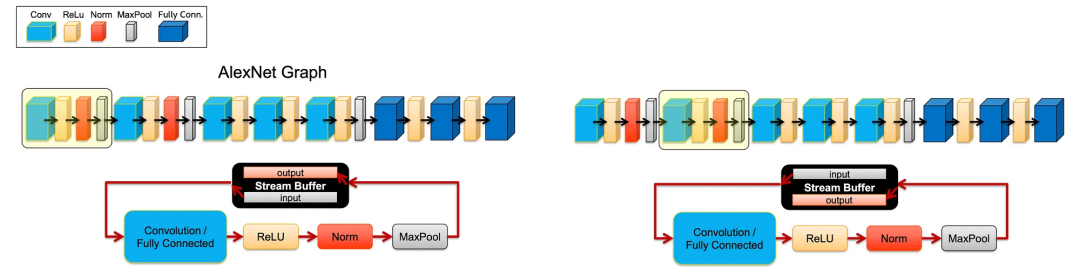
在FPGA内部DL层是由配置的互连链接的块实现的。

要运行一组层,我们创建一个数据流并通过负责特定类型DL层的块传递它。要执行整个模型,我们重复流式循环以处理下一组,直到所有DNN层都被处理。
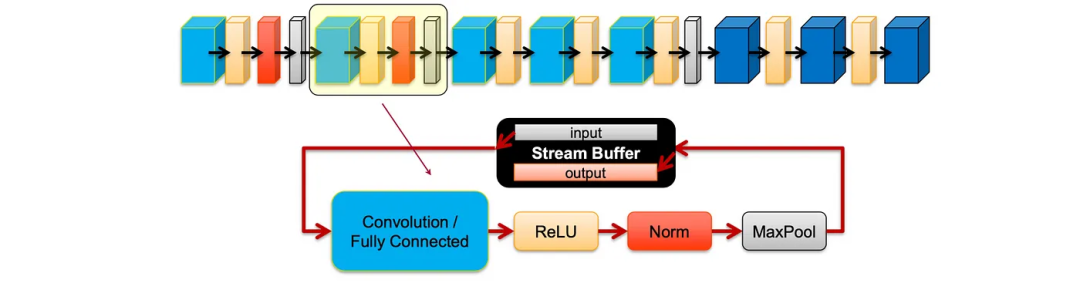
这些块在运行时高度可重构且可绕过。这使得深度学习层(DL)的不同设计参数(如CNN步幅)或跳过不需要的层成为可能。

让我们进一步阐述一下。首先,视频数据从DDR(双数据率)通道到达。
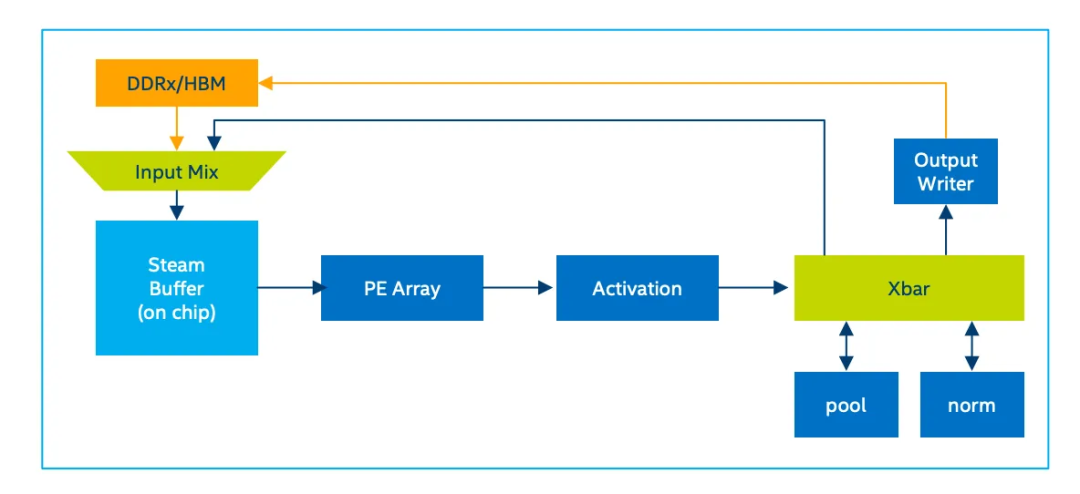
如果视频数据太大而无法存储在芯片上的流缓存中,则将其切片并在多个流水线迭代中逐个传递。在每个迭代中,数据从缓存中提取并通过卷积PE阵列(PE-处理元素)和激活块进行处理。然后通过交叉开关(XBAR)传递给其他块,例如标准化和最大池化。然后将数据反馈到流缓存中,以供下一组层使用。一旦整个模型处理完毕,就会将其写回内存并继续处理下一片数据。以下图表总结了深度学习加速器(DAL)引擎用于执行DL模型的图循环架构。
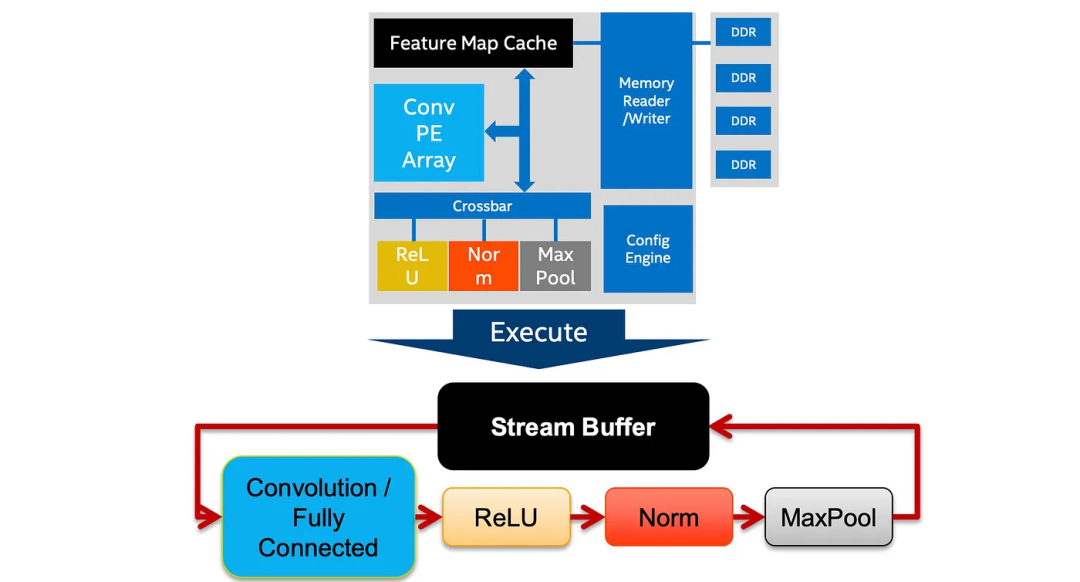
-
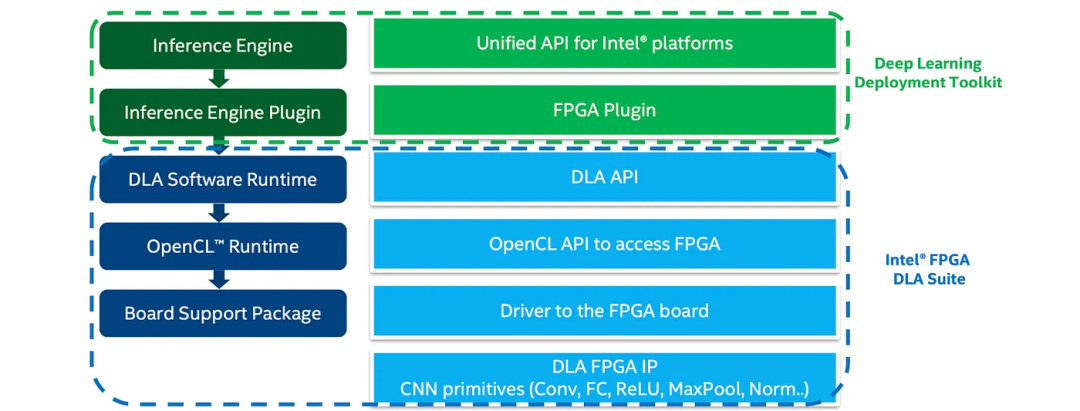
推理引擎流程
让我们也总结一下推理引擎(IE)调用FPGA设备的流程。开发人员通过IE通用API进行推理调用,IE调用FPGA插件,这调用了运行OpenCL运行时的DLA(英特尔深度学习加速器)。最终发送到实现基元(如卷积、ReLU等)的DLA FPGA IP。
(术语说明:FPGA IP是指硬化的知识产权核心。在这里,我们可以将其视为实现基元的物理块。)
-
位流
深度学习部署工具包(DLDT)随附许多位流,用于各种板卡、推理中使用的数据类型和DL模型。
这些FPGA块可以通过垂直和水平线连接在一起。

OpenVINO随附以下使用图循环架构专门针对以下DL模型的位流:

这些是支持的基元

当新类型的DNN层出现时,可以扩展此执行模型。可以使用添加了新内核(基元)的位流文件重新编程FPGA,然后将其附加到Xbar上。这就是FPGA的魅力所在,我们可以在不更换硬件的情况下更改硬件设计。

这是添加了新基元的架构
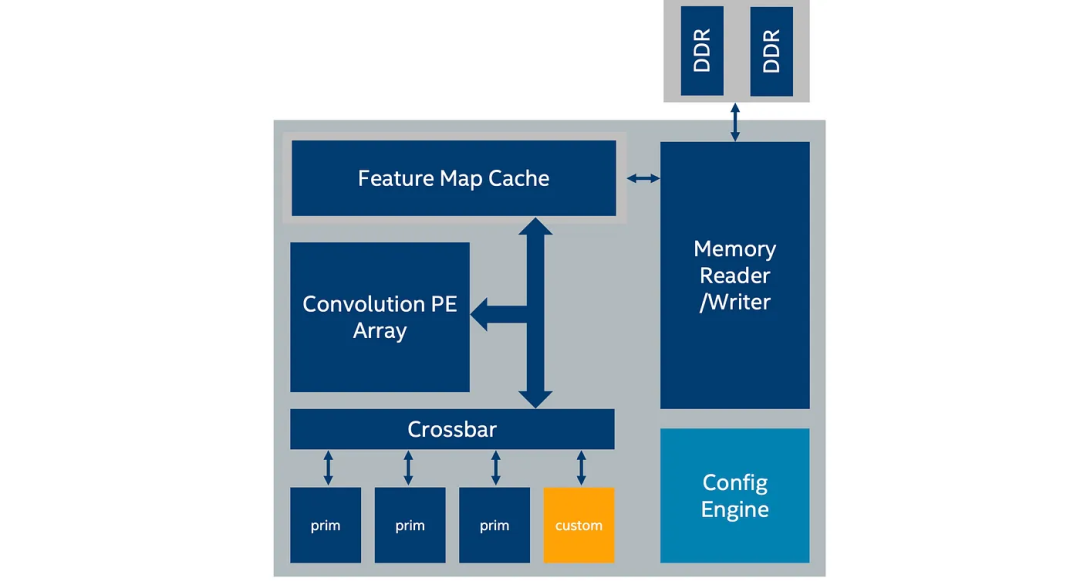
要将此类特性/层添加到DLA中,IP架构师(下面第二行)会修改DLA套件源代码,然后重新编译FPGA位流以编程FPGA。
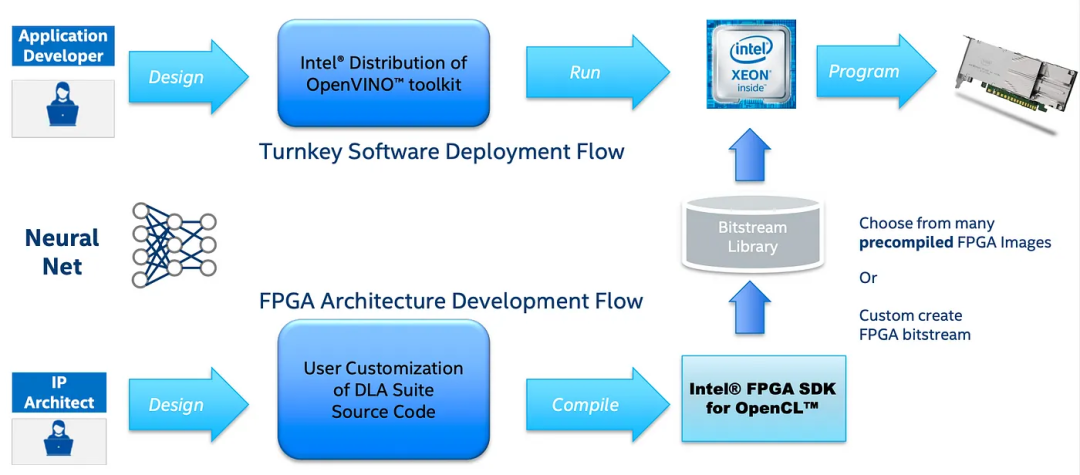
供您参考,下面的图表是IP架构师创建自定义内核(自定义基元)的典型工作流程。

-
设计权衡
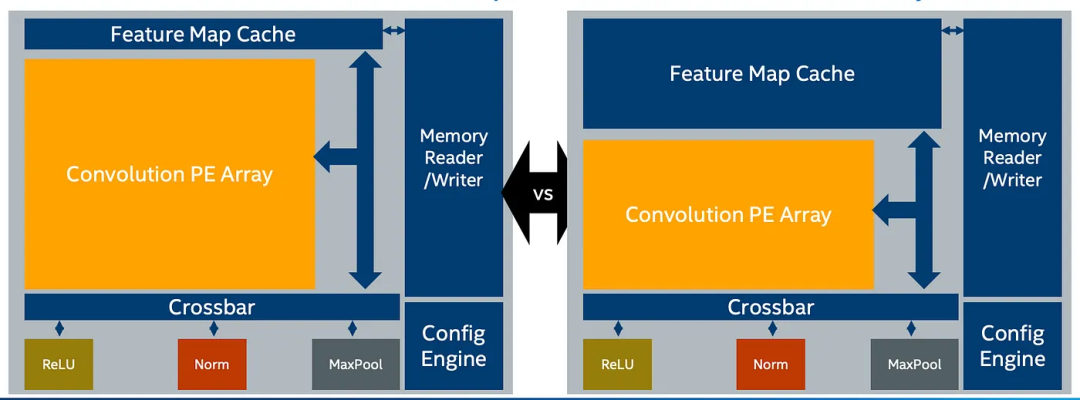
如前所示,不同的DL模型(拓扑)可能导致对位流做出不同的选择。例如,在固定的硬件资源下,添加基元可能需要缩小PE阵列的大小。
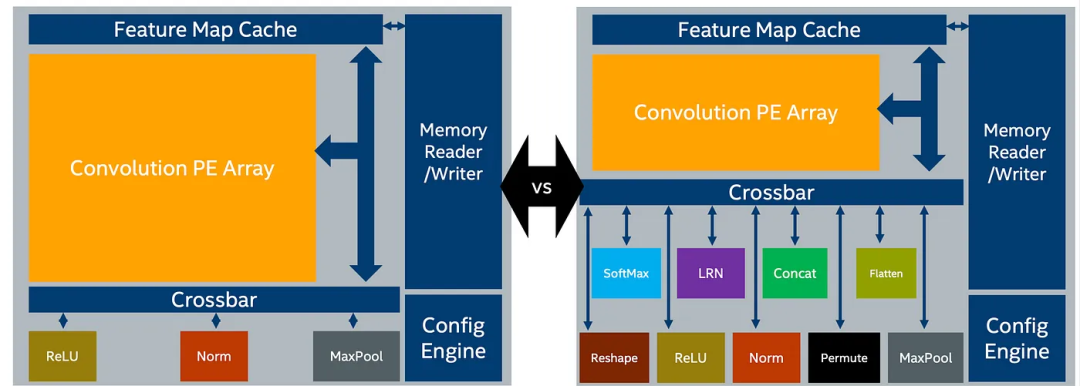
或者,这将影响您对FPGA生产线的选择,使你倾向于选择大型特征图缓存而非PE阵列(详细信息)。注意:这些权衡对DL模型和应用程序非常敏感。因为某些应用程序可能需要更大的特征图缓存以减少芯片外存储器的访问。
12 优化
FPGA在硬件设计上的灵活性允许进行无法通过其他方式实现的优化。在本节中,我们将探讨一些增加并发性和减少操作的优化。如果没有硬件的帮助,这些优化也许是不可能的或者无法获得同等的性能提升。
-
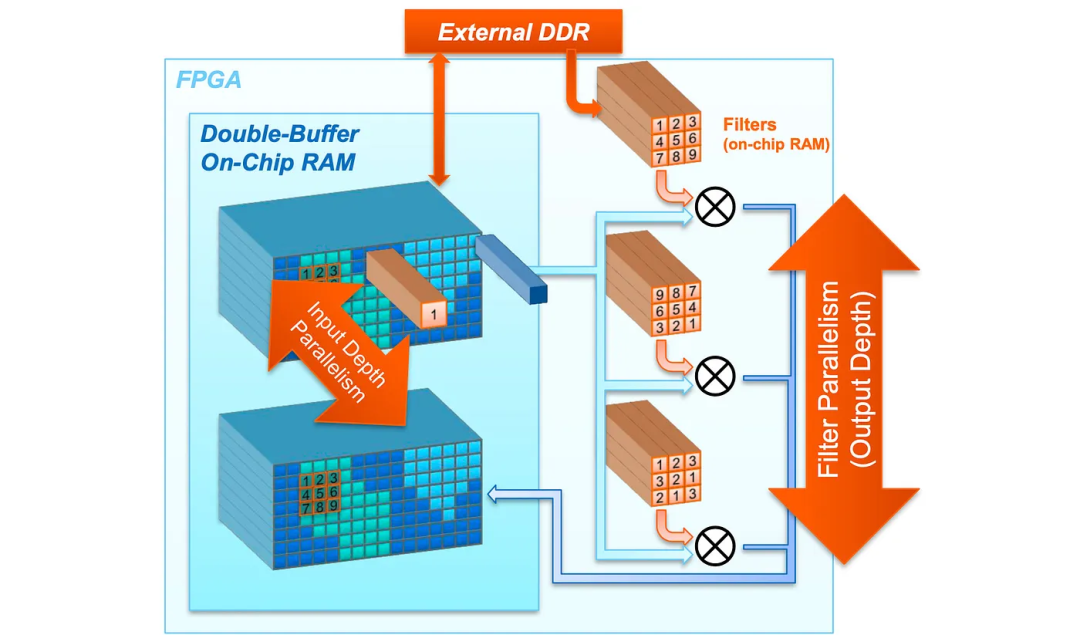
卷积的并行执行
为了增加卷积层处理过程的并行性,不同的卷积PE可以将滤波器分成若干部分并行处理。此外,可以使用向量运算将相同空间位置的特征图值与滤波器相乘以增加并发性。
-
Winograd变换
Winograd变换减少了卷积操作中所需的乘法次数。为了说明这点,我们举个例子,在这个例子中,我们对一个4×4图像(步长为1,零填充)应用一个3×3的滤波器。为了计算卷积,我们一次将滤波器窗口向右滑动一个像素,并对下面的3×3图像进行逐个分块乘法。卷积结果将是一个2×2的矩阵。传统上,我们将进行四次独立计算(如下所示),每次计算都需要进行9次乘法。这样总共需要进行36次乘法。

我们来看看这种方法的效率。对于这四个独立的计算,其中²/₃的图像数据是重叠的。但是,如果我们独立地计算它们,就无法利用这个重要的信息。从另一个角度来看,如果数据完全重叠,我们可以执行一次计算,而不是进行四次独立计算。
如何利用这个信息似乎并不明显。但是Winograd在40多年前解决了一个类似的问题。假设我们有两种预处理方法,将4×4数据和3×3滤波器分别转换为两个4×4矩阵(左侧下面的前两行):

然后我们将卷积应用于这两个转换矩阵。由于两者大小相同,卷积只需要进行16次乘法。最后,我们执行后处理转换,将其转换回2×2矩阵。结果表明,产生相同的卷积结果存在这样的预处理和后处理转换。更好的消息是,这些转换只涉及简单的加减运算,而不涉及乘法。因此,新的Winograd变换可以节省大量计算。
让我们用1-D数据和滤波器来来证明这个想法。
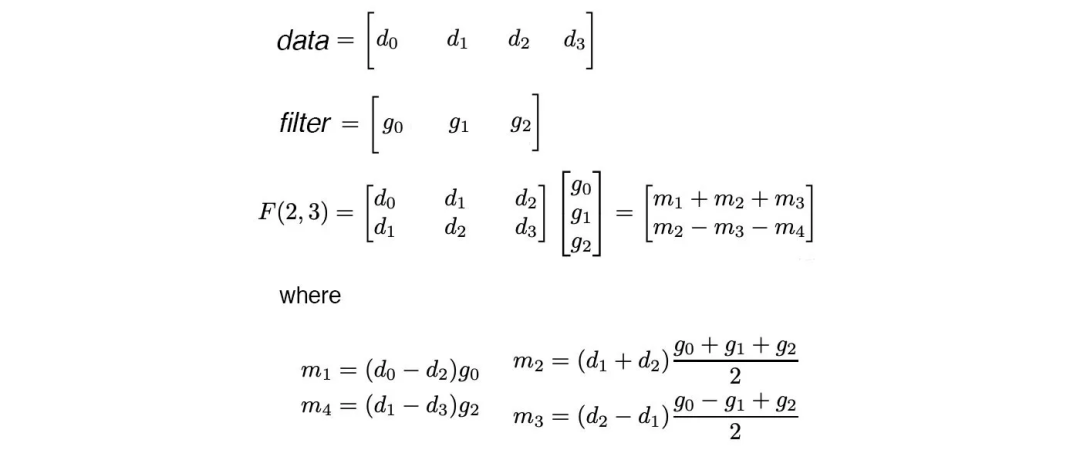
数据⊗滤波器的原始卷积方法涉及6次乘法。我们将合并预处理、卷积、后处理步骤,并展示它可以从上面计算m₁、m₂、m₃和m₄中推导出来。使用这个Winograd变换,我们只需要进行4次乘法。
为了完整起见,这里列出了所需的数学变换。可以使用简单的算术运算来完成预处理变换Gg、Bᵀ和后处理变换Aᵀ。

在FPGA中,可以在硬件中应用Winograd变换来加速卷积。

-
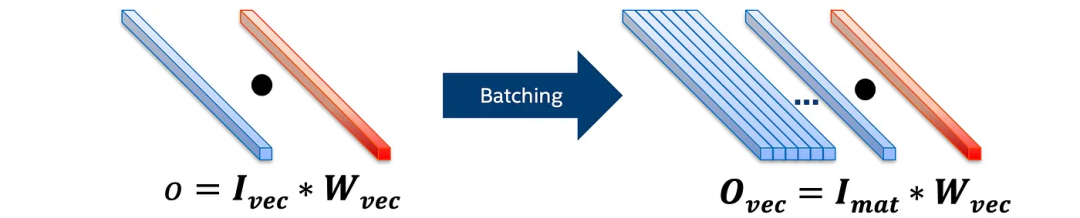
在全连接层中进行批量数据并行执行
在全连接网络中,为了增加并发性并减少权重的负载,我们可以同时处理一批图像(来自多个视频通道)。
-
特征缓存
在我们的流处理中,我们对输入和结果使用双缓冲区。对于下一次循环,我们只需切换这些缓冲区的使用(使用输入缓冲区作为输出,反之亦然),这就避免了需要将数据保存到芯片外存储器中。
-
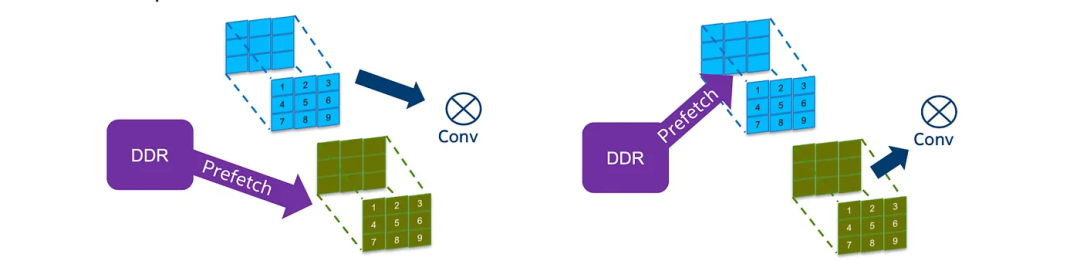
滤波器缓存
我们还可以使用双缓冲区,其中一个缓冲区存储当前卷积的权重,而另一个缓冲区用于预取下一个卷积的权重,以提高并发性。
-
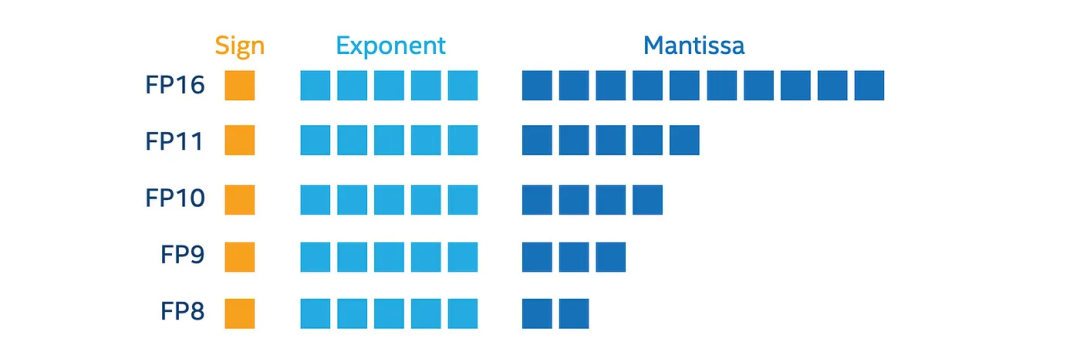
低精度
作为AI硬件设计的普遍趋势,供应商正在探索在推理中使用具有相同范围覆盖的低精度数据,例如下面的FP11将具有FP16相同的范围,但由于尾数较小,精度较低。在FPGA中用于推理的数据类型是可配置的,并且FPGA在创建不同数据大小的算术电路方面提供了很大的灵活性。
推荐书单
《微机原理与接口技术——基本原理、实用技术和基于FPGA的SOC技术》
《微机原理与接口技术--基本原理实用技术和基于FPGA的SOC技术(高等院校电子信息科学与工程规划教材)》系统地讲解了微型计算机系统的结构、工作原理、接口技术及其应用,特别是将这些内容与现代EDA技术、FPGA开发技术和SOC片上系统技术有机地融合起来,全方位强化和拓展了这一传统教学领域中的知识与技能传授的深度与广度。本书的基本内容包括80x86微处理器结构、指令系统、汇编语言程序设计、存储器系统、总线技术、中断技术、定时/计数接口技术和DMA技术、并行接口技术、串行接口技术、模拟接口技术和其他实用的接口技术,以及与这些内容相对应的基于超大规模F=PGA的SOC技术。本书可作为高等院校电子工程、通信、工业自动化、计算机等专业的本科生或研究生教材,也可用作相关专业技术人员的参考书。

精彩回顾
微信搜索关注《Java学研大本营》
访问【IT今日热榜】,发现每日技术热点















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









