







第四课:模型无关的预测
在进入正题之前,先说点题外话哈,等《David Silver课程学习笔记》系列更新完成之后,我们将会更新《PRML学习笔记》以及《RL学习笔记》,到时候希望大家多多指教哟~
在第三课中,我们介绍了动态规划方法(DP),提到DP既可用于预测,也可用于控制,但是不管怎么说,这种方法总是离不开模型的:

我们需要知道转移矩阵P和奖励函数R,这二者组成的元组即模型M。可是对于我们实际生活中的问题来说,总是不知道模型的,所以我们需要考虑一个问题:能不能不用模型,直接从与环境交互得到的样本中去估计给定策略的值函数(也即预测)?答案是可以,具体的方法就在下文中聊到。
1.蒙特卡罗方法
我们先来看一下著名赌城蒙特卡罗(也译作“蒙特卡洛”)的美景:

是不是非常美,我们的蒙特卡罗方法就是冯·诺依曼用这座赌城的名字命名的。这种方法的主要思想是“当所求解问题是某种随机事件出现的概率,或者是某个随机变量的期望值时,通过某种“实验”的方法,以这种事件出现的频率估计这一随机事件的概率,或者得到这个随机变量的某些数字特征,并将其作为问题的解。”
下面我们先对蒙特卡罗方法(MC method)进行总览:

需要知道的是,MC方法是一种模型无关的方法,不需要已知MDP的转移矩阵和奖励函数。此外,MC方法是从完整的episode中进行学习的,而不是bootstrapping的。episode可以理解为一次完整的实验,比如我们玩贪吃蛇游戏,撞到墙了或者咬到自己尾巴了或者一直吃食物,直到游戏结束,这都算是一次episode,得注意MC方法只能应用于episodic MDP,也即所有的episode都要可以终止,而不会无限运行;bootstrapping的意思则可以理解为某个状态对应的价值的更新用到了其他状态的值,而不是像MC方法一样,只是去使用总的期望奖励,或者说是回报。
从上面的解释可以发现,MC方法实质上就是利用回报的经验均值去代替期望。现在考虑一个问题,如果在某一个episode中,状态s出现了两次,分别在t1时刻和t2时刻,我们计算状态s的值时是仅用第一个还是两个都用呢?这就引出了两种不同的方法:
1)First-Visit Monte-Carlo Policy Evaluation:

这种方法就是我们上面说到的,在一个episode中如果状态s出现了两次,我们只用第一次出现的G_t进行计算。
2)Every-Visit Monte-Carlo Policy Evaluation:

在使用这种方法时,如果在一个episode中状态s出现了两次,一次在时刻t1,一次在时刻t2,则两次对应的G_t1,G_t2都要用于计算s对应的值。
不论是First-Visit还是Every-Visit,在计算回报均值时,都是利用总回报除以状态s的总访问次数的,我们能否对均值进行增量式的求取?

上面的ppt为我们展示了如何将一般的均值求取变为增量式均值求取的过程,我们可以很快地将其应用于MC方法中:

先说下stationary问题和non-stationary问题的概念,stationary问题就是说我们的MDP是不变的,比如转移矩阵,比如奖励函数,而non-stationary问题即随着时间的推移,MDP中的某些参数将会发生改变。这里我们将MC方法变为增量式,便可以使得我们的算法忘掉计数值N(t),而换为我们想要的类似于学习速率的参数,该参数的选择关乎算法的收敛性,这一点将在第五章中进行介绍。
再次强调一下,MC方法只能用于episodic MDP,也即所有的episode都要终止。不然我们算不了G_t,因为G_t是从t时刻开始,对整个episode的奖励进行累加的,显然,这种方法计算量会比较大,所以,引出了时间差分方法。
2.时间差分方法
与MC方法一样,时间差分方法(TD方法)也是直接从episode中进行学习,因而也是模型无关的,不过TD方法并不需要完整的episode,它是bootstrapping的。课程中,有一句话总结得很精彩:
TD updates a guess towards a guess.
现在我们将MC方法和TD方法进行对比,慢慢地就会体会上面这句话的含义。

从上面的对比我们可以发现,TD与MC最大的区别是将实际的回报换成了对于回报的估计,该估计被称为TD target,而这个值与当前值函数的差被称为TD error。因为这里是利用对于回报的估计作为我们更新时的目标,所以我们说TD方法是一次又一次的朝着猜测前进,关于这一点,我们可以利用一个简单的例子来进行说明:

这是一个职员下班回家对于自己的到家所需的总时间进行估计的例子,我们可以把时间看做奖励,便与我们所想要估计的值函数相吻合了,虽然这肯定不是奖励......毕竟大家都想早点回家。好了,言归正传,第一列是职员的状态,第二列是已经过去的时间,第三列是预测还需要多久才能到家,第四列是预测从下班离开办公室开始至回到家中所需要的总时间。利用MC方法和TD方法对预测所需的总时间进行估计,作图如下:
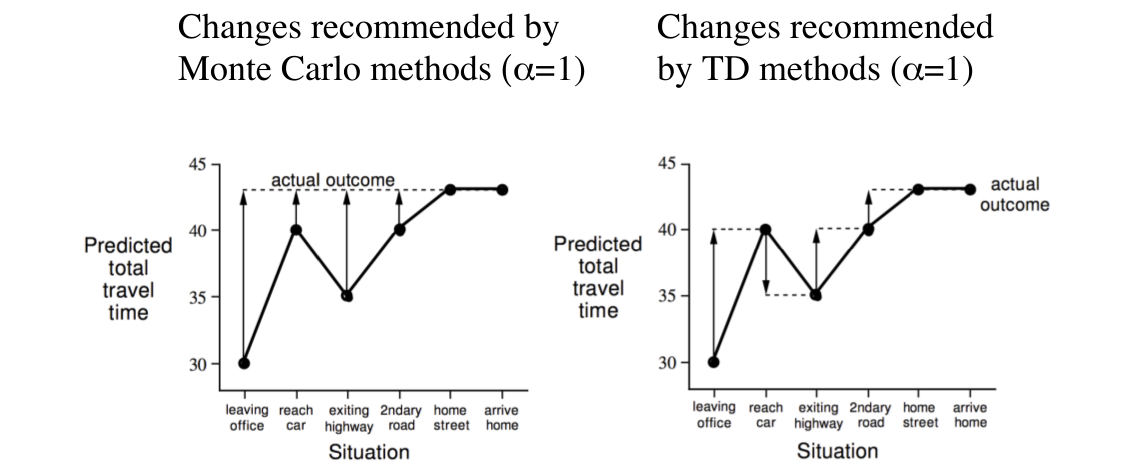
图中,实线(不带箭头的)表示当前时间步对于时间的预测,虚线表示target,也即我们更新时的参照物,对于MC方法来说是G_t,而对于TD方法来说是guess,也即上面的TD target,带箭头的实线则表示更新的方向。比如说,我们一开始离开办公室时预测的总时间是30,然后当到上车后,发现外面在下雨,所以职员觉得时间可能还要久一些,所以预测还需要35分钟到家,这时,距离开办公室已经过了5分钟,因此到家所需总时间为40分钟。后面的分析是一样的,当然,这些不是关键,关键是理解MC方法和TD方法在对值函数进行更新是所基于的目标不同。
接下来我们说一下TD方法的优缺点:
1)优点:TD方法能够在每一个时间步时对值函数进行更新,而不像MC方法那样,必须将整个episode跑完才能对值函数进行更新。也正因为如此,TD可以在continuing也即non-terminating环境中使用,而MC则不行;此外,TD方法的方差(variance)要比MC方法小得多,这也很好理解,因为MC方法中的回报G_t依赖于更多的随机动作,而TD方法中的TD target却仅仅依赖于一个随机动作。
2)缺点:TD方法中的target并不是V(s)的无偏估计(MC方法中的G_t是无偏估计),也就是说,TD对于V(s)估计是有偏差的(biased),当然这里所谓的有偏差是针对于V(s)不是真实值函数的情况。
总的来说,TD方法虽然是有偏的,但是却降低了方差,因而,我们需要在二者之间找到一个折中(Bias/Variance trade-off),关于折中的具体做法,在第3小节中将会讲到。下面给出二者更详细的对比:

对上面的几点进行一下分析,首先是收敛性,显然,MC方法的收敛性更好一些,毕竟该方法是一直向着right value更新的,这一特性同时让MC方法对初始值(值函数)不是那么敏感;而对于TD方法来说,在我们使用函数估计器对值函数进行估计时,并不能保证收敛,这一点在后面第六章中会讲到,同时由于TD target是V(s)的有偏估计,因此它对于初始值更加敏感一些。最需要知道的是TD方法比MC方法要高效多了,毕竟它每次计算TD target的计算量要比MC方法计算G_t的计算量小得多,除此之外,还有一个原因,就是在TD方法中,bootstrapping过程利用了类似于DP中的重复子问题的性质,所以效率会更高,不过这个性质对于non-Markov的环境就不那么有效了。
三幅图理解MC、TD与DP:

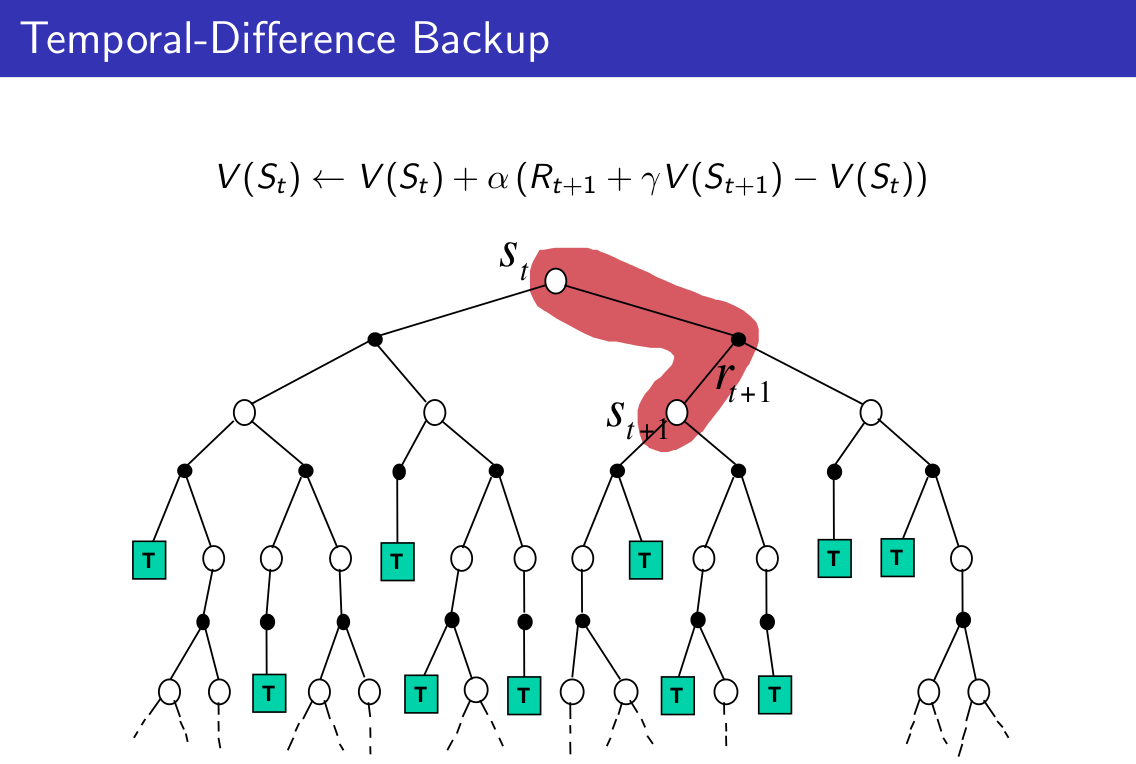

从上面三幅图的对比中可以得出下面的结论:
1)Bootstrapping:update involves an estimate
a)MC does not bootstrap
b)TD bootstraps
c)DP bootstraps
2)Sampling:update samples an expetation
a)MC samples
b)TD samples
c)DP does not sample(it's full-width)
我们可以在一张图上看一下暴力搜索、动态规划、蒙特卡罗方法、时间差分方法的关系:
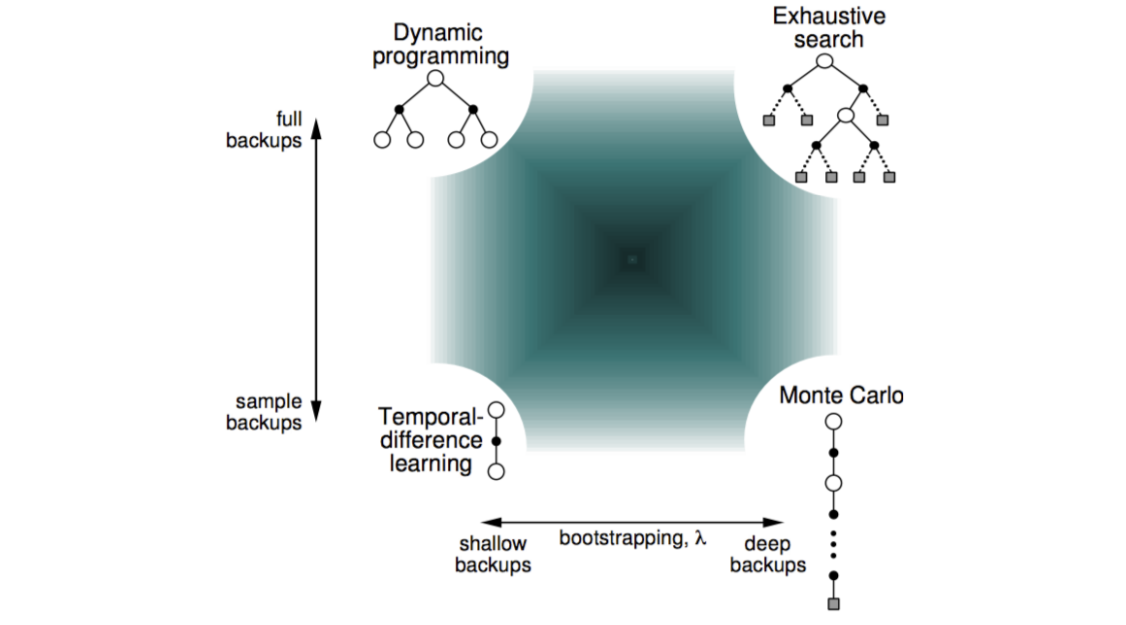
上图考虑了两个方面的差别与联系,一是full backups和sample backups,二是shallow backups和deep backups,这两个方面实际上就是上面的sampling和bootstrapping,这个图很值得收藏~
在这一小节的最后,讲一下Batch MC和Batch TD。我们上面说到,MC和TD(0)所估计得到的值函数都将收敛到策略对应的真实值函数,当然,这是在经验趋于无穷(也即无数次试验)的情况下达到的理想情况,但是实际中我们不可能达到,那如果我们利用有限的经验来对值函数进行估计将得到什么样的结果?比方说,对于下面这K个episode:
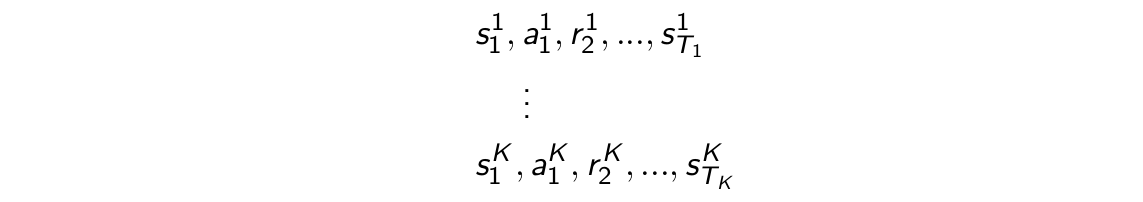
我们重复从这K个episode中进行采样,对于某一次采样得到的样本k应用MC或者TD(0)方法,将会有下面结论:
1)MC方法中的值函数将收敛到使均方误差最小的解;
2)TD(0)中的值函数将收敛到极大似然Markov模型对应的解。
下面举个例子:

以V(A)计算为例,对于MC方法而言,为了让我们的值函数与G_t的均方误差最小,V(A)=0;而对于TD(0)而言,首先对Markov进行建模,所得到的模型如上图,V(A)收敛于该模型的解,也即V(A)=1*0.75*1+1*0.25*0=0.75。
给出具体的式子:

3.时间差分方法的扩展
前面我们聊到了MC方法和TD方法,其中TD方法是利用R_(t+1)和V(S_(t+1))来估计V(S_t),而MC方法则是相当于把当前时刻t到无穷的所有的奖励都加起来了,那能不能说考虑一种介于两者之间的target呢?

我们可以将n-Step return考虑为从当前时间点,往未来考虑n步,想想自己在这n步中会得到多少奖励,然后加上站在n步之后那个点可能得到的奖励,关于这一点在后面进行讨论。
既然我们可以考虑n-Step return,那将两个或者多个这样的return结合起来或许又会有意想不到的惊喜:

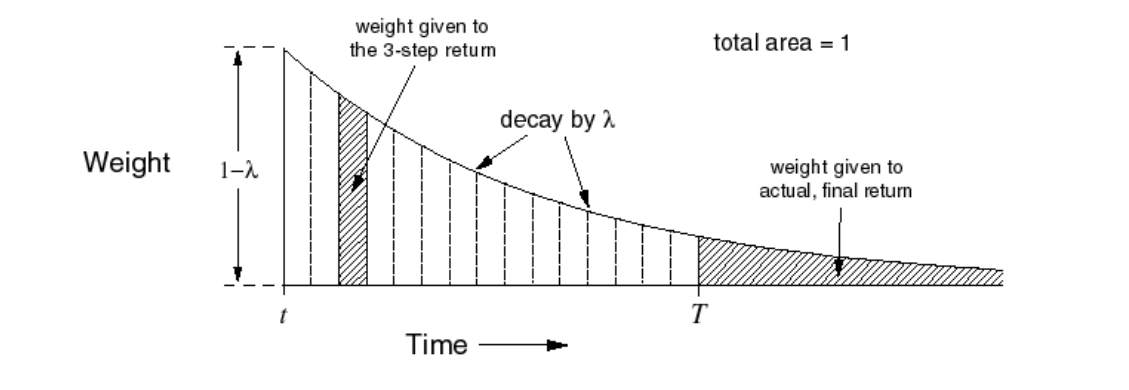
这里我们对所有的n-step return按指数分布进行加权,指数分布使得该式子在计算上更有效率,关于指数分布的具体介绍可以参考百度百科。
直观上的权重分布:
在我们对扩展TD算法进行解读之前,先给出资格迹的定义:
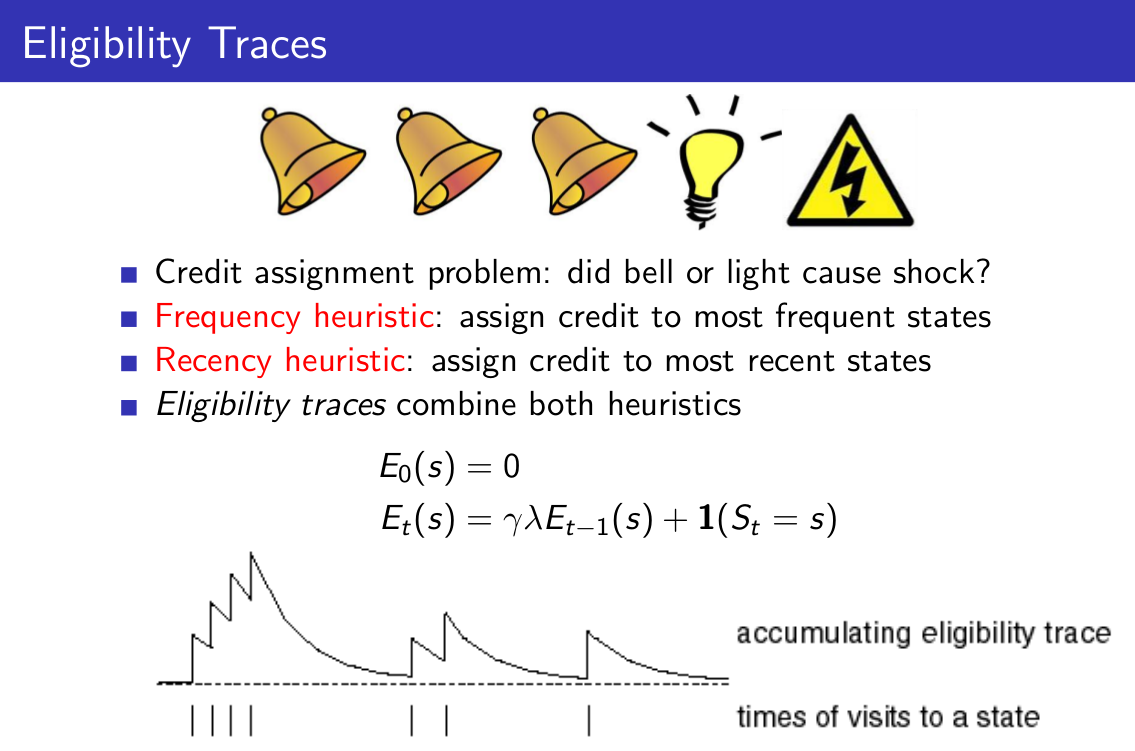
资格迹的提出是基于一个Credit assignment问题的,打个比方,最后我们去跟别人下围棋,最后输了,那到底该中间我们下的哪一步负责?或者说,每一步对于最后我们输掉比赛这个结果,分别承担多少责任?这就是一个Credit assignment问题。对于小鼠问题,小鼠先听到三次铃声,然后看见灯亮,接着就被电击了,小鼠很生气,它仔细想,究竟是铃声导致的它被电击,还是灯亮导致的呢?如果按照事件的发生频率来看,是铃声导致的,如果按照最近发生原则来看,那就是灯亮导致的,但是,更合理的想法是,这二者共同导致小鼠被电击了,于是小鼠为这两个事件分别分配了权重,如果某个事件s发生,那么s对应的资格迹的值就加1,如果在某一段时间s未发生,则按照某个衰减因子进行衰减,这也就是上面的资格迹的计算公式了。
接着我们对TD算法给出两种视角的解读(两种视角也对应着两种不同的实现方法):
1)前向视角:
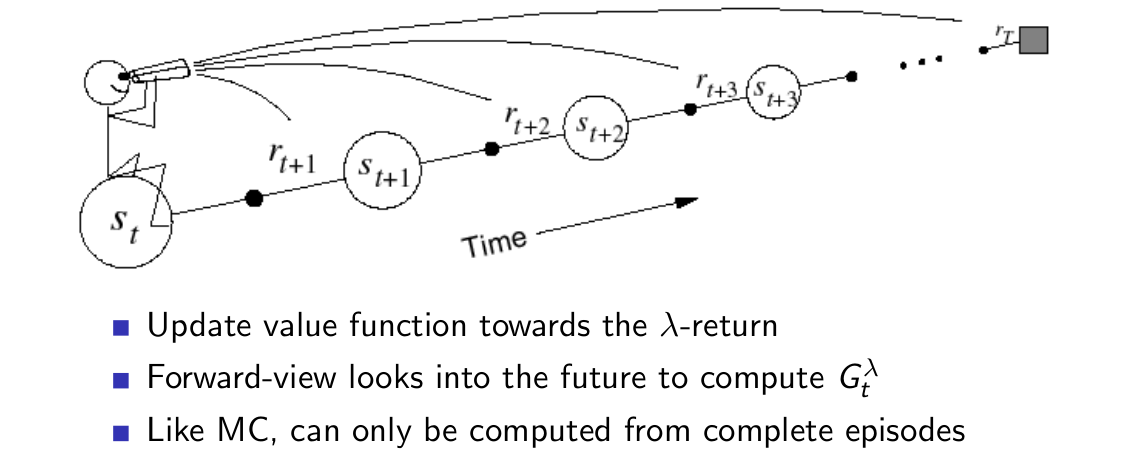
以前面定义的G作为更新的target,由于G是结合了所有的n-step return的,其中自然也就包括了MC的target,因此与MC方法一样,前向视角方法也只能应用于episodic问题。
2)后向视角:
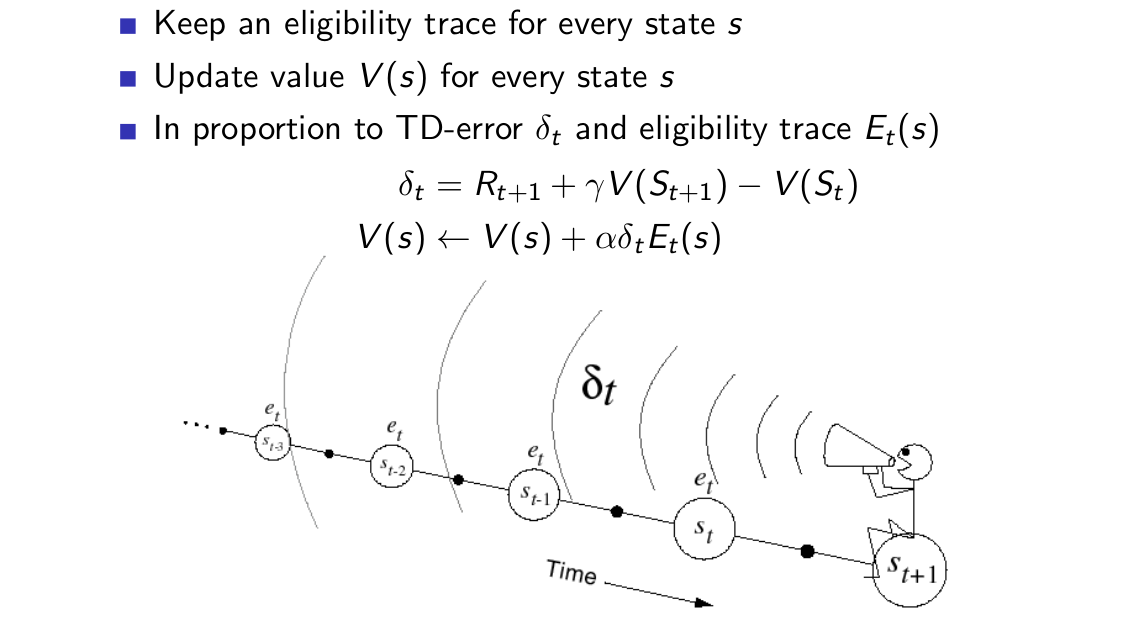
后向视角使用了我们刚刚定义的资格迹,每个状态s都保存了一个资格迹,并且利用这个资格迹对TD(0)方法进行一些修饰,便有了上面的公式,我们可以将资格迹理解为一个权重,状态s被访问的时间离现在越久远,其对于值函数的影响就越小,状态s被访问的次数越少,其对于值函数的影响也越小。
对后向视角考虑得更深入一些:

先假设在某个episode中,状态s在k时刻被访问了一次,此时按照上面的计算,可以知道当整个episode完成时,后向视角方法对于值函数V(s)的增量等于labmda-return;如果状态s被访问了多次,那么资格迹就会累积,从而相当于累积了更多的V(s)的增量。这直观地解释了前向视角和后向视角的等价性。
需要特别注意的是,上面的PPT中对error进行求和之后,得到与lambda-return一致的形式,而对于前向视角而言,V(s)是对lambda-return进行累加呀,为什么这里用后向视角的error求和与lambda-return单项对比呢?因为这里的累加只是表示对于状态s的单次访问对于后续时刻的持续性影响,这种影响并不是仅仅在某一个时间点的,而是说从时刻k开始,后续的TD-error都与这次对于状态s的访问有关。我们反过来想一下,也就是说,从每个时刻的TD-error来看,它需要去寻找为它负责的状态,然后发现,状态s1在之前访问了1次,状态s2在之前访问了2次,状态s3没有访问......于是它就依此计算资格迹,从而对各个状态的值函数进行更新。我有一种不太恰当的比喻:我们可以将TD-error想做收益,这样似乎好理解一些,假设TD-error是一种收益,“TD后向视角公司”今天收益了TD-error,现在要论功行赏,发现状态s1出勤1次,状态s2出勤2次,状态s3没有出勤,于是依此计算分红,分配到各个状态的累积奖金池(V(s))中,由于“TD后向视角公司”是每天一次分红,所以并不需要知道公司往后究竟是倒闭还是赚到越来越多的钱,我们只需要知道今天的利益如何分配就行。而“TD前向视角公司”的高层则觉得,公司应该估算一下未来每一天可能的总收益,然后按照指数平均一下,从而来为各状态分红,由于需要考虑到最终的Terminal state,所以只能在episodic MDP上使用。(博主注:我的这个例子并不是特别恰当,如果有建议可以提出来哈)。按照前面这样来理解的话,就可以很容易的想清楚为什么后向视角的TD(lambda)并不限于episodic MDP了,毕竟它是将当前时刻的TD-error按资格迹来分配到每个状态,然后对状态更新的。
下面直接放两张ppt~


总的来说,前向视角方法是一种理论方法,更直观,更容易理解,后向视角方法是一种工程方法,更容易实现,毕竟前向视角方法总是要等到整个episode结束,而后向视角方法却可以在每一个时间步进行更新。
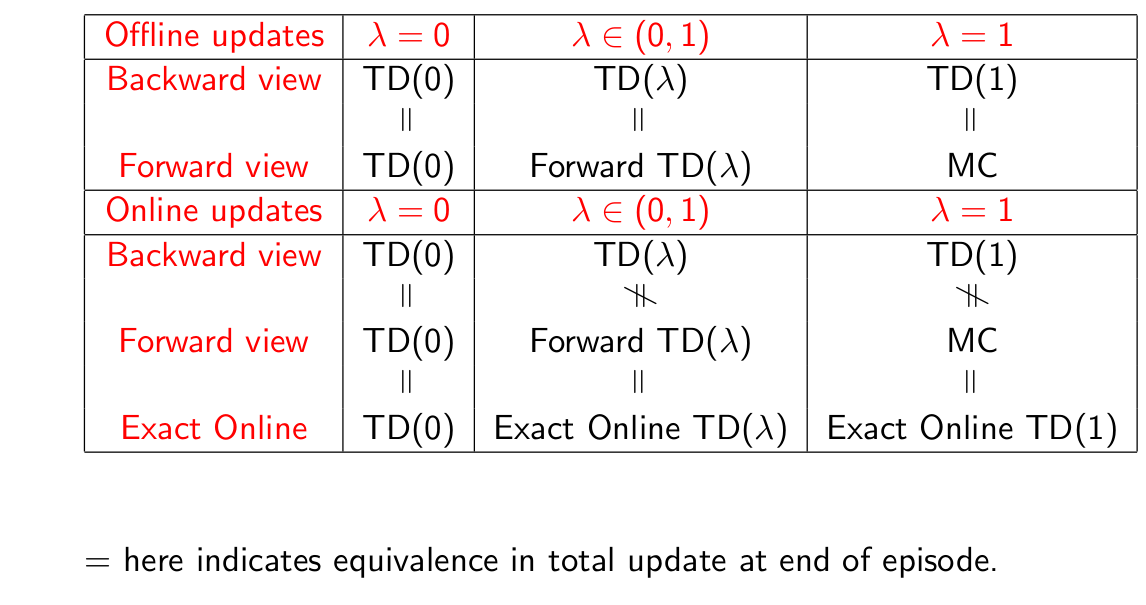
最后是对于扩展时间差分方法的总结:















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









