







在监督学习中,我们通常会定义一个目标函数来衡量模型的好坏,定义一个风险函数从而计算模型预测结果与真实值之间的误差是一种惯用手段。一般而言,我们将考虑训练集上的训练误差和测试集上的泛化误差,事实上,训练误差的持续降低并不是那么令人愉快,因为这可能是“过拟合”在背后操纵着一切。总的来说,只有泛化误差的降低才能真的让人感觉美滋滋。
如果给我们一个模型,我们该从什么方面去降低泛化误差呢?等会讨论的泛化误差上界便对此进行了释疑。
首先我们囤一些知识:
1)损失函数:
2)期望风险:
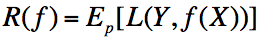
3)经验风险:

4)Hoeffding不等式:
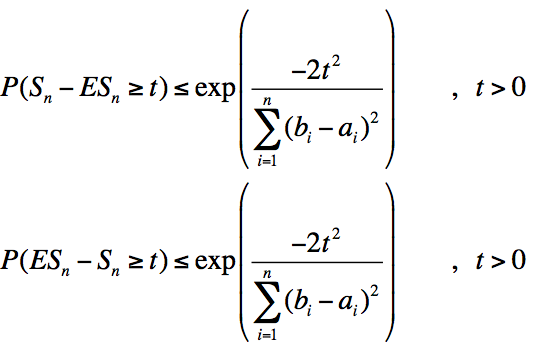
其中为独立随机变量

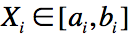
Hoeffding不等式有很多个版本,上面这个版本阐明了随机变量之和与与其期望偏差的概率上限。当然,我们也可以通过变量替换写为如下形式:
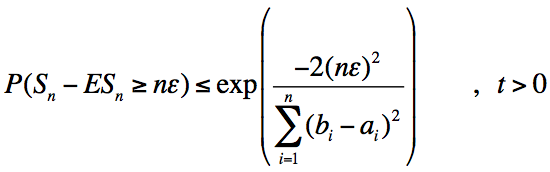
如果所有随机变量的范围都是[0, 1],则b - a =1,此时有:

这样我们就得到了随机变量
下面我们举例对泛化误差的上界进行推导,以二类分类问题的泛化误差上界为例。
考虑二类分类问题,训练数据集
中独立同分布产生的,
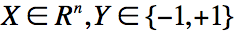
,d为函数个数。设是从
中选取的函数。损失函数是0-1损失。我们知道经验风险是N个独立随机变量

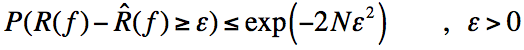
我们知道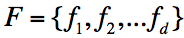
中的任意一个函数
作为模型时的泛化误差的概率上限,如果要求
中存在某个函数
符合这一式子,则由概率的加和规则可得:

于是,我们可以得到:
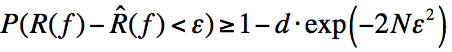
进行变量替换:
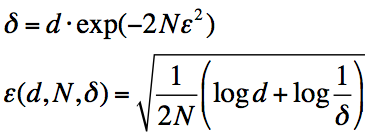
得到:
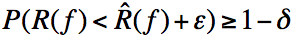
也即说明,至少以概率有
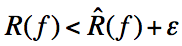
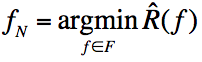
则有:

我们可以将期望风险看做泛化误差,而经验风险则是训练误差,那么由上式可知:1)训练误差越小,则泛化误差越小;2)样本容量N越大,则训练误差与泛化误差越接近;3)假设空间中包含的函数越多,则泛化误差上界越大。
事实上,关于泛化误差的上界关系式,最需要知道的是,N越大,则训练误差与泛化误差越接近。实际上这与我们通常理解的以经验频率去逼近概率或者以经验均值去逼近期望是一致的。















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









