







SPP-net
论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
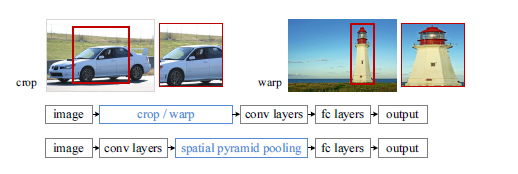
在R-CNN中,要求输入固定大小的图片,因此需要对图片进行crop、wrap变换。此外,对每一个图像中每一个proposal进行一遍CNN前向特征提取,如果是2000个propsal,需要2000次前向CNN特征提取,这无疑将浪费很多时间。
该论文对R-CNN中存在的缺点进行了改进,基本思想是,输入整张图像,提取出整张图像的特征图,然后利用空间关系从整张图像的特征图中,在spatial pyramid pooling layer提取各个region proposal的特征。
-------------------------------------------------------------------------------------------------------------------------------------------------------
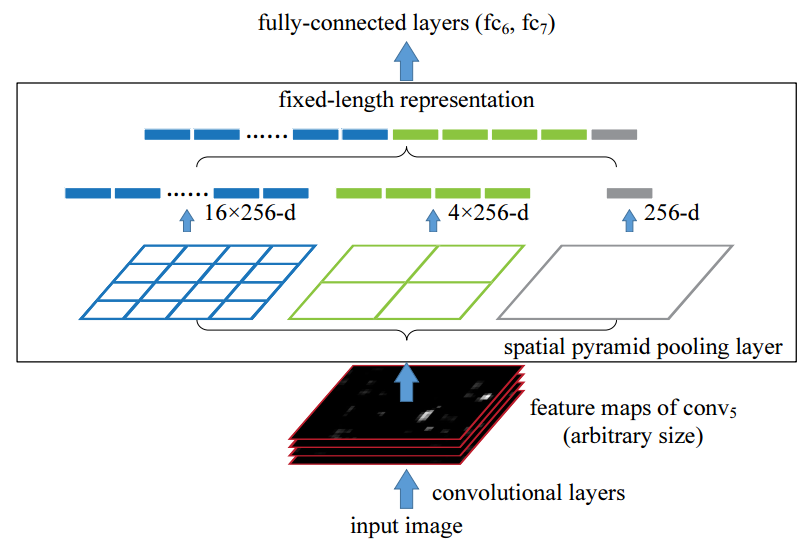
spatial pyramid pooling layer
在传统的CNN中,卷积层不需要输入固定大小的图像,并能产生任意大小的特征图,但是全连接层要求输入固定大小的图像。因此,该论文提出了将最后一个卷积层后的池化层替换为spatial pyramid pooling layer(SPP层), 该层能够生成长度固定的特征,并输入到全连接层。因此,SPP-net适合输入大小不同的图像。
spatial pyramid pooling layer的结构如下图,类似于金字塔:
-----------------------------------------------------------------------------------------------------------------------------------------------------
多尺度训练
为了能够输入任意大小的图像,在训练网络时,采用了多尺度输入,如:224*224, 180*180,其中,180*180图像是从224*224图像变换的到的。构建两种CNN模型,一种模型的输入大小为224*224,另一种模型的输入大小为180*180,而且这两个模型共享参数。
------------------------------------------------------------------------------------------------------------------------------------------------------
将图像ROI映射到feature map上
SPP-net 是把原始ROI的左上角和右下角映射到 feature map上的两个对应点。有了feature map上的两个角点,就确定了对应的 feature map 区域,如下图:
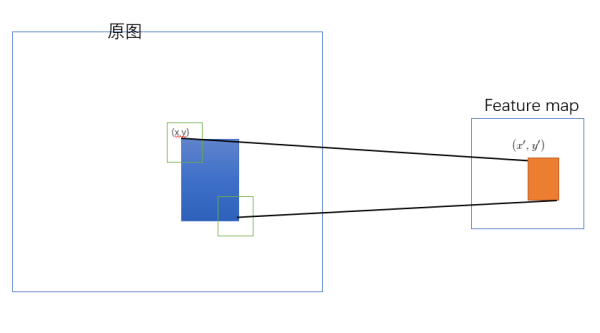
该模型从第一个卷积层到最后一个卷积层,包括中间的池化层,计算各个层stride的乘积s ; (x’, y’)表示特征图上的坐标点,(x , y)表示原输入图片上的坐标点,那么每个矩形候选框的左上角、右下角在特征图上的对应点:
左上角: x’= ⌊x/s⌋ + 1 y’= ⌊y/s⌋ + 1
右下角: x’= ⌈x/s⌉ + 1 y’= ⌈y/s⌉ + 1















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









