







思考:当你有一个包含数据所有信息的 JSON 文件的时候,怎么加载到 MONAI 框架里面?
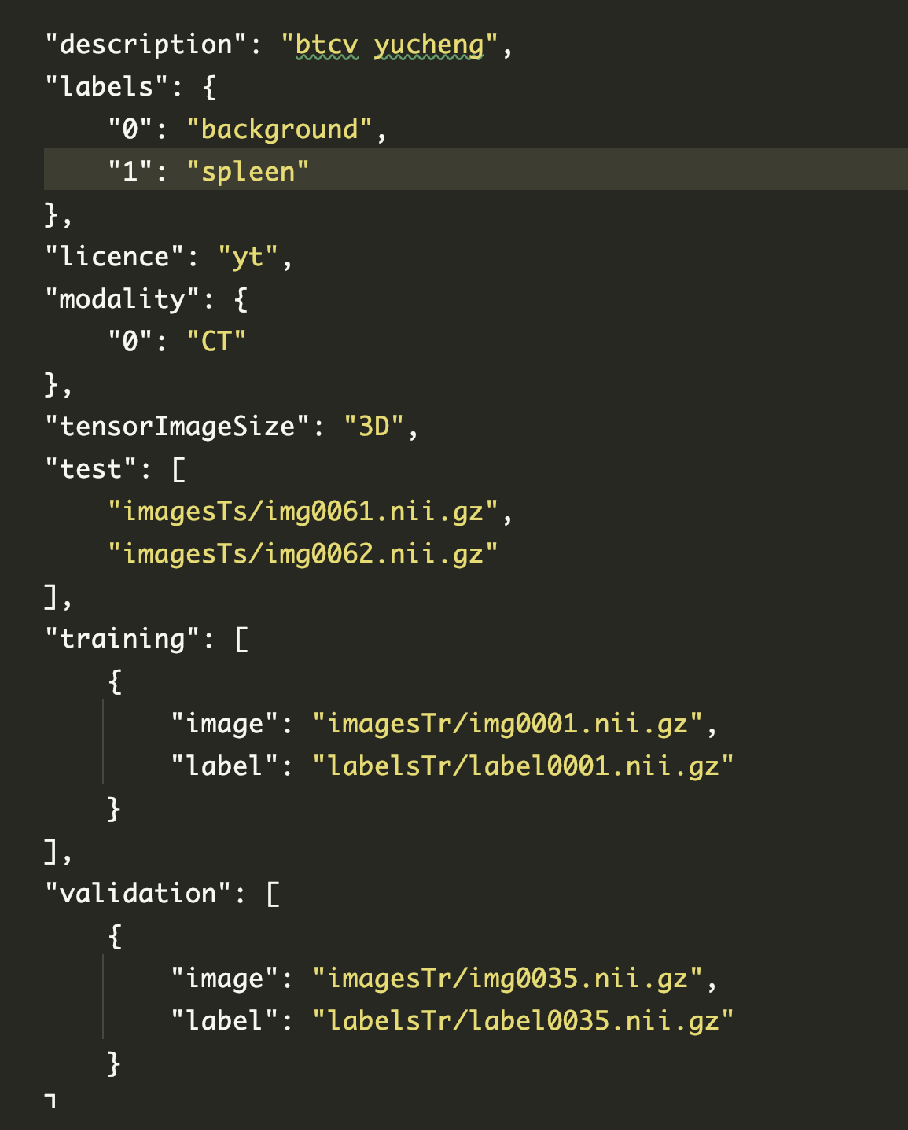
如图所示,从这个json文件里可以知道数据的label信息,每个类别的真实含义。以及它的模态是CT,图像是3D 并且把训练集、验证集和测试接包含的图像地址都写上了。
我们只要通过这个文件就可以把数据喂给模型。
在 MONAI 里确实提供了加载 json 格式数据的方式。非常方便。
同理,我们可以把自己的数据也写成 json 格式加载。
本节教程将涉及这两个内容,感兴趣的一起来看看吧
load_decathlon_datalist 加载数据
哪里调用?
from monai.data import load_decathlon_datalist
函数参数
load_decathlon_datalist(data_list_file_path: PathLike,is_segmentation: bool = True, data_list_key: str = “training”, base_dir: Optional[PathLike] = None,)
Args:
- data_list_file_path: the path to the json file of datalist. 你的 json 文件地址
- is_segmentation: whether the datalist is for segmentation task, default is True. 是否是分割任务
- data_list_key: the key to get a list of dictionary to be used, default is “training”. 你要加载哪个数据集(traning, validation, test), 这里的key值得是 json 文件中对应数据集名字(看上图)。
- base_dir: the base directory of the dataset, if None, use the datalist directory.数据的主目录。从图片可以知道,数据的地址是从imagesTs/imagesTr/labelsTr 开始的。而这些地址的上一级地址需要提供。不填写的话,默认和json文件在同一个目录下。
演示示例:
我在tested.py文件里加载数据
from monai.data import load_decathlon_datalist
data_dir = "dataset/dataset.json"
datalist = load_decathlon_datalist(data_dir, True, "training
# datalist = load_decathlon_datalist(data_dir, True, "training", 'dataset') 加上base_dir
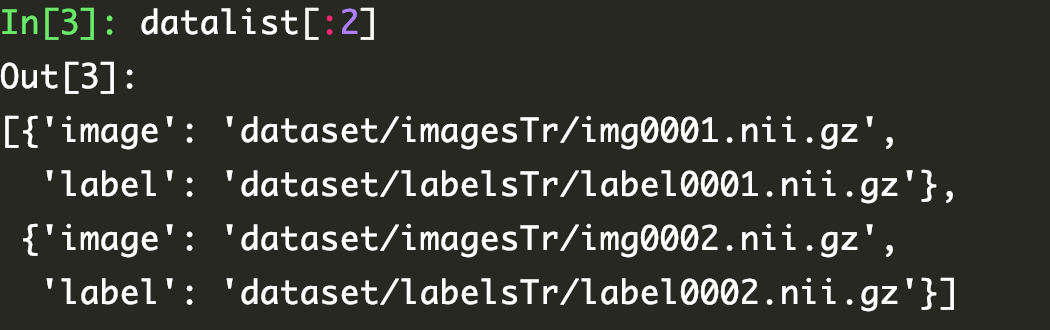
这样,符合 MONAI data 的字典就创建好了。
我们可以看到,有这个 json 文件,我们可以很方便的创建数据。
接下来,我们看一下如何创建这个json文件
创建数据 json 文件
from collections import OrderedDict
import json
json_dict = OrderedDict()
json_dict['name'] = "your task"
json_dict['description'] = "btcv yucheng"
json_dict['tensorImageSize'] = "3D"
json_dict['reference'] = "see challenge website"
json_dict['licence'] = "see challenge website"
json_dict['release'] = "0.0"
json_dict['modality'] = {
"0": "CT",
}
json_dict['test'] = [
"imagesTs/img0061.nii.gz",
"imagesTs/img0062.nii.gz",
"imagesTs/img0063.nii.gz",
"imagesTs/img0064.nii.gz",
"imagesTs/img0065.nii.gz",
"imagesTs/img0066.nii.gz"] # 把包含数据的列表写进来。
# 想保存什么信息,在json_dict里面增加一个字典数据即可
# 保存json
with open(os.path.join(out_base, "dataset.json"), 'w') as f:
json.dump(json_dict, f, indent=4, separators=(',', ': '))
文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连

















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











