







关键词
span representation
来源
arXiv 2016.10.31
问题
之前利用 match-LSTM 对 passage 打标签:要么是 span start,要么是 span end,要么是 end。这种方法对子结构并没有做独立性假设,所以在 greedy training 和 decoding 时容易产生搜索错误。
而直接枚举所有 span 可能,这会导致难以训练。
为了克服这些问题,文中提出构建固定长度表示的 span representation,并且为公共子结构重复利用 recurrent 计算结果。
文章思路
Recurrent Span Representations 这一模型分成三步:
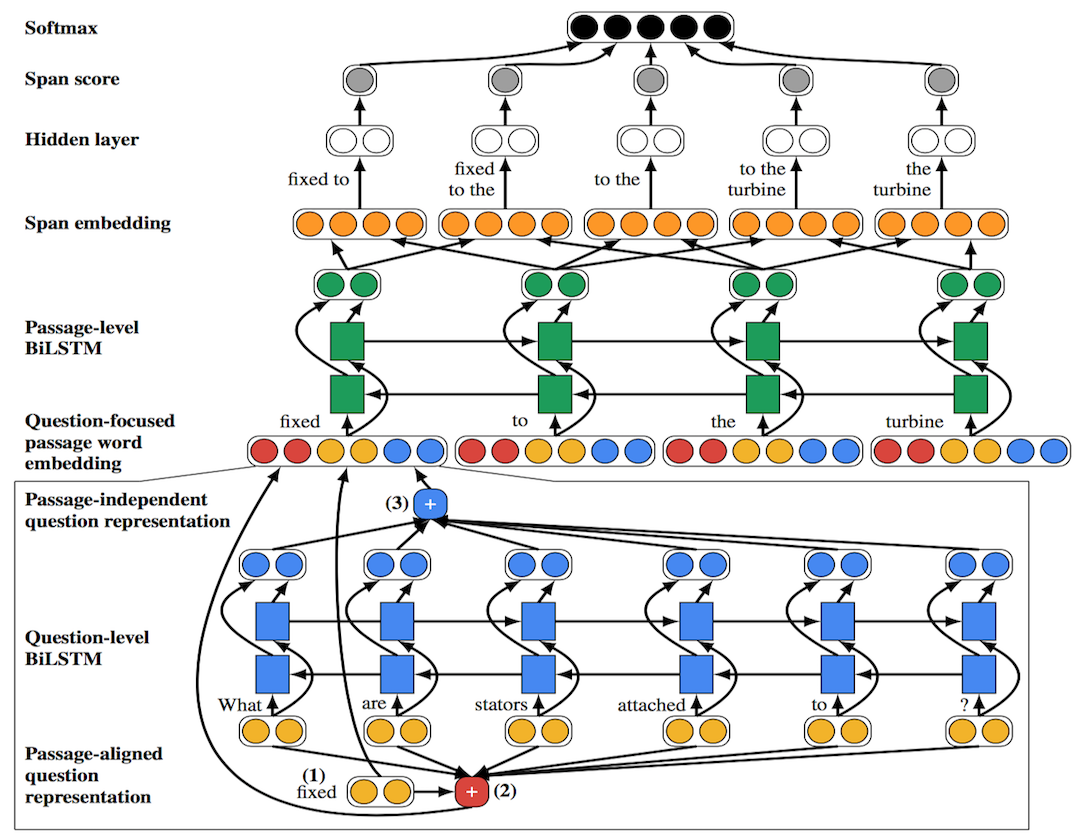
首先通过 look up table 得到 passage 和 question 中每个词的 pretrain embedding: pi 和 qj
-
Question-Focused Passage Word Embedding
-
利用
Parikh et al.(2016) 提出的 neural attention 计算 passage-aligned question representation
sij=FFNN(pi)⋅FFNN(qj)aij=exp(sij)∑nk=1exp(sik)qalign=∑j=1naijqj
然后利用 Li et al.(2016) 计算 passage independent question representation
q′1,…,q′n=BILSTM(q)sj=wq⋅FFNN(q′j)aj=exp(sj)∑nk=1exp(sk)qindep=∑j=1najq′j
基于以上,可以得到这一步最终 embedding: p∗=[pi,qaligni,qindep]
Recurrent Span Representations
-
这一步很简单,就是先将上面得到的结果经过 Bi-LSTM 处理后,然后把 span 端点的词拼接起来得到 span representation
ha
:
{p∗′1,…,p∗′m}=BILSTM({p∗1,…,p∗m})ha=[p∗′astart,…,p∗′aend]
Scoring Answer Spans
-
对所有的 span representation 打分
sa=wa⋅FFNN(ha)p(a|q,p)=exp(sa)∑a′∈A(p)exp(sa′)
资源
论文地址:https://arxiv.org/abs/1611.01436
数据地址:https://rajpurkar.github.io/SQuAD-explorer/
相关工作
neural attetion variant 2种
简评
这一模型最终在 development set 上获得了 74.9% 的 F-score,ensemble 之后提高到了 76.7%。之后分析了一下模型细节,如果只用 passage-independent 表示,效果大概会降低 20 个点;如果只用 passage-aligned 表示,效果只会降低 3 个点。
模型利用任务简单性,枚举出所有 span 候选,发现当 span 长度增大时,模型效果呈下降趋势。
最后指出模型的一个缺点:能够找到文章和问题重叠的短语作为答案,但是不能够表示语义依赖性。这种缺点也是直接计算相似度这种方法的共有缺点。















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









