







这篇博客主要列个引导表,简单介绍在深度学习算法中损失函数可以改进的方向,并给出详细介绍的博客链接,会不断补充。
1、Large Marge Softmax Loss
ICML2016提出的Large Marge Softmax Loss(L-softmax)通过在传统的softmax loss公式中添加参数m,加大了学习的难度,逼迫模型不断学习更具区分性的特征,从而使得类间距离更大,类内距离更小。核心内容可以看下图:
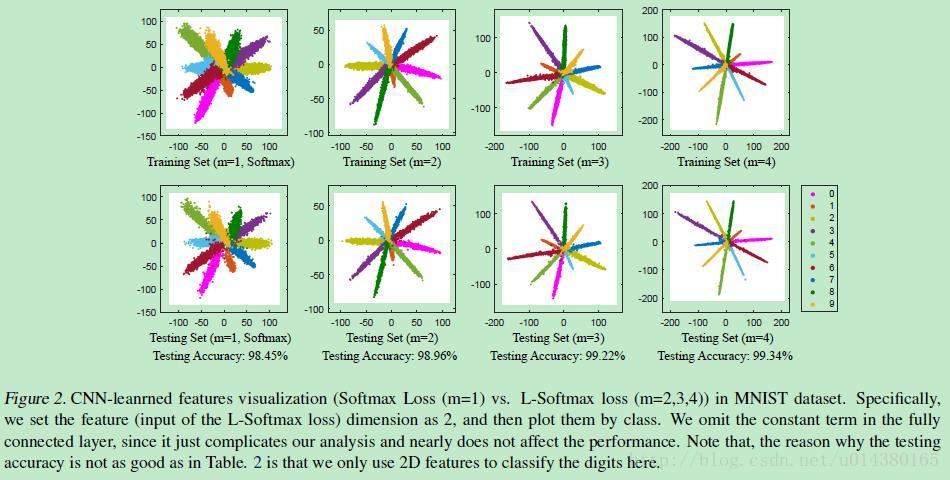
详细了解可以参看:损失函数改进之Large-Margin Softmax Loss
2、Center Loss
ECCV2016提出的center loss是通过将特征和特征中心的距离和softmax loss一同作为损失函数,使得类内距离更小,有点L1,L2正则化的意思。核心内容如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









