






【LLM学习之路】9月25日26日27日 第十二、十三、十四天 Transformer Encoder
Encoder 负责将输入的词语序列转换为词向量序列,Decoder 则基于 Encoder 的隐状态来迭代地生成词语序列作为输出,每次生成一个词语。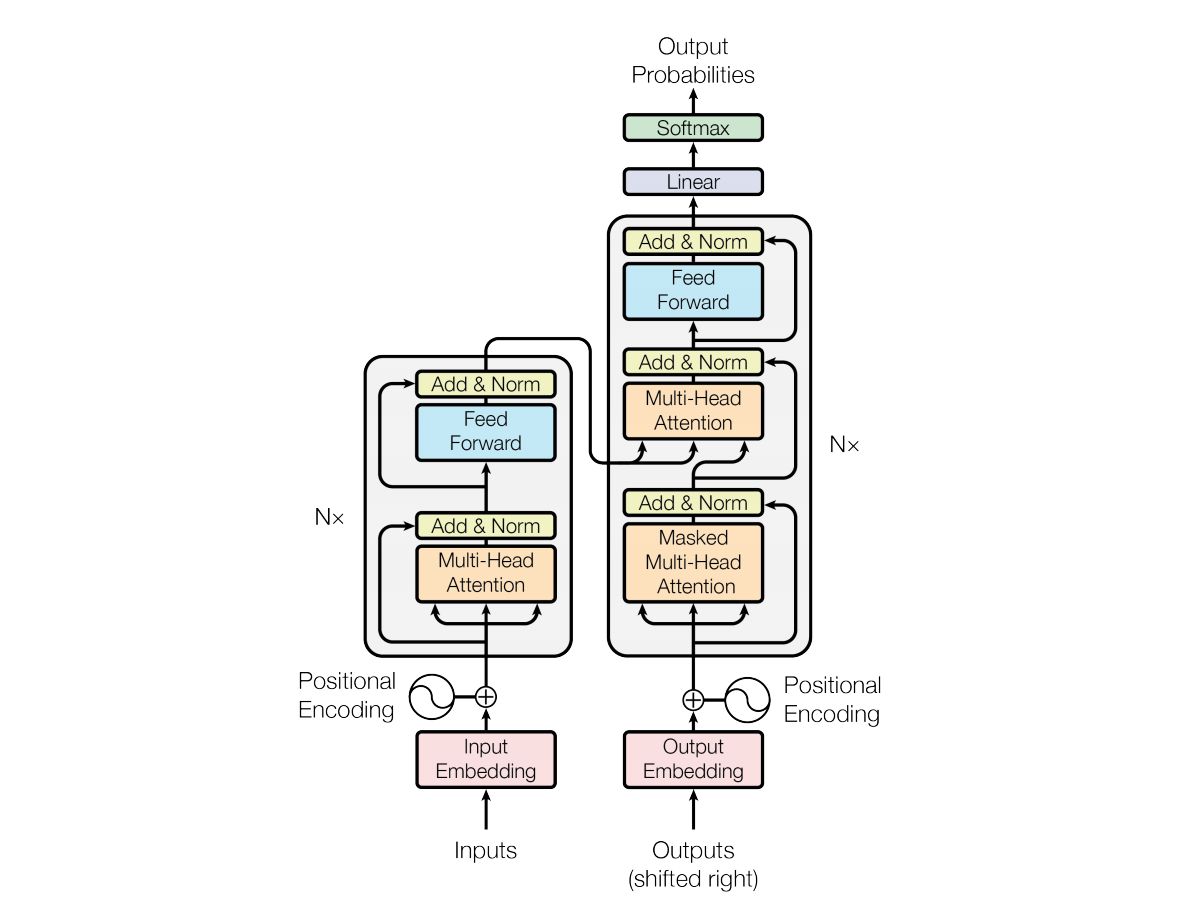
王木头
词向量,使用高维向量的码
如何得到高维向量的码?
tokenizer标记器 和 独热编码
标记器是给每一个不同的token分配一个独立的id,相当于把所有token投射在一维的数轴上
信息过于密集,很难体现词之间的关系
独热编码,有多少词就有多少维度,信息过于稀疏,信息都是正交的,很难体现出词与词之间的联系
升维降维的例子
做中英文翻译的时候,把中英文的内容都升维到一个连续的浅空间
Word2Vec
别的模型是为了完成某个任务,比如识别猫和狗。Word2Vec是为了得到嵌入矩阵,目标不是得到模型的结果,而是模型的参数,得到Token投射到嵌入空间的方法。
编码和解码的原理
输入一个token编码成词向量,词向量又可以解码变成token
CBOW
有5个(奇数个)词向量,扣去中间那个词向量,剩下的词向量与同一个嵌入矩阵相乘,变成浅空间的词向量,再把4个向量加在一起变成一个向量,再对这个和向量进行解码,损失函数就会定量去看解码的token和挖掉的token是不是一样的,如果是一样的就不需要修改参数。(类比力的合成和分解)
skip-gram
把CBOW的原理反过来,已知一个token,求出上下文token的分量
Transformer代码
The Feed-Forward Layer
它单独地处理序列中的每一个词向量,常见做法是让第一层的维度是词向量大小的 4 倍,然后以 GELU 作为激活函数。
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear_1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear_2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear_1(x)
x = self.gelu(x)
x = self.linear_2(x)
x = self.dropout(x)
return x
在 Transformer 中,前馈子层的基本流程如下:
- 输入经过第一层线性变换:将输入从
hidden_size映射到intermediate_size,通常intermediate_size比hidden_size大得多(例如,BERT 中常用intermediate_size是hidden_size的 4 倍)。 - 激活函数:一般使用 GELU 或 ReLU 来引入非线性。
- 第二层线性变换:将经过激活的输出重新映射回
hidden_size,以保证输入输出维度一致。 - Dropout:用于正则化,防止模型过拟合。
总的来说,前馈子层在 Transformer 中的角色:
- 增强特征表示能力。
- 提供非线性变换来改善模型的表达能力。
- 通过 Dropout 减少过拟合风险。
Layer Normalization
是一种用于深度学习模型的正则化技术,旨在提高训练的稳定性和加速收敛
超强动画演示,一步一步深入浅出解释Transformer原理!这可能是我看到过最通俗易懂的Transformer教程了吧!
https://www.bilibili.com/video/BV1tSHVeYEdW/?spm_id_from=333.337.search-card.all.click&vd_source=bbed391c708140d6846630627f7576d8
位置编码
词义信息和位置信息合成为一个合成向量,输入到transformer的编码器encoder
词嵌入加入词义信息
位置编码加入位置信息
除了跟踪词义和位置以外,跟踪词与词之间的关系也非常重要
词义信息和位置信息加入编码器
注意力机制query向量和key向量来计算词与词之间的关系
还有词义和位置信息的编码信息得到value向量
注意力分数和每个词的词向量加权平均,就得到新的自注意力向量head向量,包含了词义、位置、词与词之间关系的三重信息的向量
多头注意力机制
512个维度拆成8个,8个不同的角度来观察数据
最终获得了8个头向量,组装成一个新的长向量,
长向量再为给神经网络,再来一次神经变换
最终获得多头注意力向量
残差链接和层归一化是训练神经网络的常规操作
残差链接就是加原始向量,至少数据不会被嚼坏
层归一化
前馈神经网络
先升维 512维升2048维
引入非线性
降维 2048维降至512维度
为了反向传播梯度下降更稳定
掩码多头自注意力机制,将遮盖部分设置为负的很大的数字,softmax就会忽略掉
一个词就会有768个维度
GPT-3有12288维度
ai已经是黑盒,无法解释
前馈神经网络
就是简单的神经网络















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









