









CooGAN: A Memory-Efficient Framework for High-Resolution Facial Attribute Editing

目录
CooGAN: A Memory-Efficient Framework for High-Resolution Facial Attribute Editing
Cascaded Global-to-Local Face Translation Architecture
Abstract
In contrast to great success of memory-consuming face editing methods at a low resolution, to manipulate high-resolution (HR) facial images, i.e., typically larger than 7682 pixels, with very limited memory is still challenging.
This is due to the reasons of 1) intractable huge demand of memory; 2) inefficient multi-scale features fusion.
To address these issues, we propose a NOVEL pixel translation framework called Cooperative GAN (CooGAN) for HR facial image editing.
This framework features a local path for fine-grained local facial patch generation (i.e., patch-level HR, LOW memory) and a global path for global lowresolution (LR) facial structure monitoring (i.e., image-level LR, LOW memory), which largely reduce memory requirements. Both paths work in a cooperative manner under a local-to-global consistency objective (i.e., for smooth stitching).
In addition, we propose a lighter selective transfer unit for more efficient multi-scale features fusion, yielding higher fidelity facial attributes manipulation. Extensive experiments on CelebAHQ well demonstrate the memory efficiency as well as the high image generation quality of the proposed framework.
第一句,研究领域:高分辨率人脸图像生成;
第二句,提出问题:高分辨率与低分辨率人脸图像生成相比,存在的挑战是, 1) 内存消耗大;2)多尺度特征融合效率低(不理解的可以看 Introduction 部分详细介绍);
第三句,核心方法: Cooperative GAN (CooGAN) 协同GAN网络;
第四/五/六句,算法细节:该框架的特点是,局部路径用于生成细粒度的局部人脸补丁(即patch级的 HR,低内存),全局路径用于全局的低分辨率(LR)人脸结构监测(即图像级的LR,低内存),这大大降低了内存需求。两条路径在局部到全局一致性目标(即平滑拼接)下以协作的方式工作。另外,提出了一种更轻的选择性转移单元,以实现更高效的多尺度特征融合,从而实现更高保真度的面部属性操作。【这段写的很好,强调是如何解决前面提到的两大问题的】
第七句,实验结果:在CelebAHQ上的大量实验很好地证明了该框架的存储效率和高图像生成质量。
Introduction
There are two major challenges of deep model based HR facial attribute editing:
1. Constrained Computational and Memory Resource. In some mobile scenarios (e.g., smartphone, AR/VR glasses) with only limited computational and memory resources, it is infeasible to use popular image editing models [18,30] which require sophisticated networks. To address this issue, methods based on model pruning and operator simplifying [35,13,28,34,23] have been proposed to reduce the inference computational complexity. However, the metric-based way to reduce the model size will do harm to model perceptual representation ability, the output facial image quality is usually largely sacrificed.
2. Inefficient Multi-scale Features Fusion. In order to achieve high-level semantic manipulation while maintaining local details during image generation, multi-scale features fusion is widely adopted. It is a common practice to utilize skip connection, e.g., U-Net [27]. However, fixed schemes, such as skip connection, usually result in infeasible or even self-contradicting fusion output (e.g., during style transfer, content is well-preserved but failed to change the image style), and flexible schemes such as GRU [9] lead to additional computational burden (e.g., applying GRU-based unit [20] directly for multi-scale features fusion can achieve excellent fusion effects, but will increase network parameters by more than four times).
1. 受限的计算和内存资源
在一些移动场景(如智能手机、AR/VR眼镜)中,由于计算和内存资源有限,使用流行的图像编辑模型是不可行的,因为这些模型需要复杂的网络。为了解决这个问题,提出了基于模型剪枝和算子简化的方法来降低推理计算的复杂度。然而,基于度量的模型尺寸压缩方法会损害模型的感知表征能力,往往会极大地降低输出的人脸图像质量。
2. 低效的多尺度特征融合
为了在图像生成过程中在保持局部细节的同时实现高级语义操作,多尺度特征融合被广泛采用。常用的做法是使用跳接,例如U-Net[27]。然而,固定方案,如跳过连接,通常导致不可行,甚至自相矛盾的融合输出(例如,在风格转变,内容是保存完好,但未能改变图像风格),和灵活的方案,诸如格勒乌[9]导致额外的计算负担(例如,应用GRU-based单元[20]直接多尺度特性的融合可以实现良好的融合效果,但会增加网络参数超过四倍)。
In this work, a novel image translation framework for high resolution facial attribute editing, dubbed CooGAN, is proposed to explicitly address above issues. It adopts a divide-and-combine strategy to break the intractable whole HR image generation task down to several sub-tasks for reducing memory cost greatly. More concretely, the pipeline of our framework consists of a series of local HR patch generation sub-tasks and a global LR image generation sub-task. To handle these two types of sub-tasks, our framework is also composed of two paths, i.e., local network path and global network path. Namely, the local subtask is to generate an HR patch with edited attributes and fine-grained details. And a global sub-task is to generate an LR whole facial snapshot with structural coordinates to guide the local workers properly recognize the correct patch semantics. As only tiny size patch (e.g., 64×64) generation sub-task is involved in the pipeline, the proposed framework avoids processing large size feature maps. As a result, this framework is very light-weighted and suited for resource constrained scenarios.
解决内存消耗问题:
策略:将 HR 图像分为 patch,作为局部网络输入,用于生成细粒度的细节;将 HR 整体 resize 到 LR,作为全局网络输入,用于学习语义信息。因为局部网络生成的是 patch 图像,patch 之间肯定不连贯,所以需要全局图像对这些 patch 图像进行引导,使它们连接起来是平滑的。这个平滑过程怎么实现呢?就是下面多尺度特征融合的任务。
In addition, a local-to-global consistency objective is proposed to enforce the cooperation of sub modules, which guarantees between-patch contextual consistency and appearance smoothness in fine-grained scale. Moreover, we design a variant of : Simple recurrent units (SRU) [19], Light Selective Transfer Unit (LSTU), for multi-scale features fusion. The GRU-based STU [20] has similar functions, but needs two states (one state obtained from encoder, another from the higher level hidden state) to inference the selected skip feature. As a result, it has to face a heavy computing burden and is not friendly to GPU acceleration. Unlike STU, our SRU-based LSTU just need a single hidden state to get the gating signal, which greatly reduces the complexity of the unit. Actually, the LSTU has only half as many parameters as STU and almost the same multi-scale features fusion effect, achieving a good balance between model efficiency and output image fidelity. Under this design, the framework is able to selectively and efficiently transfer the shallow semantics from the encoder to decoder, enabling more effective multi-scale features fusion with constrained memory consumption.
此外,提出了一种局部-全局一致性目标来加强子模块之间的协作,在细粒度尺度上保证了补丁间的上下文一致性和外观平滑性。设计了轻量传输单元 (LSTU),用于多尺度特征融合。基于 GRUl 的 STU 具有类似的功能,但需要两种状态 (一种状态来自编码器,另一种来自更高级别的隐藏状态) 来推断所选择的跳过特性。因此,它面临着沉重的计算负担,对 GPU 加速也不友好。与 STU 不同的是,我们的基于 Simple recurrent units (SRU) 的 LSTU 只需要一个隐藏状态来获取门控信号,这大大降低了单元的复杂性。实际上,LSTU 的参数只有 STU 的一半,多尺度特征融合效果几乎相同,在模型效率和输出图像保真度之间取得了很好的平衡。在这种设计下,该框架能够有选择地、高效地将浅层语义从编码器转移到解码器,在有限内存消耗的情况下实现更有效的多尺度特征融合。[简单地说,就是通过两种方法实现 协同 -- patch 拼接平滑:1)局部-全局一致性损失函数,2)轻量传输单元 (LSTU) 来实现多尺度融合,且其是轻量级的 ]。
Methodology
Overview
The proposed CooGAN framework for conditional facial generation presents two innovative modules, the global module and the local module. The global module is designed to generate LR translated facial image, and the local module aims at generating HR facial image patches and stitching them together. A cooperation mechanism is introduced to make these two modules work together, so that the global module provides the local module with a global-to-local spatial consistency constraint. In addition, to guarantee the performance and edit-ability of the generated images, we propose a well-designed unit, LSTU, to filter the features from latent space and infuse them with detail information inside the naive skip connection.
提出的用于条件人脸生成的 CooGAN 框架提出了两个创新模块:全局模块和局部模块。全局模块用于生成 LR 人脸图像,局部模块用于生成 HR 人脸图像块并将其拼接在一起。引入了一种协同机制使两个模块协同工作,使全局模块为局部模块提供全局到局部的空间一致性约束。此外,为了保证生成的图像的性能和编辑能力,使用一个设计良好的单元 LSTU 来过滤潜在空间中的特征,并在简单的跳过连接中为它们注入详细信息。
Cascaded Global-to-Local Face Translation Architecture
The CooGAN consists of two interdependent generation modules. We depict the framework architecture in Fig. 2.
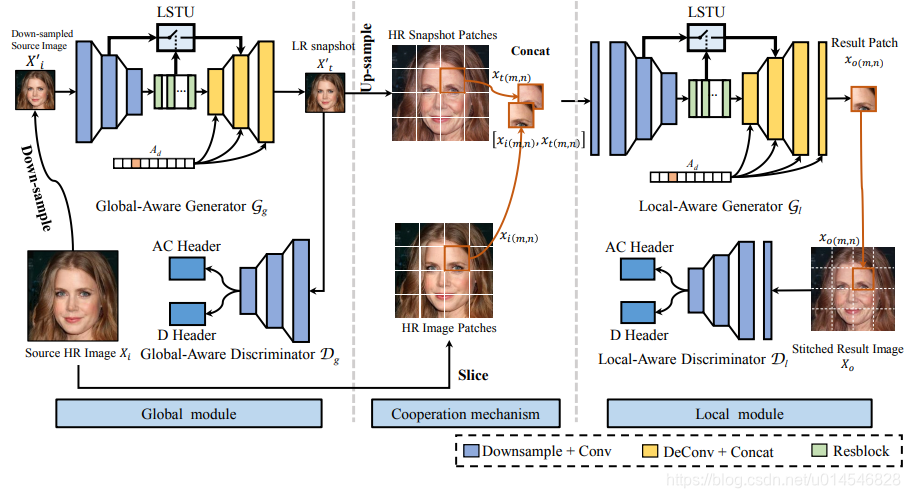
框架有两个模块,左边是全局图像平移模块,右边是局部patch细化模块。每个模块都包含一个发生器和一个判别器。两个模块通过中间的协同机制相互协作。
- Global module
1. 功能:全局模块用于生成转换后的快照(snapshot),它承载了整个图像的空间坐标信息。注意,全局模块的主要目的是保证最终结果的全局语义一致性。
2. 结构:全局感知生成器(Gg : global-aware generator)和全局感知判别器(Dg : global-aware discriminator)。
3. 细节:Gg -- LSTU 增强的传统 U-Net;输入是 下采样后的图像(降低内存消耗);输出是 低分辨率 的生成图像,称为 快照(snapshot)图像;
Dg -- 两个输入,共享一个特征提取网络; 参考 Conditional Image Synthesis with Auxiliary Classifier GANs (2017 ICML)
- Local module
1. 功能:处理高分辨率图像的 patch 块;
2. 结构:局部感知生成器(Gl : local-aware generator)和局部感知判别器(Dl : local-aware discriminator)。
3. 细节:Gl -- 输入是 级联(concatenate) 高分辨率图像(GT图像) patch 块与 快照图像(由全局模块生成的 低分辨率图像)上采样再 剪切成 patch 块;
输出是每对 patch 图像的生成相应的 patch;这些输出是不重叠的;
Dl -- 为了避免生成的补丁之间的不一致性,引入了局部感知判别器,使最终的缝合输出平滑无缝。注意,这个判别器只是临时引入来训练模型(?),因此它不会在推理阶段增加任何内存开销。
- Cooperation mechanism
1. 问题:将高分辨率图像下采样成若干 patch,patch 与 patch 在经过网络之后,可能并不连贯;
2. 功能:引入有效的协同机制,鼓励两个生成器进行良好的协作,以获得满意的生成性能;全局 LR 图像上采样再剪切成若干 patch,这些 patch 包含全局空间坐标信息,而 HR 图像的 patch 包含详细的纹理信息。通过这种方法,将全局空间信息和详细纹理信息结合在一起。即利用全局空间信息使生成的局部 patch 更加平滑和全局一致,利用细节纹理信息保持生成的质量。
Objective Function
- Image reconstruction loss
![]()
上式可以看到,“0” 表示的是,输入 HR 图像 和生成的 HR 图像有相同属性;因此,这是一个 通过自监督来实现的损失函数。
- Adversarial loss
为了减轻训练过程中对手损失的不稳定性,引入了梯度罚
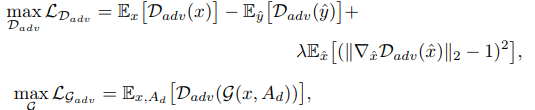
x 是 输入的真实图像, ˆy 生成的图像和 xˆ 是沿着直线的采样点之间真正的图像分布和生成图像分布。
- Attribute editing loss.
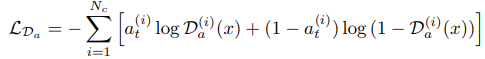
Light Selective Transfer Unit
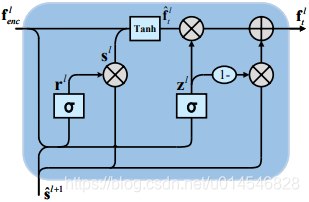
The most popular method for multi-scale features fusion in image-to-image translation is the Skip Connection structure. It helps the network balance the contradiction between the pursuit of larger receptive field and loss of more details. One of its classic deployments is U-Net. However, there is a fatal drawback of the original skip connection: it will degrade the function of deeper parts and further damage the effectiveness of condition injection. From Table 1, it is obvious that PSNR increases but attribute editing accuracy decreases when the skip connection number multiplies. A detailed graph showing the editing accuracy of each specific attribute is given in suppl. STGAN [20] tries to alleviate the problem with the STU, a variant of GRU [7,9], which uses the latent feature to control the information transfer in the skip connection through the unit. This feature carries the conditional information added through the concatenation. Unfortunately, such a unit omits the spatial and temporal complexity and it is a time-consuming process for the underlying feature to bubble up from the bottleneck to drive the STU of each layer.
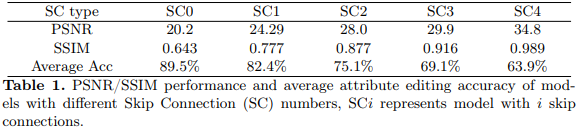
对于具有不同跳过连接数(SC)模型的PSNR/SSIM性能和平均属性编辑精度,SCi表示具有i跳过连接数的模型。
首先,分析了几种融合方法:
1. U-Net:但 skip 连接有一个致命的缺点:它会降低更深部分的功能,进一步损害条件注入的有效性(这句话的意思很简单:因为 skip 连接将浅层网络特征引入,使得更深层次网络的特征被弱化。从图 2 中看到,attribute vector 属性向量都是在 网络深层 引入的,这样 skip 连接不利于特征属性的表达)。从表 1 可以明显看出,当跳过连接数增加时,PSNR会增加,但属性编辑精度会降低。
2. STU:STGAN [A Unified Selective Transfer Network for Arbitrary Image Attribute Editing] 试图通过 GRU 的变体 STU 来缓解这一问题,STU 利用潜在特征来控制通过单元的skip连接中的信息传递。该特性携带通过连接添加的条件信息。不幸的是,这样的单元忽略了空间和时间的复杂性,并且底层特性从瓶颈中冒出来以驱动每一层的 STU 是一个耗时的过程。(对 STU 不是很理解,可以参考:[A Unified Selective Transfer Network for Arbitrary Image Attribute Editing] [Simple Recurrent Units for Highly Parallelizable Recurrence])
其次,介绍 LST。
To explicitly address the mentioned problem, we present our framework to employ Light Selective Transfer Unit (LSTU) to efficiently and selectively transfer the encoder feature. LSTU is an SRU-based unit with totally different information flow. Compare to STU, our LSTU discards the dependence on the two states when calculating the gating signal, which greatly reduces our parameters but the unit is still efficient. The detailed structure of LSTU is shown in Fig. 3. Without loss of generality, we choose the l-th LSTU as an analysis example. The l-th layer feature coming from the encoder side denotes as
denotes the feature in the adjacent deeper layer. It contains the filtered latent state information of that layer .
is firstly concatenated with attribute difference Ad to obtain up-sampled hidden state
. Then
is used to independently calculate the masks
for the forget-gate and reset-gate. WT, W1×1, Wf and Wr represent parameter matrix of transpose convolution, linear transform, forget gate and update gate. The further process is similar to SRU. The equation of gates is shown on the right side of Fig. 3.
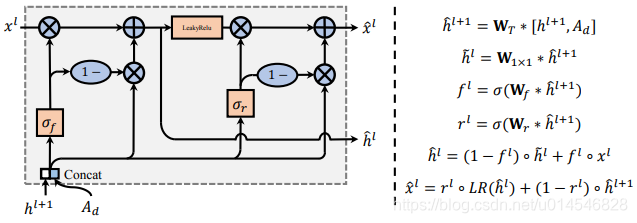
LSTU的结构。LSTU的设计灵感来自于 SRU,LSTU 比 STU 更轻,更适合 GPU 并行加速。右边是 LSTU 推理过程的数学表达式。LR 是 LeakyRelu 的缩写。
下图是 STU 的结构:
扩展阅读:
CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
FHDe2Net: Full High Definition Demoireing Network
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123670715.pdf
High-Resolution Image Inpainting with Iterative Confidence Feedback and Guided Upsampling
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123640001.pdf
High-frequency Component Helps Explain the Generalization of Convolutional Neural Networks
Nighttime Defogging Using High-Low Frequency Decomposition and Grayscale-Color Networks
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123570460.pdf

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









