







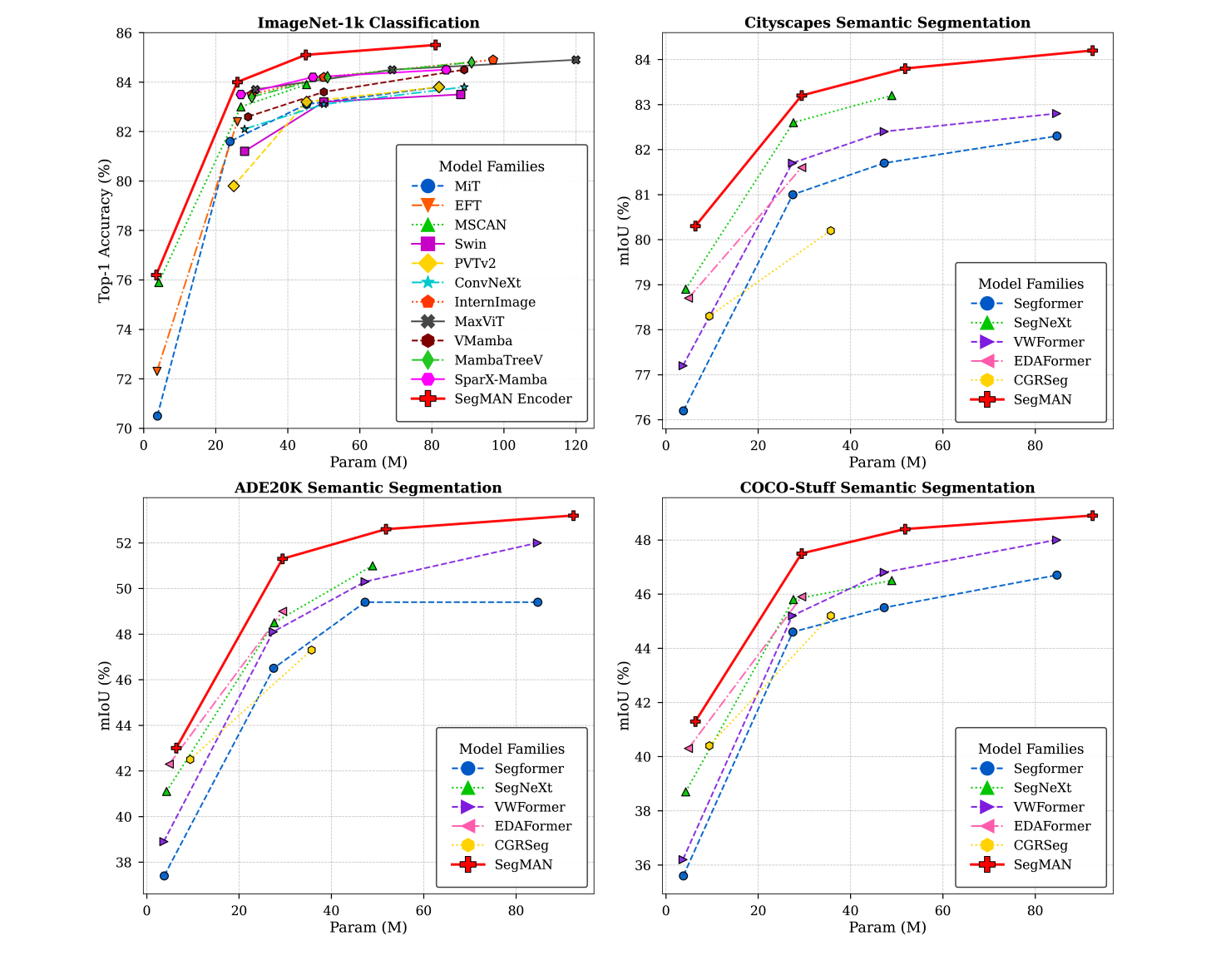
Figure 1. SegMAN Encoder classification performance compared with representative vision backbones alongside semantic segmentation results of the full SegMAN model compared to prior stateof-the-art models.
Abstract
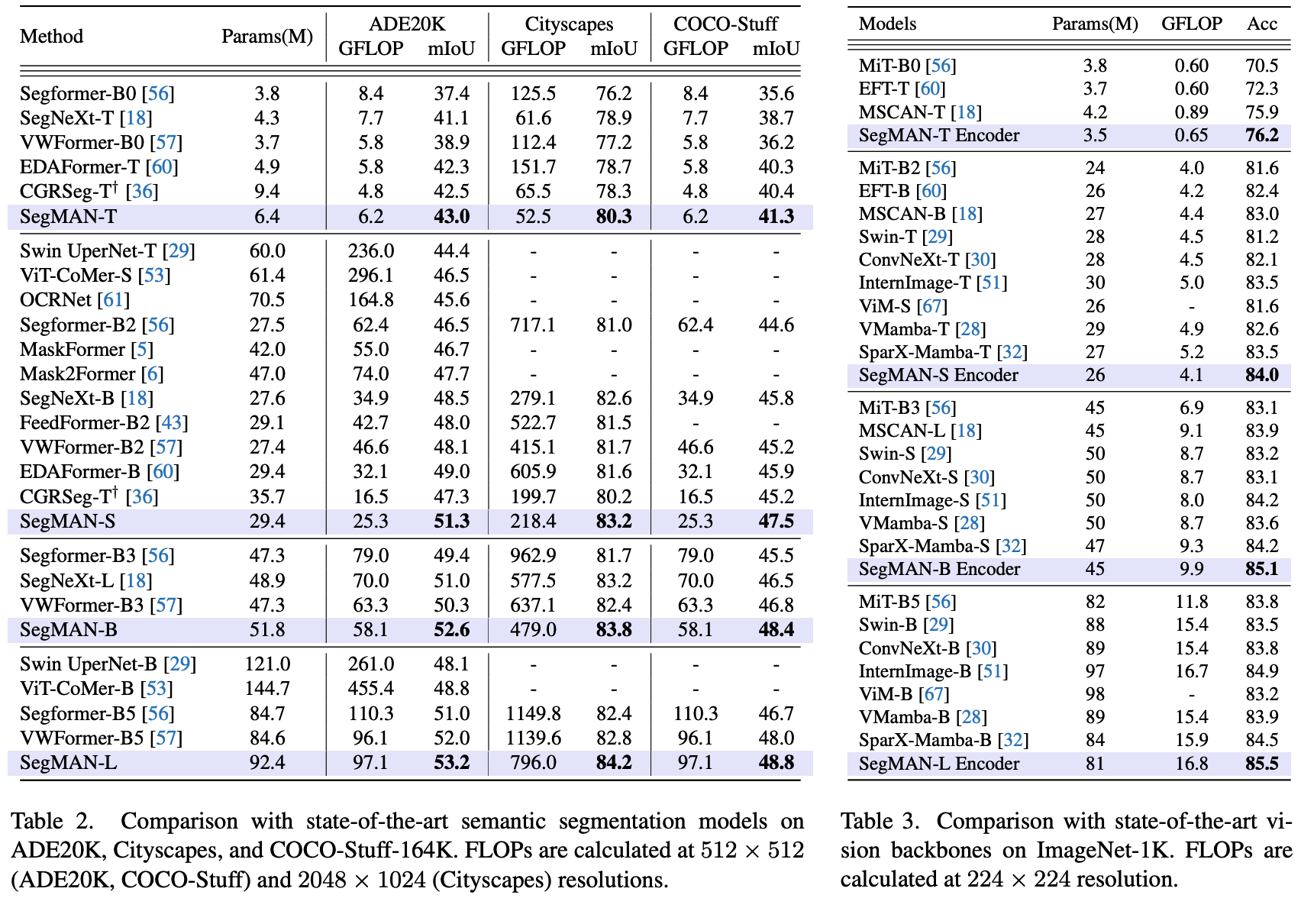
High-quality semantic segmentation relies on three key capabilities: global context modeling, local detail encoding, and multi-scale feature extraction. However, recent methods struggle to possess all these capabilities simultaneously. Hence, we aim to empower segmentation networks to simultaneously carry out efficient global context modeling, high-quality local detail encoding, and rich multi-scale feature representation for varying input resolutions. In this paper, we introduce SegMAN, a novel linear-time model comprising a hybrid feature encoder dubbed SegMAN Encoder, and a decoder based on state space models. Specifically, the SegMAN Encoder synergistically integrates sliding local attention with dynamic state space models, enabling highly efficient global context modeling while preserving fine-grained local details. Meanwhile, the MMSCopE module in our decoder enhances multi-scale context feature extraction and adaptively scales with the input resolution. Our SegMAN-B Encoder achieves 85.1% ImageNet-1k accuracy (+1.5% over VMamba-S with fewer parameters). When paired with our decoder, the full SegMAN-B model achieves 52.6% mIoU on ADE20K (+1.6% over SegNeXtL with 15% fewer GFLOPs), 83.8% mIoU on Cityscapes (+2.1% over SegFormer-B3 with half the GFLOPs), and 1.6% higher mIoU than VWFormer-B3 on COCO-Stuff with lower GFLOPs.
高质量语义分割依赖于三个关键能力:全局上下文建模、局部细节编码和多尺度特征提取。然而,现有方法难以同时具备所有这些能力。因此,本文的目标是使分割网络能够同时实现高效的全局上下文建模、高质量的局部细节编码以及针对不同输入分辨率的丰富多尺度特征表示。本文提出SegMAN,这是一种新型线性时间模型,包含一个名为SegMAN编码器的混合特征编码器,以及基于状态空间模型的解码器。具体而言,SegMAN编码器将滑动局部注意力与动态状态空间模型协同整合,在保持细粒度局部细节的同时实现高效的全局上下文建模。同时,解码器中的MMSCopE模块增强了多尺度上下文特征提取能力,并能自适应输入分辨率调整。本文的SegMAN-B编码器在ImageNet-1k上达到85.1%准确率(比VMamba-S提升1.5%且参数量更少)。配合本文的解码器,完整SegMAN-B模型在ADE20K上达到52.6% mIoU(比SegNeXtL提升1.6%且减少15% GFLOPs),在Cityscapes上达到83.8% mIoU(比SegFormer-B3提升2.1%且计算量减半),在COCO-Stuff上比VWFormer-B3提高1.6% mIoU且GFLOPs更低。
Introduction
As a core computer vision task, semantic segmentation needs to assign a categorical label to every pixel within an image [35]. Accurate semantic segmentation demands three crucial capabilities. First, global context modeling establishes rich contextual dependencies regardless of spatial distance, enabling overall scene understanding [13]. Second, local detail encoding endows fine-grained feature and boundary representations, crucial for differentiating semantic categories and localizing boundaries between adjacent regions with different semantic meanings [59]. Third, context modeling based on multiple intermediate scales promotes semantic representations across multiple scales, addressing intra-class scale variations while enhancing interclass discrimination [2, 57, 63].
背景:
作为计算机视觉核心任务,语义分割需要为图像中每个像素分配类别标签。精确的语义分割需要三个关键能力:首先,全局上下文建模建立不受空间距离限制的丰富上下文依赖,实现整体场景理解;其次,局部细节编码提供细粒度特征和边界表示,这对区分语义类别和定位不同语义区域边界至关重要;第三,基于多中间尺度的上下文建模促进跨多尺度的语义表示,解决类内尺度变化同时增强类间区分度。
Recent methods of semantic segmentation have been unable to simultaneously encapsulate all three of these capabilities effectively. For instance, VWFormer [57] introduces a varying window attention (VWA) mechanism that effectively captures multi-scale information through cross-attention between local windows and multiple windows with predefined scales. However, at higher input resolutions, the global context modeling capability of VWA diminishes because the predefined window sizes fail to maintain full feature map coverage. In addition, larger windows significantly increase the computational cost as self-attention exhibits quadratic complexity. Likewise, EDAFormer [60] proposes an embedding-free spatial reduction attention (SRA) mechanism to implement global attention efficiently and an all-attention decoder for global and multi-scale context modeling. However, fine-grained details are lost due to its reliance on downsampled features for token-to-region attention. Moreover, the absence of dedicated local operators in the feature encoder limits fine-grained feature learning [56, 60].
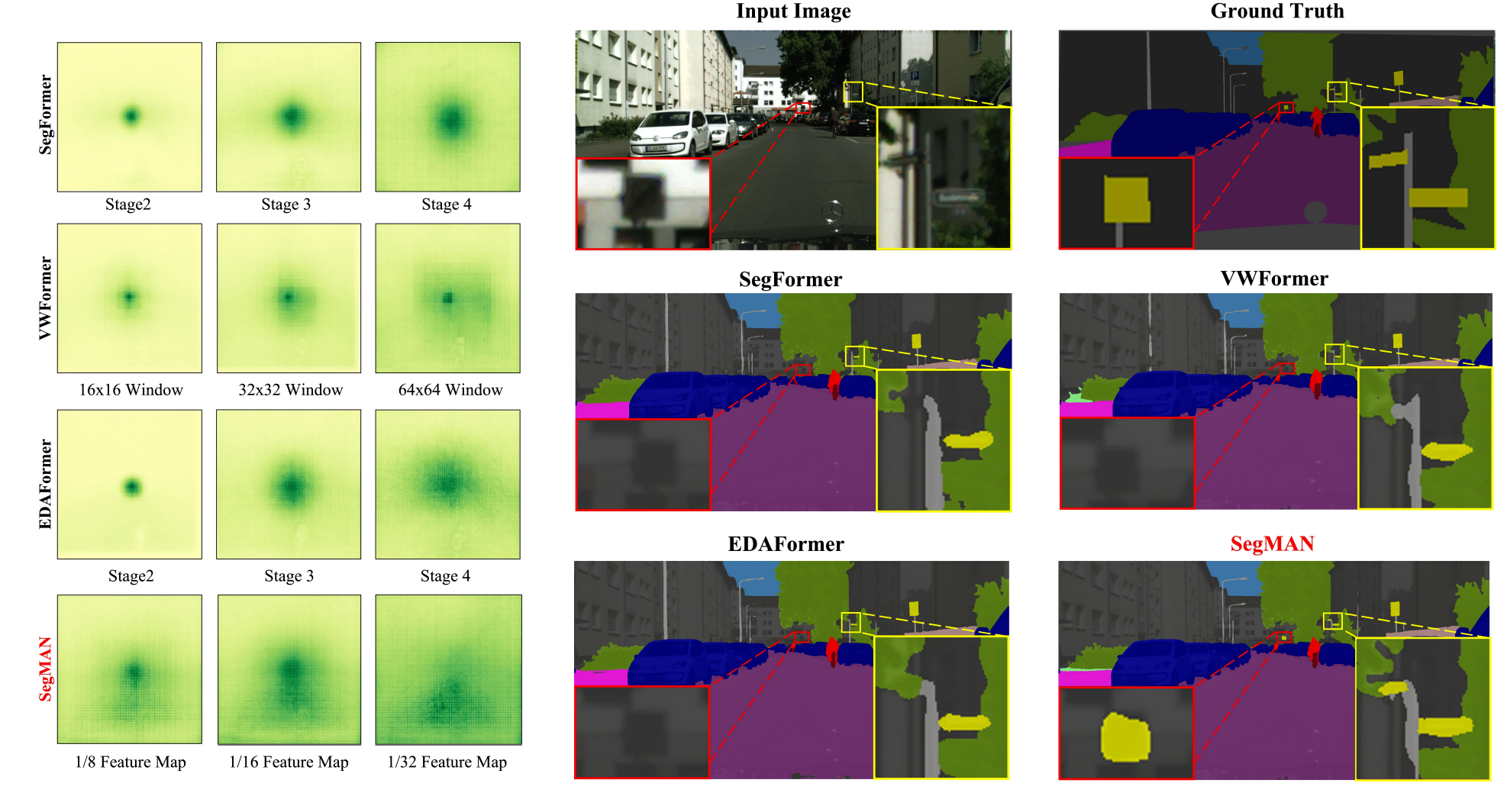
To present a more intuitive understanding of the aforementioned issues, we visualize the effective receptive field (ERF) maps and segmentation maps of recent state-of-the-art models [56, 57, 60] with 27M-29M parameters. As depicted in Figure 2 (Left), the ERF of VWFormer [57] and EDAFormer [60] has limited feature map coverage when processing high-resolution Cityscapes images. Meanwhile, the segmentation maps in Figure 2 (Right) reveal that existing methods have a limited ability to recognize fine-grained local details, which we attribute to insufficient local feature modeling in these architectures.
Figure 2. Qualitative analysis of receptive field patterns and segmentation performance for small-sized models (27M-29M parameters). Left: Visualization of effective receptive fields (ERF) on the Cityscapes validation set at 1024×1024 resolution, illustrating SegMAN’s stronger global context modeling capacity in comparison to existing state-of-the-art models. Right: Segmentation maps highlighting SegMAN’s superior capacity to encode fine-grained local details that are often missed by existing approaches.
提出问题:
现有语义分割方法难以同时有效实现这三种能力。例如VWFormer提出的可变窗口注意力(VWA)机制通过预定义多尺度窗口间的交叉注意力捕获多尺度信息,但在高分辨率输入时,由于预设窗口尺寸无法保持完整特征图覆盖,其全局上下文建模能力下降。此外,较大窗口会因自注意力的二次计算复杂度显著增加计算成本。类似地,EDAFormer采用无嵌入空间缩减注意力(SRA)机制高效实现全局注意力,并使用全注意力解码器进行全局和多尺度上下文建模,但由于依赖下采样特征进行token-to-region注意力,会丢失细粒度细节。同时,特征编码器缺乏专用局部算子也限制了细粒度特征学习。
为直观展示这些问题,本文可视化27M-29M参数量级的最新模型的有效感受野(ERF)和分割结果。如图2(左)所示,处理高分辨率Cityscapes图像时,VWFormer和EDAFormer的ERF覆盖范围有限。图2(右)的分割结果则显示现有方法识别细粒度局部细节的能力有限,本文将其归因于这些架构中局部特征建模不足。
In this work, we aim to encapsulate omni-scale context modeling for a varying input resolution within a semantic segmentation network. As a result, we propose SegMAN, a novel segmentation network capable of carrying out efficient global context modeling, high-quality local detail encoding, and rich context representation at diverse scales simultaneously. Our SegMAN introduces two novel subnetworks: (1) a hybrid feature encoder that integrates Local Attention and State Space models (LASS) in the token mixer, and (2) a decoder with a Mamba-based Multi-Scale Context Extraction (MMSCopE) module. In the SegMAN Encoder, LASS leverages a two-dimensional state space model (SS2D) [28] for global context modeling and neighborhood attention [19] (Natten) for local detail encoding, both functioning in linear time. The dynamic global scanning in our method always covers the full feature map, enabling robust global context modeling across varying input resolutions and all encoder layers. Meanwhile, by performing local attention within a sliding window, Natten exhibits an outstanding capability in fine-grained local detail encoding. Our decoder complements the encoder with robust feature learning across multiple scales. The core MMSCopE module first aggregates semantic context from multiple regions of the encoder feature map. Then it uses SS2D to scan each regionally aggregated feature map to learn multiscale contexts at linear complexity. For higher efficiency, the feature maps at different scales are reshaped to the same resolution and concatenated so that scanning only needs to be performed on a single feature map. Note that our method differs from existing methods in two aspects. First, unlike multi-kernel convolution [2] and multi-scale window attention [57], our design adaptively scales with the input resolution. Second, by performing SS2D-based scanning over entire multi-scale feature maps, our method better preserves fine-grained details that are typically compromised by pooling operations [36, 63] or spatial reduction attention [60] in existing methods.
As shown in Figure 1, our SegMAN Encoder shows superior performance compared to representative vision backbones on ImageNet-1k. When paired with our novel decoder, the full SegMAN model establishes new state-of-the-art segmentation performance on ADE20K [65], Cityscapes [8], and COCO-Stuff-164k [1].
本文工作:
本研究旨在语义分割网络中实现适应不同输入分辨率的全尺度上下文建模。为此提出SegMAN——一种能同时执行高效全局上下文建模、高质量局部细节编码和丰富多尺度上下文表示的新型分割网络。
SegMAN包含两个创新子网络:
(1)在token mixer中整合局部注意力与状态空间模型(LASS)的混合特征编码器;
(2)基于Mamba的多尺度上下文提取(MMSCopE)模块的解码器。
在SegMAN编码器中,LASS利用二维状态空间模型(SS2D)进行全局上下文建模,采用邻域注意力(Natten)实现局部细节编码,二者均具有线性时间复杂度。本文的动态全局扫描始终覆盖完整特征图,确保不同输入分辨率和所有编码层都能进行鲁棒的全局上下文建模。同时,Natten通过滑动窗口内的局部注意力展现出卓越的细粒度局部细节编码能力。解码器通过多尺度鲁棒特征学习补充编码器:核心MMSCopE模块首先从编码器特征图的多个区域聚合语义上下文,然后使用SS2D扫描每个区域聚合特征图以线性复杂度学习多尺度上下文。为提高效率,将不同尺度特征图重塑为相同分辨率并拼接,只需扫描单个特征图。
本文的方法有两个独特优势:
(1)不同于多核卷积[2]和多尺度窗口注意力,本文的设计能自适应输入分辨率;
(2)通过对完整多尺度特征图进行SS2D扫描,比现有方法中池化操作或空间缩减注意力[60]更好地保留细粒度细节。
如图1所示,SegMAN编码器在ImageNet-1k上相比代表性视觉骨干网络展现出优越性能。配合新型解码器,完整SegMAN模型在ADE20K、Cityscapes和COCO-Stuff-164k上创造了新的语义分割性能记录。
To summarize, our contributions are threefold:
• We introduce a novel encoder architecture featuring our LASS token mixer that synergistically combines local attention with state space models for efficient global context modeling and local detail encoding.
• We propose MMSCopE, a novel decoder module that operates on multi-scale feature maps that adaptively scale with the input resolution, surpassing previous approaches in both fine-grained detail preservation and omni-scale context learning.
• We demonstrate through comprehensive experiments that SegMAN, powered by LASS and MMSCopE, establishes new state-of-the-art performance while maintaining competitive computational efficiency across multiple challenging semantic segmentation benchmarks.
本文贡献:
贡献包含三个方面:
• 提出了一种新型编码器架构,其核心是LASS token混合器,通过协同整合局部注意力与状态空间模型,实现了高效的全局上下文建模和局部细节编码。
• 设计了MMSCopE模块,这是一种新型解码器组件,能够自适应输入分辨率处理多尺度特征图,在细粒度细节保留和全尺度上下文学习方面超越了现有方法。
• 通过系统实验验证,由LASS和MMSCopE驱动的SegMAN模型在多个具有挑战性的语义分割基准测试中,不仅创造了新的性能记录,同时保持了具有竞争力的计算效率。
Method
1. Overall Architecture
As shown in Figure 3, our proposed SegMAN consists of a newly designed feature encoder and decoder. Specifically, we propose a novel hybrid feature encoder based on core mechanisms from both Transformer and dynamic State Space Models [16], and a Mamba-based Multi-Scale Context Extraction module (MMSCopE) in the decoder. The hierarchical SegMAN Encoder integrates Neighborhood Attention (Natten) [19] and the 2D-Selective-Scan Block (SS2D in VMamba) [28] within the token mixer termed Local Attention and State Space (LASS), enabling comprehensive feature learning at both global and local scales across all layers while maintaining linear computational complexity. Meanwhile, MMSCoPE dynamically and adaptively extracts multi-scale semantic information by processing feature maps at varying levels of granularity using SS2D [28], with the scales adaptively adjusted according to the input resolution. Collectively, the SegMAN Encoder injects robust global contexts and local details into a feature pyramid, where feature maps are progressively downsampled and transformed to produce omni-scale features at different pyramid levels. This feature pyramid is then fed into MMSCopE, where features are further aggregated spatially as well as across scales, resulting in comprehensive multi-scale representations that can be used for dense prediction.
Figure 3. Overall Architecture of SegMAN. (a) Hierarchical SegMAN Encoder. (b) LASS for modeling global contexts and local details with linear complexity. (c) The SegMAN Decoder. (d) The MMSCopE module for multi-scale contexts extraction.
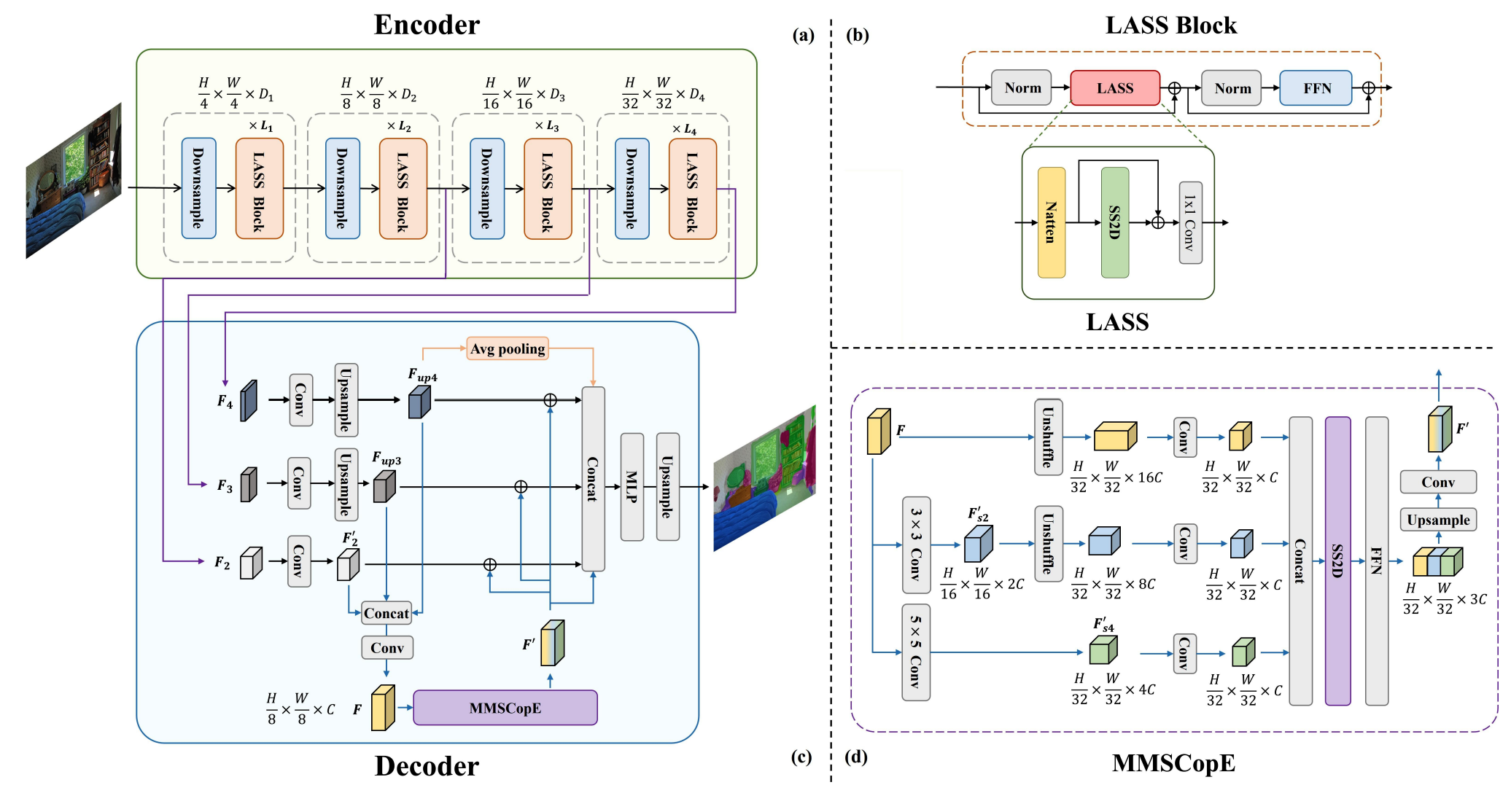
如图3所示,本文提出的SegMAN包含全新设计的特征编码器和解码器。具体而言,本文基于Transformer和动态状态空间模型的核心机制,提出了一种混合特征编码器,并在解码器中引入了基于Mamba的多尺度上下文提取模块(MMSCopE)。层次化SegMAN编码器在其token混合器(LASS)中整合了邻域注意力(Natten [19])和2D选择性扫描块(VMamba中的SS2D [28]),能够在所有网络层级同时进行全局和局部尺度的特征学习,同时保持线性计算复杂度。与此同时,MMSCoPE模块通过SS2D处理不同粒度的特征图,动态自适应地提取多尺度语义信息,其处理尺度会根据输入分辨率自动调整。SegMAN编码器将鲁棒的全局上下文和局部细节注入特征金字塔,通过逐步下采样和变换特征图,在不同金字塔层级生成全尺度特征。这些特征图随后输入MMSCopE模块,在空间和尺度维度进行进一步聚合,最终形成可用于密集预测的全面多尺度表征。
[19] Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi. Neighborhood attention transformer. CVPR 2023.
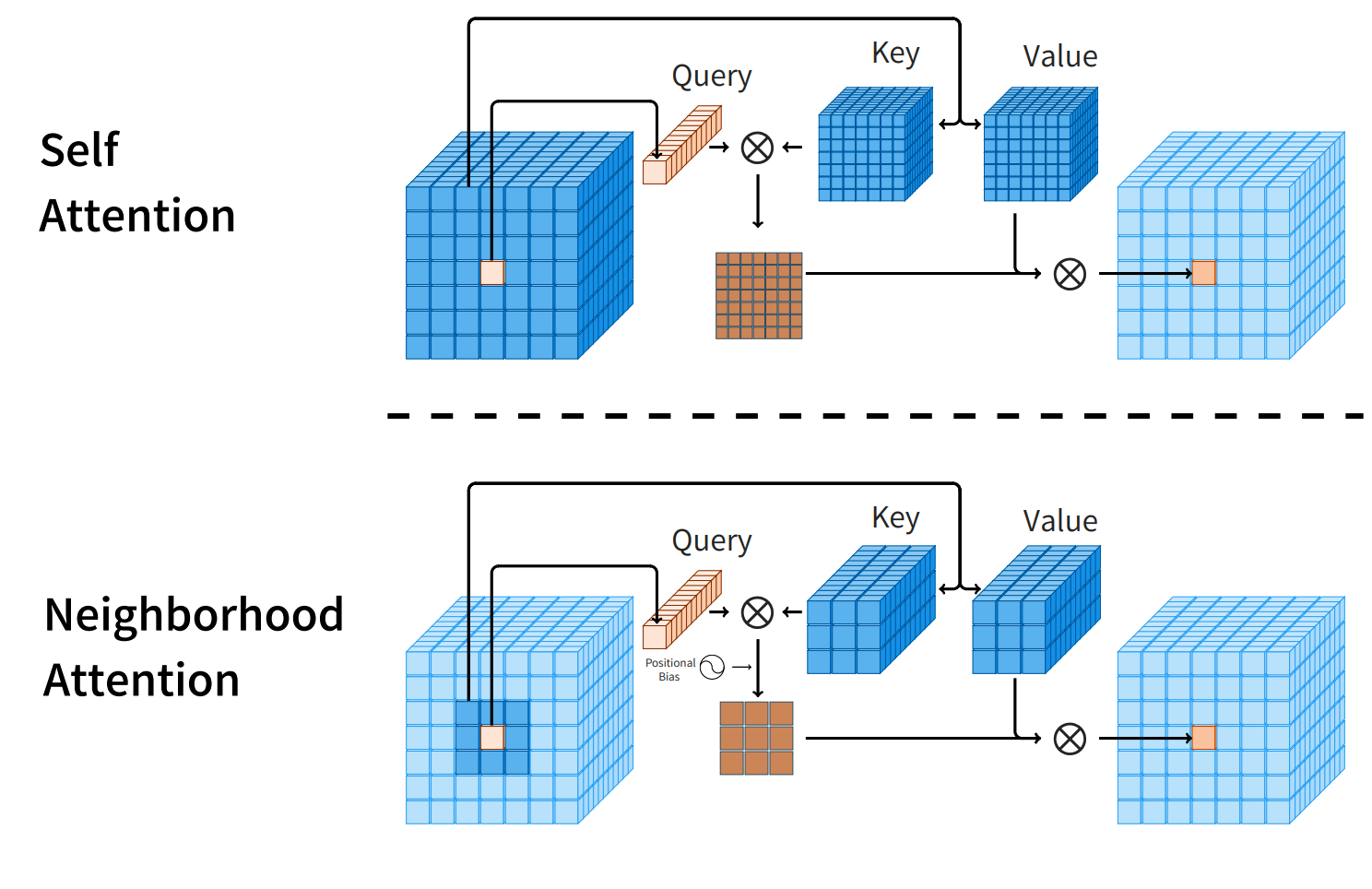
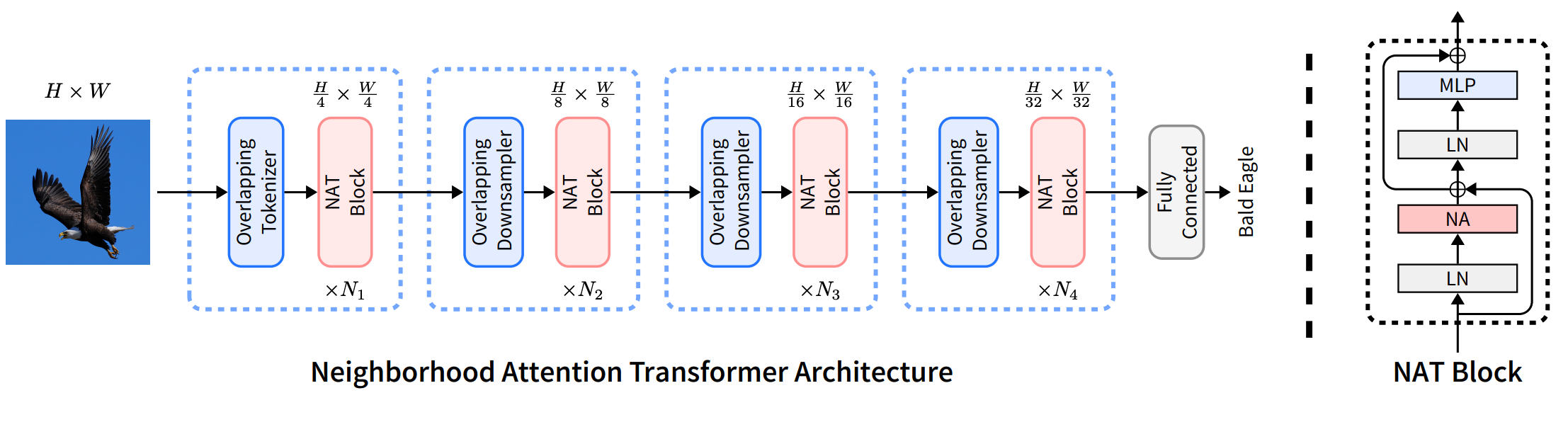
[28] Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu. Vmamba: Visual state space model. NeurIPS, 2024.
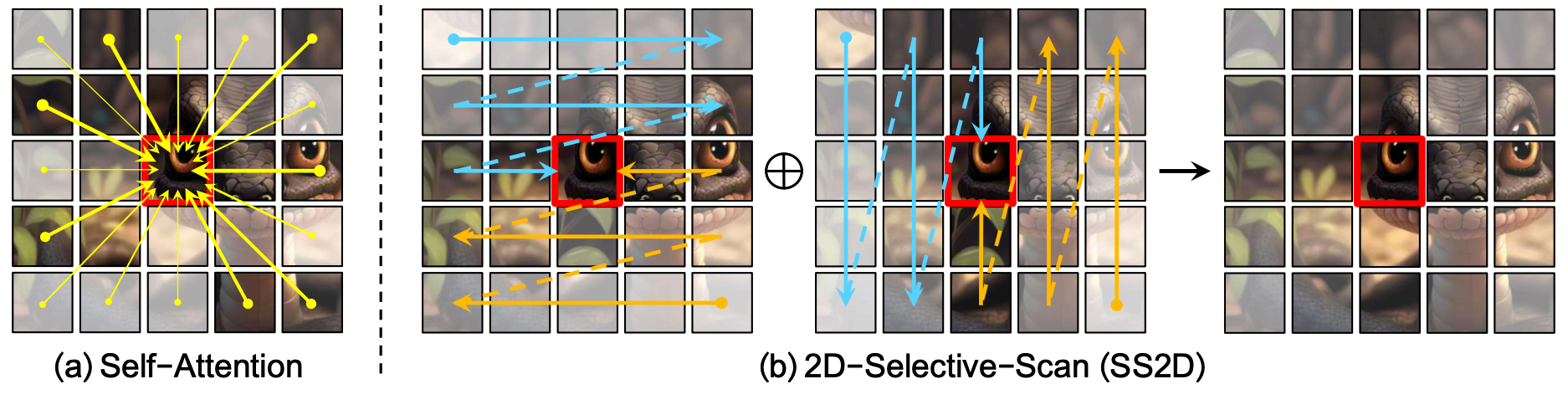
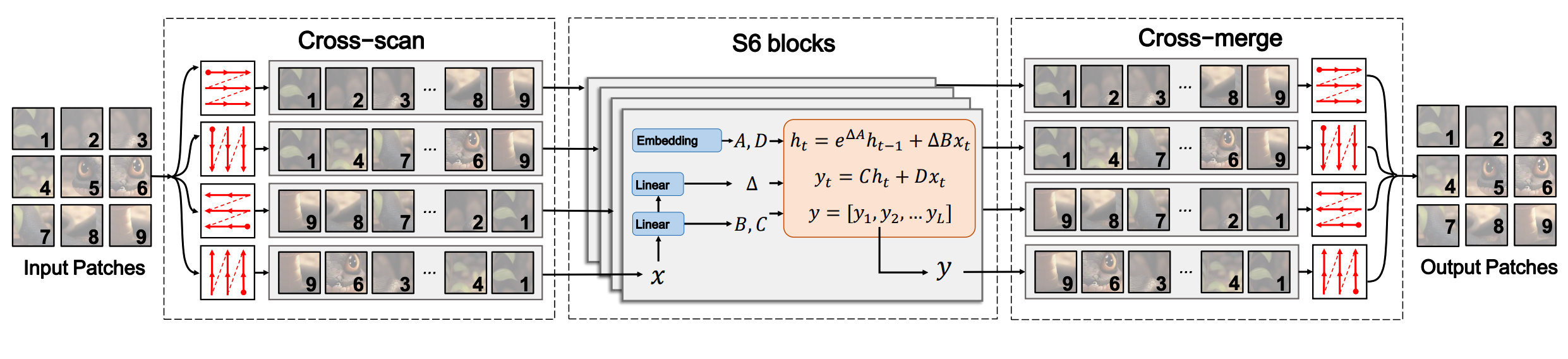
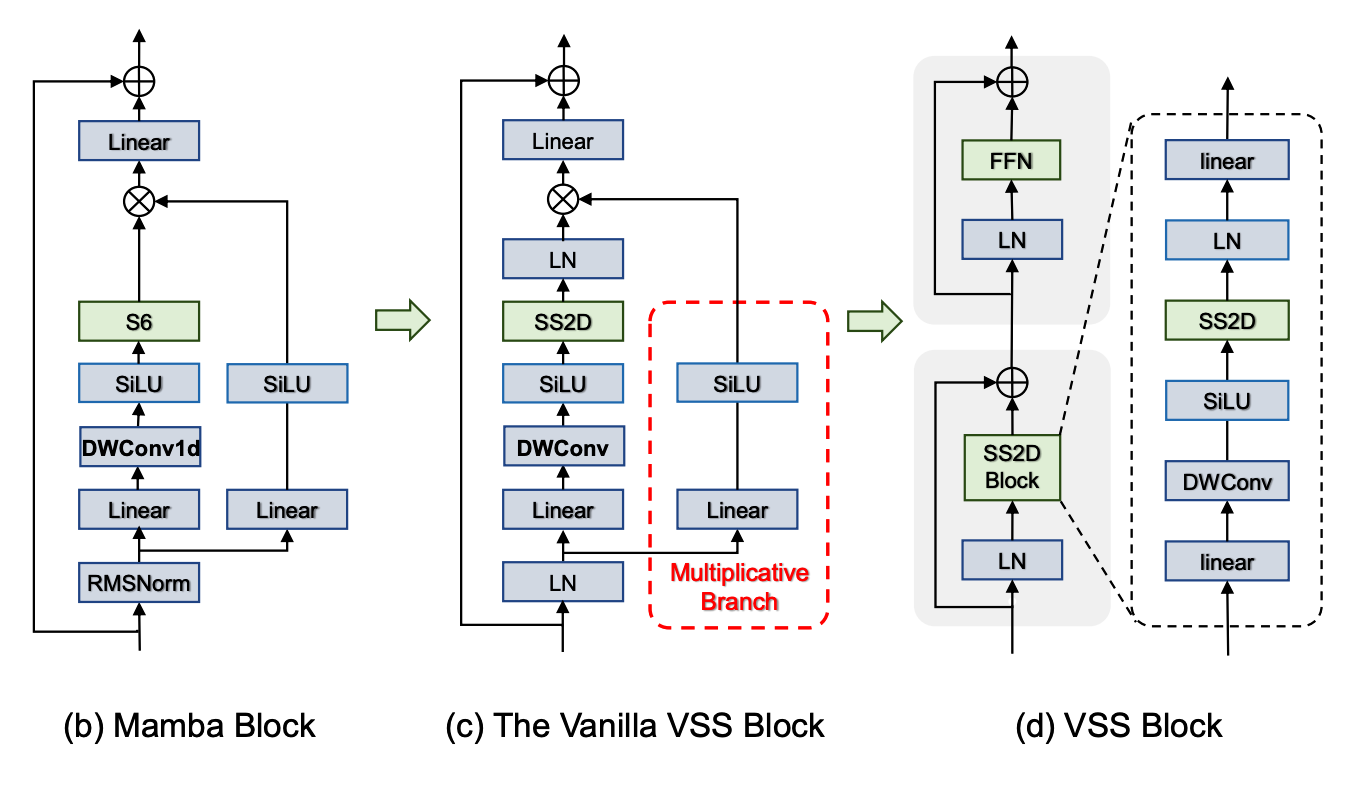
2. Feature encoder
Overview
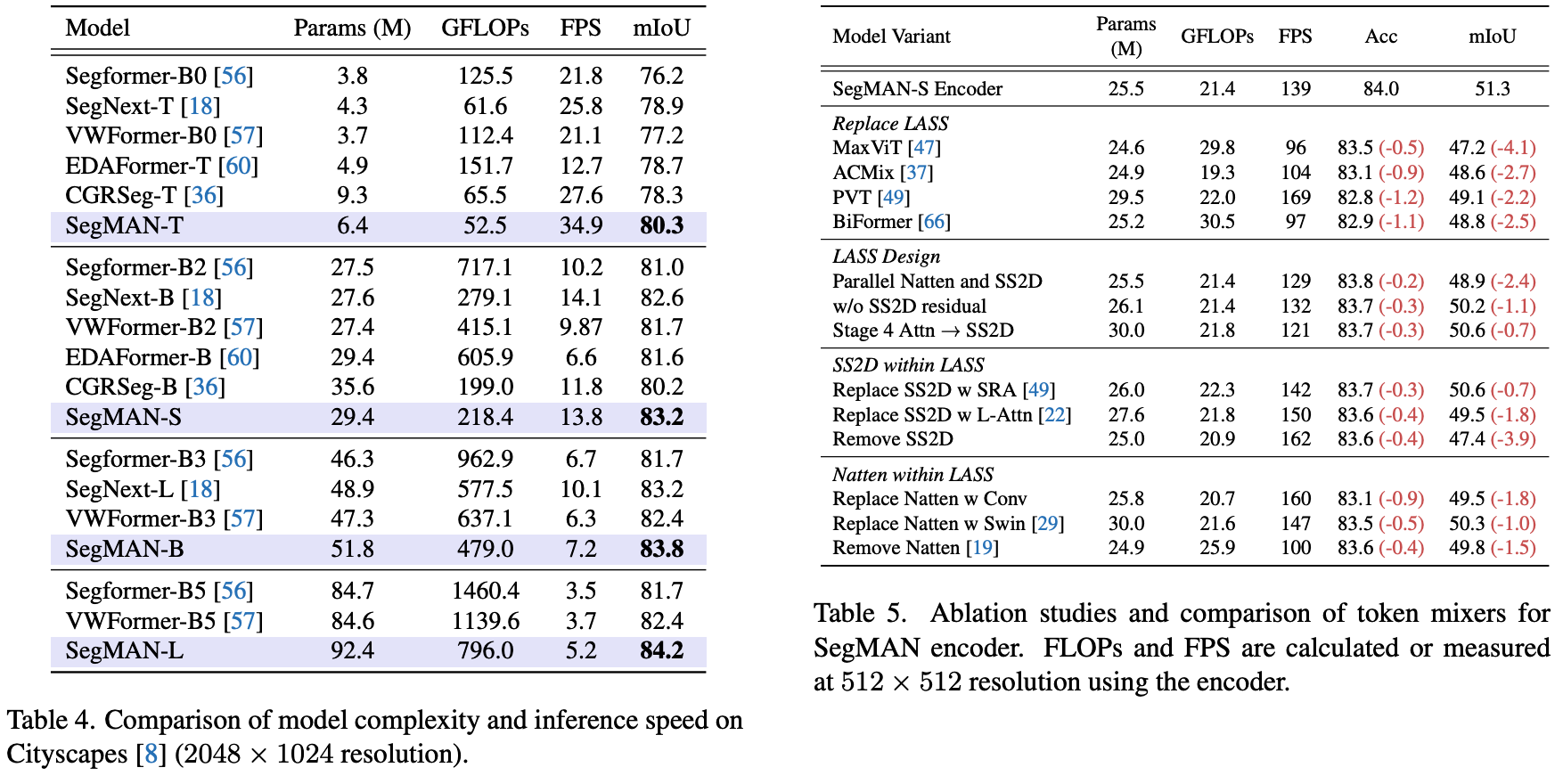
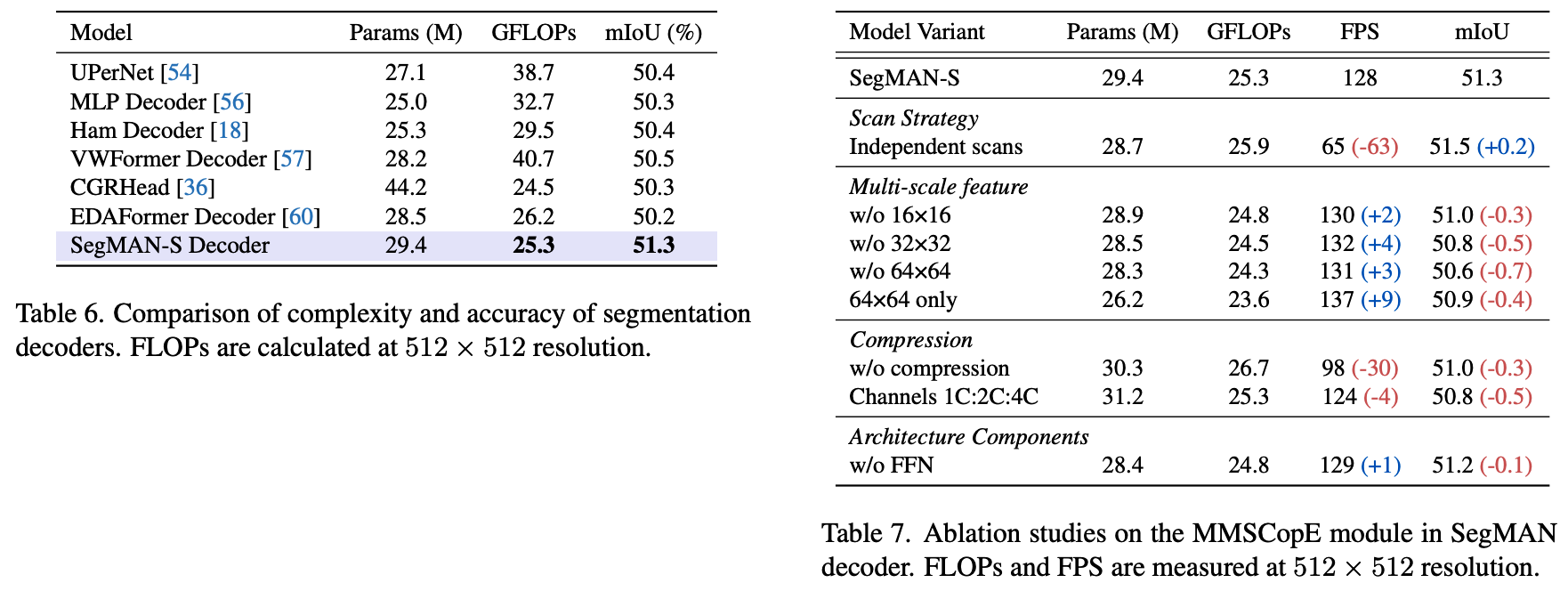
As shown in Figure 3, our SegMAN Encoder is a standard four-stage network [29, 30], where each stage begins with a strided 3×3 convolution for spatial reduction, followed by a series of LASS Blocks. Each LASS Block includes pre-layer normalization, a novel LASS module, and a feedforward network (FFN) [10, 19, 29]. Our proposed LASS represents the first integration of local self-attention (Natten [19]) and state space models (SS2D [28]) for semantic segmentation, capturing local details and global contexts simultaneously with linear time complexity. Ablation studies (Table 5) confirm the necessity of both components.
如图3所示,本文的SegMAN编码器采用标准四阶段网络结构。每个阶段首先使用步长为2的3×3卷积进行空间降维,随后连接一系列LASS模块。每个LASS模块包含层前置归一化、创新的LASS组件以及前馈网络(FFN)。本文提出的LASS首次将局部自注意力(Natten)与状态空间模型(SS2D)相结合用于语义分割,以线性时间复杂度同时捕获局部细节和全局上下文。消融实验(表5)证实了这两个组件都是必要的。
Local attention and state space module
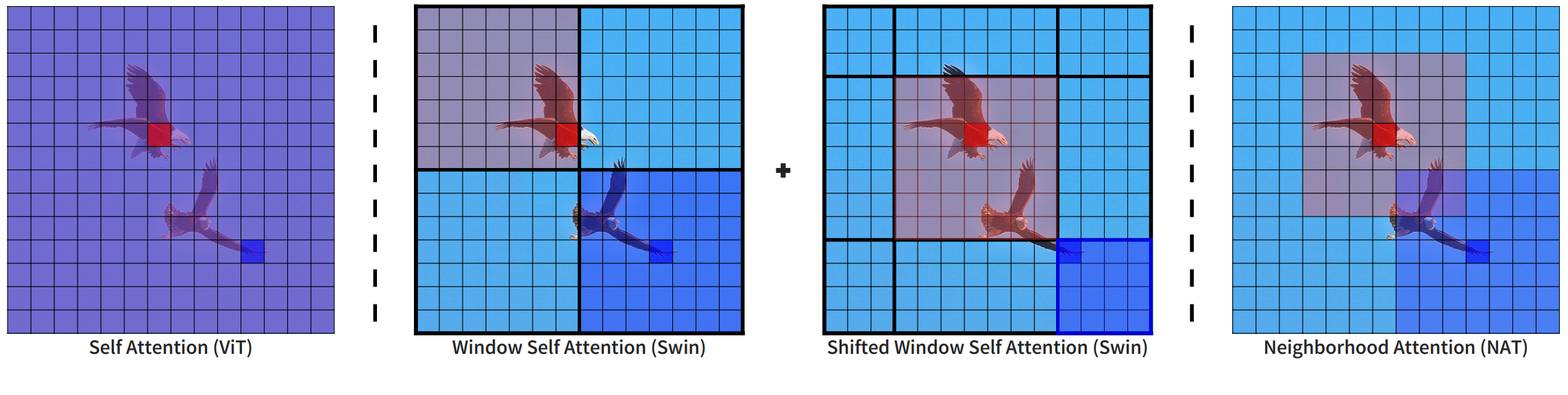
Longrange dependency modeling is crucial for semantic segmentation as they enable comprehensive context learning and scene understanding, as demonstrated by the success of Transformer-based semantic segmentation models [34, 39, 56, 60, 64]. To efficiently learn global contexts across all network layers, we leverage the SS2D block in VMamba [28]. This variant of a dynamic state space model named Mamba [16] adopts four distinct and complementary scanning paths, enabling each token to integrate information from all other tokens in four different directions.
However, while Mamba [16] achieves linear time complexity by compressing the global context of each channel into a fixed-dimensional hidden state [16], this compression inherently leads to information loss, in particular, loss of fine-grained local spatial details, that are crucial in segmentation to accurately localize region boundaries. To this end, we utilize Neighborhood Attention (Natten) [19], where a sliding-window attention mechanism localizes every pixel's attention span to its immediate neighborhood. This approach retains translational equivalence, effectively captures local dependencies, and has linear time complexity. In practice, we serially stack Natten and SS2D, and a shortcut around SS2D is employed to merge local and global information. The merged output is then fed into a 1×1 convolution layer for further global-local feature fusion.
局部注意力与状态空间模块
长程依赖建模对语义分割至关重要,它能实现全面的上下文学习和场景理解,这一点在基于Transformer的语义分割模型的成功中得到了验证。为了在所有网络层高效学习全局上下文,本文采用了VMamba中的SS2D模块。这个基于动态状态空间模型Mamba的变体采用四种互补的扫描路径,使每个token能够从四个不同方向整合来自其他所有token的信息。
然而,虽然Mamba通过将每个通道的全局上下文压缩为固定维度的隐藏状态实现了线性时间复杂度,但这种压缩本质上会导致信息损失,特别是对分割任务中精确定位区域边界至关重要的细粒度局部空间细节。为此,本文采用邻域注意力(Natten),其滑动窗口注意力机制将每个像素的注意力范围限定在其邻近区域。这种方法保持了平移等效性,有效捕获局部依赖关系,并具有线性时间复杂度。实际实现中,本文串联堆叠Natten和SS2D,并通过绕过SS2D的捷径连接来融合局部和全局信息。融合后的输出再经过1×1卷积层进行进一步的全局-局部特征融合。
Network architecture
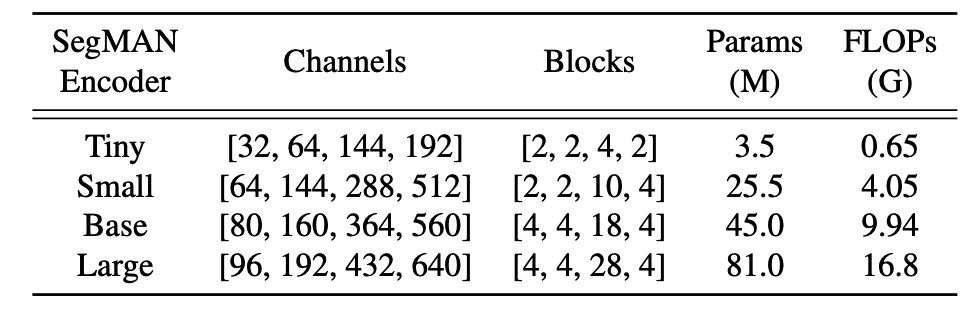
Our SegMAN Encoder produces a feature pyramid. The spatial resolution of F_i is H/2^{1+i }× W/2^{1+i} , where H and W are the height and width of the input image, respectively. We design three SegMAN Encoder variants with different model sizes, each with computational complexity comparable to some existing semantic segmentation encoders [18, 56, 60]. As the feature map resolution at Stage 4 is ( H/32 × W/32 ), global selfattention [48] becomes computationally feasible. Therefore we replace SS2D with this more powerful global context modeling mechanism. The configurations of these models are presented in Table 1.
Table 1. Configurations of the three SegMAN Encoder variants. FLOPs were measured at the 224 × 224 resolution.
网络架构
本文的SegMAN编码器生成特征金字塔。特征图Fi的空间分辨率为H/2^(1+i)×W/2^(1+i),其中H和W分别是输入图像的高度和宽度。本文设计了三种不同规模的SegMAN编码器变体,每种的计算复杂度都与现有的一些语义分割编码器相当。由于第四阶段的特征图分辨率降至(H/32×W/32),此时采用计算可行的全局自注意力来替代SS2D,以获得更强大的全局上下文建模能力。这些模型的具体配置详见表1。
3. Feature Decoder
Overview
As shown in Figure 3, our proposed decoder first aggregates features at various levels of abstraction (from low-level F_2 to high-level F_4) to obtain a feature map F of size H/8 × W/8, as in prior works [56, 57]. Specifically, each feature map Fi is projected to a lower dimension using a 1 × 1 convolution followed by batch normalization and ReLU, collectively denoted as **'Conv'** in Figure 3. Subsequently, F_3 and F_4 are upsampled using bilinear interpolation to match the spatial dimensions of F_2. The upsampled features F_up3 and F_up4 are concatenated together with F_2 and passed through a Conv layer for channel dimension reduction, resulting in F with size H/8 × W/8 × C, where C is the number of channels. The feature map F is then processed by our proposed MMSCopE module to extract rich multi-scale context features, producing a new feature map F'. We then add the feature map F' to F_2, F_up3, and F_up4 to enrich their multi-scale contexts. The final prediction pathway concatenates F' with these context-enhanced features and the global pooling result on F_up4, passes the combined features through a two-layer MLP, and the result is upsampled to the input resolution.
如图3所示,本文提出的解码器首先聚合不同抽象层次的特征(从低层级的F_2到高层级的F_4),获得尺寸为H/8×W/8的特征图F,这与先前工作[56,57]类似。具体而言,每个特征图Fi通过1×1卷积、批归一化和ReLU激活进行降维处理,在图3中统称为"Conv"。随后,F_3和F_4通过双线性插值上采样至F_2的空间尺寸。上采样后的特征F_up3和F_up4与F_2拼接后,再经过Conv层进行通道降维,最终得到尺寸为H/8×W/8×C的特征图F(C为通道数)。该特征图随后输入本文提出的MMSCopE模块,提取丰富的多尺度上下文特征,生成新特征图F'。本文将F'分别与F_2、F_up3和F_up4相加,增强它们的多尺度上下文信息。最终预测路径将F'与这些上下文增强特征以及F_up4的全局池化结果拼接,通过两层MLP融合后,上采样至输入分辨率。
Mamba-based multi-scale context extraction
To effectively extract contexts at different scales, we propose a Mamba-based Multi-Scale Context Extraction (MMSCopE) module. As shown in Figure 3, we apply strided convolutions to downsample the feature map F, generating F_s2 and F_s4 with a resolution equal to 1/2 and 1/4 of that of F, respectively. The motivation behind this is to obtain multiple regionally aggregated contexts through two derived feature maps: F_s2, which aggregates features from 3 × 3 neighborhoods using a convolution with stride 2, and F_s4, which aggregates features from 5 × 5 neighborhoods with stride 4. Then, motivated by the observation that Mamba scans each channel independently, we use a single Mamba scan to simultaneously extract contexts from the three feature maps F, F_s2, and F_s4. The main idea is to concatenate these feature maps along the channel dimension and perform a single Mamba scan, which is more efficient on the GPU than processing each feature map separately. However, the spatial dimensions of these feature maps are not consistent, which prevents direct concatenation.
基于Mamba的多尺度上下文提取
为有效提取不同尺度的上下文,本文提出基于Mamba的多尺度上下文提取模块(MMSCopE)。如图3所示,本文使用步长卷积对特征图F进行下采样,分别生成分辨率为F的1/2和1/4的F_s2和F_s4。这样设计的动机是通过两个派生特征图获得区域聚合的上下文:F_s2通过步长2的卷积聚合3×3邻域特征,F_s4通过步长4的卷积聚合5×5邻域特征。基于Mamba可独立扫描各通道的特性,本文使用单次Mamba扫描同时从F、F_s2和F_s4三个特征图提取上下文。核心思想是沿通道维度拼接这些特征图后执行单次Mamba扫描,这比单独处理每个特征图在GPU上更高效。但由于各特征图空间尺寸不一致,直接拼接不可行。
To resolve this, we employ lossless downsampling via the Pixel Unshuffle [42] operation to reduce the spatial dimensions of F and F_s2 to match that of F_s4, which is H/32 × W/32. Specifically, this operation rearranges non-overlapping 4×4 patches from F and 2×2 patches from F_s2 into their respective channel dimension, increasing the channel depth by a factor of 16 and 4 respectively, while preserving complete spatial information. The transformed feature maps retain information at their original scales. To reduce computational costs, we project each feature map to a fixed channel dimension C through 1 × 1 convolutions. This step assigns equal importance to the context information from each scale. Then we concatenate the projected feature maps along the channel dimension, and pass the combined feature map to SS2D [28] to achieve multi-scale context extraction in a single scan. The resulting feature map is of size H/8 × W/8 × 3C, where the three segments along the channel dimension correspond to earlier feature maps at three distinct scales (F, F_s2, and F_s4). To facilitate context mixing across scales, we append a 1 × 1 convolution layer after the SS2D scan. Finally, we use bilinear interpolation to upsample the mixed features to 1/8 of the input resolution, and project the channel dimension down to C using another 1 × 1 convolution. This yields the new feature map F' with mixed multi-scale contexts.
为此,本文采用Pixel Unshuffle操作进行无损下采样,将F和F_s2的空间尺寸降至与F_s4相同的H/32×W/32。具体来说,该操作将F的4×4非重叠块和F_s2的2×2块重排至通道维度,分别使通道深度增加16倍和4倍,同时保留完整空间信息。变换后的特征图保留了原始尺度信息。为降低计算成本,本文通过1×1卷积将各特征图投影至固定通道维度C,这确保各尺度上下文信息具有同等重要性。然后将投影后的特征图沿通道维度拼接,输入SS2D实现单次扫描的多尺度上下文提取。所得特征图尺寸为H/8×W/8×3C,其中通道维度的三个区段对应原始三个尺度(F、F_s2和F_s4)的特征图。为促进跨尺度上下文融合,本文在SS2D扫描后添加1×1卷积层。最后使用双线性插值将混合特征上采样至输入分辨率的1/8,并通过另一个1×1卷积将通道维度降至C,最终得到融合多尺度上下文的新特征图F'。
Multi-scale fusion
Instead of directly using the feature map F' to predict pixel labels, we further exploit stage-specific representations from the encoder by adding F' to F_2, F_up3, and F_up4. This effectively injects multi-scale contexts into stage-specific feature maps, which inherits information from various levels of abstraction. Next, we concatenate the resulting context-enhanced feature maps from each stage, the multi-scale context feature F', and the global average pooling result on F_up4. For pixel-wise label prediction, the diverse concatenated features are fused through a two-layer MLP, and further bilinearly interpolated to restore the original input resolution.
多尺度融合
本文不仅直接使用F'预测像素标签,还通过将其与F_2、F_up3和F_up4相加,进一步利用编码器的阶段特异性表征。这有效将多尺度上下文注入各阶段特征图,继承不同抽象层级的信息。接着,本文将各阶段的上下文增强特征、多尺度上下文特征F'和F_up4的全局平均池化结果拼接。对于像素级标签预测,这些多样化特征通过两层MLP融合后,再经双线性插值恢复至原始输入分辨率。
Results

















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









